Fine-tuning Starategy : Self-Ensemble, Self-Distillation
Abstract
BERT와 같은 pre-trained language model을 fine-tuning하여 downstream task에서 사용하는 것은 높은 성능을 보이는 효과적인 방법입니다. 최근의 연구들은 BERT 모델의 구조를 변경하거나, task에 맞는 데이터로 pre-train을 다시하거나, 외부 데이터와 지식을 활용하는 것에 집중해왔습니다. 그러나 fine-tuning 전략 자체에 대한 연구는 많이 진행되지 않았습니다. 이 논문에서는 self-ensemble 과 self-distillation 이라는 효과적인 메커니즘을 통해 fine-tuning을 개선하고자 합니다. 텍스트 분류와 자연어 추론 task에서 위 방법이 외부 데이터나 지식을 활용하지 않고도 높은 성능을 보이는 것을 실험을 통해 증명했습니다.
Introduction
BERT, RoBERTa, XLNet과 같은 pre-trained langauge model은 방대한 양의 레이블 되지 않은 데이터로부터 범용적인 langauge representation을 학습하였고, classification, QA, NLI 등에서 높은 성능을 보이고 있습니다. 이러한 모델을 downstream task에서 초기 값으로 사용하는면 처음부터 모델을 학습하는 것을 피할 수 있습니다.
Downstream task에서 pre-trained language model을 사용하는 방법으로는 일반적으로 두가지가 있습니다.
1. Feature extraction
pre-trained language model의 parameter을 frozen 합니다.
2. Fine-tuning
pre-trained language model의 parameter을 frozen 하지 않고 downstream data로 학습합니다.
두가지 방법 모두 대부분의 downstream task에서 효과적이지만, 일반적으로 fine-tuning이 feature extraction보다 더 좋은 결과를 보입니다.
사전 학습을 다시 하거나, data augmentation, 외부 지식을 활용한 fine-tuning 최적화, further-pretraining, 또는, 여러 개의 모델을 ensemble하여 BERT 모델의 성능을 더 향상 시킬 수 있습니다. 그러나 위와 같은 방법은 외부 데이터나 지식을 필요로 하거나, 모델 사이즈가 커지는 단점이 있습니다. 따라서 이 논문에서는 외부 데이터나 지식을 사용하지 않으면서, BERT의 성능을 효율적으로 향상시킬 수 있는 방법을 연구하였습니다.
Methodology
BERT 모델을 fine-tuning 하는 것은 일반적으로 stochastic gradient descent 을 사용하여 cross entropy loss를 최소화하는 것을 목표로 합니다. 확률적 특성으로 인해 학습 데이터의 순서에 따라 fine-tuning model의 성능이 영향을 받을 수 있습니다(e.g. 마지막 학습 batch에 노이즈가 있는 경우). 이 논문에서는 ensemble과 knowledge distillation 아이디어를 채용하여 두가지 fine-tuning 전략을 제안합니다.
1. Ensemble BERT
Voted BERT
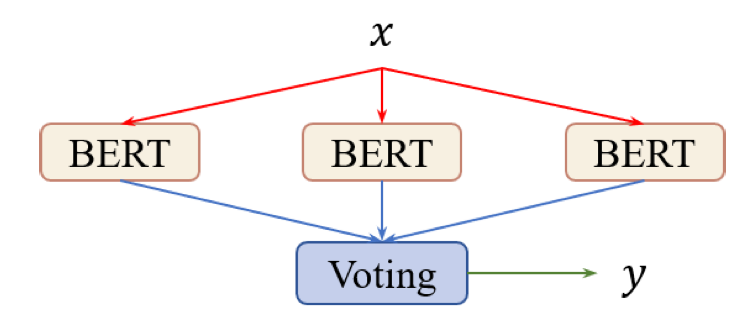
일반적인 ensemble 방법으로는 voting이 있습니다. 먼저, 각기 다른 random seed 로 여러 개의 BERT를 fine-tune 합니다. Input을 각 model에 통과시켜서 probability 값을 구하고, 모두 더합니다. Ensemble 모델의 예측값은 이 더한 값중 확률이 가장 큰 값이 됩니다.
Ensemble은 다음과 같이 정의합니다.
는 다른 random seed 값으로 학습된 -th 모델을 말합니다. 는 -th 모델의 parameter을 의미하고, 는 모든 K BERT의 parameter을 의미합니다.
Single BERT에 비해 voted BERT는 높은 성능을 보일 수 있지만, 여러 개의 BERT 모델을 갖고 있어야 하기 때문에 자원 효율성이 떨어집니다.
Averaged BERT
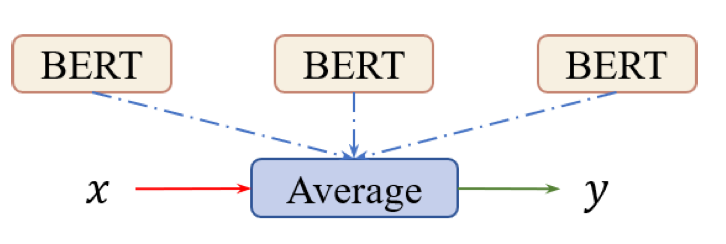
Averaged BERT는 ensemble model의 모델 복잡도를 낮추기 위하여 고안된 방법으로, 여러 개의 BERT 모델 parameter 를 평균내서 single 모델의 파라미터로 사용합니다. 이를 parameter-averaging 전략이라고 하며, 모델이 하나이므로 voted BERT 보다 연산 비용과 메모리 효율성이 좋습니다.
Averaged BERT는 다음과 같이 정의합니다.
는 K개의 독립된 fine-tuned BERTs parameters의 평균값입니다.
2. Self-Ensemble BERT
Ensemble BERT는 일반적으로 좋은 성능을 보이지만, 여러 개의 BERT를 학습시켜야하므로 비용이 비쌉니다. 학습 비용을 낮추기 위해서 논문에서는 self-ensemble 기법을 제안하였습니다. Self-ensemble은 다른 time step의 모델을 활용합니다. 즉, 각 time step의 BERT 모델을 base model로 간주하고, 이를 ensemble 합니다.
Self-Ensemble BERT는 다음과 같이 정의합니다.
는 time step의 averaged parameters of BERT를 의미합니다.
3. Self-Distillation BERT
Self-ensemble이 model의 성능을 개선할 수는 있지만, base model은 일반적인 fine-tuning 전략과 동일한 방법으로 학습하고 ensemble model의 영향을 받지 않습니다. 논문에서는 이를 개선하기 위해 Knowledge distillation을 사용하였습니다. 각 학습 단계에서 BERT 모델은 student model이고 두 개의 teacher(target label, teacher model) 로 부터 학습합니다. Teacher model은 self-ensemble model로 이전 time step의 student model의 평균입니다. Teacher-student learning을 통해, student model은 더 강건하고 정확해집니다.
Self-Distillation-Averaged (SDA)
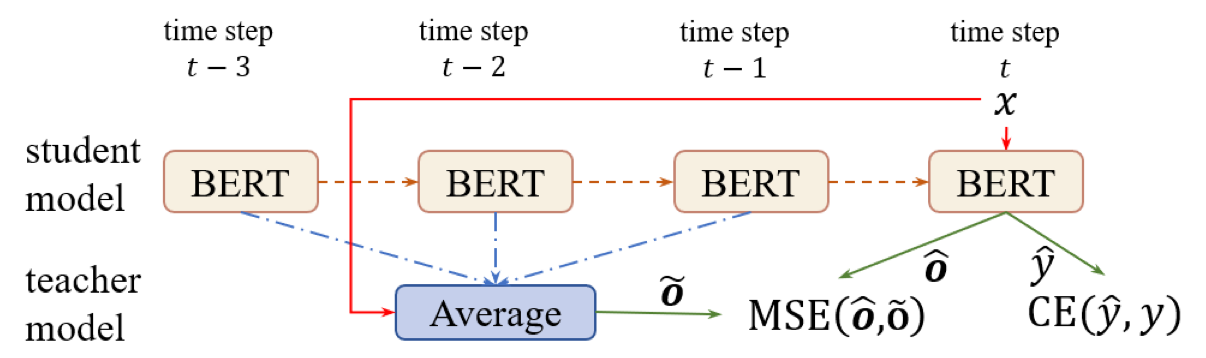
는 teacher model로 self-ensemble BERT with parameter averaging을 사용합니다.
가 student BERT를 의미할 때, 의 학습 목표는
을 최소화하는 것입니다. CE와 MSE는 각각 cross entropy loss와 mean squared error을 의미하고, 는 두 loss function의 중요도를 조절하는 변수입니다. CE에서는 label과 student model의 예측 label을 활용하여 학습하며, MSE에서는 teacher model과 student model의 logits 값을 활용하여 학습합니다. Teacher model인 는 최근 time step의 self ensemble BERT 입니다.
Time step 에서, 는 최근 time step의 averaged parameters를 의미합니다. 는 teacher size의 개수를 나타내는 hyperparameter 입니다.
Self-Distillation-Voted (SDV)
는 의 teacher model을 self-voted BERT로 변경한 방법입니다. 의 학습 목표는
을 최소화하는 것입니다.
Experiments
논문에서는 vanilla fine-tuning BERT를 base model로 사용하고, self-ensemble, self-distillation 기법을 사용한 모델과 성능을 비교하였습니다.
1. Dataset
Text Classification
- IMDb
- AG's News
- DBPedia
- Yelp
Natural Language Inference
- SNLI
- MNLI
2. Hyperparameters
- Official BERT 모델과 동일
(self-distillation weight , teacher size 제외) - AdamW optimizer with warm-up proportion of 0.1
- lr for BERT encoder: 2e-5, lr for softmax: 1e-3, dropout 0.1
- 512 token 이상인 sequence는 뒤를 자름
- batch size gradient accumulation step = 16
- 4 different random seeds and save checkpoint for ensemble BERT
3. Model Selection
Self-Distillation Weight
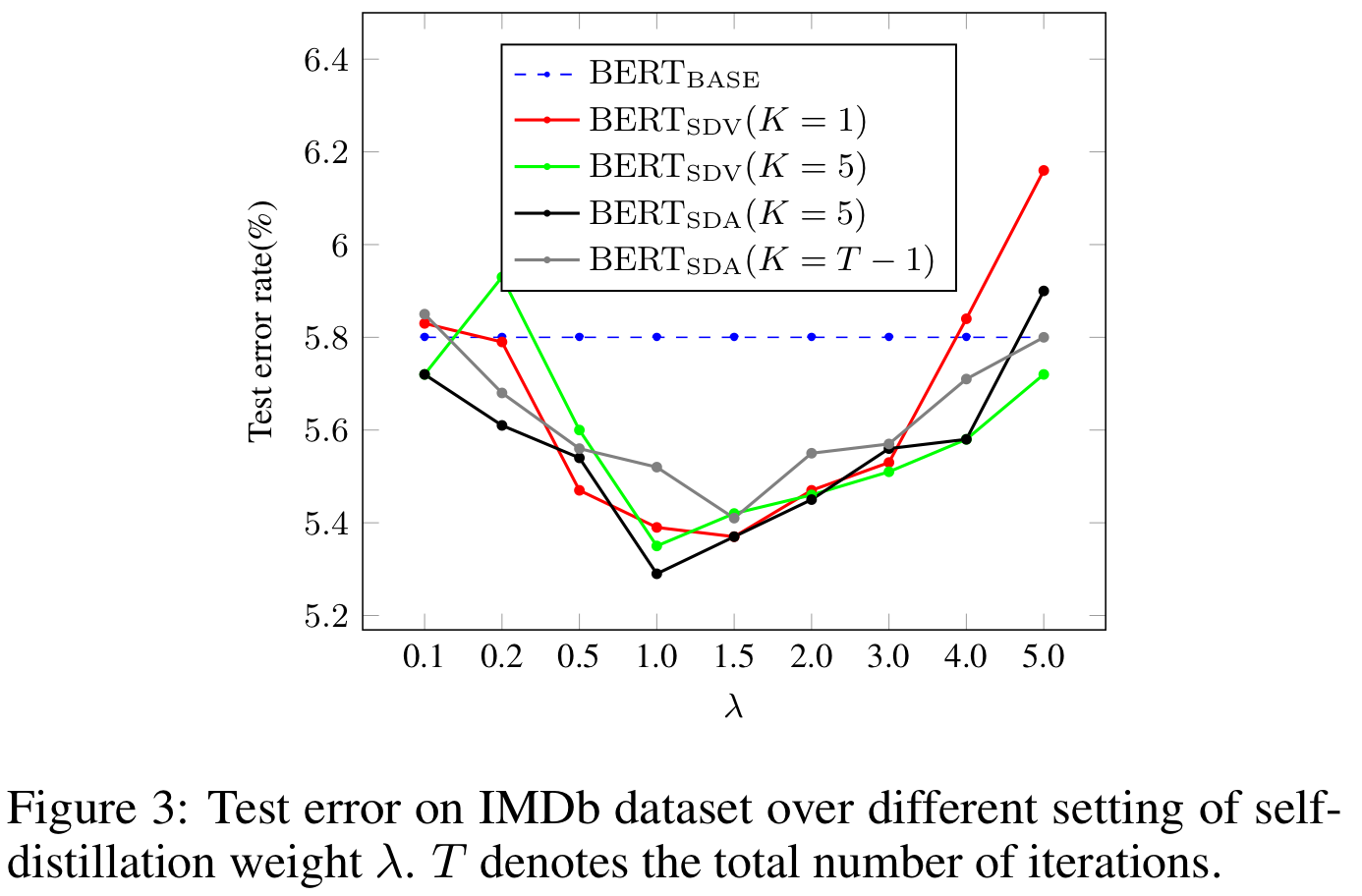
일 때 가장 좋은 성능을 보였기 때문에 로 설정하습니다.
Teacher Size
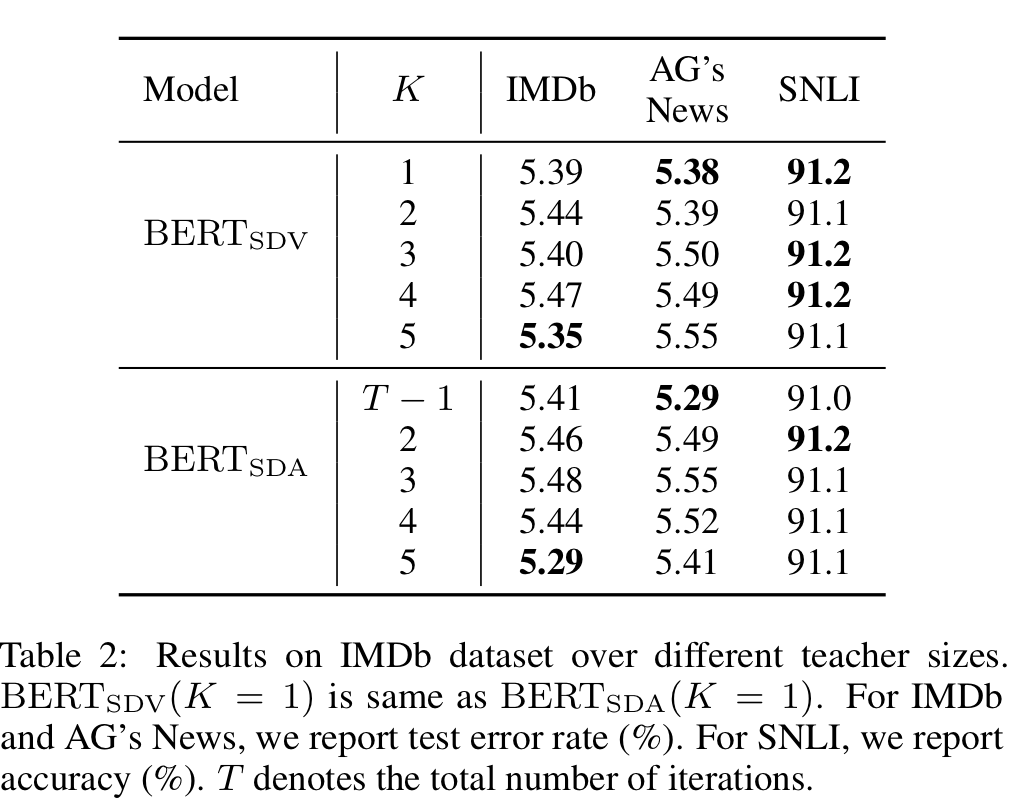
Teacher size 는 dataset에 민감했습니다. 따라서, 각 dataset에 대한 teacher size를 실험을 통해 결정했습니다.
4. Model Analysis
Train Stability
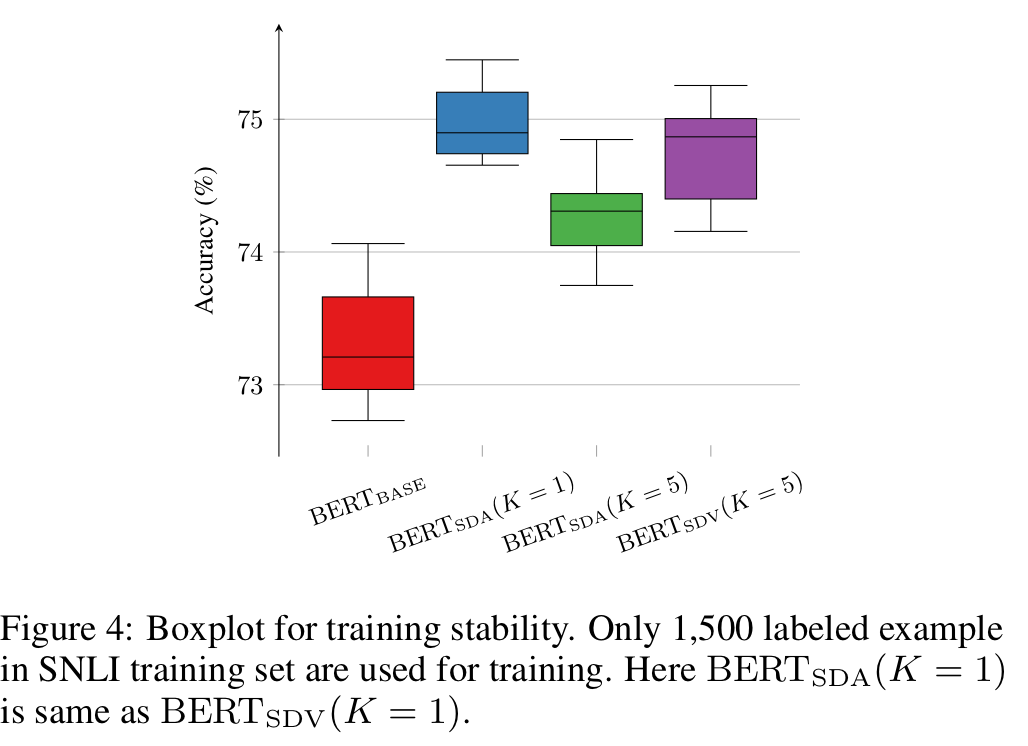
Hyperparameter가 동일해도 데이터가 학습되는 순서가 다르면 모델의 성능은 다를 수 있습니다. 실험 결과 vanilla 보다 self-distillation을 사용한 모델이 정확도가 높고, 더 작은 분산 값을 보였습니다.
Convergence Curves
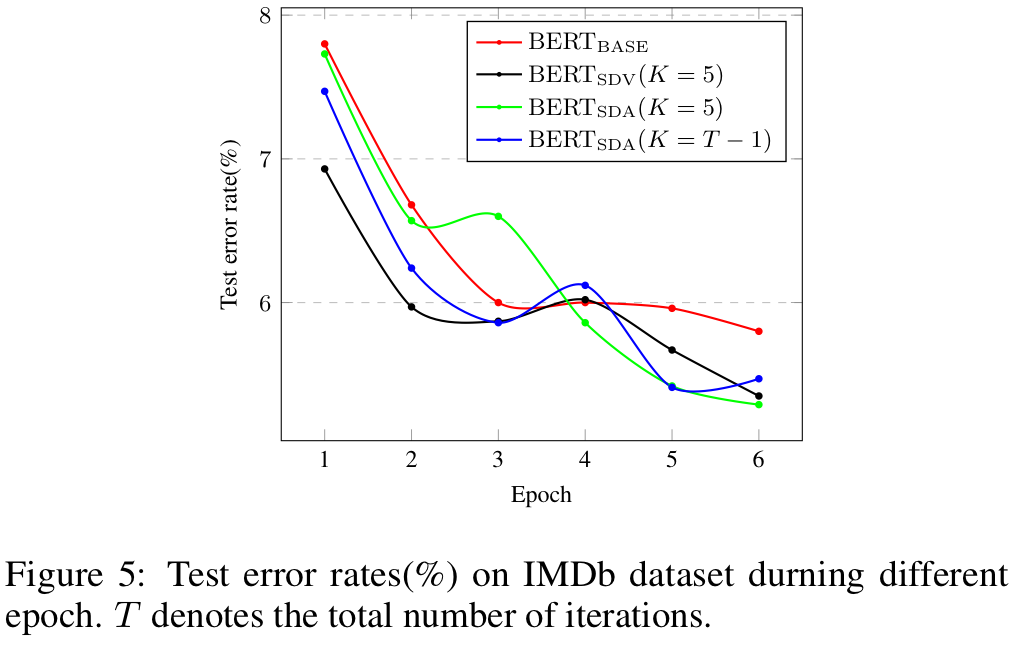
를 사용했을 때 마지막 3 epochs(6.00% to 5.80%)에 대해선 test error rate이 많이 줄어들지 않았습니다. 그러나 self-distillation을 사용하면 5.35%(), 5.29%()까지 줄어들었습니다.
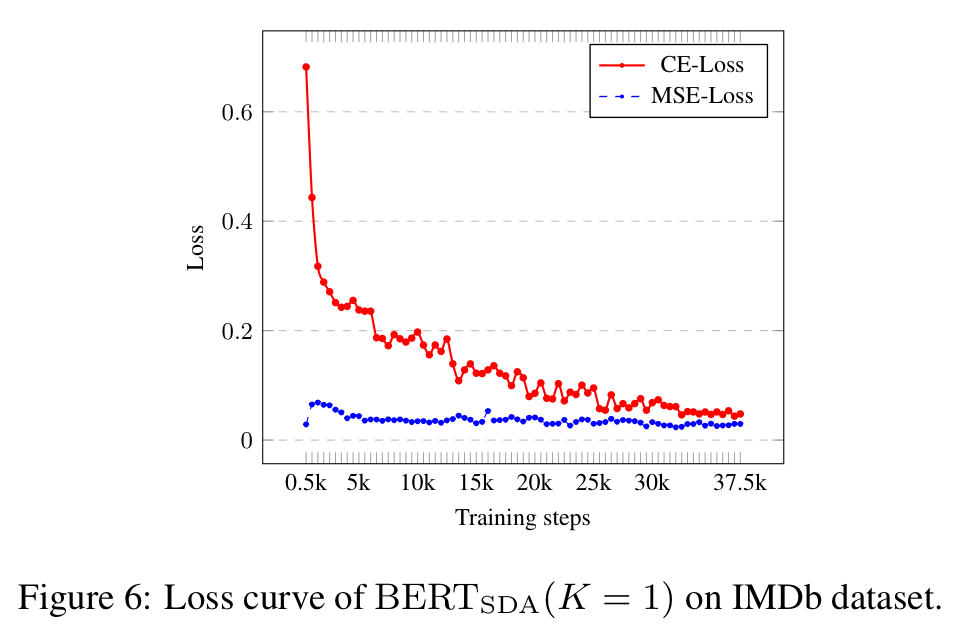
초기에는 CE loss가 optimization에 영향을 많이 미쳤습니다. 그러나 학습이 끝나갈 때, CE loss가 작아져서 self-distillation이 optimization에 끼치는 영향의 비중이 늘어나게 되었습니다. Self-distillation을 통해서 CE loss로 더이상 성능 개선을 기대할 수 없음에도, ensemble 된 teacher 모델을 통해 모델은 더욱 강건해지고 일반화 되었습니다.
5. Model Performance
Effects on Fine-tuning BERT-Base
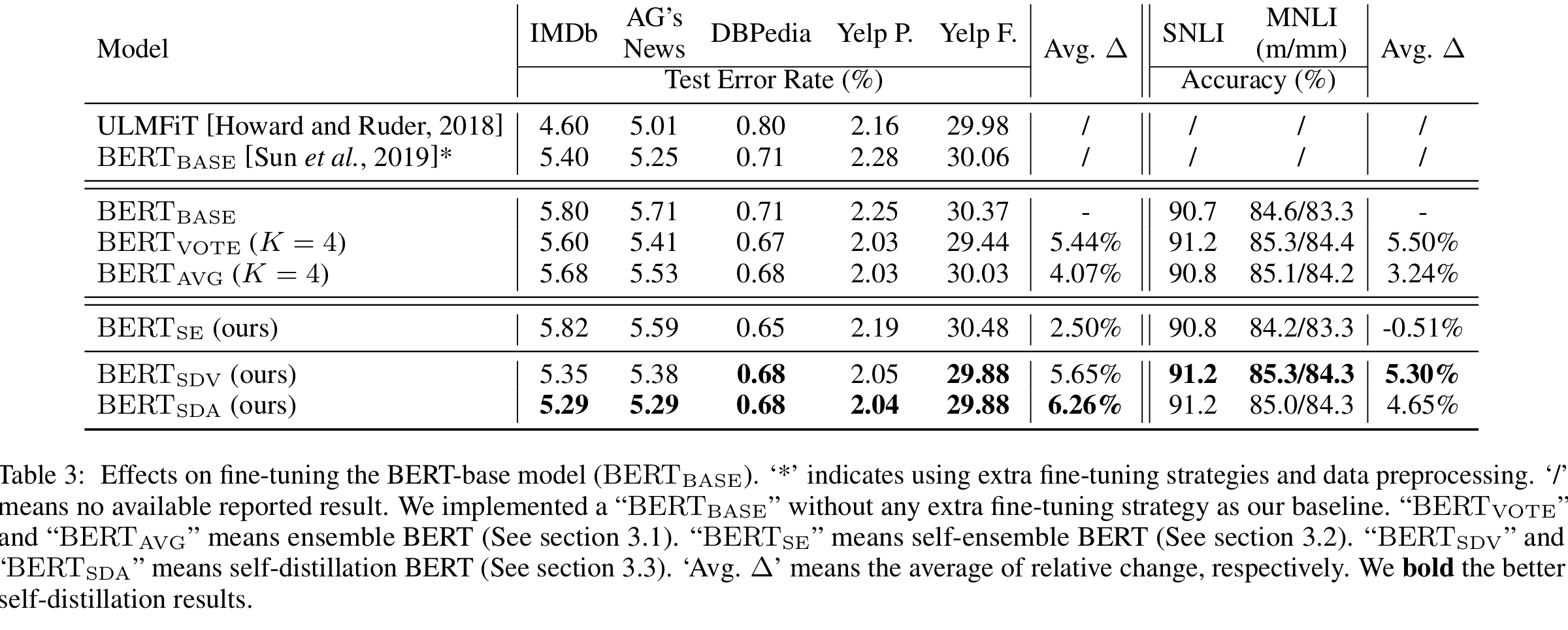
Ensemble BERT는 Single BERT 보다 좋은 성능을 보였습니다만, self-ensemble BERT는 성능 개선이 크지 않았습니다. Self-distillation을 적용하면 성능이 많이 개선된 것을 보아 base model을 개선하기 위해서 self-distillation이 필요한 것을 알 수 있습니다.
Effects on Fine-tuning BERT-Large
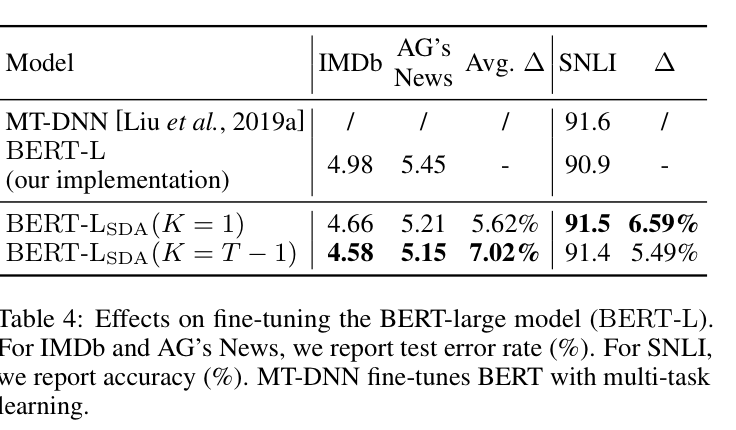
BERT-Large 모델을 사용했을 때, MT-DNN에 근사한 성능을 외부 데이터나 지식 없이 보이는 것을 확인하였습니다.
Discussion
일반적으로 BERT{SDA}$가 메모리 효율성이 더 높음에도, $BERT{SDV}$와 유사한 성능을 보였습니다. NLI에서는 SDA가 SDV 보다 성능이 떨어졌습니다. NLI와 같은 어려운 task의 경우 parameter averaging이 logits voting 보다 낮은 성능을 보였지만, 단순한 text classification task 에서는 높은 성능을 보였습니다.
Conclusion
논문에서는 외부 지식이나 데이터를 사용하지 않고 효율적으로 BERT를 fine-tuning 할 수 있는 방법을 제안했습니다. Self-ensemble은 학습 효율성을 낮추지 않으면서 parameter averaging을 통해 성능을 개선합니다. Self-distillation은 student와 teacher model이 함께 성능이 향상되며 학습합니다. 정교한 hyperparameter tuning이나 data augmentation을 적용하면 모델의 성능을 더욱 개선할 수 있을 것으로 보입니다.
