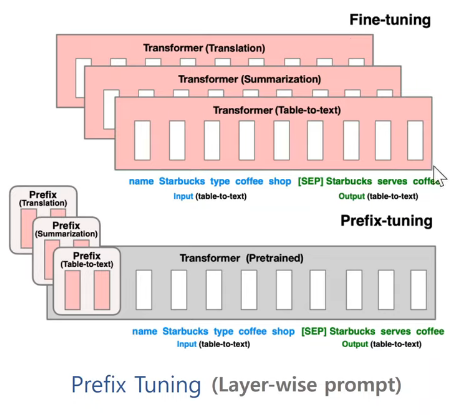
- 분홍색: 학습되는 부분
- prefix의 경우 각 트랜스포머 레이어의 앞부분에 레이어를 붙여 해당 부분만 학습한다.
Prefix Tuning의 기본 개념:
Prefix Tuning은 사전 학습된 LLM의 대부분의 매개변수를 고정한 채로, 각 레이어의 시작 부분에 학습 가능한 연속적인 벡터(prefix)를 추가하는 방식입니다. 이 prefix는 특정 태스크에 맞게 모델의 동작을 조정하는 역할을 합니다.
-
기존 fine-tuning 방식:
전통적인 방식으로는 모델의 모든 매개변수를 업데이트해야 합니다. GPT-3의 경우 1750억 개의 매개변수를 모두 조정해야 하므로, 계산 비용이 매우 높고 시간이 오래 걸립니다. -
Prefix Tuning 방식:
- 모델의 각 트랜스포머 레이어 앞에 학습 가능한 prefix 벡터를 추가합니다.
- 예를 들어, GPT-3가 96개의 레이어를 가지고 있다면, 96개의 prefix 벡터를 추가합니다.
- 각 prefix 벡터의 길이를 예를 들어 10이라고 하면, 총 96 x 10 x 히든 차원(예: 12,288) = 약 11,796,480개의 매개변수만 학습하면 됩니다.
- 이는 전체 모델 매개변수의 약 0.007%에 불과합니다.
Prefix Tuning의 장점:
1. 효율성: 적은 수의 매개변수만 학습하므로 계산 비용과 시간이 크게 줄어듭니다.
2. 유연성: 여러 태스크에 대해 각각의 prefix를 학습할 수 있어, 하나의 기본 모델로 다양한 태스크를 수행할 수 있습니다.
3. 메모리 효율성: 각 태스크별로 전체 모델을 저장할 필요 없이 학습된 prefix만 저장하면 되므로 메모리 사용이 효율적입니다.
Prefix Tuning은 LLM을 효과적으로 활용하면서도 계산 비용을 크게 줄일 수 있는 혁신적인 방법입니다. 특히 다양한 태스크에 대해 모델을 빠르게 적응시켜야 하는 상황에서 매우 유용합니다.
prompt tuning과의 차이
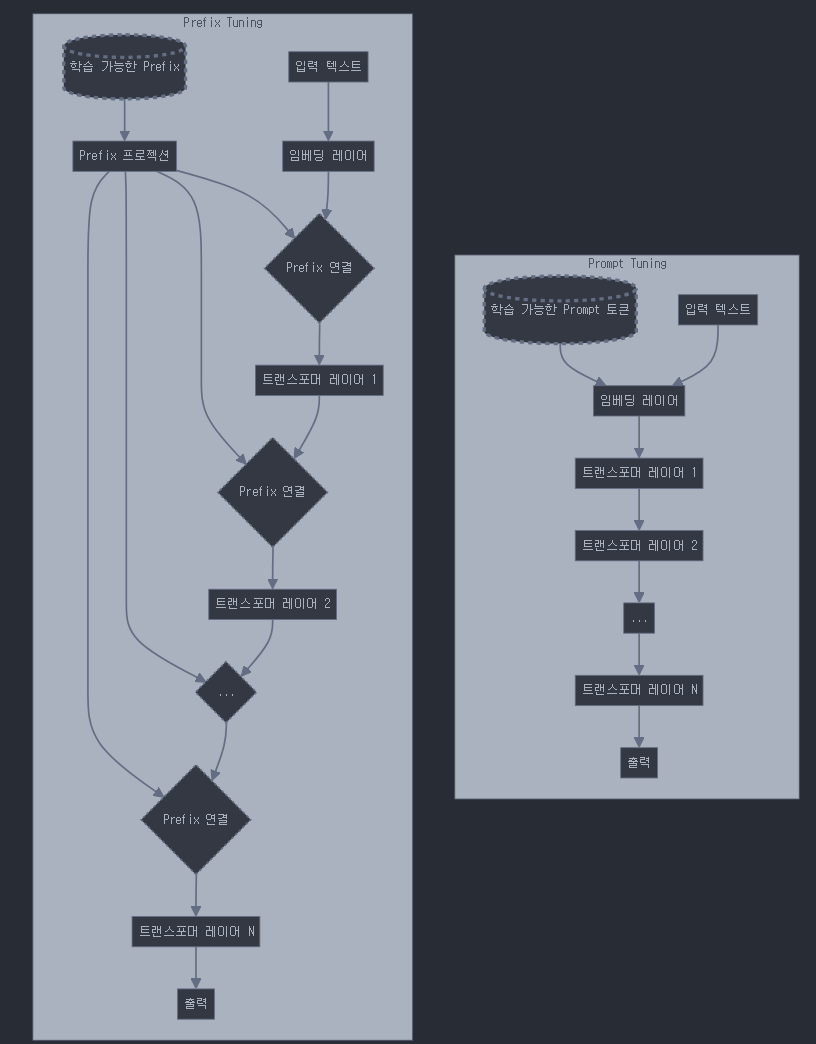
p-tuning과 prompt tuning은 prefix tuning과 유사하지만, 약간의 차이가 있습니다:
- Prompt tuning:
- 모델의 입력 부분에만 학습 가능한 연속적인 임베딩을 추가합니다.
- 주로 입력 시퀀스의 시작 부분에 적용됩니다.
- P-tuning:
- Prompt tuning과 유사하지만, 더 복잡한 구조를 사용합니다.
- 입력의 여러 위치에 학습 가능한 프롬프트 토큰을 삽입할 수 있습니다.
- 주로 입력의 앞부분에 집중되지만, 중간이나 끝에도 삽입 가능합니다.
- Prefix tuning:
- 모델의 각 레이어에 학습 가능한 접두사(prefix)를 추가합니다.
- 입력 부분뿐만 아니라 모델의 여러 레이어에 걸쳐 적용됩니다.
따라서, p-tuning과 prompt tuning은 주로 모델의 입력 부분에 집중되는 반면, prefix tuning은 모델의 여러 레이어에 걸쳐 적용된다는 점에서 차이가 있습니다.
