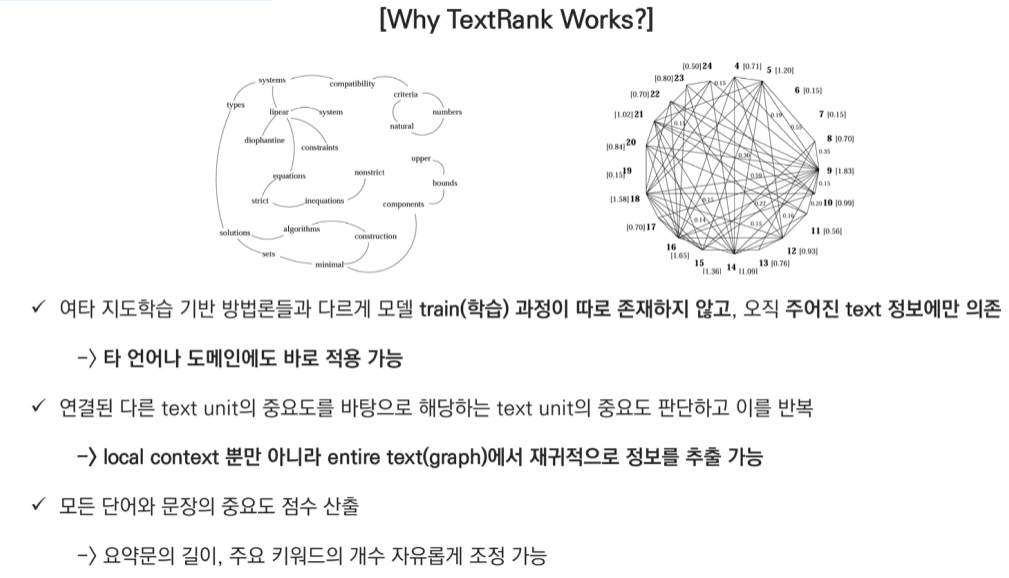
TextRank는 PageRank 알고리즘을 자연어 처리에 적용한 것으로, 크게 두 가지 주요 방법이 있습니다.
1. 문장 기반 TextRank (Extractive Summarization)
동작 원리
-
전처리
- 입력 텍스트를 문장 단위로 분리
- 각 문장을 벡터로 변환 (보통 TF-IDF 사용)
-
그래프 구성
- 노드: 각 문장
- 엣지: 문장 간 유사도 (코사인 유사도)
-
순위 계산
Score(Si) = (1-d) + d * Σ(Similarity(Si,Sj) * Score(Sj) / Σ(Similarity(Sj,Sk)))- d: 감쇄 계수 (보통 0.85)
- Si: i번째 문장
- Similarity: 문장 간 유사도
구현 예시
def sentence_similarity(sent1, sent2, tfidf_matrix):
return cosine_similarity(
tfidf_matrix[sent1:sent1+1],
tfidf_matrix[sent2:sent2+1]
)[0][0]
def build_similarity_matrix(sentences, tfidf_matrix):
similarity_matrix = np.zeros((len(sentences), len(sentences)))
for idx1 in range(len(sentences)):
for idx2 in range(len(sentences)):
if idx1 != idx2:
similarity_matrix[idx1][idx2] = sentence_similarity(
idx1, idx2, tfidf_matrix
)
return similarity_matrix2. 키워드 기반 TextRank (Keyword Extraction)
동작 원리
-
전처리
- 텍스트를 단어 단위로 분리
- 품사 태깅 및 불용어 제거
- 주로 명사, 형용사만 선택
-
그래프 구성
- 노드: 각 단어
- 엣지: 단어 간 동시 출현 관계
- 윈도우 크기(N) 내에서 함께 등장하는 단어들을 연결
-
순위 계산
Score(Wi) = (1-d) + d * Σ(Wji * Score(Wj) / Σ(Wjk))- Wi: i번째 단어
- Wji: 단어 j와 i 사이의 가중치
- d: 감쇄 계수
구현 예시
def build_word_graph(words, window_size=4):
graph = defaultdict(lambda: defaultdict(int))
for i in range(len(words) - window_size + 1):
window = words[i:i + window_size]
for word1 in window:
for word2 in window:
if word1 != word2:
graph[word1][word2] += 1
return graph공통 특징
장점
- 비지도 학습 방식으로 학습 데이터 불필요
- 언어 독립적 적용 가능
- 구현이 상대적으로 간단
한계
- 문서의 길이가 너무 짧은 경우 성능 저하
- 문맥적 의미 파악의 한계
- 동음이의어/이음동의어 처리 어려움
성능 최적화 팁
-
문장 기반
- 문장 임베딩 방식 개선 (Word2Vec, BERT 등 활용)
- 문장 유사도 계산 방식 다양화
- 문장 길이에 따른 가중치 적용
-
키워드 기반
- 윈도우 크기 최적화
- 품사 태깅 정확도 개선
- 복합명사 처리 로직 추가
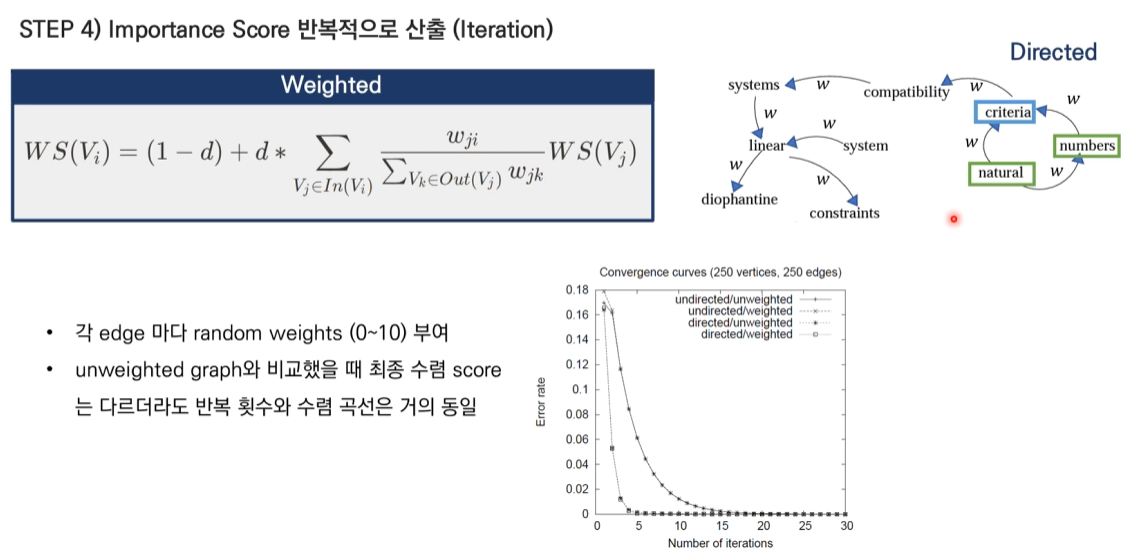
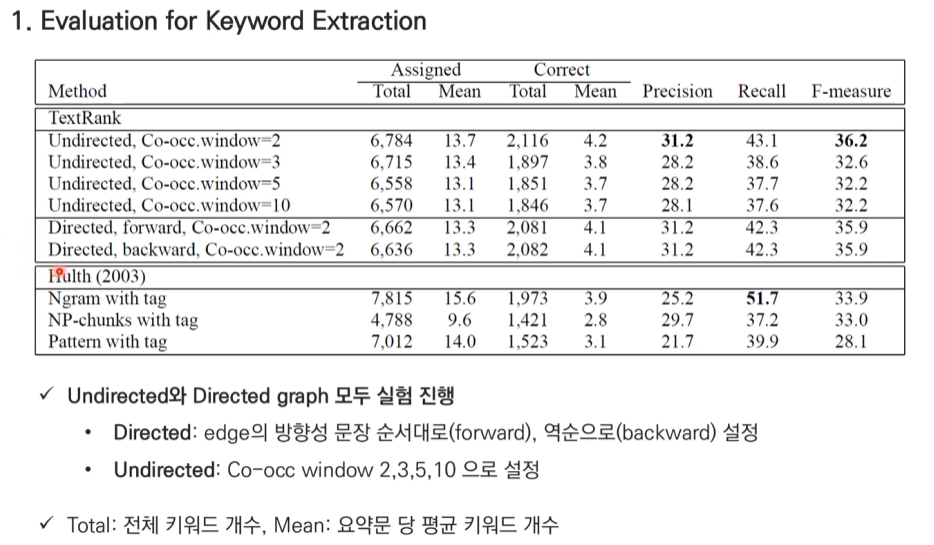
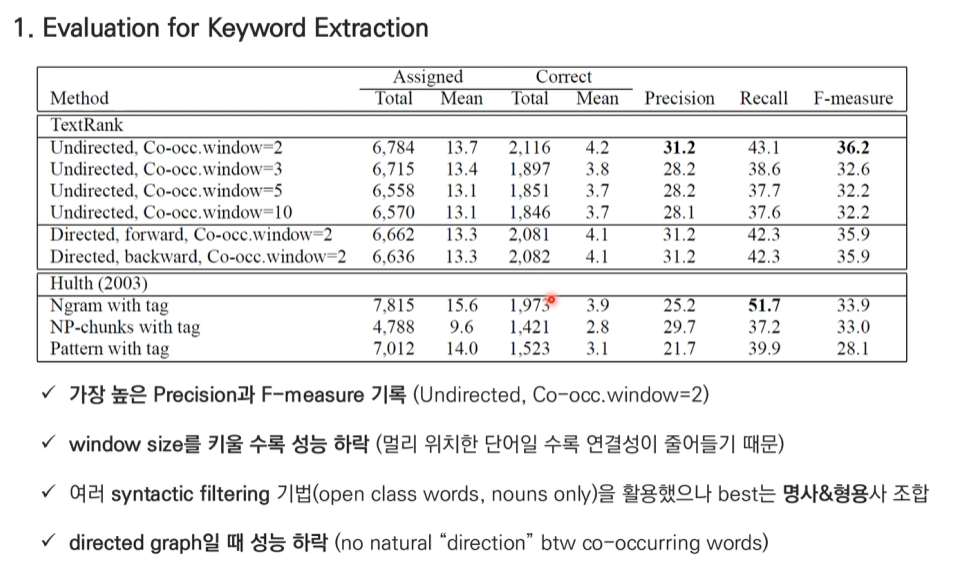
TextRank for keyword


- 실험 결과 명사, 형용사 조합이 가장 좋은 결과.

- window size 2에 해당하는 단어들을 연결해 준다.
- 위 예제는 방상형과 가중치가 없는 그래프이다.
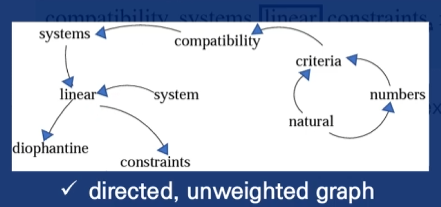
- 방향이 있고 가중치가 없는 그래프
- 방향성은 window size에서 왼쪽에서 오른쪽에 있는 방향으로 정해진다.
- ex) linear 중심, window size 2인 경우: system이 linear로 방향을 가르킨다.<
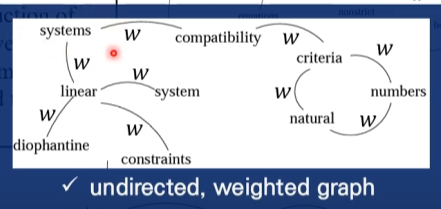
- 방향이 없고 가중치가 있는 그래프
- 가중치 W
- 랜덤으로 생성
- 단어의 빈도 or Sentence의 경우 문장의 유사도
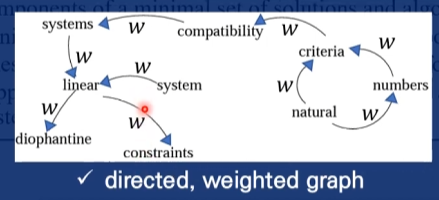
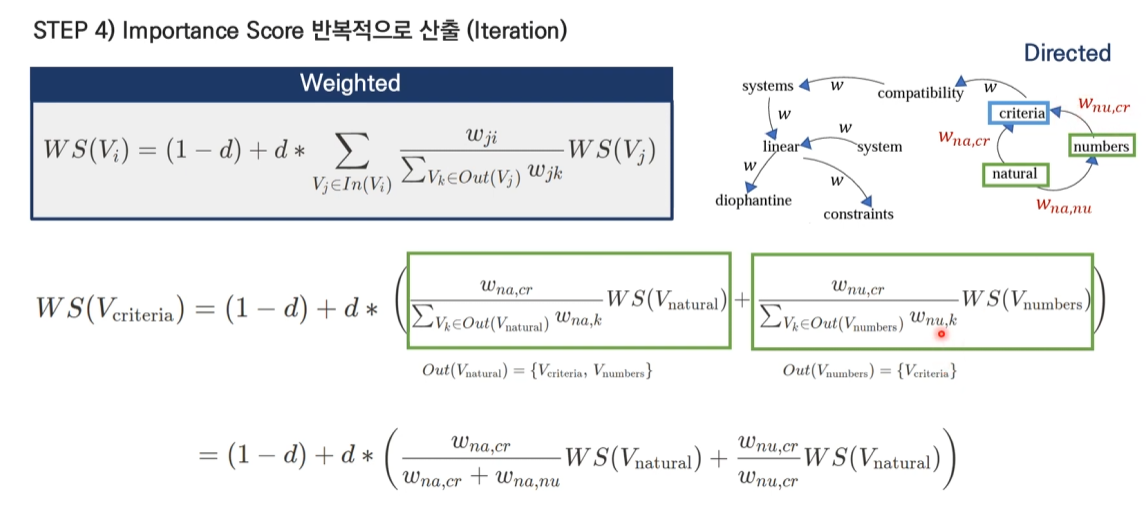
- 방향이 있고 가중치도 있는 그래프
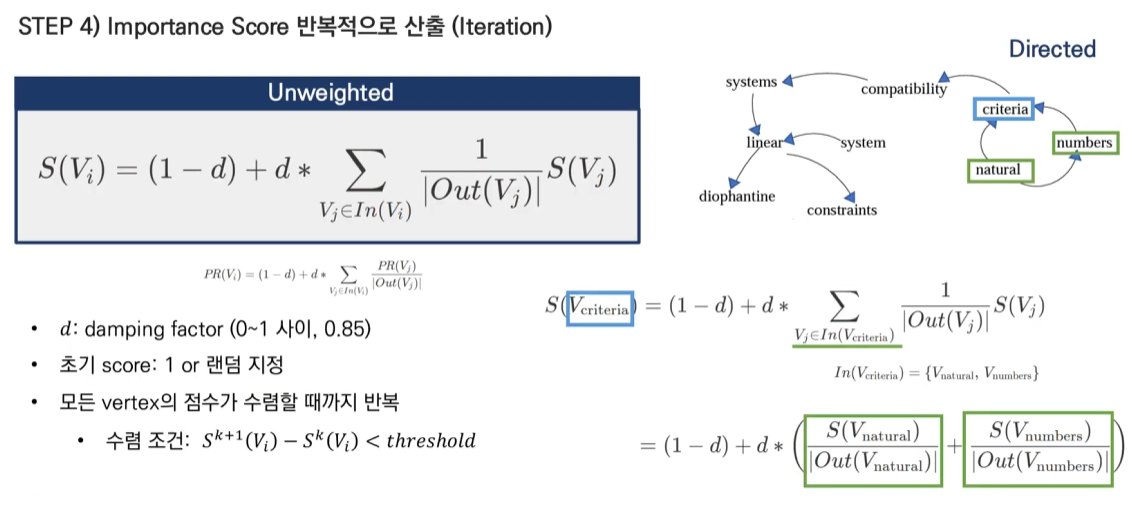
- page rank식과 일치한다.
- 초기 Score는 1 또는 랜덤으로 지정한다


TextRank for sentence

TextRank for Sentence Extraction에 대해 주어진 예시 문장들(9번, 18번)을 통해 자세히 설명드리겠습니다.
- 문장 유사도 계산 과정:
문장 9: "Hurricane Gilbert Swept toward the Dominican Republic Sunday, and the Civil Defense alerted its heavily populated south coast to prepare for high winds, heavy rains, and high seas."
문장 18: "Strong winds associated with the Gilbert brought coastal flooding, strong southeast winds, and up to 12 feet to Puerto Rico's south coast."
공통 단어(wk) 확인:
- winds
- coast
- Gilbert
- strong (같은 의미의 단어도 포함)
유사도 계산:
Similarity(S9, S18) = |공통 단어 수| / (log|S9의 단어 수| + log|S18의 단어 수|)
= 4 / (log28 + log22)- 유사도 특징:
- 모든 문장이 각각의 vertex가 됨
- 큰 context window 대신 문장 간 단어 중복을 봄
- Normalization factor(log 사용)로 긴 문장의 유사도가 지나치게 높아지는 것을 방지
- Weight Score 계산 (d=0.85 사용):
WS(Vi) = (1-d) + d * Σ(wji / Σwjk * WS(Vj))예시 문장 9의 경우:
- 다른 문장들과의 유사도를 모두 계산
- 연결된 모든 문장들의 weight score에 영향을 받음
- 정규화를 위해 나가는 edge들의 weight 합으로 나눔
- 주요 특징:
- 문서 전체의 맥락을 고려함 (전체 문장 간의 관계)
- 단순 빈도수가 아닌 문장 간 유사도를 기반으로 함
- 로그를 사용한 정규화로 문장 길이 차이 보정
- 반복적인 계산을 통해 수렴된 점수 도출
- 실제 활용:
- 최종 score가 높은 문장들이 문서의 주요 내용을 담고 있는 것으로 판단
- 요약문 생성시 상위 점수의 문장들을 선택
- 문장 9와 18의 경우 'Gilbert 허리케인의 영향과 강한 바람' 이라는 주제를 공유하므로 높은 유사도를 가짐
이러한 방식으로 TextRank는 문서 내의 중요 문장들을 효과적으로 추출할 수 있습니다.

- min-sim을 0.2로 둔다면 1과 23, 1과 24는 edge로 연결되지 않는다.

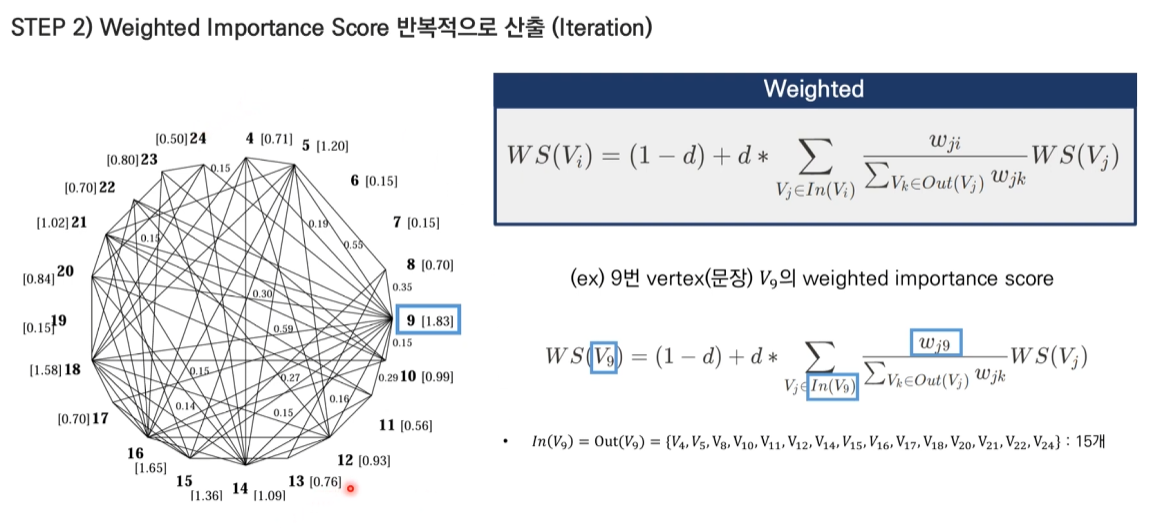

- 그래프 구조 분석:
이미지에서 9번 문장(V9)을 중심으로 설명하면:
- In(V9) = Out(V9) = {V4, V5, V8, V10, V11, V12, V14, V15, V16, V17, V18, V20, V21, V22, V24} (15개)
- 각 엣지에는 문장 간 유사도가 가중치(w)로 부여됨
- 가중치 예시 (9번 문장과 연결된 일부 문장들):
- w9,18 = 0.27 (높은 유사도: Gilbert, winds, coast 등 공통 단어 많음)
- w9,16 = 0.15 (중간 유사도: Gilbert 관련 내용)
- w9,15 = 0.14 (낮은 유사도: 위치 정보만 공유)
- Weighted Score 계산:
9번 문장의 score를 계산하는 과정:
WS(V9) = (1-0.85) + 0.85 * Σ(wj9 / Σwjk * WS(Vj))
= 0.15 + 0.85 * (
(w18,9 / Σw18,k * WS(V18)) +
(w16,9 / Σw16,k * WS(V16)) +
(w15,9 / Σw15,k * WS(V15)) +
... (다른 연결된 문장들)
)- WS(V18)는 18번 문장의 Weighted Score를 의미
- Σw18,k는 18번 문장(V18)에서 나가는 모든 엣지들의 weight 합
- 실제 값 대입:
- d = 0.85 (damping factor)
- 초기 WS 값은 모두 1로 시작
- 반복적으로 계산하여 최종적으로:
- WS(V9) = 1.83 (최고점)
- WS(V16) = 1.65 (2위)
- WS(V18) = 1.58 (3위)
- 최종 요약문 생성:
상위 점수를 받은 문장들이 선택됨: - 9번 문장: 허리케인 Gilbert의 접근과 시민 방위대의 경고
- 16번 문장: Gilbert의 이동 방향과 속도
- 18번 문장: Gilbert로 인한 구체적인 피해 상황
- 15번 문장: 허리케인의 정확한 위치 정보
이러한 결과가 나온 이유:
- 9번 문장: 문서의 핵심 내용을 포함하고 많은 문장과 높은 유사도
- 16번과 18번 문장: 허리케인의 상태와 영향을 구체적으로 설명
- 이들 문장이 서로 높은 유사도를 가지며 다른 문장들과도 잘 연결됨
이처럼 TextRank는 문장 간의 유사도를 바탕으로 중요한 문장들을 효과적으로 추출하여 문서의 핵심 내용을 요약할 수 있습니다.



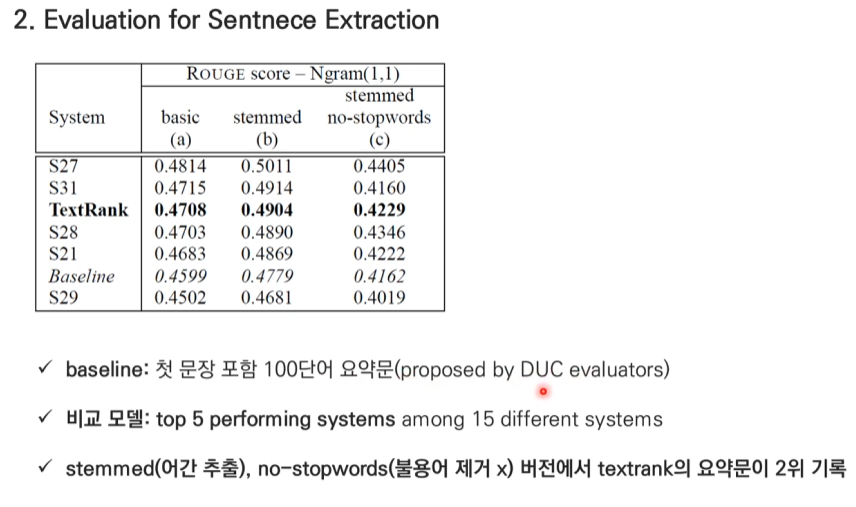
Rouge score의 계산 과정
예시 상황:
원본 요약문(사람이 작성): "자연어 처리 기술이 발전하면서 기계 번역의 성능이 향상되었다."
시스템 요약문: "자연어 처리 기술의 발전으로 기계 번역이 좋아졌다."- Unigram (1-gram) 계산:
원본 요약문 단어들: [자연어, 처리, 기술이, 발전하면서, 기계, 번역의, 성능이, 향상되었다]
시스템 요약문 단어들: [자연어, 처리, 기술의, 발전으로, 기계, 번역이, 좋아졌다]
일치하는 단어: 자연어, 처리, 기계, 번역
Unigram Recall = 일치 단어 수 / 원본 단어 수
= 4 / 8 = 0.5 (50%)- Bigram (2-gram) 계산:
원본 요약문 bigrams:
[자연어 처리], [처리 기술이], [기술이 발전하면서], [발전하면서 기계], [기계 번역의], [번역의 성능이], [성능이 향상되었다]
시스템 요약문 bigrams:
[자연어 처리], [처리 기술의], [기술의 발전으로], [발전으로 기계], [기계 번역이], [번역이 좋아졌다]
일치하는 bigrams: [자연어 처리]
Bigram Recall = 1 / 7 ≈ 0.143 (14.3%)이미지에서 보이는 가중치 적용:
최종 Rouge Score = (Unigram * 3/4) + (Bigram * 1/3)
= (0.5 * 0.75) + (0.143 * 0.333)
= 0.375 + 0.048
= 0.423실제 평가에서의 의미:
- Unigram이 높은 점수(0.5)를 받은 것은 기본적인 키워드들이 잘 보존되었음을 의미
- Bigram이 낮은 점수(0.143)를 받은 것은 문장 구조나 표현이 많이 달라졌음을 보여줌
- 가중치를 통해 Unigram에 더 중요도를 둠으로써, 핵심 내용 전달에 초점을 맞춤
다른 예시:
원본: "딥러닝 모델이 좋은 성능을 보였다"
시스템1: "딥러닝 모델의 성능이 우수했다" (높은 Rouge score)
시스템2: "인공지능이 잘 작동했다" (낮은 Rouge score)이런 방식으로 Rouge score는 시스템이 생성한 요약문이 원본 요약문의 내용을 얼마나 잘 보존하는지를 정량적으로 평가할 수 있게 해줍니다.