Exercise
Saliency map을 구하기 위해서 필요한 기본적인 구현 디테일을 익힘
Autograd: Automatic gradient API- 대부분의 DL library의 고유한 기능
- 행렬 연산 뿐만 아니라 Forward, backward pass 계산을 가능하게 해줌
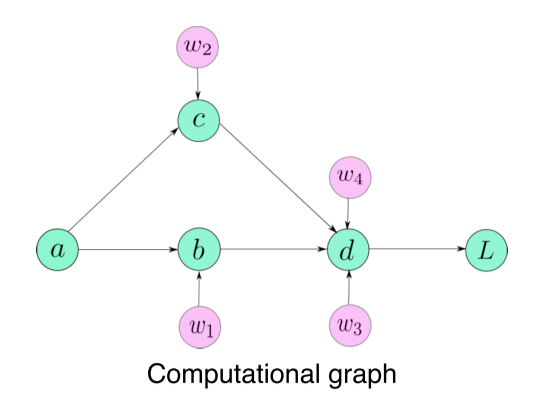
- Computational graph라는 구조를 이용해 automatic differentiation를 편하게 구현할 수 있도록 만듬
Computational graph: ~의 연산을 어떤 history(어떤 연산들, 연결성을 가지고 계산이 되었나)를 가지고 있었는지 계보를 기록
Autograd
x에 대한 y gradient를 계산하는 예제
x = torch.randn(2, requires_grad = True) # x는 2-dimension의 변수로 선언
y = x * 3 # y함수를 x에 대한 연산으로 정의
gradients = torch.tensor([100, 0.1], dtype = torch.float)
# y에 대한 backward를 콜하게 되면 y가 여태껏 계산되면서 저장해온 computation graph
# 즉, history 를 가지고 거꾸로 backpropagation을 하면서 나가는 것이다
# delta y/ delta ?, ? = y가 계산될때 사용했던 모든 변수들을 다 미리 계산해 놓을 수 있다
y.backward(gradients)
print(x.grad) # x.grad를 통해 delta y/ delta x 를 출력해준다
# y 함수를 보면 3이 나와야한다고 생각해야 하지만 아래와 같이 나온다
# 그 이유는 위에 y.backward() 함수 내에서 gradients라는 argument가 들어갔기 때문이다
# backward 안에 어떤 argument가 들어가게 되면 delta y/ delta ? 를 계산하는 것이 아니라
# argument가 곱해진 delta y/ delta ? 를 계산해준다
# tensor([300.0000, 0.3000]) - Backward 함수의 API는 × argument 의 형태
--> Chain rule을 사용하기 위해서! - 미분 행렬이 아닐 경우는 값을 안 넣어줘도 되고, default로 1이 들어감
requires_grad
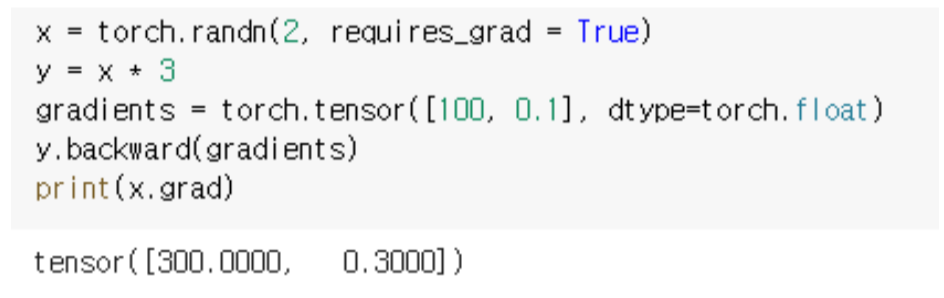
requires_grad = True는 x가 gradient를 저장할 수 있는 변수라고 선언
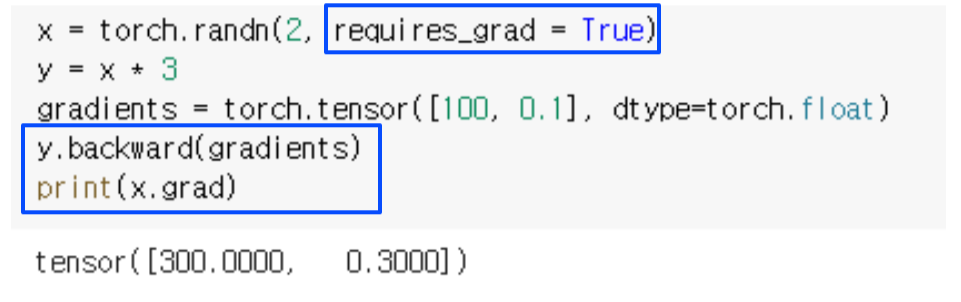
requires_grad = False로 선언하면 backward pass에서 오류 발생

-
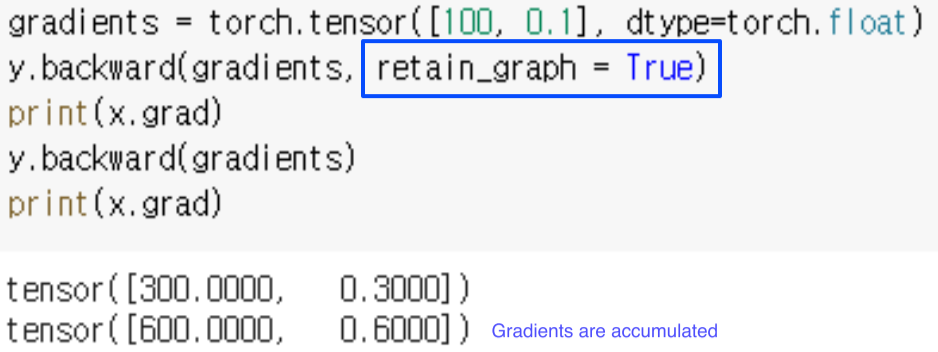
Resource 관리를 위해 한번 backward하면 computational graph를 release
-
retain_graph = True로 설정하면 backward를 호출하더라도 그래프가 사라지지 않고, 각 호출마다 gradient가 accumulate
-->zero_grad()로 gradient를 초기화
grad_fn
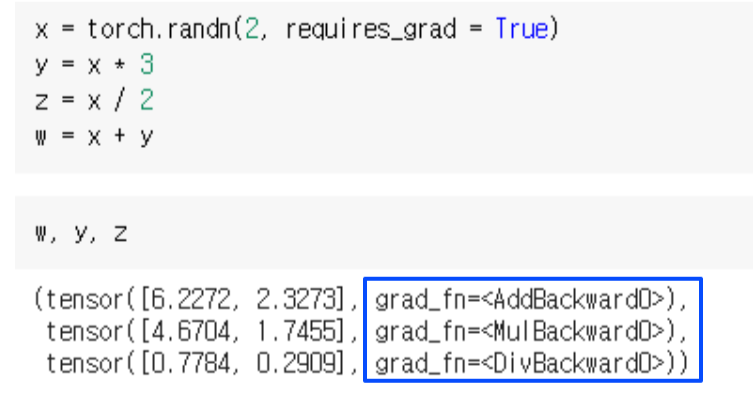
-
각 w, y, z 마다 computational graph를 갖고있고, graph에 쓰인 operation의 backward passs가
grad_fn에 등록돼있음 -
따라서 backward를 호출하면 grad_fn이 호출되면서 backpropagation이 이뤄짐
CAM, Class Activation Mapping
Hook
Hook: 어떤 function call을 했을때 두 개의 software component사이에 전달 되는 메세지를 intercept
Hook으로 model의 중간에서 gradient를 얻거나, 변경할 수 있음

- register_hook은 backward pass에서 전달되는 메세지를 가져오는 식
register_forward_hook

Hook function에 사용자가 하고싶은 동작을 선언
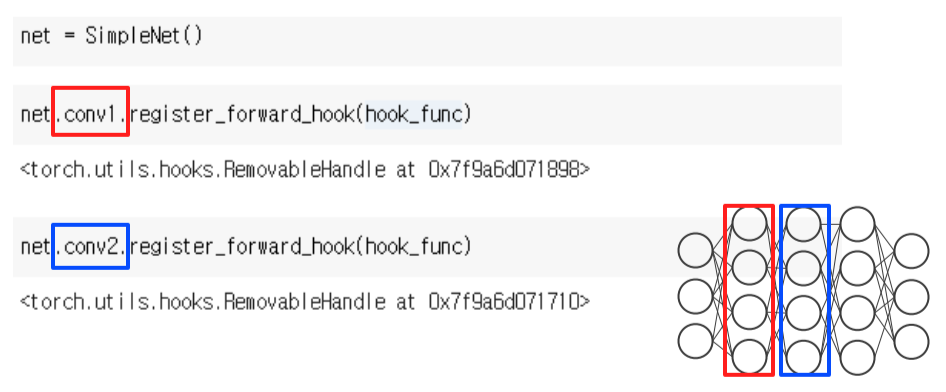
- 원하는 layer에 hook을 추가하고 run하면,

- 지정한 layer에서 hook이 실행되는 것을 확인할 수 있다
register_forward_pre_hook
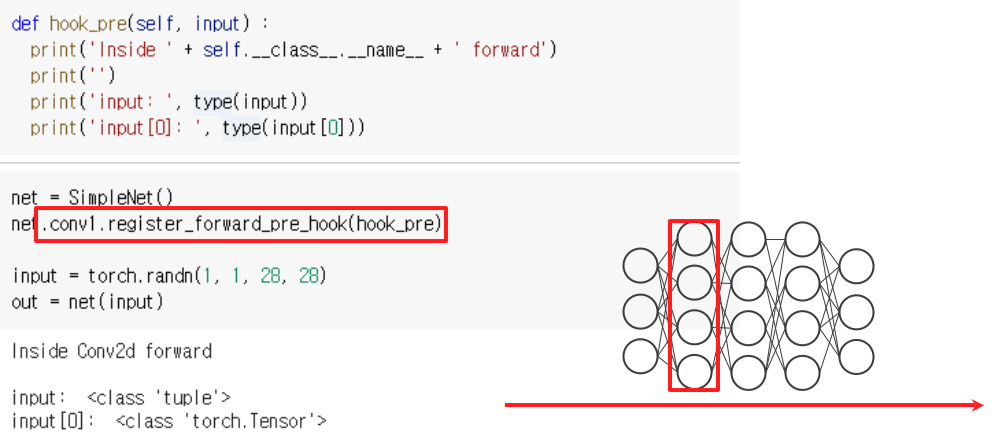
- With register_forward_pre_hook, hook_func gets executed before the forward pass
--> pre_hook이 발생하는 시점은 forward pass 하기 바로 직전
register_backward_hook
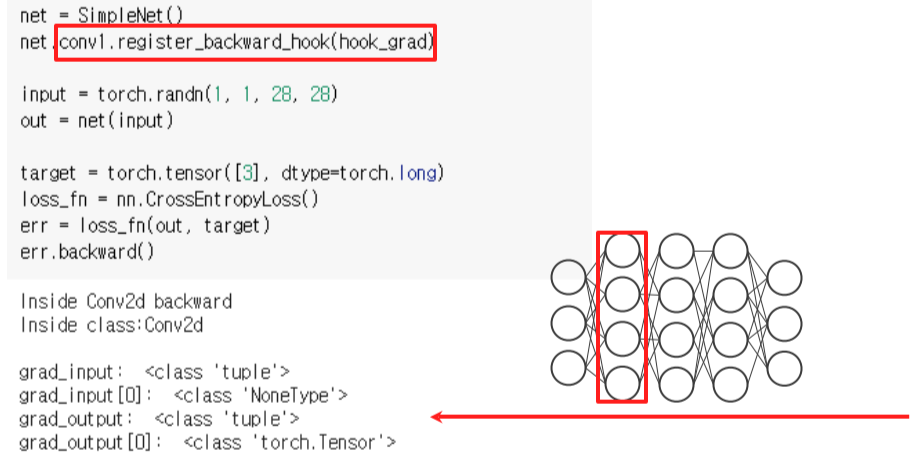
- hook_func gets executed when the gradients with respect to module inputs are computed
--> hook이 걸린 layer의 backpropagation이 실행되고, gradient가 나온 후 hook_func가 실행됨
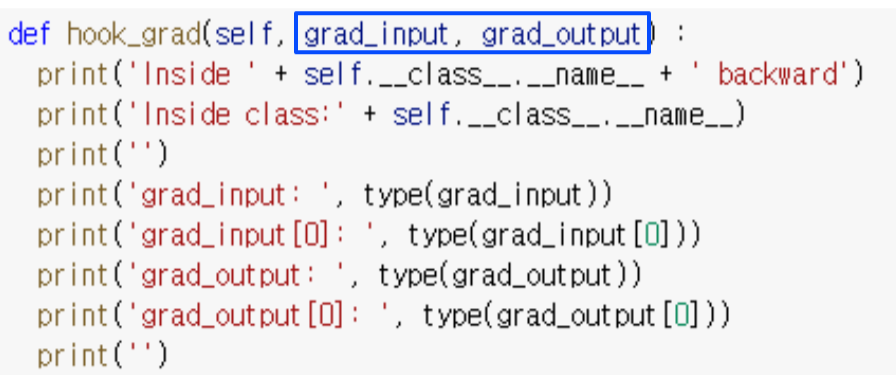
- hook의 return 값은 None or changed value
remove

- register hook을 호출할때 리턴값(위에선 h로 정의)을 받는데 이것을 handle 이라고 부른다
h.remove()로 hook 제거

즐겁게 개발하기