CNN 시각화
-
CNN은 non-linear activation function이 이어진 연산기
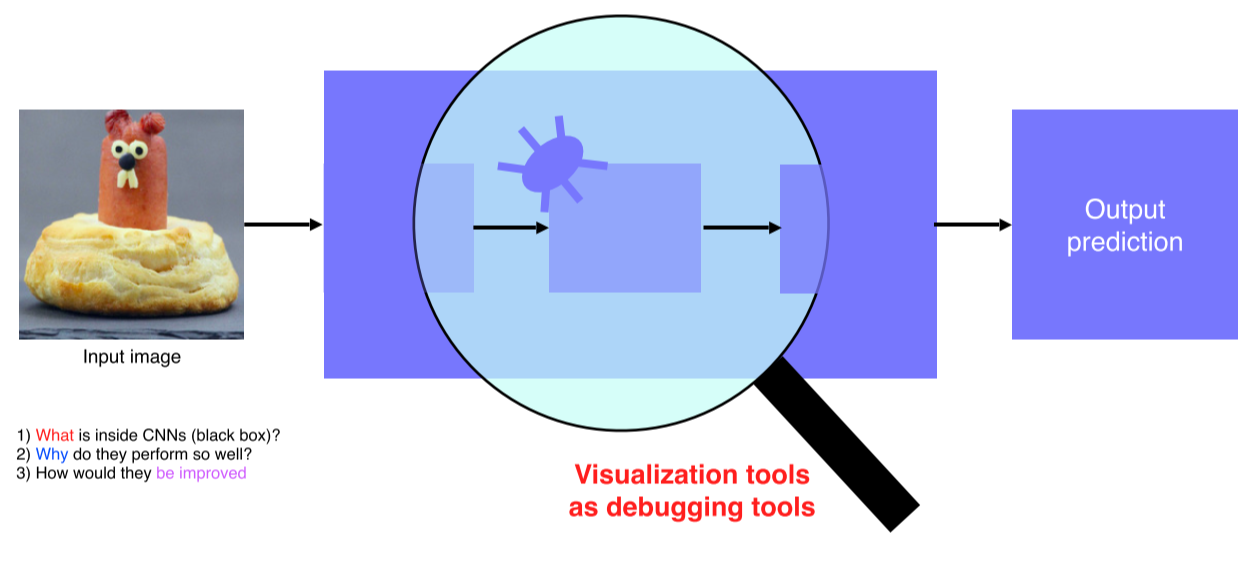
하지만 black box라고 불릴만큼 해석이 어려움 -
CNN을 시각화 한다는 것은 디버깅 도구를 갖는다는 것과 같은 의미
안에 뭐가 들어있고, 왜 좋은 성능이 나오고, 어떻게 개선할지를 알 수 있음
ZFNet
-
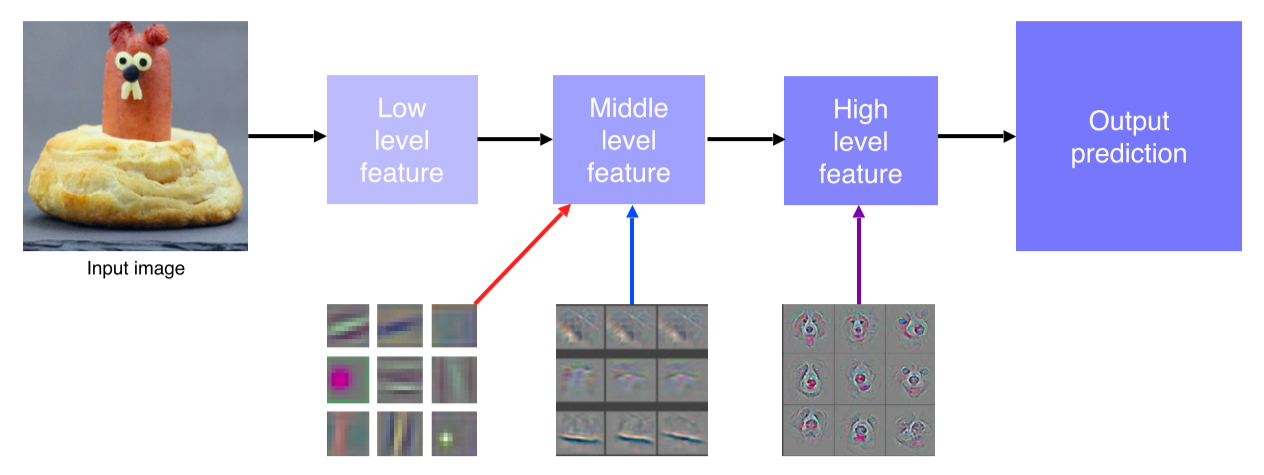
CNN layer들이 각 위치에 따라 어떤 지식을 습득하는지 deconvolution으로 시각화
-
낮은 단계에서는 edge나 block을 익히고, 높은 단계에서는 구체적인 정보를 익힘
-
ImageNet 2013에서 우승
Filter visualization
-
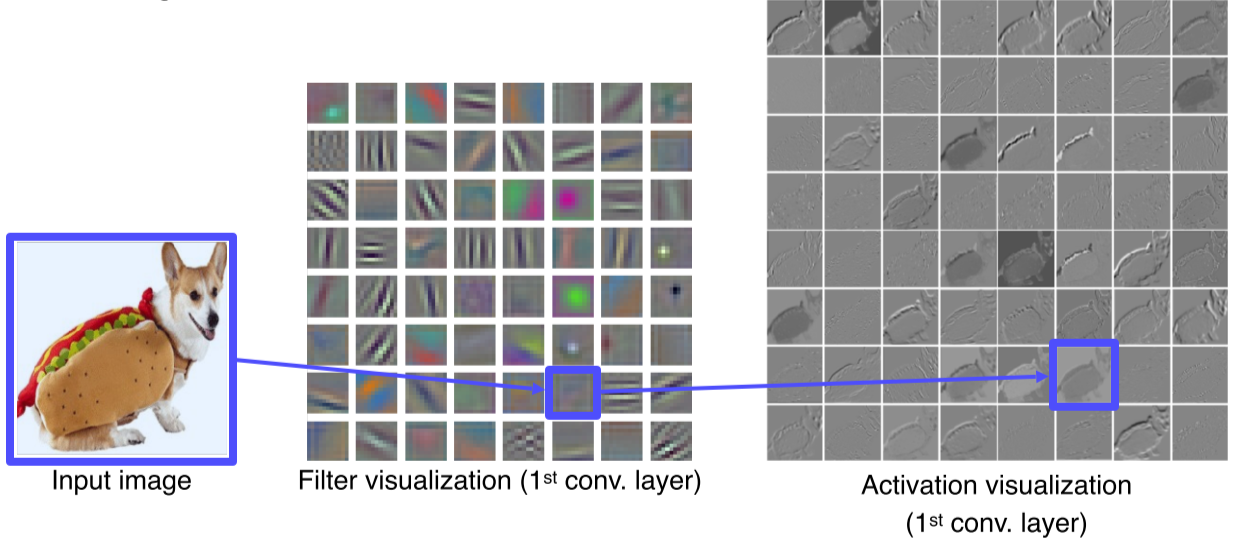
Filter visualization으로 CNN의 첫 layer가 어떤 특징에 집중하는지 알 수 있음
-
Low level feature는 시각화 할 수 있지만 그 이상 올라가면 channel 수가 커져서 visualization이 불가
How to visualize?
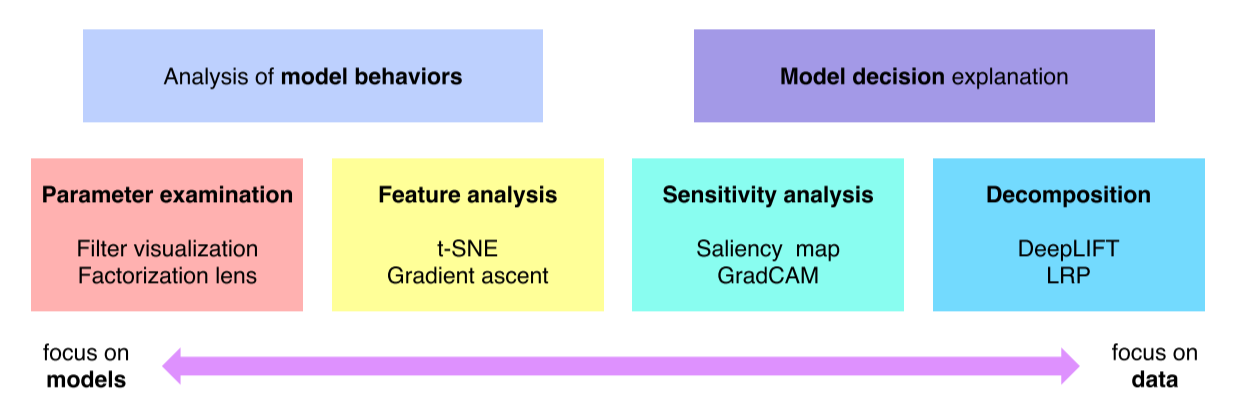
- 모델 자체의 특성을 분석하는 방법
- 하나의 입력 데이터에서부터 모델이 왜 그런 결과를 냈는지 출력을 분석하는 방법
Analysis of model behaviors
Embedding feature analysis
- High level layer를 해석하는 방법
1. Nearest neighbors in a feature space

-
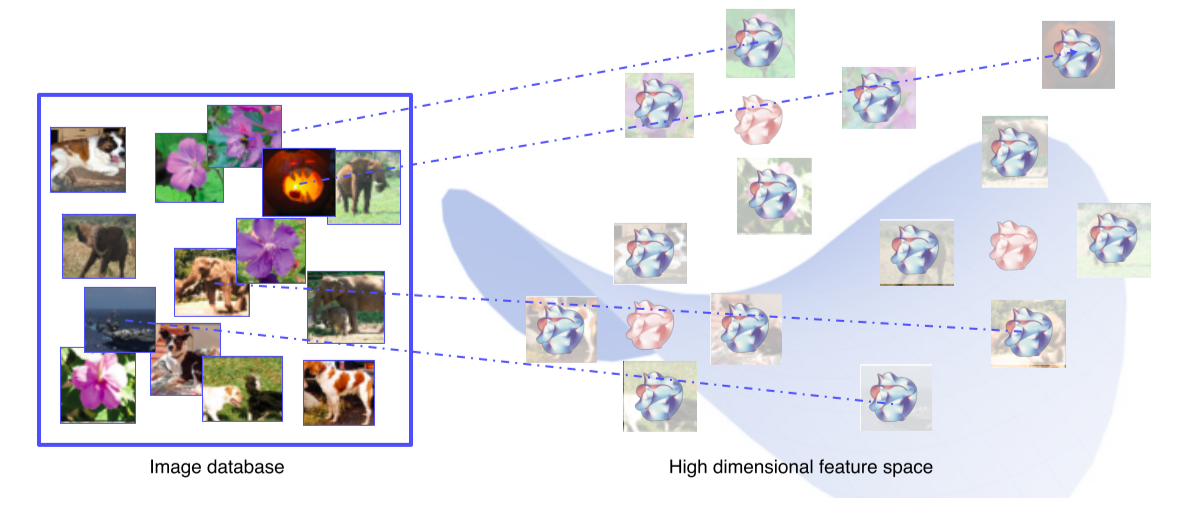
예제 영상을 통해 visualize 하는 방법
-
DB에는 분석을 위한 예제 dataset이 존재
-
Query image와 유사한 이웃 영상들을 DB에서 찾아 거리순으로 정렬
-
의미론적으로 유사한 영상들이 cluster 되어있음
-
하지만 검색된 예제를 통해서 분석하는 방법은 전체적인 그림을 파악하기 어려운 단점이 존재
-
NN에서 마지막 fc layer를 제거해 input image의 feature vector를 추출할 수 있게 만듬
-
DB의 모든 image들을 feature vector를 추출해 다시 DB에 저장
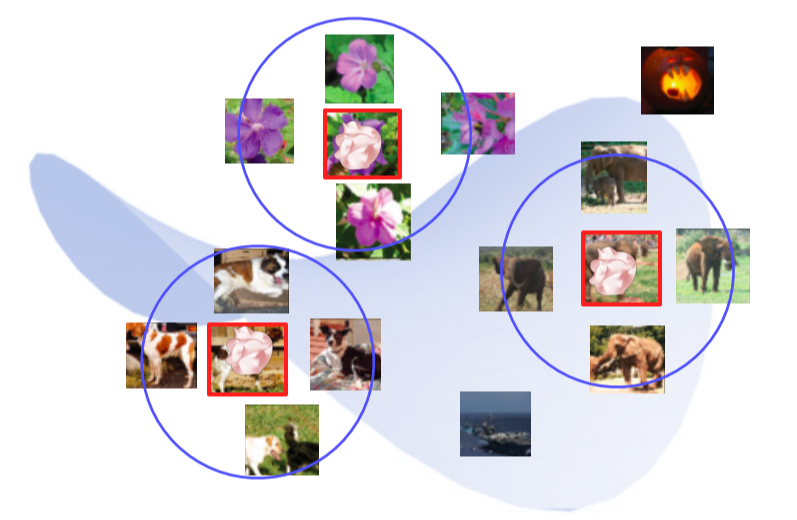
- Query image를 넣어 feature vector를 추출하고 그것과 근접한 거리에 있는 feature vector의 원본 image를 찾아 return
2. Dimensinality reduction
-
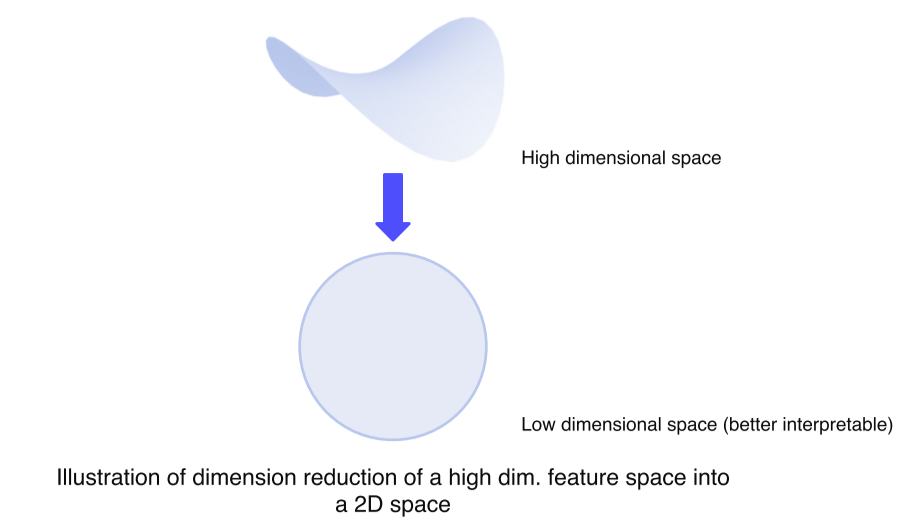
Backbone network을 활용해서 특징을 추출하게 되면 고차원 특징 벡터가 나오게 되는데 이것이 너무 고차원이라 해석하기 힘든 문제가 있다
-
이런 문제를 해결하기 위해서 고차원 벡터를 저차원으로 내려서 표현하는 방법 즉, 차원 축소 방법을 통해서 눈으로 쉽게 확인 가능한 분포를 얻어내는 방법을 소개
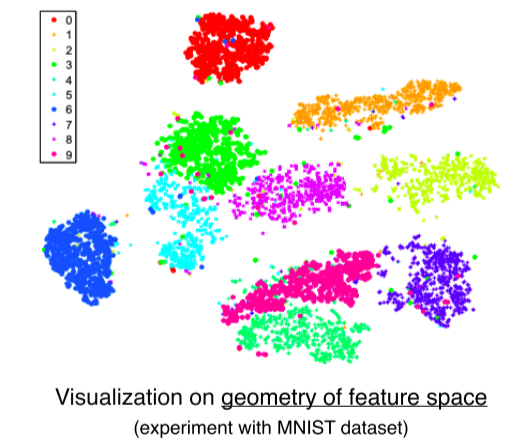
t-SNE: t-distributed stochastic neighbor embedding- High dimensional feature를 2차원 상에 각 클래스마다 다른 색으로 표현
- 몇몇 튀는 example들을 제외하곤 전반적으로 비슷한 클래스들 끼리 잘 분포되어 있다
- 클래스간의 분포도, 유사성을 거리를 기반으로 판단 가능
Activation investigation
Layer의 activation을 분석함으로써 모델의 특성을 파악하는 방법
1. Layer activation

- Mid, high layer의 activation을 해석

-
위 첫번째 행은 AlexNet에서 Conv5 layer의 138번째 채널의 activation을 적당한 값으로 threshoding 후 마스크로 만들어서 영상에 overlay 한 결과
-
각 activation의 채널이 어디를 중점적으로 바라보고 있는지 파악할 수 있음
-
CNN은 중간의 hidden node들이 손, 얼굴 등 부분을 detect하는 것을 다층적으로 쌓아서 물체를 인식한다는 것을 알 수 있음
2. Maximally activating patches

- Mid layer에 적용하는 방법

-
각 layer의 채널에서 하는 역할을 판단하기 위해서 그 hidden node에서 가장 높은 값을 갖는 위치의 patch를 출력
-
국부적 patch만을 보기 때문에 mid layer에 적합
- 분석하고 싶은 layer와 channel을 선택
- 예제 data를 backbone network에 넣어 각 layer의 activation을 얻음

- 해당 channel의 activation 중 가장 큰 값을 갖는 위치를 파악해 그 값을 도출해낸 receptive field를 찾아 출력
3. Class Visualization

- 각 클래스를 판단할때 이 네트워크는 어떤 모습을 상상하고 있는지 확인하는 방법

-
새 class에서는 새 모습들이, 개 class에서는 개 모습이 추출되는 것을 확인 가능
-
개 class에서는 개 뿐만 아니라 인간의 모습도 출력되고 있음
--> 1. 이 모델은 개를 파악하기 위해 해당 물체만 찾는게 아니라 주변의 사람 같은 모습도 찾고 있다
--> 2. Dataset이 가족적인 사진으로 biased 돼있다
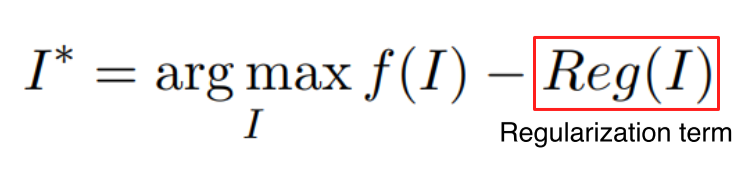
- Backpropagation으로 gradient ascent를 이용해 목적함수의 값을 최대화하면서 image를 학습
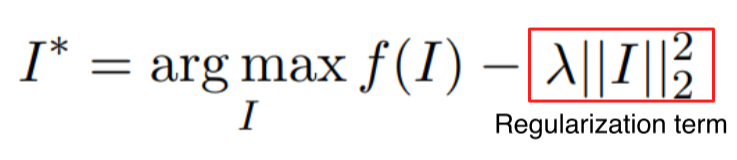
- : class에 대한 score
- : CNN 같은 backbone network
- : input
- : 입력 image의 L-2 norm
해석 가능한 형태(image)가 아닌 가 입력으로 들어왔을 때 의 값이 매우 커서 정답으로 분류하는 것을 방지
- 임의의 image를 넣어 관심있는 class의 score를 얻음
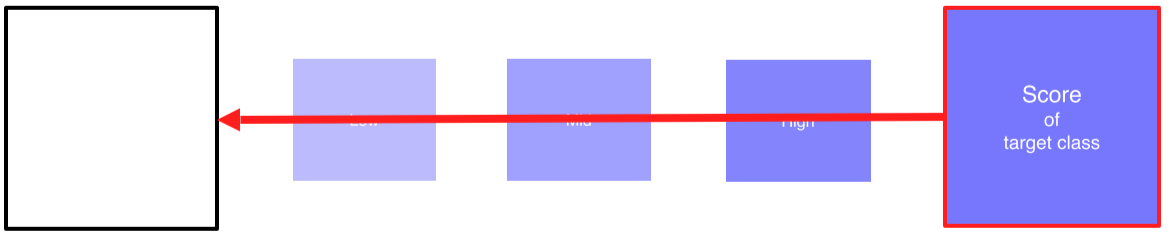
- Backpropgate로 입력이 어떻게 변해야 target class의 score가 높아지는지를 관찰
--> 기존의 CNN처럼 input을 고정시킨채 network를 바꿔서 score를 높이는게 아니라, network를 고정하고 input을 변경!!

- Gradient를 더하면서 update를 반복
Model decision explaination
모델이 특정 입력을 어떤 각도로 해석하고 있는지 분석하는 방법
Sailency test
1. Occlusion map
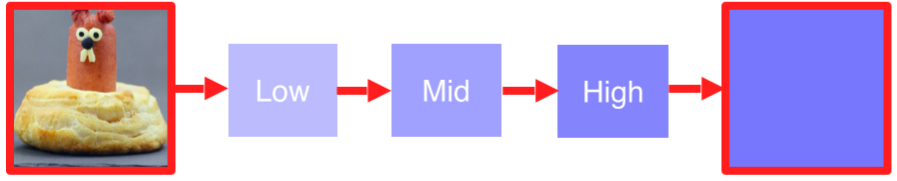
- 특정 image가 주어졌을 때, 그 image가 제대로 판정되기 위한 각 영역의 중요도를 추출
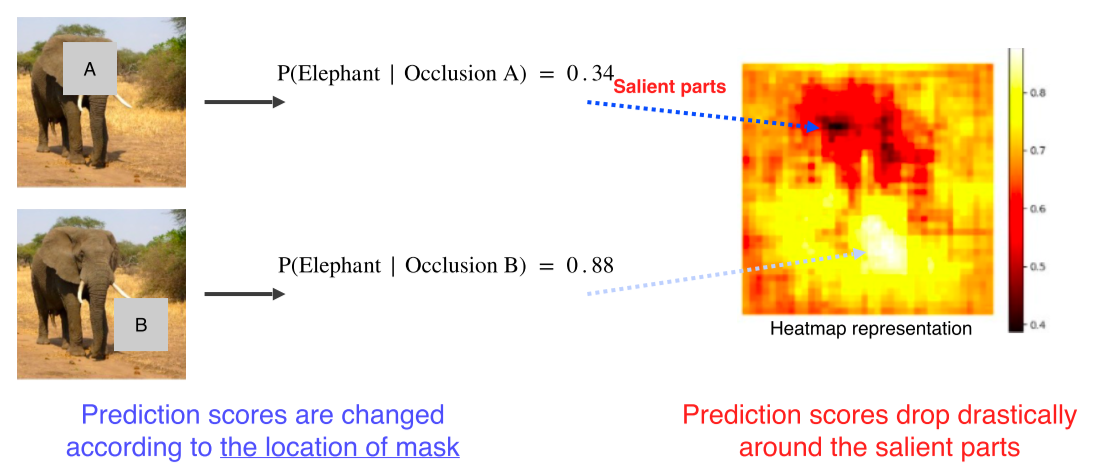
-
특정 영역을 occlusion 했을 때 전체 image를 정확한 class로 판별할 확률을 heatmap으로 만듬
-
진한 색일수록 class 검출에 중요한 영역이라는 것을 파악할 수 있음
2. via Backpropagation

- Gradient ascent를 이용해 분석 이미지를 생성했던 방법과 유사
임의의 image가 아니라 목표로 하는 image를 입력으로 넣는다는 점이 차이점

-
특정 이미지를 classification을 해보고 최종 결론이 나온 class에 결정적으로 영향을 미친 부분이 어디인지 heatmap 형태로 나타내는 기법
-
관심 물체 영역에 밝은 값이 분포
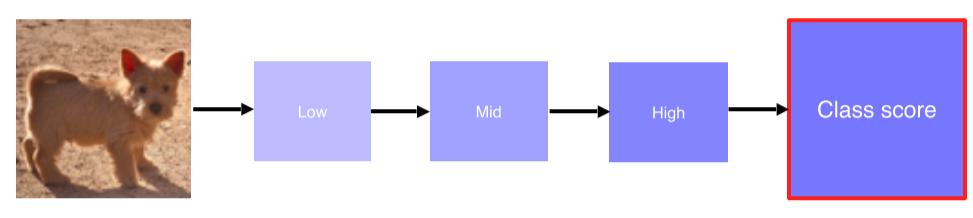
- 입력 image에 대한 class score를 구함
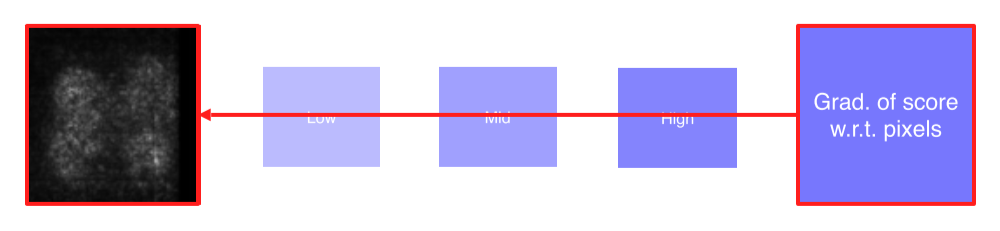
- Backpropagate로 gradient의 절댓값를 구함
gradient의 부호보다는 magnitude 자체가 중요한 정보기 때문에 절댓값이나 제곱을 사용
(Magnitude가 큰 부분이 input에서 바뀌어야 score도 변함, 민감한 영역)
- Gradient를 visualize해서 어떤 부분이 민감한지를 볼 수 있음
Backpropagate features
Rectified unit(backward pass)
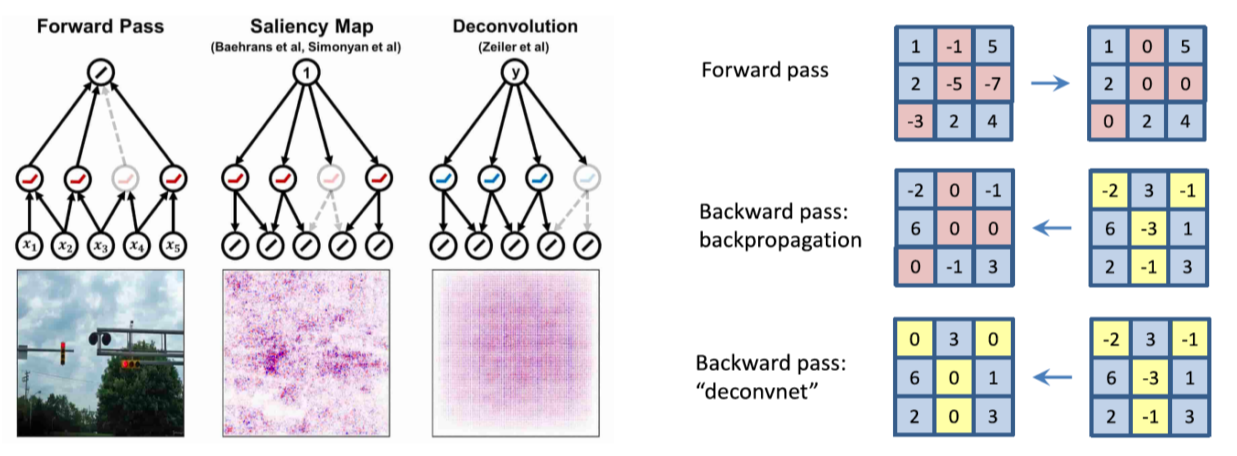
-
일반적으로 CNN에서 ReLU를 이용하면 forward에서 음수인 부분은 0으로 masking됨
-
Zeiler는 deconvolution된 activation이 backward로 내려올 때 gradient 자체에 ReLU를 적용

- 수식으로 표현한 그림
Guided backpropagation
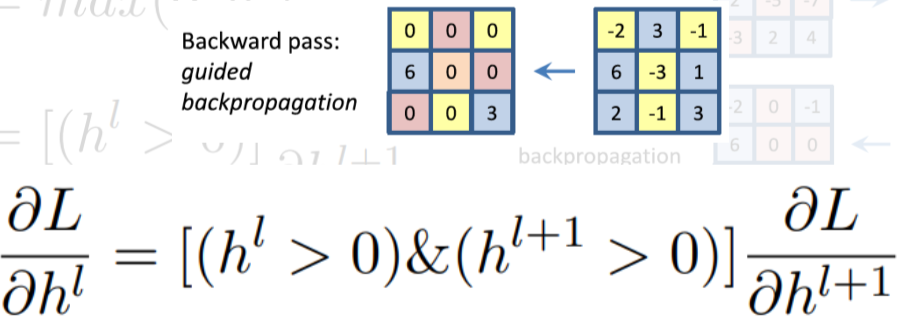
- forward, backward 모두 ReLU를 적용

- 수학적으로는 별다른 의미가 없지만 성능은 좋게 나옴
Class activation mapping
- 가장 유명하고 자주 사용되는 알고리즘

- 어떤 부분을 참고해서 결과가 나왔는지 heatmap으로 보여줌
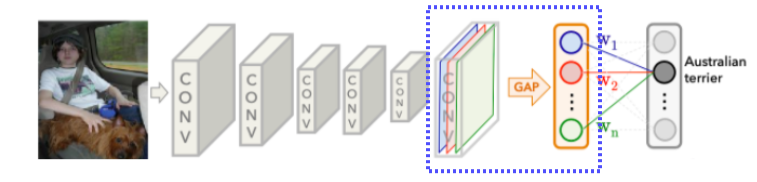
- Convolution의 결과로 나온 feature map을 FC layer가 아니라 GAP(global average pooling)을 통과하게 바꿈
- 그 다음에 최종 FC layer 1개만 통과해서 classify
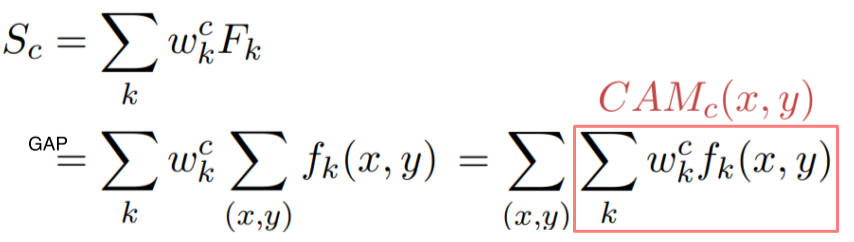
-
: Convolution layer의 output인, convolution map(혹은 feature map)의 channel 수
-
: FC layer에서 class 에 해당하는 weight
class 에서 의 중요도를 나타냄 -
: conv map의 k번째 channel에서 (x, y)좌표 pixel의 값
-
: conv map의 k번째 channel의 모든 pixel을 GAP한 값(node)
-
: weight 와 feature 의 linear combination
class C에 대한 score -
: (x, y) 좌표의 pixel의 class 에 대한 중요도
(input이 c로 분류되는데 해당 pixel이 얼마나 영향을 미치는지)
GAP을 적용하기 전이기 때문에 공간에 대한 정보(width , height )가 남아있음 --> image처럼 visualization이 가능
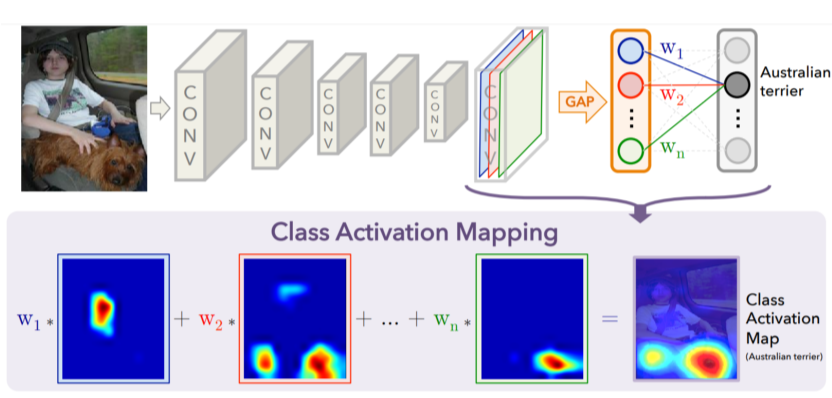
- 는 공간정보가 남아있기 때문에 heatmap 형태로 visaulization이 가능
- 위 사진에서 각 heatmap은 feature map의 각 channel을 의미
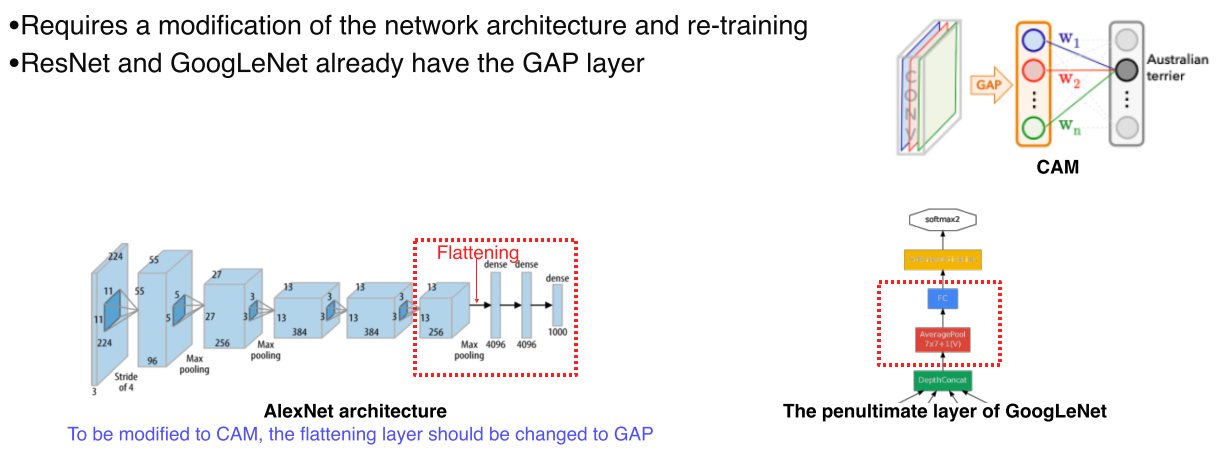
-
일부 model에서는 CAM을 사용하기 위해선 architecture를 바꾼 후 재학습을 해야된다는 점이 단점
--> 성능이 떨어지거나 parameter tuning이 다시 필요함 -
GoogLeNet 같은 경우는 마지막에 AveragePooling, FC layer가 있기 때문에 CAM을 적용하기 쉬움
-
참고: https://mole-starseeker.tistory.com/m/66?category=859657
https://kangbk0120.github.io/articles/2018-02/cam
--> 코드도 있음!
GAP, Global Average Pooling
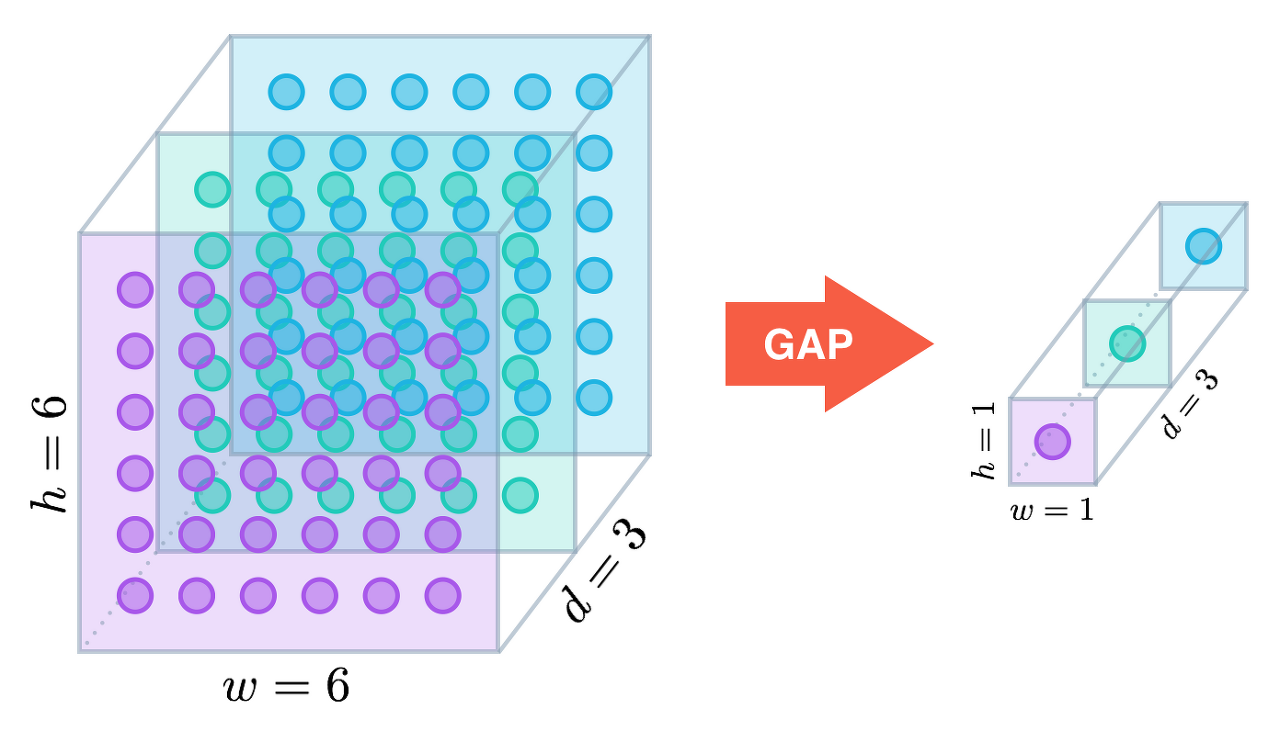
- 공간 정보가 FC layer보다는 덜 날아감 == channel이 남아있기 때문에???, 하지만 width, height가 날아가기 때문에 손실되는것 자체는 맞다
- GAP는 어떤 크기의 feature 라도 같은 채널의 값들을 하나의 평균 값으로 대체하기 때문에 벡터가 된다.
- 따라서 어떤 사이즈의 입력이 들어와도 상관이 없고, 단순히 (H, W, C) → (1, 1, C) 크기로 줄어드는 연산이므로 파라미터가 추가되지 않으므로 학습 측면에서도 유리
- 또한 파라미터의 갯수가 FC Layer 만큼 폭발적으로 증가하지 않아서 over fitting 측면에서도 유리
- 따라서 GAP 연산 결과 1차원 벡터가 되기 때문에 최종 출력에 FC Layer 대신 사용할 수 있음
- 경우에 따라서 FC layer와 같이 사용 되기도 함
FC layer에 전달하기 전에 GAP를 이용하여 차원을 줄여서 벡터로 만든 다음에 FC layer로 전달 하면 FC Layer에서 쉽게 사이즈를 맞출 수 있기 때문
- GAP이 공간정보가 유지된다고 하는 이유??
- GAP를 쓰면 사상(embedding)된 특징 공간에서 이미지의 특정 영역이 response 되고, 이를 class activation map으로 시각화 함으로써 확인할 수 있기 때문입니다.
- 더 자세히 말하면, GAP 연산은 채널 별로 평균을 낼 뿐이고, 평균을 통해 얻은 클래스 개수만큼의 1차원 벡터와 클래스 라벨로 loss를 계산해 업데이트 했을 때, GAP 연산의 결과가 아닌 GAP 연산을 거치기 전의 컨볼루션 필터(커널)들을 학습시킵니다.
- 이때 역전파를 통해 loss를 업데이트하면서 해당 컨볼루션 필터들은 이미지의 특징을 더 잘 잡도록 훈련될 것이며, 그 부분이 response가 됩니다.
- 이 response 덕에 GAP 연산을 적용하면 FC Layer에 비해 location 정보를 상대적으로 덜 잃는 것으로 볼 수 있습니다.
- 참고: https://gaussian37.github.io/dl-concept-global_average_pooling/
https://mole-starseeker.tistory.com/m/66?category=859657
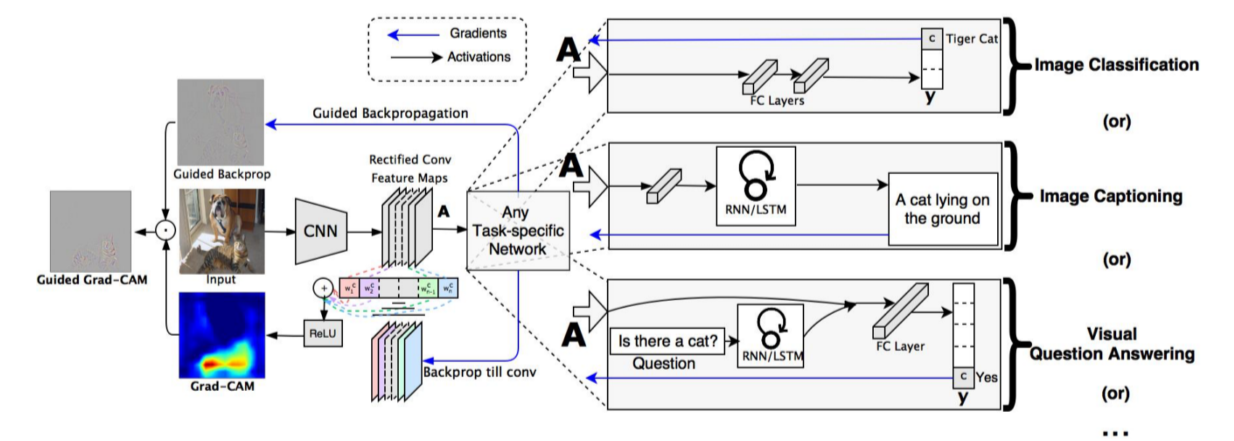
Grad-CAM

-
Pre-trained network를 변경하지 않고 사용할 수 있음
-
Model을 변경할 필요가 없기 때문에 image task에만 국한되지 않고 backbone이 CNN이기만 하면 사용 가능
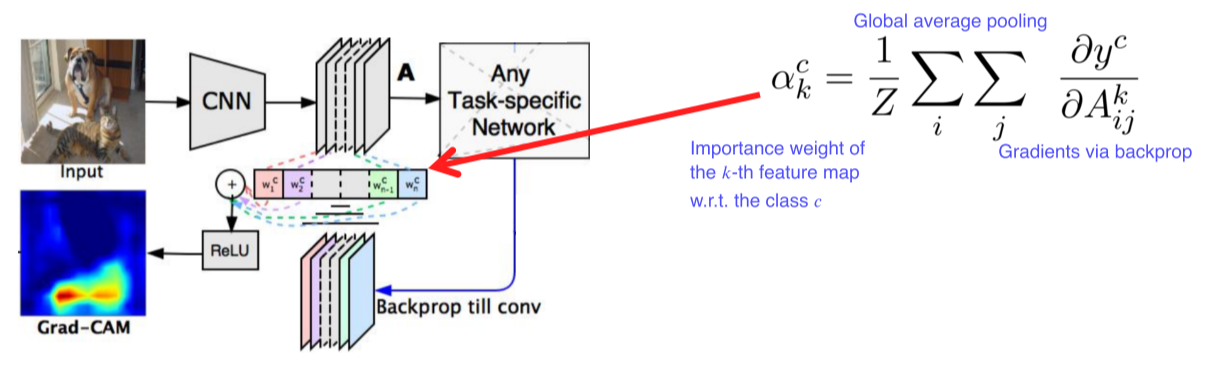
- Input image까지가 아니라 activation map(conv layer)까지만 backpropagate함
- : 현재 class의 score
- : 현재 class의 weight
score를 미분 후 공간축으로 GAP해서 각 channel의 gradient 크기를 구함
Activation map을 결합하기 위한 weight로 사용
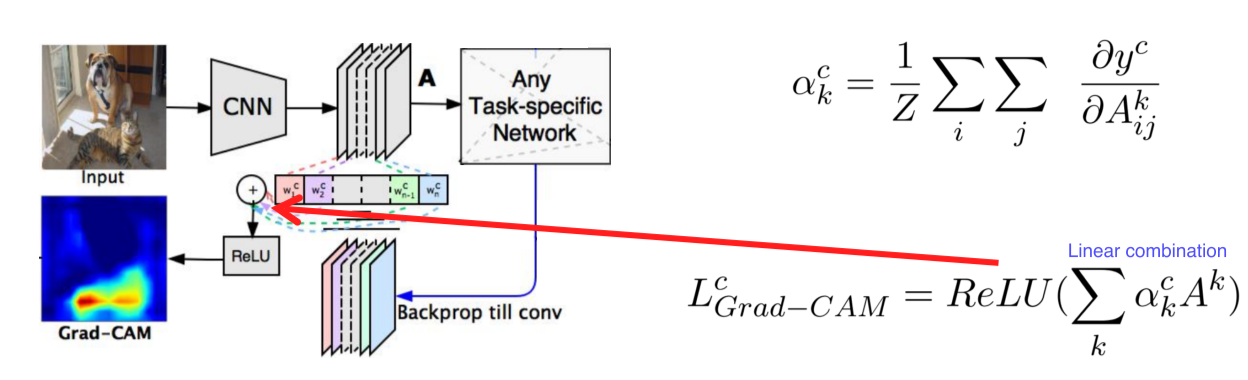
- 과 을 선형결합 후 ReLU를 적용해 양수값을 사용
-
CNN backbone 외엔 별다른 요구사항이 없기 때문에 classification, RNN 등 여러 task에 적용할 수 있는 일반화된 도구
-
Grad-CAM은 rough, smooth, class에 민감하고 Guided Backprop은 sharp, sensitive, high frequency하기 때문에 둘의 결과를 곱해서 특정 class에 대한 texture만 알아낼 수 있음
SCOUTER

- 요즘에는 Grad-CAM을 개선해서 class를 판별할 뿐만 아니라 어딜 보고 해석했는지, 왜 다른 class는 아닌지에 대한 정보도 얻을 수 있음
Conclusion

- Hidden node가 어느 부분을 담당하는지 알면 GAN 같은 생성모델에도 이용할 수 있다
- 이렇듯 해석 방법을 알면 이를 응용할 수도 있어야 함
Reference

Further Study
(1) 왜 filter visualization에서 주로 첫번째 convolutional layer를 목표로할까요?
(2) Occlusion map에서 heatmap이 의미하는 바가 무엇인가요?
(3) Grad-CAM에서 linear combination의 결과를 ReLU layer를 거치는 이유가 무엇인가요?
