Conditional generative model
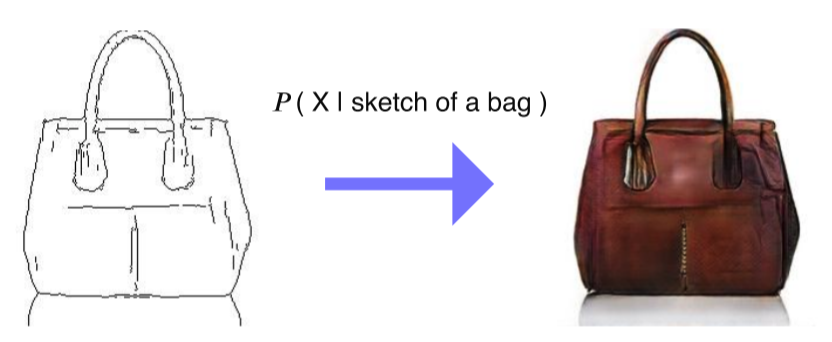
- Condition이 주어졌을 때, 조건에 해당하는 결과가 나오는 형태

-
기존 generative model은 image나 sample을 생성할 수는 있지만, 조작은 할 수 없었음
-
Conditional generative model은 user의 의도를 반영해 응용 가능성을 높임
Example
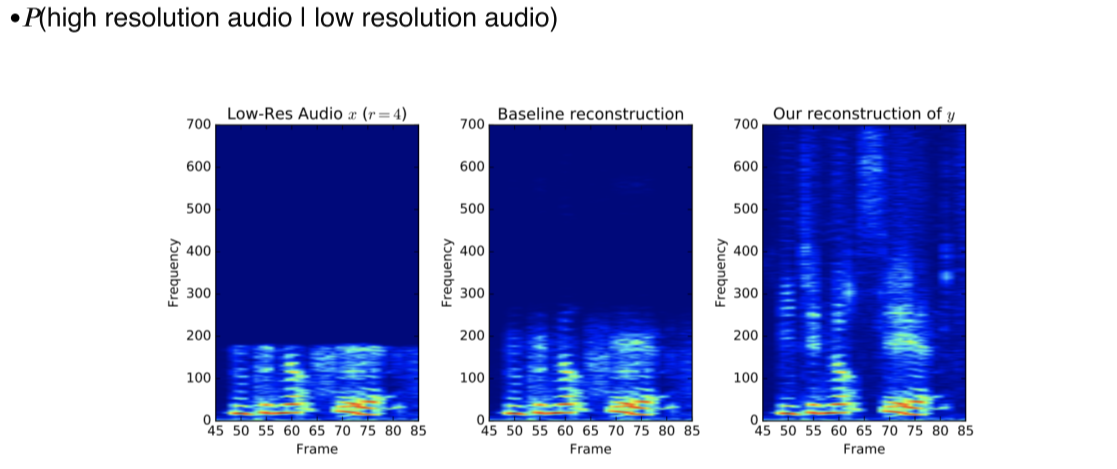
- Audio super resolution, 오디오의 퀄리티를 높임
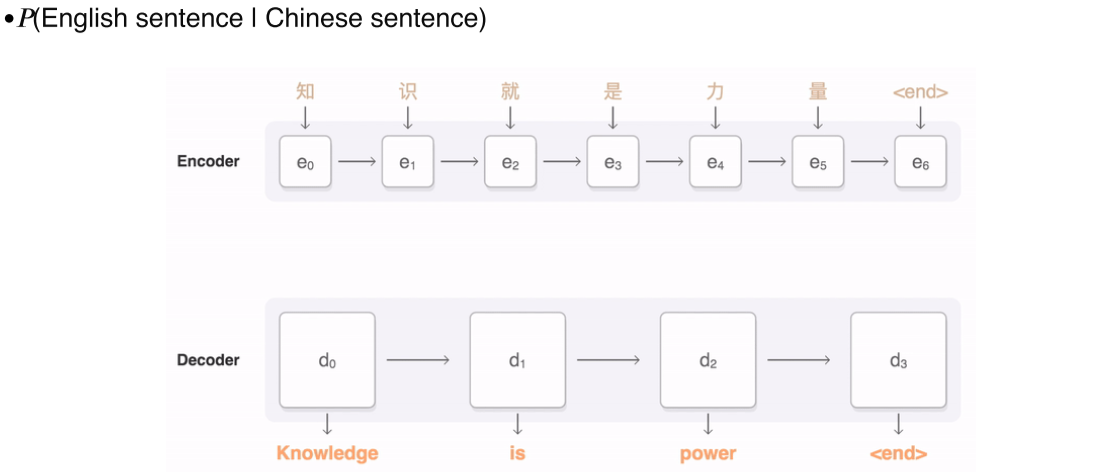
- Machine translation

- Article generation
GAN vs Conditional GAN
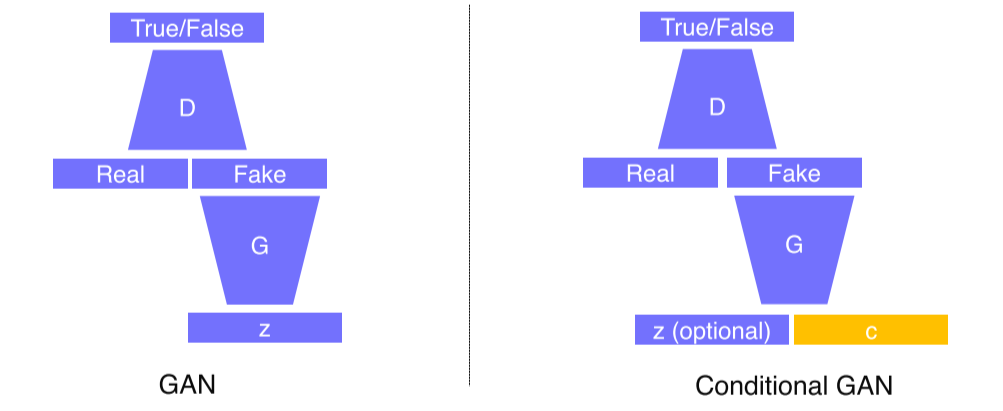
-
GAN: Generator의 입력으로 random vector z를 넣고, fake data가 생성되면 discriminator로 판별
-
Conditional GAN: Input으로 conditional input c를 넣음
Conditional GAN and image translation

- Image의 화풍이나 해상도를 변경 가능
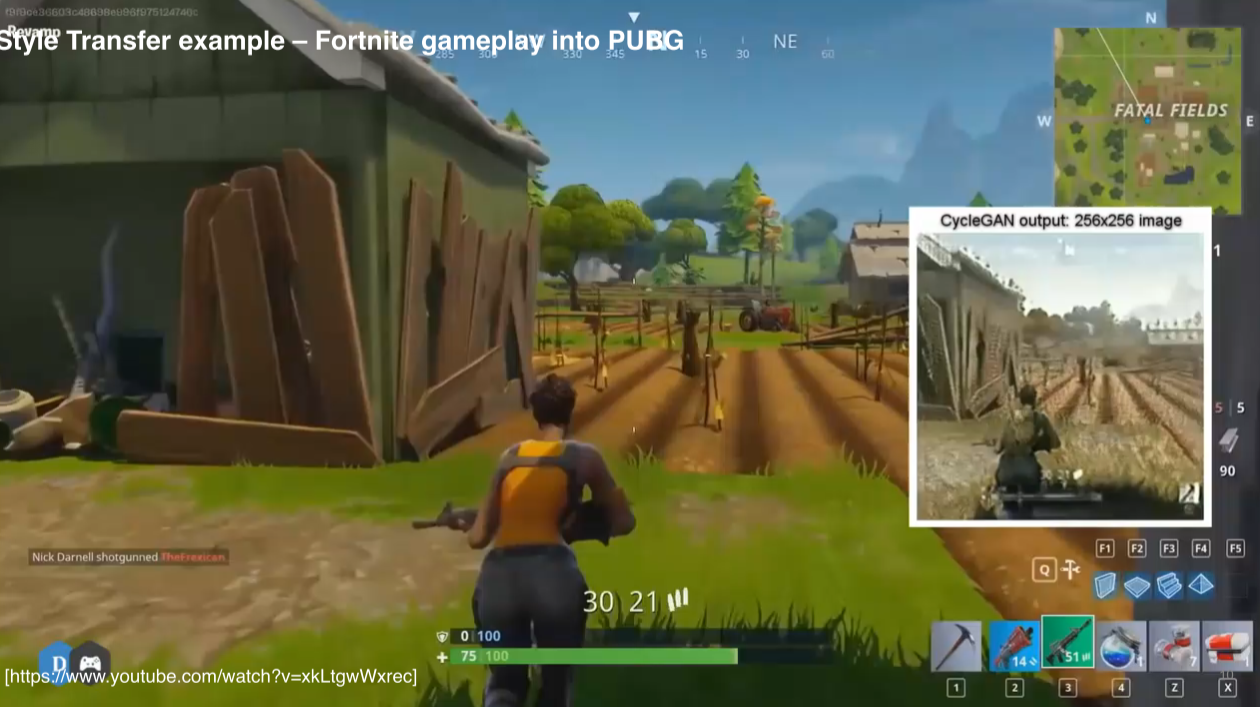
- 한 게임 화면을 다른 게임처럼 변경하는 것도 가능
Exmaple: Super resolution
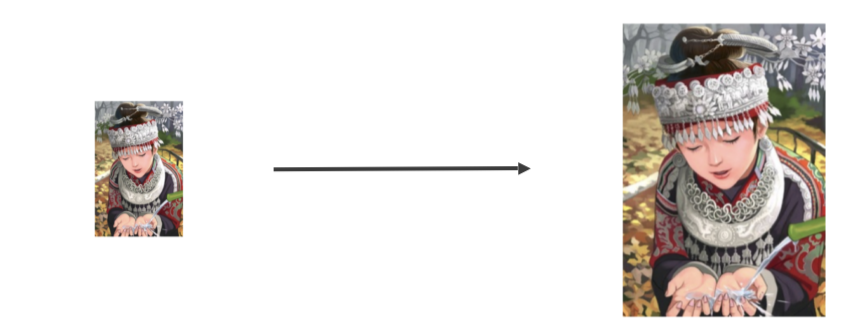
- 저해상도 -> 고해상도
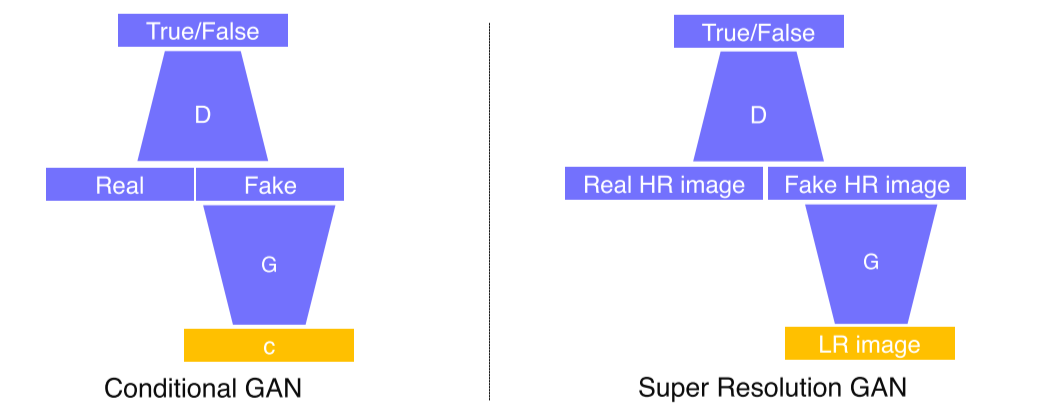
- Low resolution을 입력해서 Fake high resolution image를 만들고, real data로 real high resolution image를 줘서
가짜 hr image가 실제 hr image와 비슷한 통계적 특성을 지니는지 판별
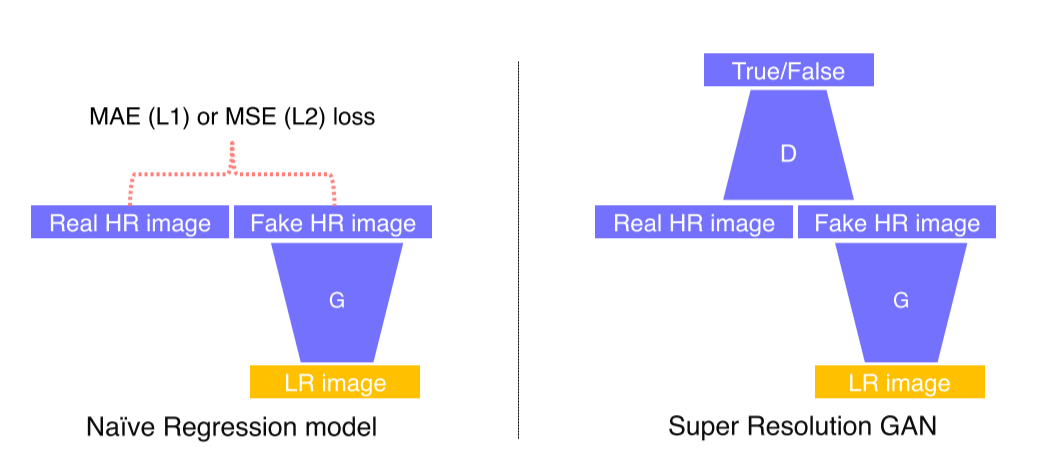
- 이전까지는 단순히 L1, L2 loss를 사용했음 -> Regression model
-
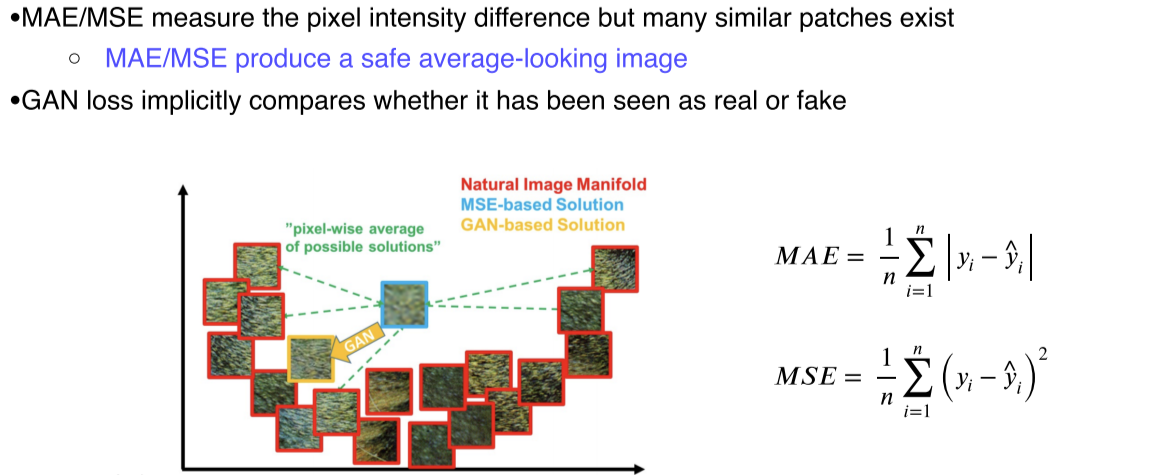
MAE(L1), MLE(L2)를 사용하면 높은 해상도에서 blur image를 얻게됨
--> 평균 error를 구하다보니 출력 결과와 비슷한 error를 갖는 많은 patch들이 존재
--> 모든 입력과 적당히 비슷한, 안전한 output을 만들게됨 -
GAN은 real data와 구분을 못하게 하는 것이 목적이므로 가장 가까운 real data와 더 닮게 함으로써 loss를 낮춤
- L1 loss: 두 real image에 대해 모두 loss를 낮추는 중간값을 선택
- GAN: Discriminator가 real data 중 비슷한게 있는지 판별하기 때문에 real data에 가까워짐

- MSE loss를 사용한 SRResNet보다 SRGAN이 훨씬 sharp한 output
Image translation GANs
Pix2Pix
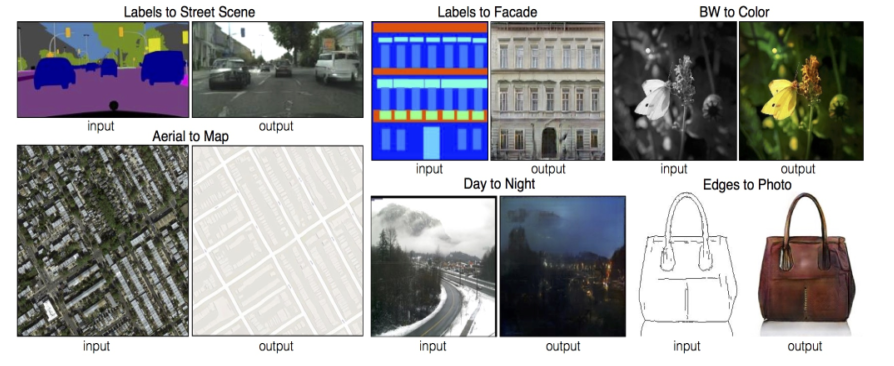
-
한 image의 domain을 다른 domain으로 translate하는 task
-
Pix2Pix: Image translation task를 CNN 구조를 이용해 학습기반으로 처음 정리한 연구
-
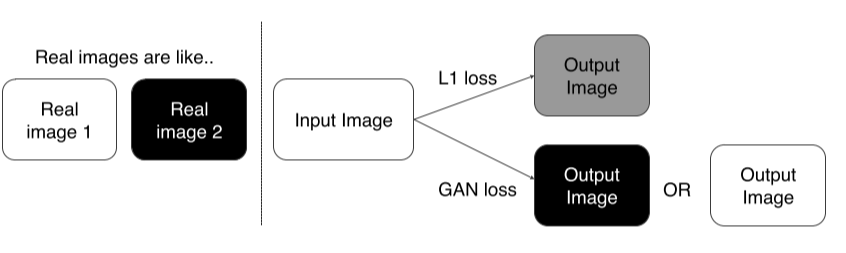
L1 loss: blurry output을 만들지만 적당한 guide로 쓰기엔 좋음
(GAN만 쓰면 학습이 불안정) -
GAN loss: realistic output을 만듬
-
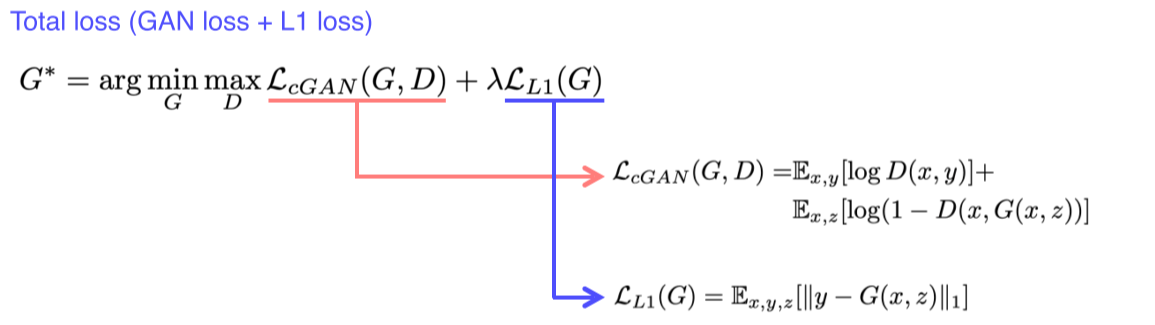
L1 loss는 input 를 ground truth 에 대해 학습하기 때문에 (supervised learning),
GAN loss만 사용할 때엔 real/fake만 판별하기 때문에 y에 대해 학습하지 못한다는 단점을 개선

-
L1만 쓰면 blurry하고, GAN만 쓰면 GT와 다른 스타일의 output이 나오는 것을 확인 가능
-
L2는 어중간한 색상을 선택해 안전한(어느 input에도 loss가 적절히 작은) 선택을 하는 것을 확인 가능
CycleGAN
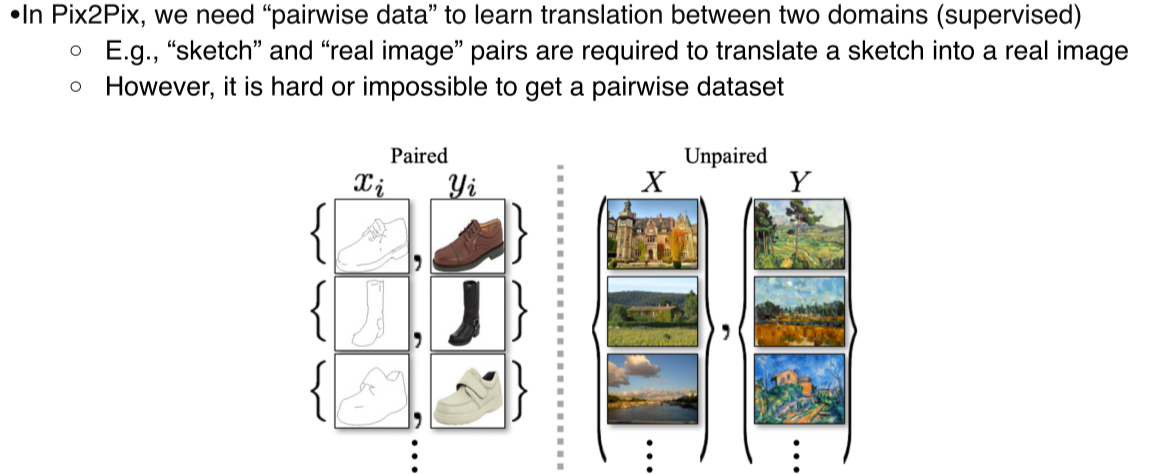
- Pix2Pix는 의 pairwise data를 얻기 어렵다는 것이 단점

- CycleGAN은 1:1 대응하는 data가 아니라 dataset만 있어도 활용할 수 있게함

-
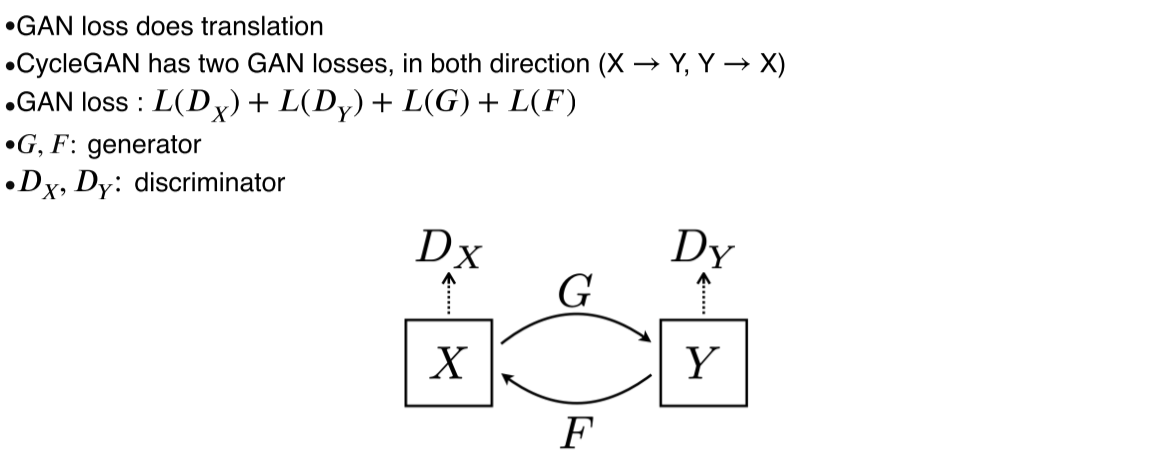
GAN loss: 방향성이 존재
-
CycleGAN loss: image가 translation을 forward/backward로 거쳤을 때 원본 image와 동일해야함
-
가 에서 를 만들면 실제 데이터셋과 비슷한 스타일을 갖는지 로 판별
-
가 다른 NN 로 를 만들면 다시 실제 데이터셋과 비슷한 스타일을 갖는지 로 판별
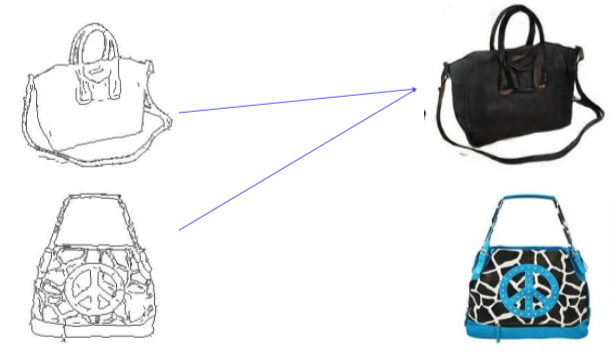
- 하지만 GAN loss만 계속 사용하면 input에 관계없이 하나의 realistic한 output만 출력하는 Mode Collapse가 발생
(input과 다르긴 한데 realistic 하니까 GAN에서는 잘하고 있다고 판단하고 더 이상 학습하지 않음)
-
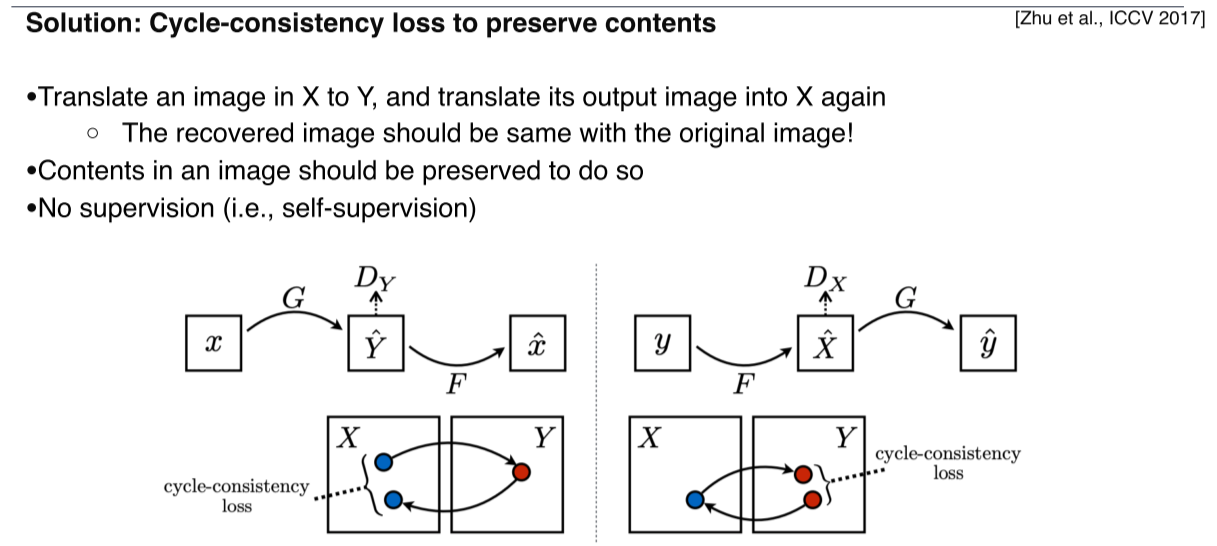
Cycle-consistency loss: style 뿐만 아니라 content도 유지
-
/ 에서 원본 data가 유지돼야함
-
Loss를 계산할 때 어떤 supervision도 들어가지 않기 때문에 self-supervision
Perceptual loss
GAN loss가 복잡해서 다른 방법으로 high-quality image를 얻기 위해 사용
Perceltual loss를 사용하면 GAN과 같이 복잡한 연산을 하지 않더라도 쉽게 image translation, style transfer 할 수 있음
예시)


- GAN loss(Adversarial loss)
- Generator, discriminator가 서로 경쟁하면서 학습해야하기 때문에 복잡하다는 단점이 존재
- Pre-trained network가 필요하지 않다는 장점
- Application에 상관없이 data만 주어지면 사용 가능하다는 장점
--> Data-dependency가 단점이 될 수도 있음
- Perceptual loss
- 일반적인 NN을 train하듯 forward & backward computation으로 사용 가능
- Pre-trained network가 필요

-
Pre-trained의 early network filter들이 human perception의 방법과 닮아있다는 점에서 착안
-
Pre-trained filter가 image를 인간이 세상을 바라보는 방법과 비슷하게 perceptual space로 변환하는 transformer 역할을 할 수 있다
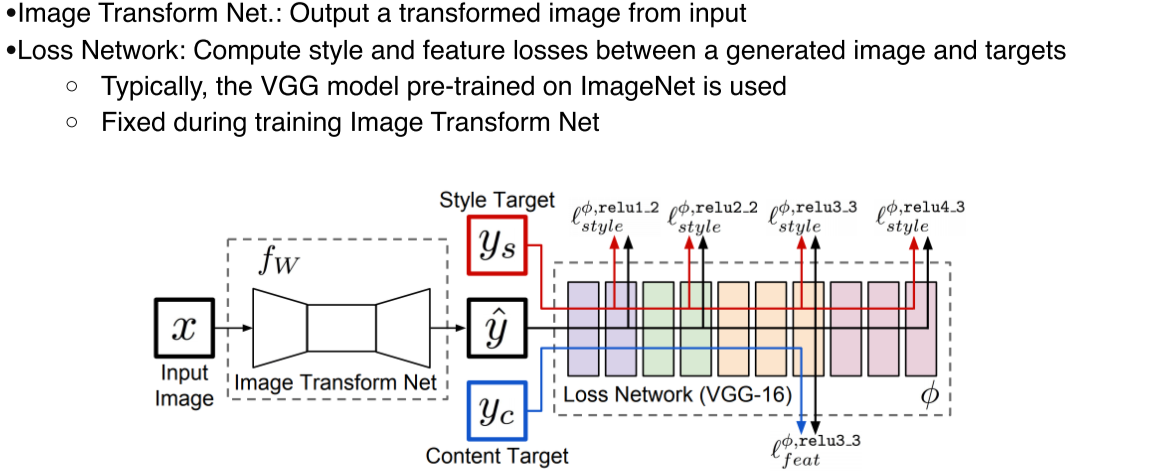
-
Image Transform Net: Input image를 원하는 1개의 style로 transform -
Loss network(VGG-16): 학습될 loss를 측정, feature(activation)를 추출
Networks는 pre-trained model을 사용, fixed라 학습되지 않음
Backpropagation에서 학습되는건 Image transform network뿐
Feature reconstruction loss
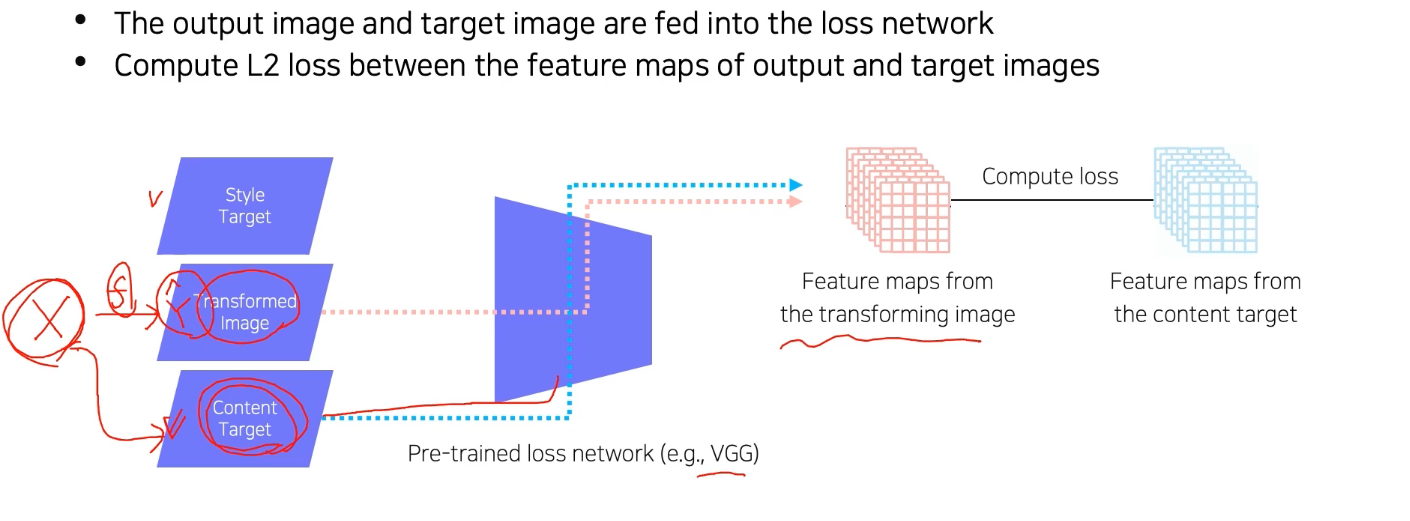
Feature reconstruction loss: transformed image 가 content target 를 잘 유지하고 있는지 판단
Style reconstruction loss
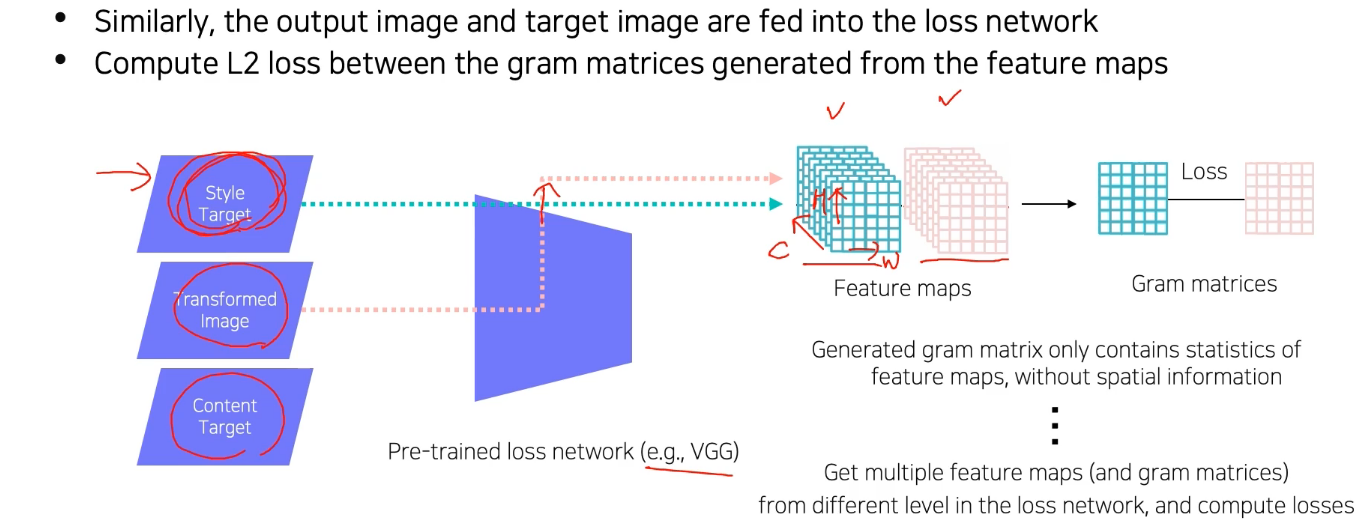
-
Style reconstruction loss: 원본의 style을 잘 유지하고 있는지 판단 -
Pre-trained loss network에서 convolution feature map을 출력하기 때문에 feature map은 tensor 형태로 나옴
-
Style 비교를 위해 feature map을 바로 비교하지 않고 gram matrix를 만들어서 비교
Gram matrix: Feature map의 spatial information이 없는 통계적 특징을 담기 위해 생성
Style은 특정 공간에 대한 feature가 아니라 전반적인 경향성이기 때문!
-
하나의 convolution layer에서만 gram matrix를 뽑는게 아니라 중간중간 channel에서 다 뽑아서 서로 다른 level에서 style loss를 내적
-
결국 transformed image의 gradient는 style target의 channel 간의 correlation(statistics)을 저장
--> style을 encoding -
그래서 transformed image의 gram matrix가 style target의 gram matrix를 닮아가게 됨
-
Super resolution처럼 style이 변하지 않는 경우엔
style reconstruction loss는 안 쓰고 Feature reconstruction loss만 L2 loss 대신 사용해서
content는 유지하되, perceptual한 quality를 높임
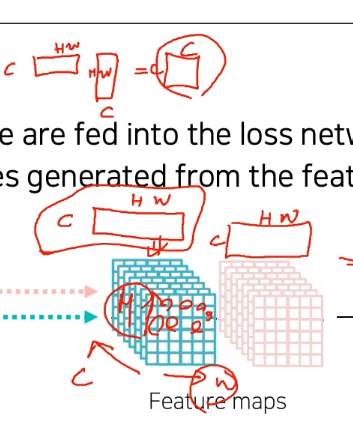
- [C, H, W] shape의 tensor를 [C, H*W]로 reshape한 후,
[C, H*W], [H*W, C]를 내적해서 [C, C] shaped tensor로 만듬
Various GAN applications
Deepfake

- 기존에 존재하지 않는 사람 얼굴이나 목소리를 만들 수 있음
- 윤리적 문제가 생기기 쉽기 때문에 이를 막기 위한 competition도 생기는중
Face de-identification

- 개인정보 보호를 위해 GAN을 사용
Face anonymization with passcode
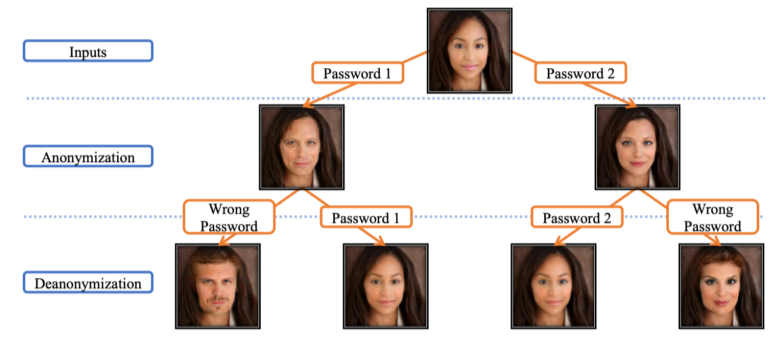
- Passcode를 condition으로 줘서 정확히 입력할 경우에만 원본 data로 돌아올 수 있게 만듬
Video translation

Reference

