Introduction
Image captioning 구현 구조 분석

Encoder

-
Pre-trained CNN을 사용
-
Resnet101의 마지막 2개 layer는 linear, pooling layer로, logit을 출력하기 때문에 제외
우리가 필요한 것은 spatial feature를 유지하는 tensor -
Feature tensor size는
encoded_image_size로 미리 class에 등록해둠
Decoder
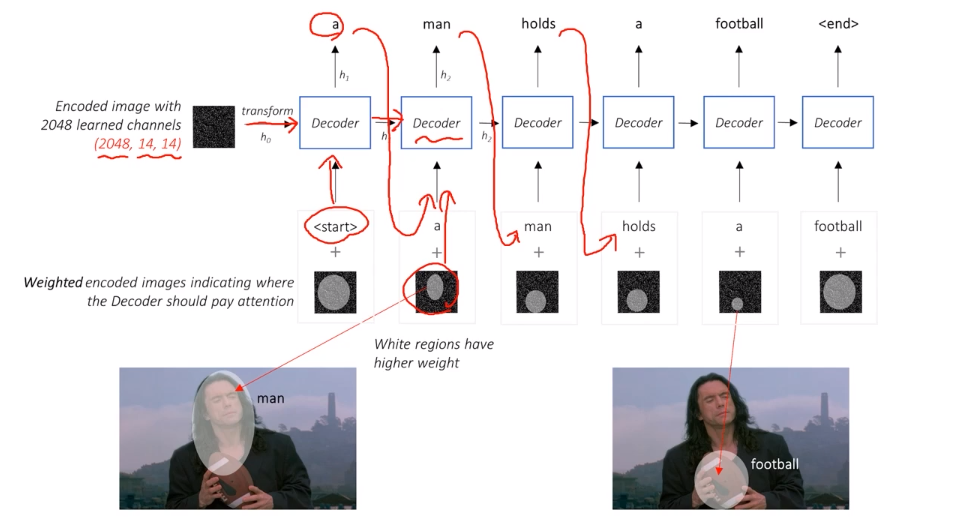
-
Image feature와 start token이 RNN(decoder)에 들어감
-
각 iter에서 나온 output과 attention을 다시 decoder에 넣어서 결과 출력
Beam search
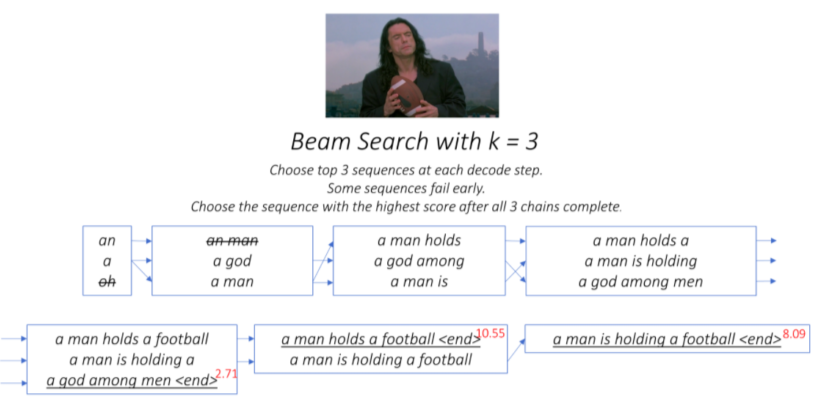
-
RNN decoder는 일종의 classification model
10k~ 의 다양한 word pool에서 score가 가장 높은 word를 출력할지 softmax로 출력- 하지만 1개의 best score만 따라가는게 global best가 아닐수도 있음
-
Beam search는 각 step에서 top k개의 후보를 남김
다음 step에서 각 후보에서 k개의 후보를 뽑고, step, step의 후보들의 score를 더하거나 곱한 최종 score로 후보를 정렬, 다시 top k개만 남김 -
end token이 나오면 그때의 score가 최종 score
Further Reading
https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning

즐겁게 개발하기