Neural Network
- Artificial neural networks (ANNs), usually simply called neural networks (NNs), are computing systems inspired by the biological neural networks that constitute animal brains(Wikipedia).
- 하지만 날기 위해서 새를 모방할 필요는 없듯, AI도 꼭 인간의 뇌를 모방할 필요는 없다.
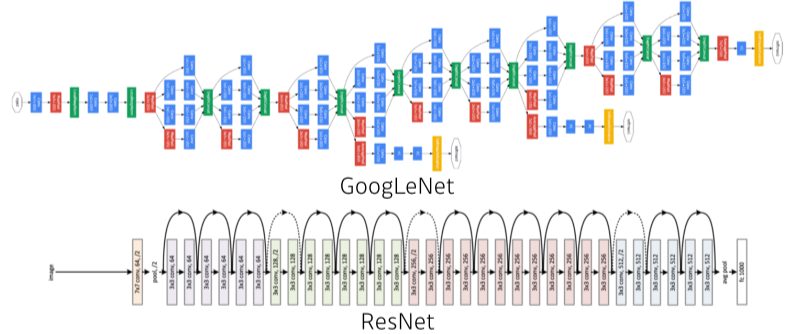
- Neural Networks are function approximators that stack affine transformations followed by nonlinear transformations.
- 행렬변환을 쌓아 함수를 근사하는 모델
Linear Neural Networks
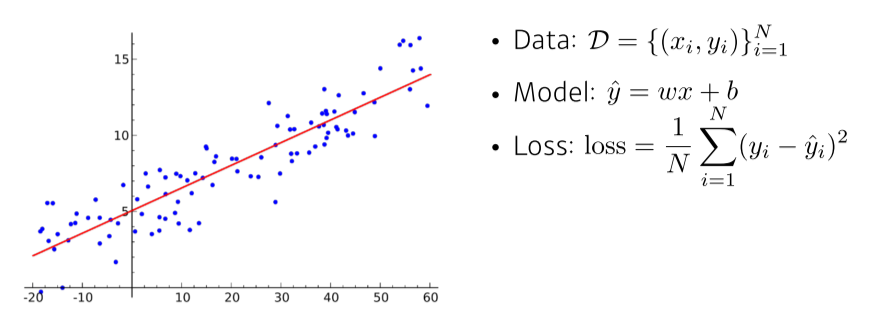
- estimated output(y_hat)과 ground truth(y)의 loss를 최소화하는 w, b를 찾는것이 목적
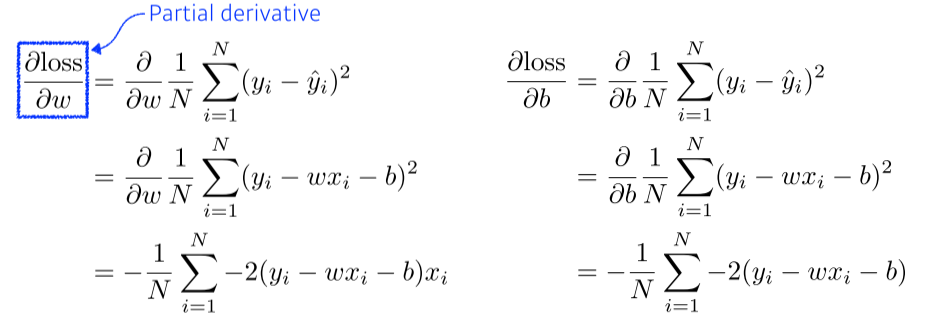
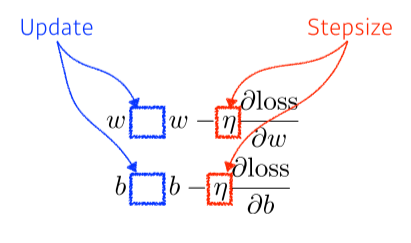
- Gradient Descent: loss function을 줄이기 위해, parameter가 어느 방향으로 움직였을 때 줄어들지를 찾고, 그 방향으로 parameter를 update
--> loss function을 각각 parameter로 미분하게되는 방향의 역수 방향으로 update
Multi-Layer Perceptron
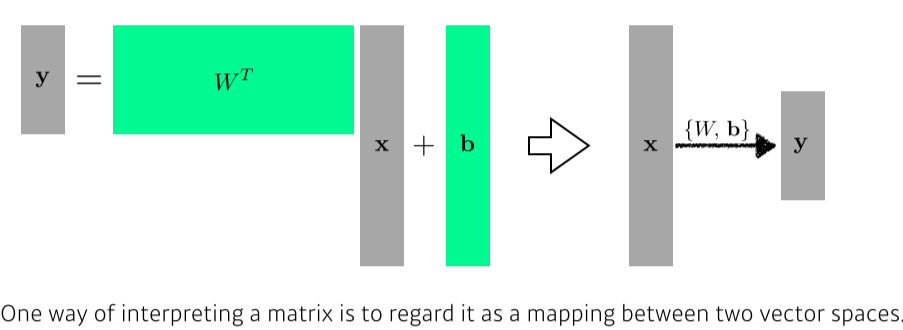
- LNN은 입출력이 1차원이 아니어도 적용 가능
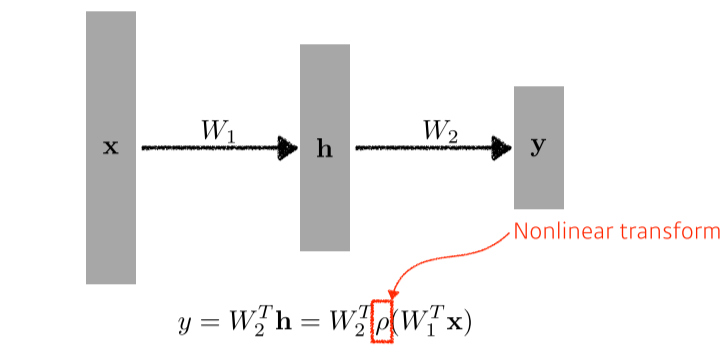
- W1TW2T는 WT라는 새로운 1개짜리 matrix가 되기 때문에 non-linearity를 위해 activation function을 적용
Loss function
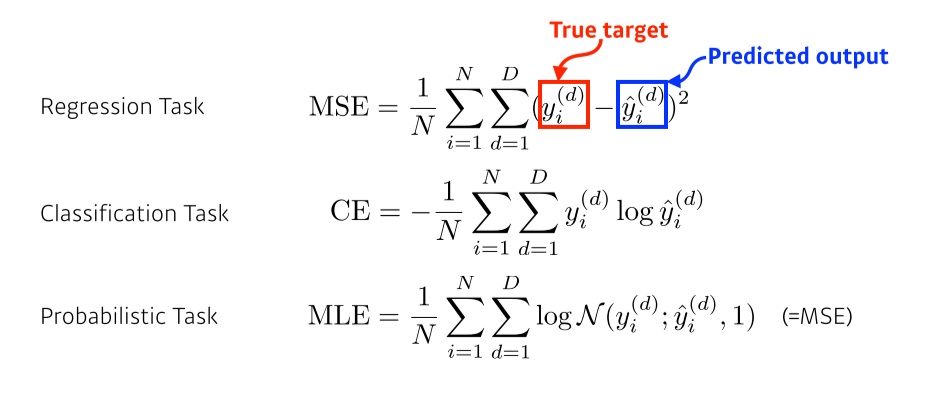
-
Loss function이 어떤 성질을 갖고있고, 왜 내가 train하는데 도움이 될 것인지를 알고 사용하는 것이 중요
-
Regression:
MSE = 0이라고 항상 최적의 모델인 것은 아니다
loss는 L-1 norm, L-2 norm 혹은 다른 것을 사용해도 무관
L-2는 outliar가 있을 때 영향을 많이 받기 때문에(robustness가 낮다) 주의할 필요가 있음 -
Classification:
yid(i = index, d = class)는 one-hot vector라서 정답인 차원의 class만 1이고 나머지는 0
--> NN의 출력값 중에서, 해당하는 차원의 class의 값만 높이겠다(얼마나 높아지는진 상관x) -
Probablistic:
uncertain한 정보를 같이 찾고싶을 때 주로 사용
-

놀고 먹으면서 개발하기