Import Concepts in Optimization
Generalization
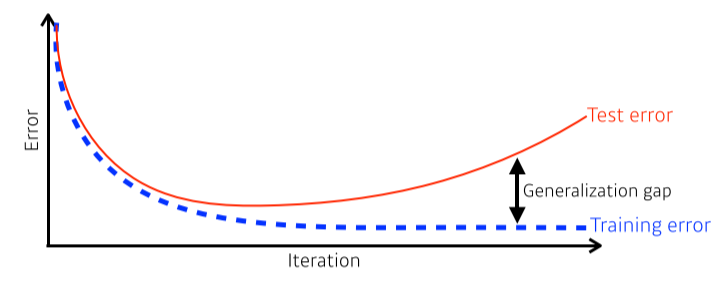
- Good generalization: 이 네트워크의 성능이 unseen data(test)에서도 학습 data만큼 나올 것이다
Overfitting & Underfitting
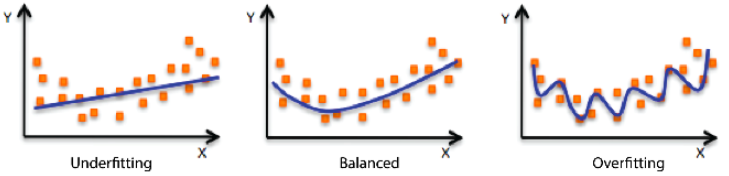
- Overfitting: 학습 data에서는 잘 동작하지만 test data에서는 잘 동작하지 않음
- Underfitting: 학습 data에서도 잘 동작하지 않음
Cross-validation
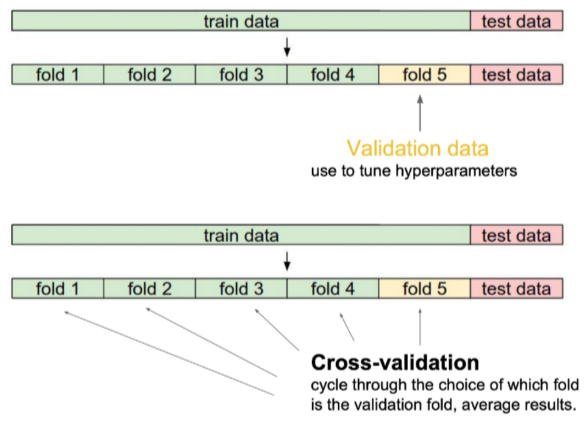
- 학습 data를 나눠서 일부는 train으로, 일부는 validate로 사용
--> test data로 train하는 것은 cheating이기 때문에 절대 건들면 안됨! - K-fold validation: 학습 data를 k개로 나눠서 k-1개로 train, 1개로 validate
최적의 hyper-paramerter를 설정(tuning)하기 위해 사용
최적의 hyper-paramerter를 설정한 이후엔 모든 데이터를 이용해 학습시킴
Bias and Variance
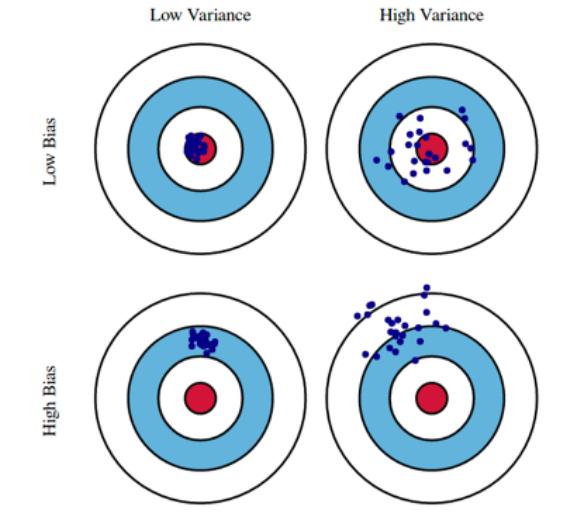
- Variance: 입력을 넣었을 때 비슷한 출력이 얼마나 일관적으로 나오는지
- Bias: 출력을 평균적으로 봤을때 ground truth와 얼마나 가까운지
Bias and Variance Tradeoff

- 학습데이터 D에 노이즈가 있다고 가정했을때, cost(loss)를 minimize하는 것은 3가지 파트로 나뉜다
- 모델 특성상 bias를 줄이면 variance가 높아질 가능성이 크다, and vice versa
Bootstrapping
- 학습데이터 중 일부만 활용해서 모델을 만드는 걸 반복해서 여러개의 모델을 만들고, 동일한 input에 대한 output의 consensus를 보고 전체적인 모델을 예측하고자 함
--> 학습데이터가 고정되어 있을때, subsampling을 통해 학습데이터를 여러개 만들고, 그걸 갖고 여러 model 혹은 metric을 만들어서 무언가 하겠다.
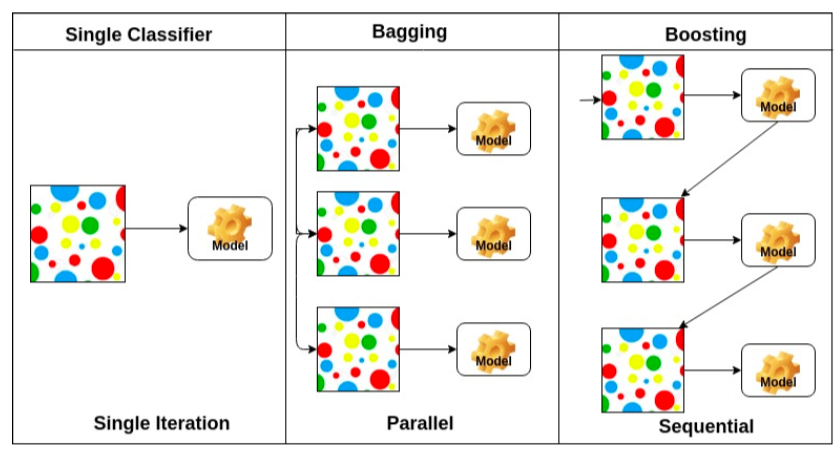
Bagging
- Bootstrapping aggregating
- 각각의 데이터로 모델을 여러개 만들고 독립적으로 만들어서 각각 모델에서 예측값의 평균이나 최다투표값을 사용
--> 모델의 output들만 이용한다는 얘기! - ensemble(앙상블)이라고 불리기도 함
참고: https://datascienceschool.net/03%20machine%20learning/12.02%20%EB%AA%A8%ED%98%95%20%EA%B2%B0%ED%95%A9.html
Boosting
- 먼저 모델을 만들고, 그 모델이 약한 데이터에 대해서 새로운 모델(weak learner) 을 만듬
그리고 weak learner를 합쳐서 strong learner를 만든다 - 참고: https://datascienceschool.net/03%20machine%20learning/12.02%20%EB%AA%A8%ED%98%95%20%EA%B2%B0%ED%95%A9.html
Cross-Validation과 Bootstrapping의 차이?
- Cross-Validation은 1개의 모델로 train data를 변경하면서 optimize
Bootstrapping은 train data가 바뀔 때마다 model을 새로 만들어서 합침
Practical Gradient Descent Methods
Gradient Descent Methods
-
Stochastic GD
한번에 1개의 sample만으로 gradient를 update(batch size = 1) -
Mini-batch GD
sub sample로 update(batch size = 128, 256 등등) -
Batch GD
whole data로 updatd(batch size = whole data)
Batch-size matters
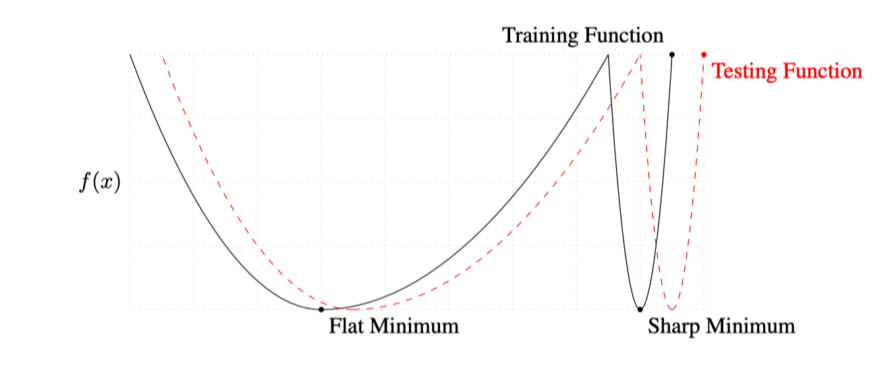
-
large-batch method는 sharp minimizer에, small-batch method는 flat minimizer로 converge한다
출처: https://arxiv.org/abs/1609.04836 -
목적: testing function의 minimum을 찾는것
flat min은 test func.가 train func.에서 조금 멀어져도 적당히 작은 값이 나옴
그러나 sharp min은 test func.가 train func.에서 조금만 멀어져도 굉장히 높은 값이 나옴
--> flat min이 generalization이 좋다
Gradient Descent

- learning rate(step size)를 정하기가 어려운 단점이 있음
Momentum
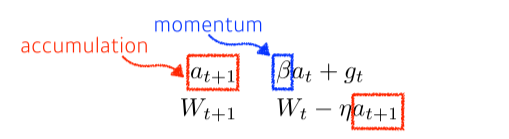
- momentum(관성)을 이용해 현재 gradient와 이전 gradient의 합을 이용해 optimize
NAG, Nesterov Accelerated Gradient
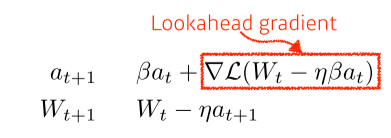
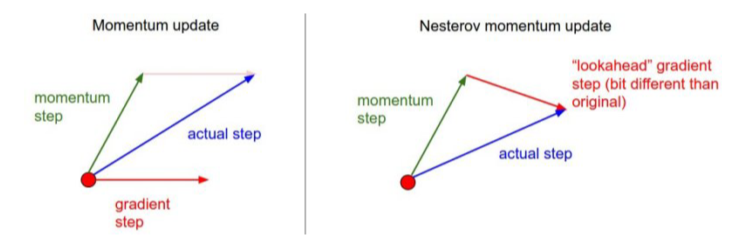
- NAG는 앞을 미리 보고 현재의 관성을 조절하여 업데이트 크기를 바꾸는 방식으로 이 문제를 해결한다
멈춰야 할 때 momentum 때문에 멈추지 못하는(converge를 못하는) 문제를 해결할 수 있음
Adagrad
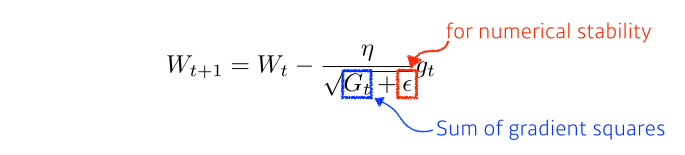
- 각 parameter가 update되는 정도를 맞춰주기 위해 분모에 gradient sum을 넣어 지금까지 많이 변한 param은 적게 update되도록, 적게 변한 param은 많이 update되도록 해줌
- gradient sum은 계속해서 커지기 때문에 뒤로 갈수록 gradient가 update되지 못하는 문제가 발생
Adadelta

- 크기가 w인 window를 도입해 지난 w개의 gradient 정보만 저장
- gradient sum을 저장하는 것이 아니라 graident에 대한 기댓값을 저장
- EMA, exponential moving average: 최근 데이터에 더 가중치를 두는 방식
- learning rate가 없어 많이 활용되지는 않음
RMSprop
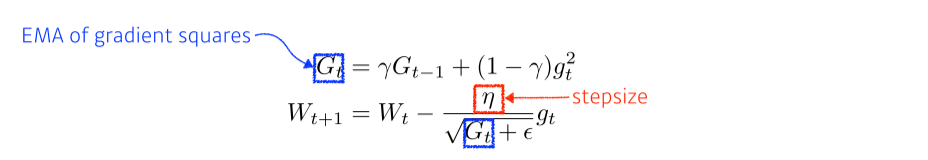
- gradient의 EMA와 step size를 넣었더니 잘 되더라~해서 탄생한 방식
Adam
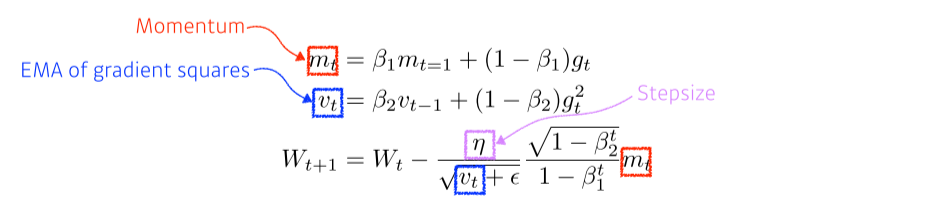
- Adaptive Moment Estimation: RMSprop + Momentum
Regularization
- train data 뿐만 아니라 test data에서도 잘 동작하게 하는 테크닉
Early stopping
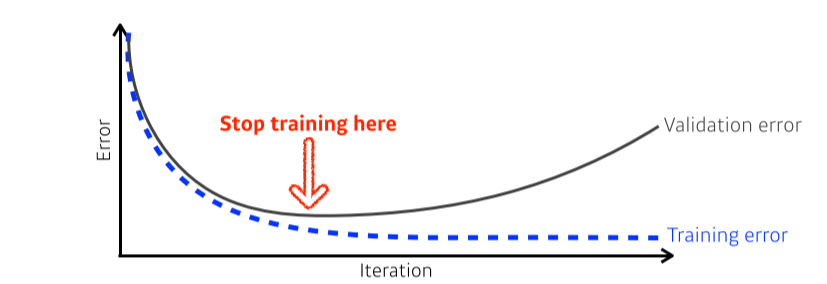
- K-fold validation 같은 방법 등으로 stop point를 정해줌
Parameter norm penalty
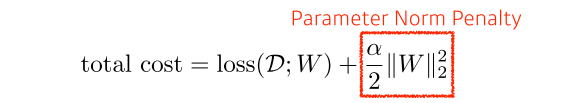
- parameter가 너무 커지지 않게 penalty를 줌
Data augmentation
- data는 많으면 많을수록 좋음
- Data Augmentation에 대한 세미나: http://dmqm.korea.ac.kr/activity/seminar/307
- label이 바뀌지 않는 한도 내에서 data를 가공

-
SimCLR의 unsupervised learning 방식
Noise robustness

- data, weight에 noise를 넣어주면 더 잘될 수 있다
Label smoothing
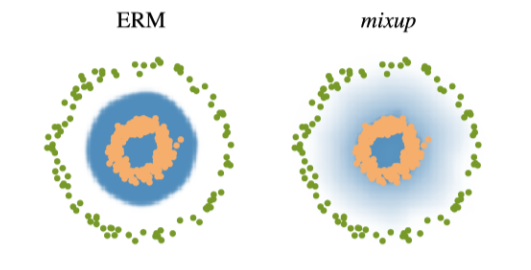
- data 2개를 뽑아 섞어서 decision boundary를 부드럽게 만들어서 성능을 높일 수 있다

- label smoothing의 예시. label과 image를 섞어버림
Dropout
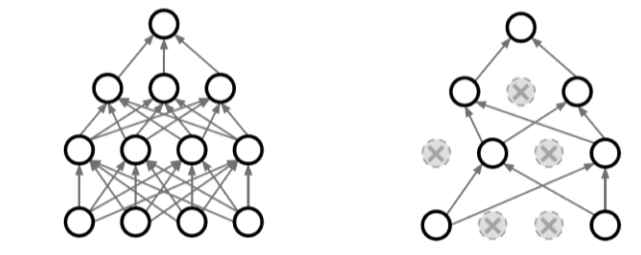
- neuron을 0으로 바꿔서 각각의 neuron이 robust한 feature를 잡을 수 있다
Batch normalization
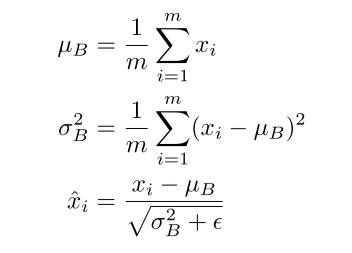
- layer가 깊으면 batch normalization을 사용했을 때 성능이 올라감

즐겁게 개발하기