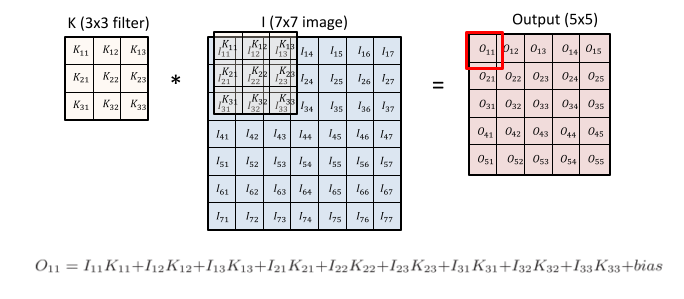
Convolution
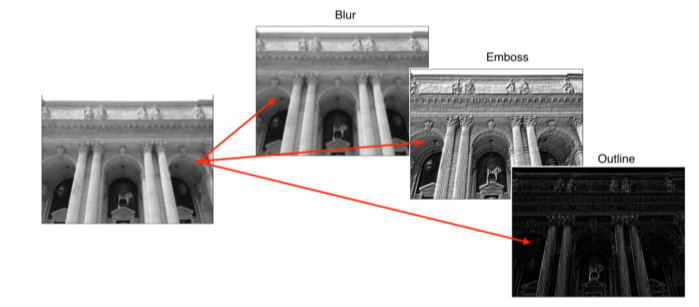
- filter에 따라 이미지에 다양한 변형을 할 수 있다
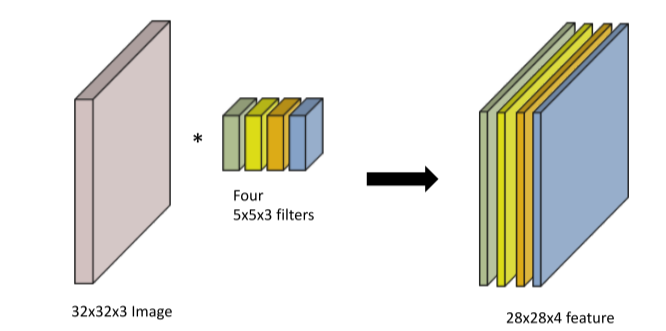
- filter의 dimension은 input의 dimension과 같고
filter의 갯수는 output의 dimension과 같다
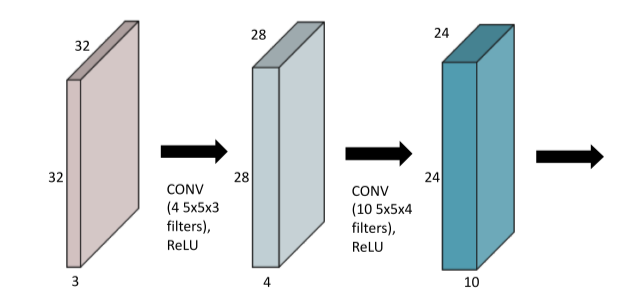
- convolution + non-linear activation
CNN
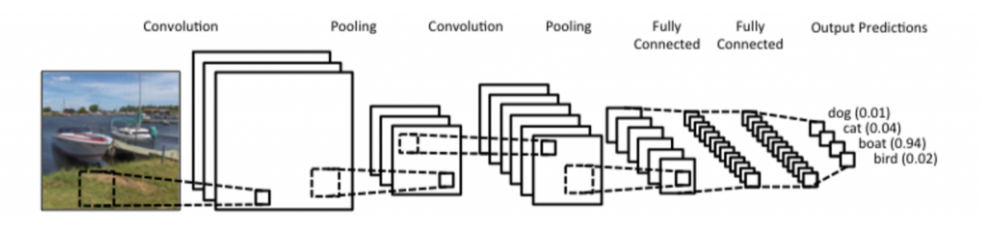
- convolution, pooling layer: feature extranction
- fully connected layer: decision making(classification 등의 score를 출력)
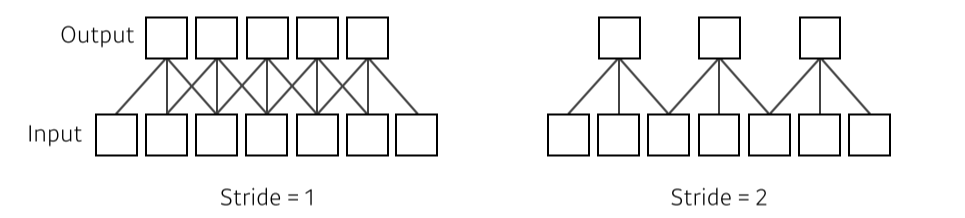
Stride
Padding
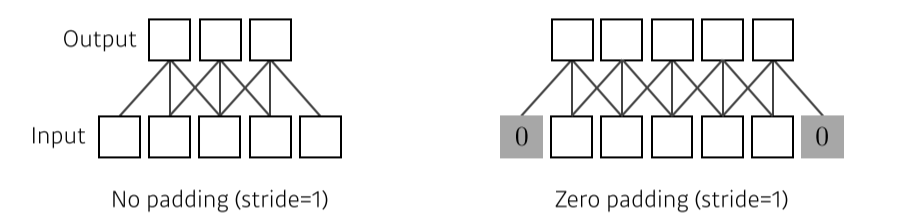
- 가장자리를 채워줌
- 보통은 zero padding
Convolution Arithmetic
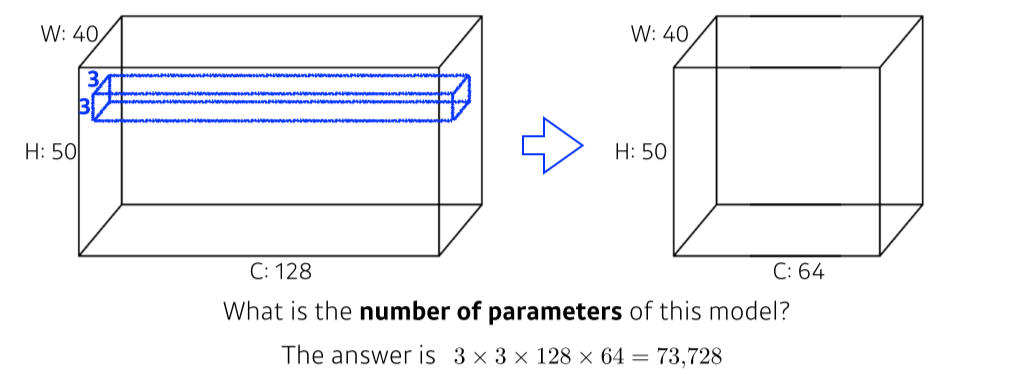
- filter size * input의 channel 수 * output의 채널 수
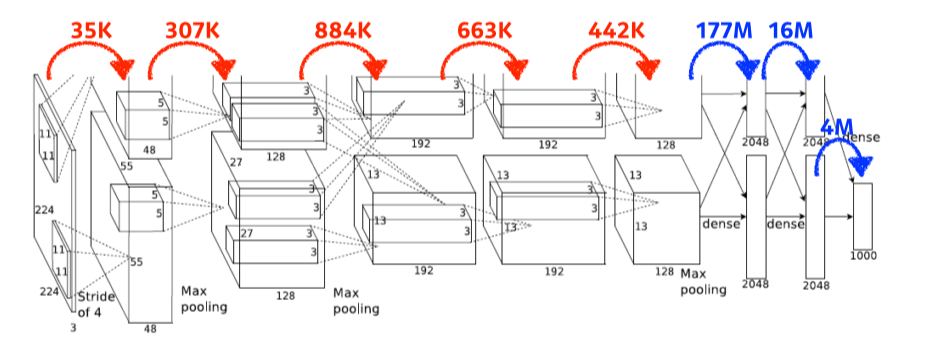
- fully connected layer의 parameter 수가 convolution layer의 1000배 정도로 차이난다
- 그래서 요즘은 f-c layer를 줄이고 conv layer를 깊게 쌓아서 parameter 수는 줄이고 성능을 높이는 방향으로 발전중
1 x 1 convolution
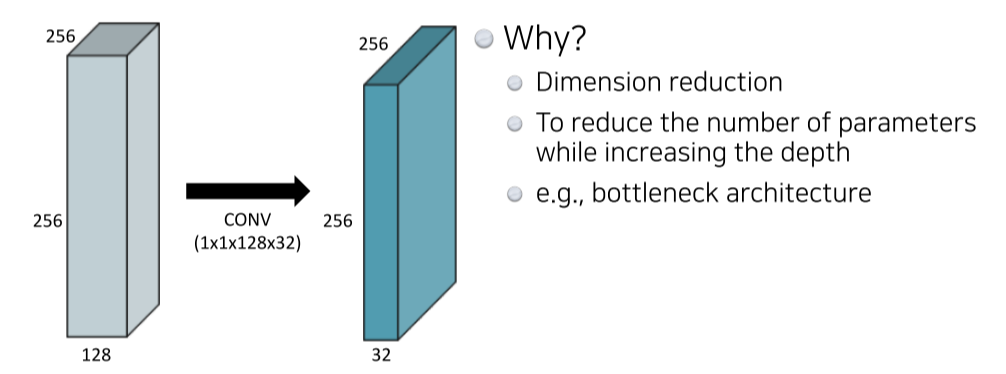
- layer는 깊게 쌓으면서 parameter는 줄이는 방식
- 3x3 쓰는거에 비해 1x1은 spatial dimension을 유지하면서도 채널을 자유롭게 늘리거나 줄일 수 있다
채널을 줄이면 압축하면서 노이즈를 줄이는 효과가 있고, 늘리면 더 많은 high level feature를 추출할 수 있는 장점이 있다 - SeNet 같은데서 1x1로 attention을 주기도 한다
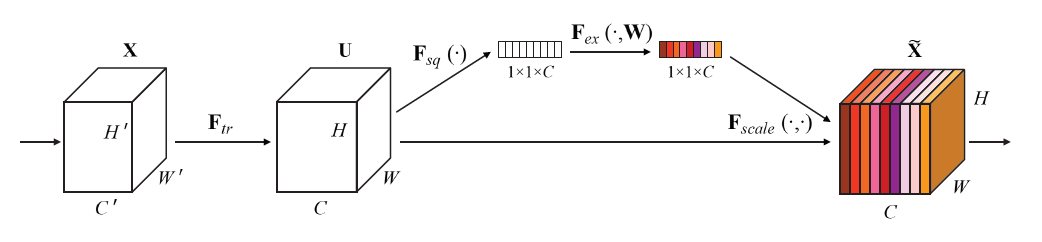
-
SENet: 2017 ILSVRC에서 1등을 한 CNN 구조
Classification에서 top-5 error 2.251%로 전년도 대비 25% 나아진 결과를 보이며 SOTA를 갱신했다.
SENet은 채널 간의 상호작용을 학습한 뒤, 그 정보를 사용해 채널 단위로 새로운 가중치를 줘 성능 향상을 이끌어냈다
(일종의 attention)
그림 중간의 1x1xC가 SE block출처: https://wwiiiii.tistory.com/entry/SqueezeandExcitation-
출처: https://sike6054.github.io/blog/paper/seventh-post/
Attention?

"자연어 처리에선 Attention 기법이 많이 연구되었고 널리 쓰이고 있다. 그렇다면 이미지에서도 이미지에 따라 봐야할 부분을 달리해서 가중치를 더 준다면 이미지 분류나 이미지 감지에서 더 좋은 성능을 줄 수 있지 않을까? 이 attention 기능을 해주는 모듈이 바로 BAM, CBAM이다."
CNN vs MLP?
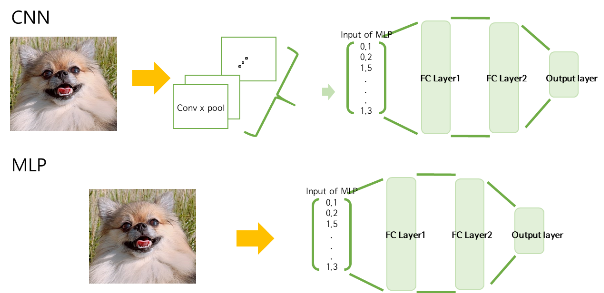
- 가장 큰 차이는 이미지의 feature를 어떻게 추출하느냐의 차이
- MLP: 이미지의 픽셀값을 바로 network의 input으로 넣음
- CNN: Filter를 이용해 convolutional layer, pooling layer를 통과하고 그 결과인 feature map을 network에 input으로 넣음

즐겁게 개발하기