긴 문맥을 처리하는 데 있어 현재의 대형 언어 모델(LLM)이 겪는 한계와, 이를 극복하기 위한 새로운 접근법인 Chain-of-Agents(CoA) 프레임워크를 소개합니다.
LLM은 문서 요약, 질의응답, 코드 완성 등 다양한 작업에서 뛰어난 성능을 보이지만, 긴 문맥(long-context)이 필요한 작업에는 어려움을 겪습니다.
특히 책 전체, 긴 기사, 코드 베이스 전체처럼 수십만 토큰 이상의 입력을 요구하는 경우, 성능 저하가 두드러집니다.
- 기존 접근 방식의 한계
지금까지 긴 문서를 처리하기 위해 주로 사용되던 두 가지 방식은 '입력 축소'와 '윈도우 확장'입니다. 입력 축소 방식은 중요한 정보만 골라서 모델에 넣는 방식인데, 이 과정에서 핵심이 빠지거나 중요한 맥락을 놓치는 경우가 생깁니다. 반면, 윈도우 확장은 모델이 한 번에 처리할 수 있는 입력 길이를 늘리는 방식이지만, 입력이 너무 길어지면 중간에 있는 정보들이 무시되는 ‘lost-in-the-middle’ 현상이 발생할 수 있습니다. 결국 이 두 방법 모두 긴 문서를 완전히 이해하기에는 부족한 점이 있습니다.
-
Chain-of-Agents (CoA)
이 논문에서는 위와 같은 문제를 해결하기 위해 'Chain-of-Agents(CoA)'라는 새로운 방법을 제안합니다. CoA는 여러 개의 언어 모델(에이전트)들이 마치 사람처럼 협업하는 방식으로, 문서를 여러 조각으로 나누고, 각 에이전트가 순서대로 해당 조각을 읽고 요약하거나 중요한 내용을 뽑아 다음 에이전트에게 전달합니다. 마지막에는 관리자 역할을 하는 에이전트가 이 모든 내용을 종합하여 최종 답변을 생성합니다. 이렇게 순서대로 읽고 처리하는 ‘읽고-처리하고-전달하기’ 구조는 기존의 한 번에 다 읽고 한 번에 처리하는 방식보다 훨씬 더 자연스럽고 유연한 접근입니다. -
CoA의 장점
CoA 방식은 별도의 추가 훈련 없이 바로 사용할 수 있고, 특정 작업에 제한되지 않으며, 처리 과정을 단계별로 살펴볼 수 있어 신뢰성과 해석 가능성이 높다는 점이 장점입니다. 또한 각 에이전트는 짧은 입력만을 집중해서 처리하므로, 긴 문서에서 중간 정보를 놓치는 문제도 줄어듭니다. 실험 결과, CoA는 기존 방식들보다 최대 10% 정도 더 나은 성능을 보였습니다.
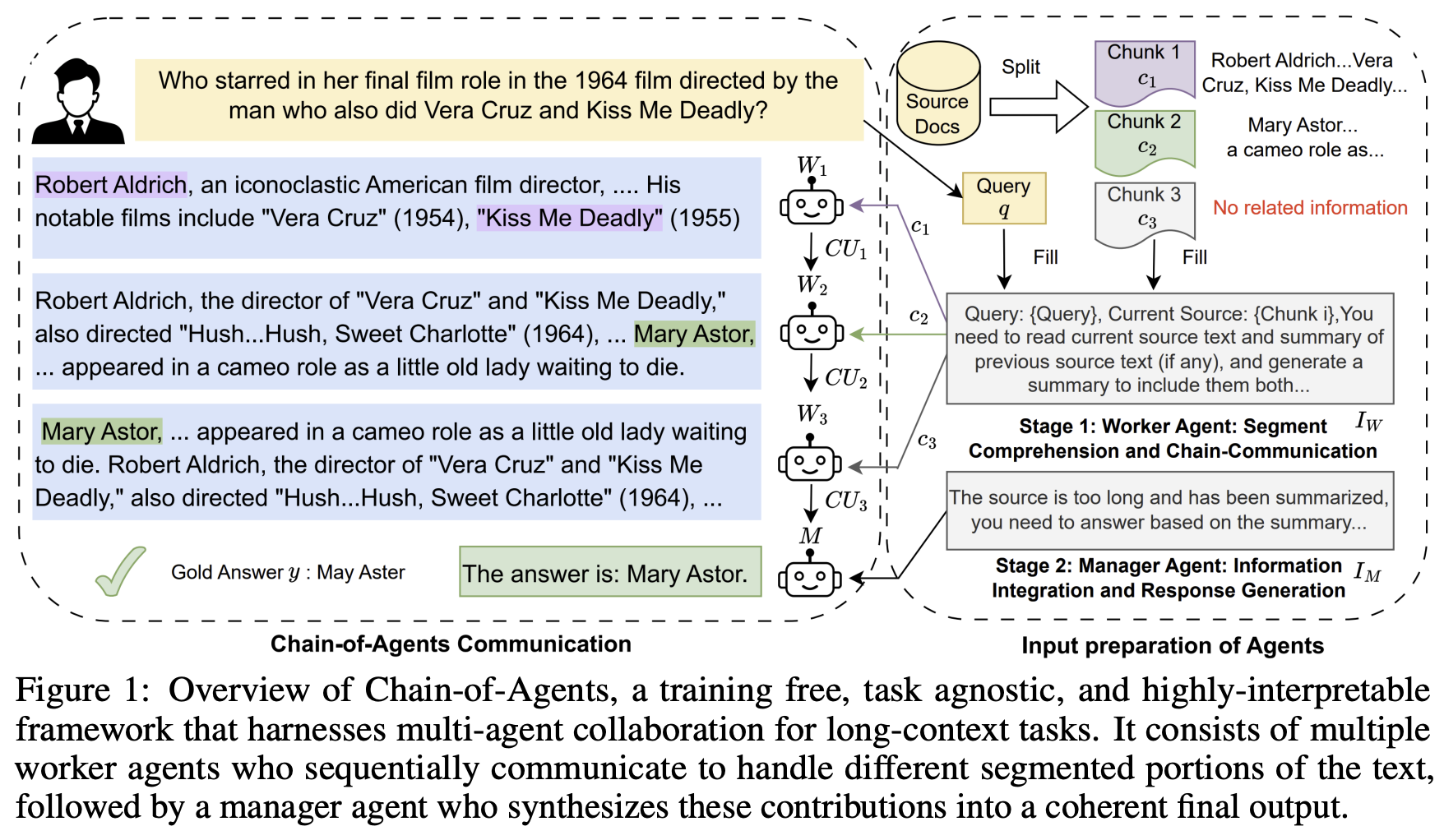
CoA 프레임워크의 주요 구성 요소
작업자 에이전트(Worker Agents):
-
역할: 긴 입력 텍스트를 처리 가능한 크기의 청크로 분할하여 각 부분을 순차적으로 처리합니다.
-
작동 방식: 각 작업자 에이전트는 할당된 텍스트 청크를 읽고, 해당 부분의 주요 정보를 추출하거나 요약하여 다음 에이전트에게 전달합니다.
관리자 에이전트(Manager Agent):
-
역할: 모든 작업자 에이전트로부터 받은 정보를 종합하여 최종 출력을 생성합니다.
-
작동 방식: 작업자 에이전트들이 전달한 요약이나 주요 정보를 기반으로 전체 문맥을 이해하고, 최종적인 응답이나 결과물을 생성합니다.
CoA의 작동 흐름

-
입력 분할 및 할당:
긴 입력 텍스트는 여러 개의 청크로 분할되며, 각 청크는 순서대로 작업자 에이전트에게 할당됩니다. -
순차적 처리 및 소통:
첫 번째 작업자 에이전트는 첫 번째 청크를 처리하고, 그 결과를 다음 작업자 에이전트에게 전달합니다.
이러한 과정이 마지막 작업자 에이전트까지 순차적으로 이루어지며, 각 에이전트는 이전 에이전트로부터 받은 정보를 바탕으로 자신의 청크를 처리합니다. (communication unit: extract relevant information in a
long-context source) -
최종 출력 생성:
마지막 작업자 에이전트의 결과는 관리자 에이전트에게 전달되며, 관리자는 이를 종합하여 최종적인 결과물을 생성합니다.(synthesizes relevant information) -
Comments: 마지막 작업자 에이전트(Wₗ)가 직접 최종 출력을 생성하도록 할 경우, 성능이 떨어졌습니다. 또한, 모든 작업자들이 생성한 소통 단위(CU_i)들을 관리자 에이전트에게 전부 주거나,
각 작업자가 정답과 관련 있다고 판단한 일부 CU만 골라서 줄 경우에도 성능이 나빠졌습니다.
그 이유는 서로 충돌하거나 일관되지 않은 정보들(conflicting CU_i)이 섞여 들어가면서 관리자가 혼란을 겪었기 때문입니다. 따라서, 정보를 단계별로 정제하고, 최종 종합은 관리자 에이전트가 담당하되, 입력 정보는 신중하게 선택하는 설계가 가장 효과적이라는 의미입니다.
Experiments
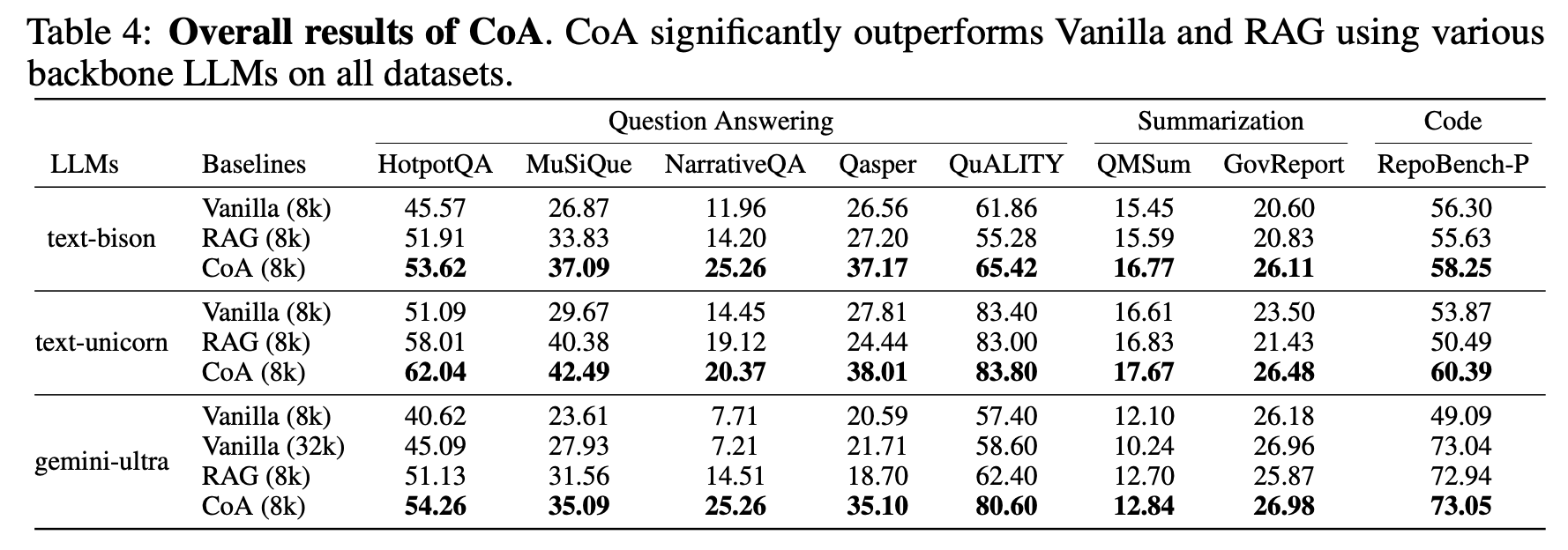
- Table 4에 따르면, CoA(8k)는 text-bison, text-unicorn, gemini-ultra 모델을 사용한 모든 8개 데이터셋에서 Vanilla(8k)보다 우수한 성능을 보였습니다. 특히, NarrativeQA에서 13.30%, MuSiQue에서 12.82%, QuALITY에서 22.00%의 향상을 나타냈습니다. 또한, CoA(8k)는 RAG(8k) 모델보다도 모든 데이터셋에서 더 높은 성능을 보여, 다중 에이전트 LLM이 RAG 모델보다 우수함을 입증했습니다.
- gemini-ultra의 경우, Vanilla(32k)가 Vanilla(8k)보다 성능이 향상되었지만, 여전히 CoA(8k)보다는 낮은 성능을 보였습니다. 이는 긴 문맥 처리에서 CoA의 효과를 강조합니다.
- CoA(8k)는 모든 요약 및 코드 완성 데이터셋에서 Vanilla(8k) 및 Vanilla(32k)보다 우수한 성능을 보였습니다. 이는 CoA가 다양한 작업에서 강력한 성능을 발휘함을 보여줍니다.
- GovReport 데이터셋의 경우, RAG는 의사 쿼리(pseudo query)를 사용하여도 기본 성능을 향상시키지 못했지만, CoA는 성능을 크게 향상시켰습니다. 이는 CoA가 비쿼리 기반 작업에서도 효과적임을 시사합니다.
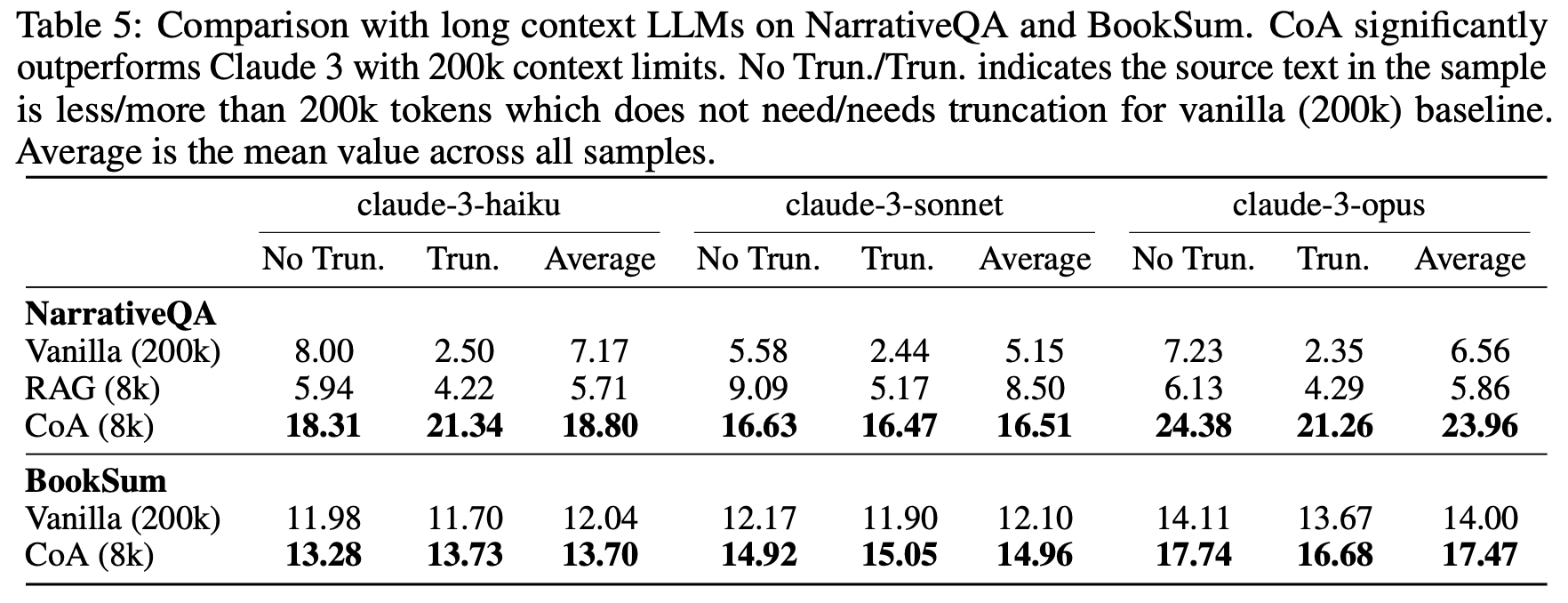
- Claude 3 모델(200k 토큰 지원)과 비교하여, CoA(8k)는 NarrativeQA와 BookSum 데이터셋에서 Vanilla(200k)보다 현저히 높은 성능을 보였습니다. 이는 8k의 문맥 창만으로도 CoA가 200k 문맥 창을 가진 모델보다 우수한 성능을 달성할 수 있음을 보여줍니다.
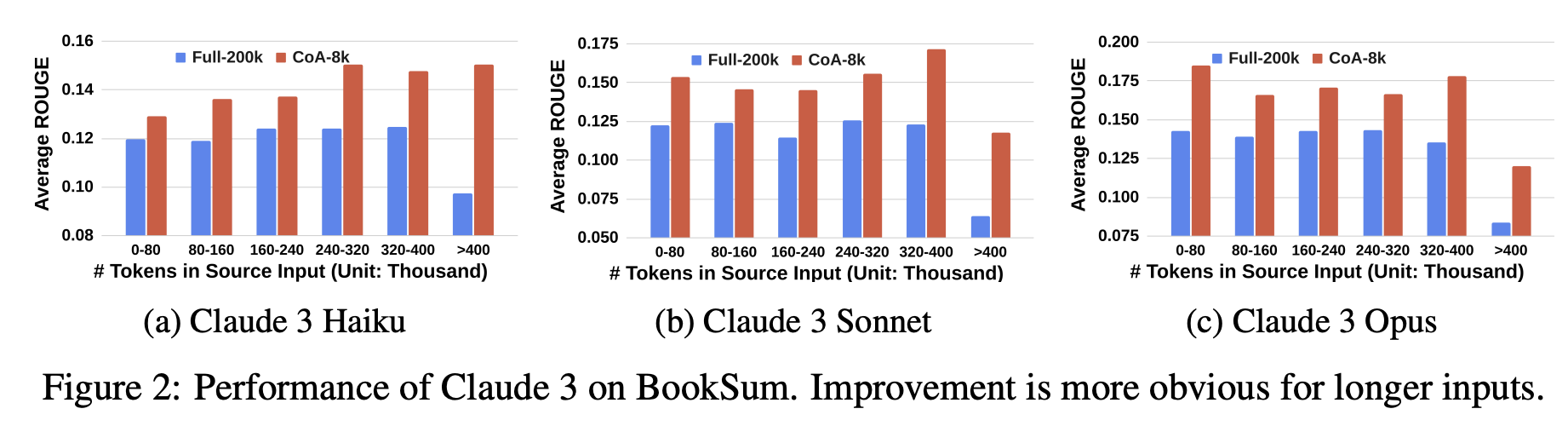
- 긴 문맥을 처리할 수 있는 모델(예: Claude 3)조차도, 입력이 더 길어질수록 CoA가 더 큰 성능 향상을 보여준다는 점을 강조합니다. BookSum 데이터셋을 활용한 실험에서, 다양한 입력 길이에 대해 CoA와 일반 모델(Vanilla)을 비교한 결과, CoA는 모든 길이에서 Vanilla보다 우수한 성능을 보였고, 특히 입력이 40만 토큰을 넘는 경우에는 성능 향상폭이 약 100%에 달했습니다. 이 결과는 두 가지 중요한 결론을 보여줍니다: 첫째, 긴 문맥을 지원하는 모델이라 하더라도 CoA를 통해 성능을 더 끌어올릴 수 있으며, 둘째, 입력이 길수록 CoA의 효과가 더욱 커진다는 점입니다.

- CoA의 다중 에이전트 협업 구조가 긴 문맥에서 복잡한 추론(complex reasoning)을 가능하게 한다는 점을 보여줍니다. 기존의 RAG 방식은 쿼리와 의미적으로 유사한 텍스트 청크만을 가져오므로, 다중 단계 추론(multi-hop reasoning)이 필요한 경우에는 핵심 정보(예: 1단계 답변)를 놓치기 쉽다고 지적합니다. 반면 CoA는 에이전트들이 서로 다른 정보를 순차적으로 탐색하며 추론 사슬(reasoning chain)을 형성합니다. 첫 번째 에이전트는 정답을 모른 채 관련 주제를 탐색하고, 두 번째 에이전트는 앞의 정보에 새로운 지식을 덧붙이며 범위를 확장합니다. 마지막 에이전트는 앞서 전달된 정보와 새로운 단서를 종합해 최종적으로 정답을 도출합니다. 이와 같은 단계적 협업 방식 덕분에 CoA는 복잡하고 장거리 문맥이 필요한 추론 작업에서 탁월한 성능을 보일 수 있습니다.
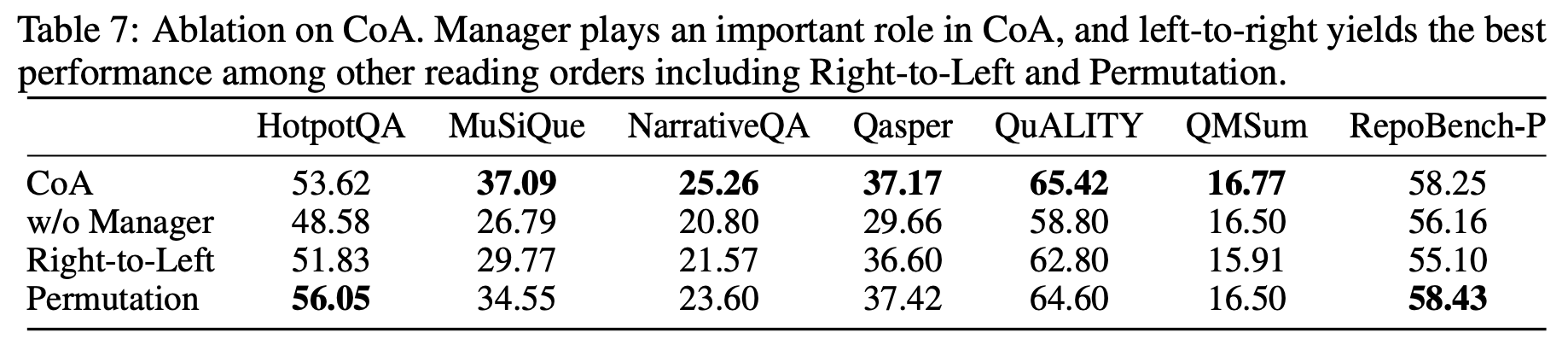
-
먼저, Manager 에이전트를 제거하고 마지막 Worker가 직접 최종 출력을 생성하도록 설정한 "w/o Manager" 실험에서는, MuSiQue 데이터셋에서 성능이 10% 이상 하락하는 등 전반적으로 큰 성능 저하가 나타났습니다. 이는 Manager 에이전트가 전체 문맥을 통합하고 정리하는 데 중요한 역할을 한다는 것을 보여줍니다.
-
또한, 에이전트들이 정보를 읽는 순서에 따라 성능이 어떻게 달라지는지도 실험했습니다. 세 가지 순서를 비교했는데요:
- Left-to-Right (자연스러운 순서): 처음 청크부터 끝까지 읽는 방식
- Right-to-Left: 마지막 청크부터 처음으로 거꾸로 읽는 방식
- Permutation: 청크를 무작위 순서로 읽는 방식
실험 결과, 대부분의 데이터셋에서 Left-to-Right 순서가 가장 높은 성능을 기록했습니다. 이는 사람의 자연스러운 읽기 방식과 일치하는 순서가 정보를 점진적으로 축적하고 추론하는 데 가장 효과적임을 시사합니다.
