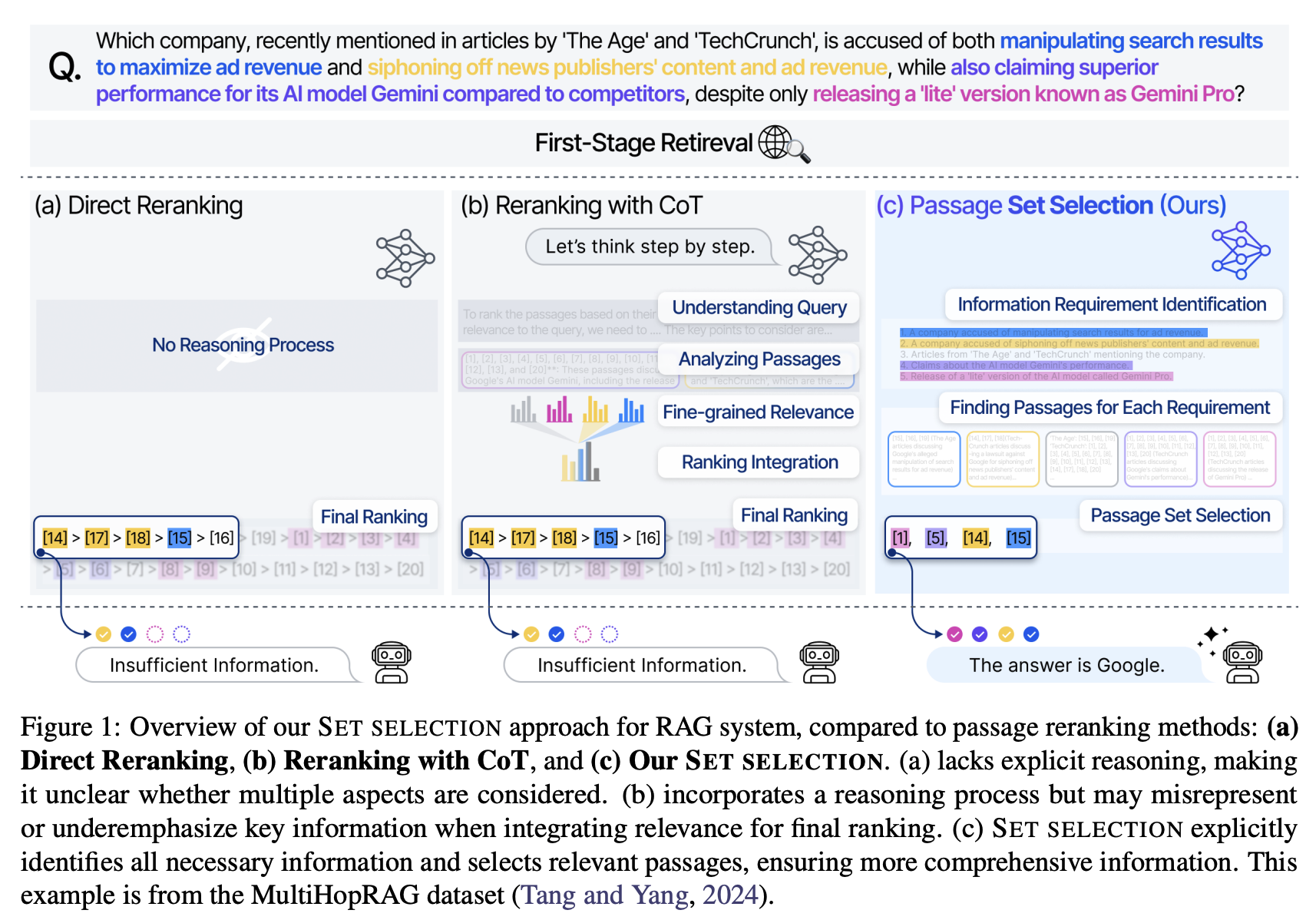
(a) Direct Reranking
그냥 점수 기반으로 passage를 개별 정렬
reasoning 없음 → 질의가 요구하는 여러 측면을 반영했는지 불분명
(b) Reranking with CoT
reasoning은 있지만, 최종 단계에서 모든 관련성 점수를 단일 ranking으로 통합
이 과정에서 중요 정보가 희석·누락될 수 있음
(c) Set Selection (SETR)
질의를 정보 요구사항(IRI) 단위로 명시적으로 분해
각 요구사항을 커버하는 passage를 선택
최종적으로 가장 포괄적·완전한 passage 집합을 확보
- 다중 추론(multi-hop) 질의는 보통 여러 정보 조각(R1, R2, …)이 함께 있어야 답을 만들 수 있음.
- 그런데 전통적 reranker는 각 문서를 독립적으로 점수 매겨 상위 k개를 채택함. 이때 흔히 생기는 문제:
중복: 비슷한 문서만 잔뜩 뽑힘.
누락: 꼭 필요한 한 조각(R3 같은)이 빠짐 → 답을 못 만듦. - 결론: multi-hop에서는 “각 문서가 얼마나 좋냐”보다 문서 집합이 전체 요구사항을 ‘완성’하느냐가 더 중요함.
SETR: Set-wise Passage Selection for Retrieval-Augmented Generation
- 기존: reranking → 각 passage를 개별적으로 점수화 후 top-k 선택.
- 문제: 단순 relevance 기준으로는 완결성(coverage), 간결성(conciseness) 확보가 어려움.
- 제안: set-wise retrieval → 집합 단위로 최적화하여
관련성(relevance), 완결성(completeness), 간결성(conciseness) 을 동시에 고려. - 추가 장점: top-k 값을 사람이 정할 필요 없음, 시스템이 자동으로 “적절한 집합”을 고름.
Method
- 요구사항 도출 (Information Requirement Identification via CoT)
 핵심 아이디어: 질문을 풀기 위해 필요한 정보 요구사항을 명시적으로 뽑아내는 것.
핵심 아이디어: 질문을 풀기 위해 필요한 정보 요구사항을 명시적으로 뽑아내는 것.
방법: Chain-of-Thought (CoT) reasoning을 활용해 3단계로 진행:
(1) 질문을 정보 요구사항(subgoals)으로 분해.
(2) 각 요구사항과 관련된 passage를 매칭.
(3) 요구사항들을 가장 잘 집합적으로 충족하는 passage 세트 선택.
- 특징:
LLM을 활용해 후보 passage + 질의를 함께 주고 reasoning.
기존 listwise reranking과 달리 “모든 후보를 포함”할 필요 없음.
최종 출력은 순위(rank)가 아니라 집합(set).
-
Model distillation
문제: GPT-4o 같은 대형 LLM은 성능은 뛰어나지만 → 비용·지연 때문에 실시간 검색 시스템에 비현실적.
해결: LLM의 step-by-step reasoning 능력을 distillation 해서, 가볍고 빠른 전문화된 모델(SETR)로 압축.< 학습 데이터 생성 >
- Pradeep et al. (2023b)에서 제공한 MS MARCO v1 기반 4만 개 질문 사용.
- SETR의 teacher 라벨 생성 과정:
질문 + top-20 후보 passages를 GPT-4o에 넣음.
GPT-4o가 Chain-of-Thought reasoning으로 질문을 풀기 위한 정보 요구사항(IRI)을 분해.
각 요구사항을 커버할 수 있는 passages를 매핑.
최종적으로 질문에 가장 잘 답할 수 있는 set(집합)을 선택.
결과:
이렇게 얻은 “set-wise passage selection 결과(teacher label)”가 만들어짐.
이 결과를 distillation해서 Llama-3.1-8B 기반 student 모델(SETR)을 학습.
- 추가로,
passage 내 [n] → (n) 치환 (혼동 방지)해서 MS MARCO나 QA 데이터셋에는 본문 내에 종종 숫자 reference 표기를 LLM이 혼동하지 않도록 변경해주었음. (결과에서의 혼동 피하기 위함).
또한, 텍스트 전처리 라이브러리 FTFY(Fixes Text For You)를 사용하여 정상적인 유니코드 텍스트로 텍스트를 정제하였음. (문자 인코딩 깨지는 부분이나, 특수문자/공백 깨짐 등을 처리할 수 있다.)< Training >
베이스 모델: Llama-3.1-8B-Instruct
학습 방식: Supervised fine-tuning(SFT)입력: 질문 + 후보 passages
출력: teacher LLM이 만든 CoT reasoning + 최종 선택된 passage 집합비교 모델(어블레이션):
(1) SETR-Selection only: reasoning 없이 최종 passage 집합만 출력.
(2) SETR-CoT: 일반 CoT("let’s think step by step") 기반 reasoning, 하지만 정보 요구사항(IRI)을 명시적으로 뽑지 않음.
(3) SETR-CoT & IRI (최종 모델): CoT reasoning + 정보 요구사항 식별(IRI)을 모두 포함. passage selection도 함께 수행.
Experiments
Benchmarks (평가 데이터셋)
- 두 가지 과제로 평가:
End-to-end QA (질문→답 생성까지 전체 성능)
Retrieval task (retrieved passages 품질 자체 평가) - 사용한 4개 multi-hop QA 데이터셋:
HotpotQA: 대표적인 위키 기반 multi-hop QA
2WikiMultiHopQA: 위키 기반 2-hop QA
MuSiQue: 질문 분해와 reasoning 요구가 복잡한 QA
MultiHopRAG: RAG 특화 multi-hop QA 벤치마크 - 특징: 다양한 질의 유형과 multi-hop 시나리오를 포함해 복잡한 실제 QA 상황 평가 가능.
Baselines
- 전통적 비지도 랭킹: BM25
- Dense ranking (supervised): bge-large-en-v1.5, bge-reranker-large
- LLM 기반 reranking 모델: RankLlama, RankVicuna, RankZephyr, FirstMistral, RankGPT (GPT-4o 기반)
Details
- Retriever: bge-large-en-v1.5 (고성능 dense retriever) → 고정
기존 RAG 시스템처럼 모델 구조를 수정하거나 추가 학습 없이, retrieved 문서를 질문 앞에 그대로 덧붙여서 language model에게 전달하는 방식인 In-Context Retrieval‑Augmented Language Models (In‑Context RALM) 방식을 사용함.
End-to-end QA Evaluation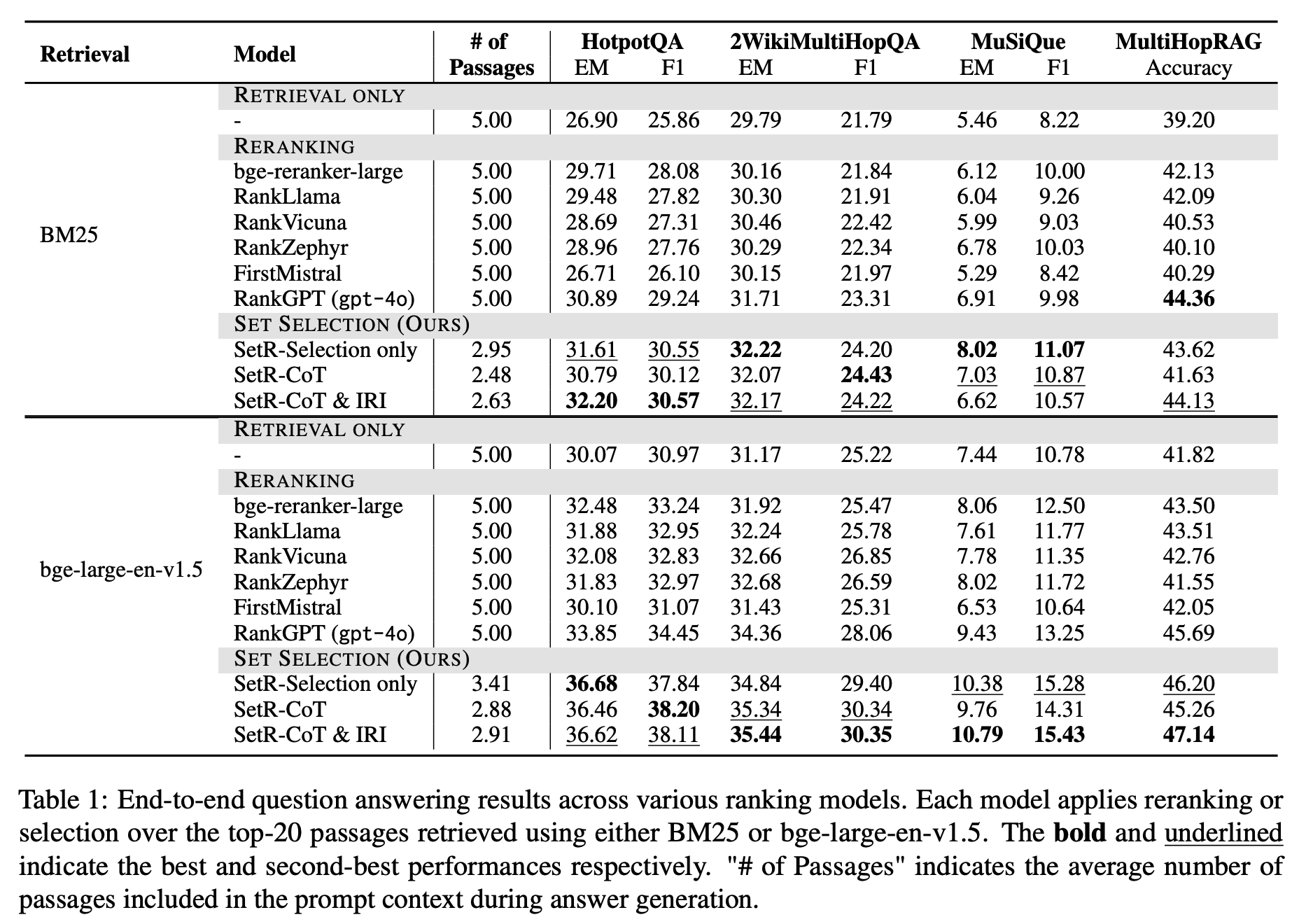
- 평가 항목:
RETRIEVAL ONLY: 1차 검색기(bge-large-en-v1.5 등)만 사용했을 때.
RERANKING: 기존 reranker(Llama 기반, BGE reranker 등)로 top-20 후보 재정렬.
SET SELECTION (SETR): 제안 방식으로 top-20 중 최적의 집합을 선택.
-
SETR의 성능 우위
정답 정확도(F1, Accuracy)에서 모든 baseline을 큰 폭으로 앞섬.
평균적으로 40~50% 더 적은 passage만 사용했음에도 더 높은 정답률 달성.
→ 즉, “많이”가 아니라 “필요한 집합을 정확히” 고르는 게 더 효과적임을 입증. -
LLM 기반 reranker의 성능 한계
RankLlama, RankZephyr 같은 LLM 기반 reranking 모델들의 성능이 기대보다 낮음.
오히려 bge-reranker-large(상대적으로 작은 dense reranker)가 비슷하거나 더 잘함. -
이유
복잡한 질의 → retrieval 난도 증가 → 잡음 많은 후보 pool
이 상황에서 단순 relevance 점수로는 부족 → diversity, completeness, comprehensiveness 필요.
SETR는 이 집합적 속성을 고려하므로 성능 격차가 발생. -
결론적 시사점
RAG에서 중요한 것은 “더 많은 passage”가 아니라 “더 적고 유용한 passage 집합”.
제대로 된 retrieval paradigm(SETR 같은 set-wise selection)을 쓰면, 작은 모델도 큰 LLM보다 우월할 수 있음.
Retrieval Evaluation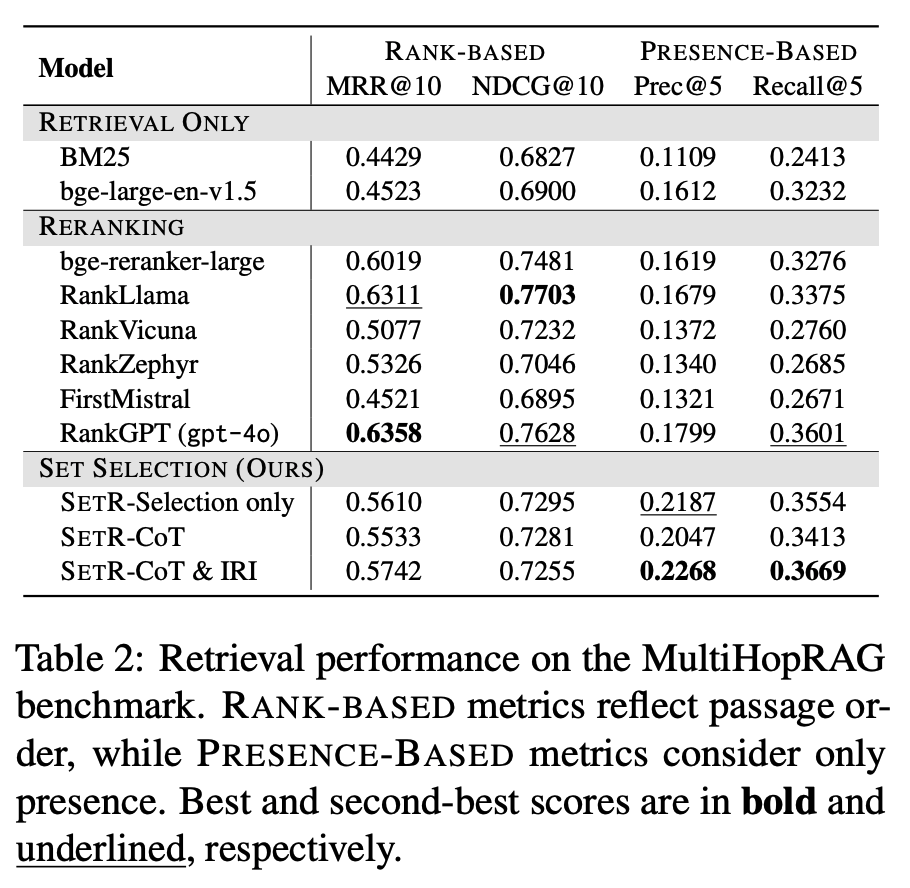
- 데이터셋: MultiHopRAG (Tang & Yang, 2024)
- 지표:
Rank-based metrics: MRR, NDCG → “문서 개별 순위 품질” 평가
Presence-based metrics: Precision, Recall → “정답 문서가 포함되었는지 여부” 평가 - SETR 성능:
Precision에서 3.8%~4.6% 향상 (기존 베이스라인 대비, 즉, 같은(혹은 더 적은) 개수로 뽑더라도 잡음이 적고 유효 문서가 더 많다).
rank-based 지표(MRR, NDCG)에서도 경쟁력 유지, 심지어 적은 수의 passage만 사용했음에도 안정적 성능. - LLM 기반 ranker (RankGPT 등):
RankGPT(gpt-4o)는 rank-based & presence-based 모두에서 개선된 성능을 보여줌.
하지만 end-to-end QA 성능에서는 기대만큼의 이득이 없음. - 지표 불일치(discrepancy):
Rank-based 지표(MRR, NDCG)는 “문서-질의 1:1 관련성”을 가정.
그러나 multi-hop 질의는 여러 문서 간 관계/연결이 필요 → 단순 relevance로는 부족.
따라서 rank-based metric 성능이 높아도, 실제 QA 성능은 떨어질 수 있음. - 시사점:
Multi-hop QA에서는 “개별 문서 관련성”이 아니라, 집합적 완결성/관계성이 더 중요.
따라서 기존 rank-based metric은 불완전 → 새로운 평가 기준이 필요함.
Analysis
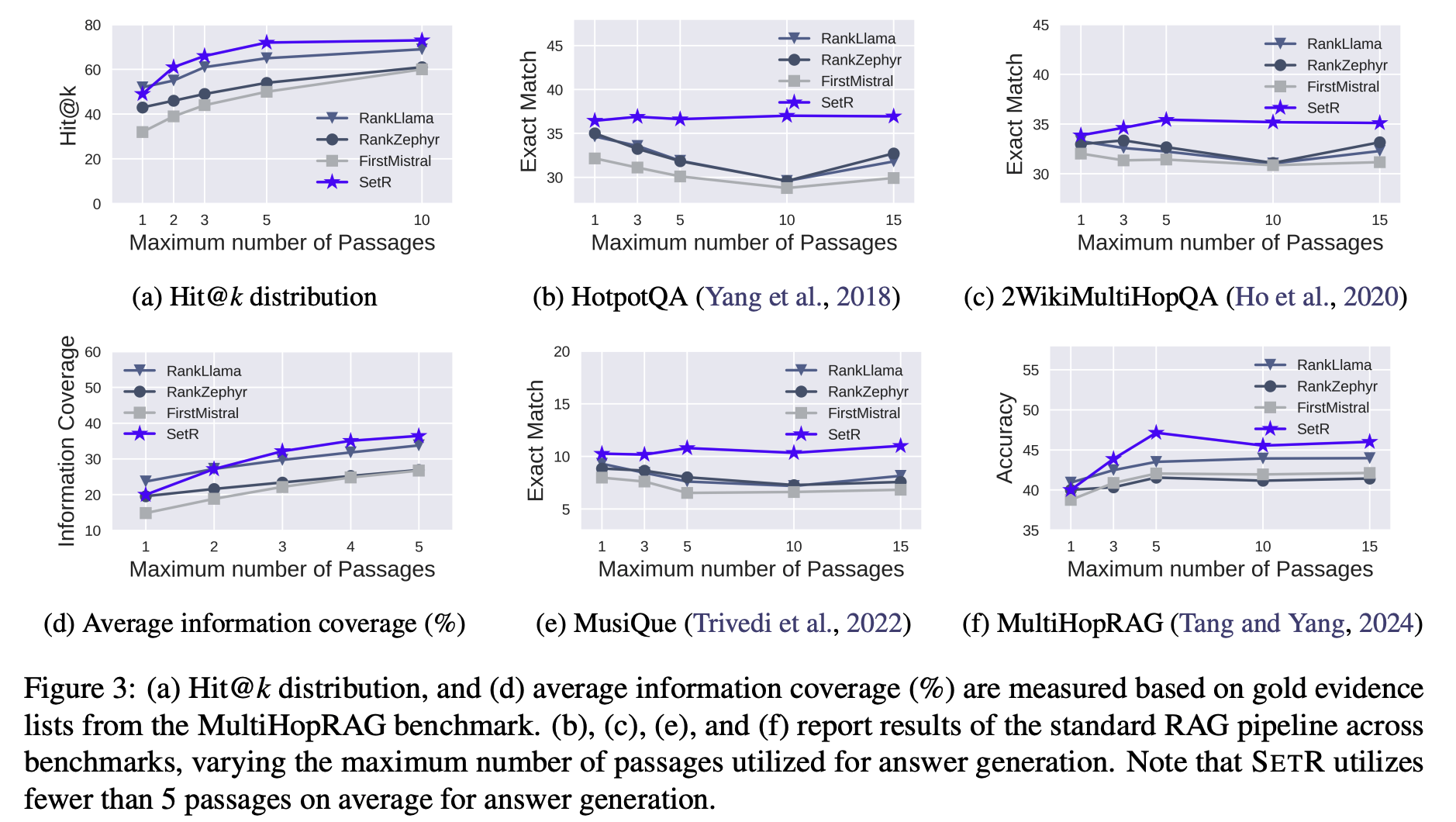
Effectiveness of Set Selection: Informativeness and Robustness
(1) Informativeness – 얼마나 잘 필요한 정보를 커버하는가?
-
기존 문제:
전통적인 ranking 기반 retrieval은 개별 passage의 관련성 점수만 보고 고르기 때문에,
중복 문서를 반복적으로 뽑을 가능성이 크고,
결과적으로 새로운 정보를 잘 못 챙김. -
분석 방법:
MultiHopRAG의 gold evidence 리스트를 기준으로,
Hit@k: top-k 내에 gold evidence가 있는지 여부.
Information Coverage: 선택된 passage들이 누적해서 얼마나 새로운 gold evidence를 추가로 확보하는가. -
결과:
SETR → Hit@k 48.87% → 69.90% 상승. (3a)
SETR → Information coverage 19.33% → 36.49% (거의 2배 가까이). (3d)
다른 reranker들은 평균 9.8% 정도만 개선. -
의미:
SETR는 단순 relevance뿐만 아니라 “집합적으로 새로운 정보를 얼마나 확보하는지”까지 잘 최적화 →
multi-hop 질의에서 필요한 근거 누락을 줄임.
(2) Robustness – 불필요한/잡음 문서를 얼마나 잘 걸러내는가?
-
문제 상황:
일반적으로 passage 개수를 늘리면 더 많은 근거가 포함될 수 있지만,
irrelevant(무관) / contradictory(모순) evidence가 늘어나면서 성능 오히려 하락. (3b, 3c, 3e, 3f)
특히 multi-hop QA에서는 잡음 문서가 generator를 혼란스럽게 만들어 답 정확도가 떨어짐. -
결과:
SETR는 적은 passage만 사용하면서도 consistently 높은 성능 유지.
평균 사용 passage 수: Reranker = top-5, SETR = 2.91개 (거의 절반 이하).
즉, “더 많이”가 아니라 “더 정제된 집합”이 훨씬 효과적임. -
의미:
SETR는 단순히 recall만 추구하지 않고,
효율성(적은 수로도 충분)과 정확성(잡음 배제)을 동시에 달성.
→ Recall vs. Conciseness 균형 최적화가 multi-hop RAG에서 성능 핵심임을 입증.
Effectiveness of Reasoning Components: The Role of CoT and IRI
-
질문: SETR의 성능 향상이 단순히 “LLM이 step-by-step으로 생각(CoT)하기 때문인가?”
→ 아니면 명시적 정보 요구사항 식별(IRI) 덕분인가? -
방법: Ablation study (모듈별 효과 확인)
Variant 1: No reasoning → reasoning 전혀 없음, 그냥 top-k 선택.
Variant 2: General CoT → 일반적인 “Let’s think step by step” 방식 reasoning만 사용.
Variant 3: IRI-based reasoning → 질문을 명시적 정보 요구사항(정보 subgoal)으로 분해한 뒤, 이를 충족하는 passage 집합을 고르는 방식.
-
Precision:
No reasoning < General CoT < IRI-based reasoning
특히 IRI는 단순 CoT 대비 정확히 필요한 passage를 집합적으로 골라내는 능력이 뛰어남. -
End-to-end RAG 성능 (QA 정확도):
IRI 기반 reasoning을 적용했을 때가 모든 벤치마크에서 가장 높은 성능. -
결론:
성능 향상이 단순히 LLM의 일반 CoT 능력 때문이 아니라,
“질문 → 요구사항 리스트 → 집합 충족”이라는 명시적 reasoning 구조(IRI) 덕분임이 입증됨.
일반 CoT만 사용하는 경우:reasoning은 하지만, 정보 요구사항을 명확히 분리하지 못함 → 결국 passage를 중복되게 고르거나, 핵심 evidence를 놓칠 수 있음.
IRI를 추가하는 경우:
질문을 구조적 subgoal로 나누고, 각 subgoal별로 passage 매핑 → 정보 coverage 최대화 + 중복 최소화.따라서: 단순히 LLM이 “생각해주는 것”에 기대는 게 아니라, 정보 요구사항을 명시적으로 정의하는 과정이 성능 핵심.
A More Equitable Comparison: Method-Level Effects
앞선 결과만 보면 “SETR가 성능이 좋은 이유가 모델 크기, 데이터 차이, teacher 모델의 품질 때문 아닐까?”라는 의문이 있을 수 있음.
→ 따라서 공정하게(method-level) 비교할 필요가 있음.
(1) Upper Bound 실험
모든 모델(reranking, set selection)이 똑같이 GPT-4o teacher를 사용해 passage selection/ ranking 수행.
이렇게 하면 모델 자체의 성능 차이를 최소화 → 순수하게 방법론 차이만 남음.
-
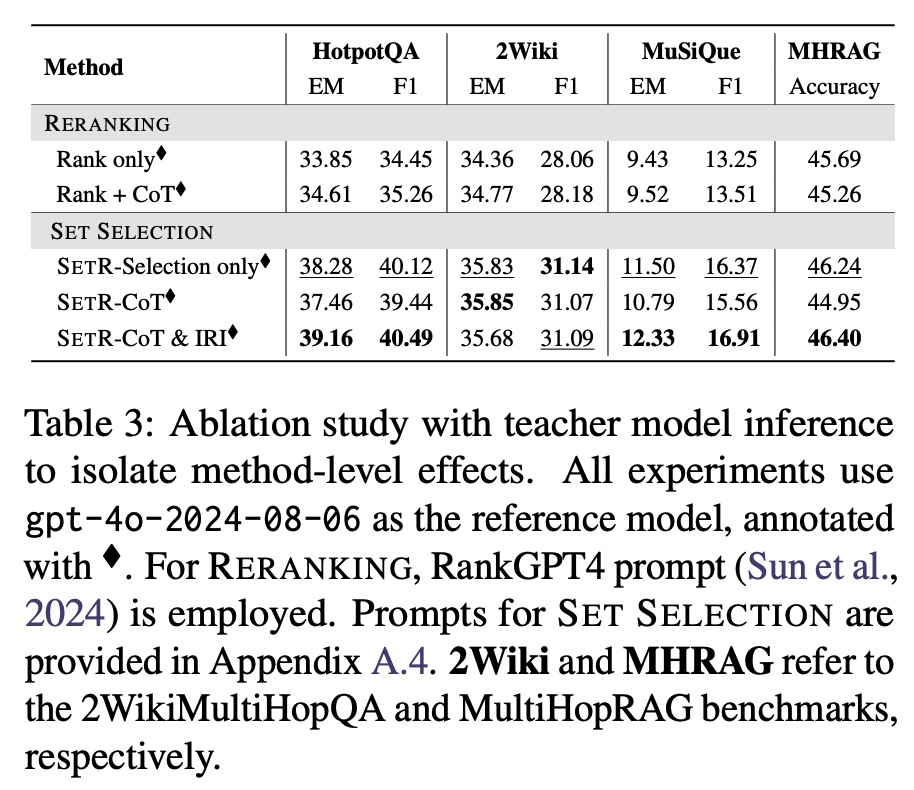
결과(Table 3):
SETR (특히 IRI 포함)이 전통적 reranking 및 CoT-only 모델보다 consistently 높은 성능. -
흥미로운 점:
Rank + CoT vs. SETR-CoT → 같은 CoT 프롬프트를 쓰더라도, ranking 형식보다 set selection 형식이 더 좋은 결과.
이유: ranking은 reasoning 과정의 일부를 단일 점수로 압축하면서 정보 손실 발생.
반면 set selection은 reasoning step들을 보존 → 정보 coverage ↑, precision ↑.
SETR-CoT vs. SETR-CoT+IRI → IRI 단계가 있을 때 precision과 coverage 모두 개선.
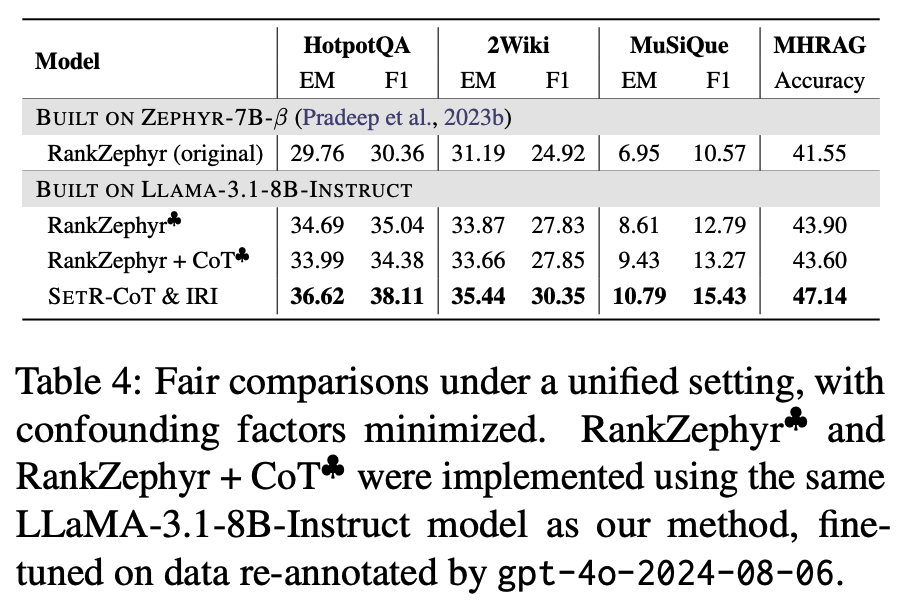
(2) Unified Setting 실험
-
통일된 조건:
같은 base model (Llama-3.1-8B-Instruct)
같은 teacher supervision (GPT-4o re-annotation)
같은 generation protocol -
결과(Table 4):
다시 SETR가 reranking baselines보다 end-to-end QA에서 consistently 우위. -
원인 분석:
Ranking+CoT: reasoning 체인을 하나의 “score”로 합치다 보니 중요한 정보 요소가 묻힘.
SETR: reasoning step을 유지하고, 필요 정보 요구사항을 직접 반영 → 질문 정보 요구와 더 정합적.
성능 향상은 단순히 큰 모델(GPT-4o)이나 teacher supervision 덕분이 아님.
Retrieval을 “ranking 문제”가 아닌 “set selection 문제”로 재정의한 방법론적 혁신 덕분임.
즉, CoT + IRI 기반 set-wise selection이야말로 성능 향상의 주된 원인.
Efficiency Analysis
RAG용 retrieval 모듈은 단순히 성능(F1/Accuracy)만 중요한 게 아니라,
실제 배포 환경에서 효율성(latency, memory, compute cost)도 핵심임.
직접적인 GPU 시간이나 latency는 환경별 차이가 크므로,
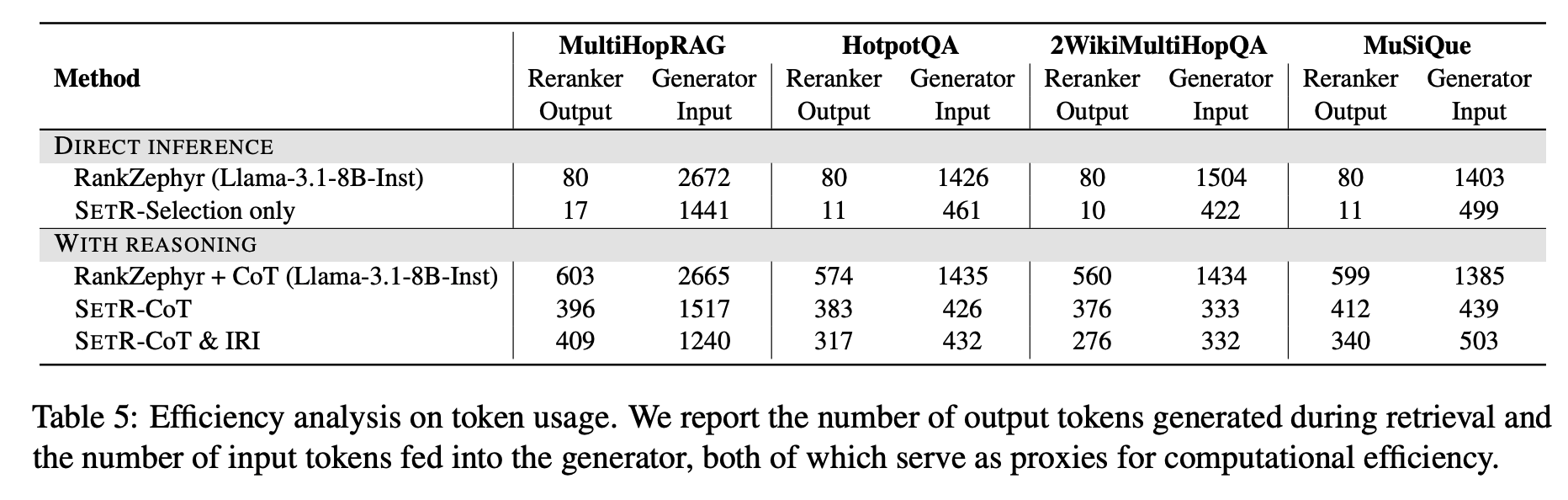
Token-level 분석을 효율성의 대리 지표로 사용:
(1) 입력 토큰 수: generator에 넘기는 passage 길이 합계
(2) 출력 토큰 수: retrieval reasoning 과정에서 발생한 토큰 양
-
SETR는 reranking보다 훨씬 적은 입력 토큰을 사용.
예: MultiHopRAG에서
SETR-CoT & IRI → 1,240 input tokens
RankZephyr → 2,672 input tokens (2배 이상) -
성능(정답률, F1)은 줄지 않고 오히려 더 나음.
SETR variant 간 비교:
SETR-Selection only: 가장 효율적 (토큰 사용량 최소)
SETR-CoT & IRI: 약간 더 많은 토큰 사용(프롬프트 길이 ↑),
하지만 그만큼 정답률·리콜 성능↑ -
시사점:
SETR는 성능-효율 trade-off spectrum을 제공 →
자원 제약·응답 지연(latency budget)에 따라 선택 가능.
