LongRAG는 검색 단위를 4,000 토큰으로 30배 확장하여 전체 검색 단위를 2,200만 개에서 60만 개로 줄임으로써 답변 정확도를 높인 연구입니다. 검색된 약 3만 토큰의 텍스트를 장문 처리가 가능한 LLM에 입력하여 제로샷 방식으로 답변을 추출한 결과, 별도의 훈련 없이 NQ에서 62.7%, HotpotQA에서 64.3%의 정확도(EM)를 달성합니다.
이 연구에서는 아래와 같은 세 가지를 문제점으로 지적하고 있습니다.
- 검색기(리트리버)와 독자(리더) 간의 불균형:
검색기는 많은 양의 데이터를 검색해야 하므로 부담이 크고 "무겁다"고 표현됩니다.
독자는 짧은 단위에서 답을 생성하는데, 이 과정은 비교적 가볍지만 그로 인해 중요한 맥락 정보가 사라질 수 있습니다. 즉, 짧은 단위에서 의미가 손실되어 정확한 답을 생성하기 어려울 수 있습니다.
- 짧은 단위에서 발생하는 문제:
짧은 단위는 맥락을 온전히 담기 어렵기 때문에, "어려운 네거티브"(잘못된 답변을 유도하는 정보)가 발생할 가능성이 높습니다. 이는 잘못된 정보를 검색하거나 답을 도출하는 데 방해가 될 수 있습니다.
- 최근 LLM(대형 언어 모델)의 잠재력 미활용:
짧은 단위에 의존하다 보니, 최신 기술인 LLM을 충분히 활용하지 못하고, 그에 따른 성능을 최대로 끌어내지 못하는 상황이 발생합니다.
이 연구에서는 위의 문제를 해결하기 위해 LongRAG라는 방법을 제안합니다. LongRAG는 긴 검색기와 긴 독자를 사용해, 위키백과 데이터를 더 큰 단위로 묶어서 처리합니다. 이렇게 하면 검색할 데이터의 양이 줄어들고, 검색기의 부담도 덜어져 효율적인 검색이 가능합니다. 결과적으로 더 적은 수의 단위만으로도 강력한 검색 성능을 얻을 수 있습니다. 또한, 이 단위들을 기존의 긴 문맥을 처리할 수 있는 LLM에 넣어 답을 생성하면 훈련 없이도 매우 높은 성능을 보입니다.
LongRAG
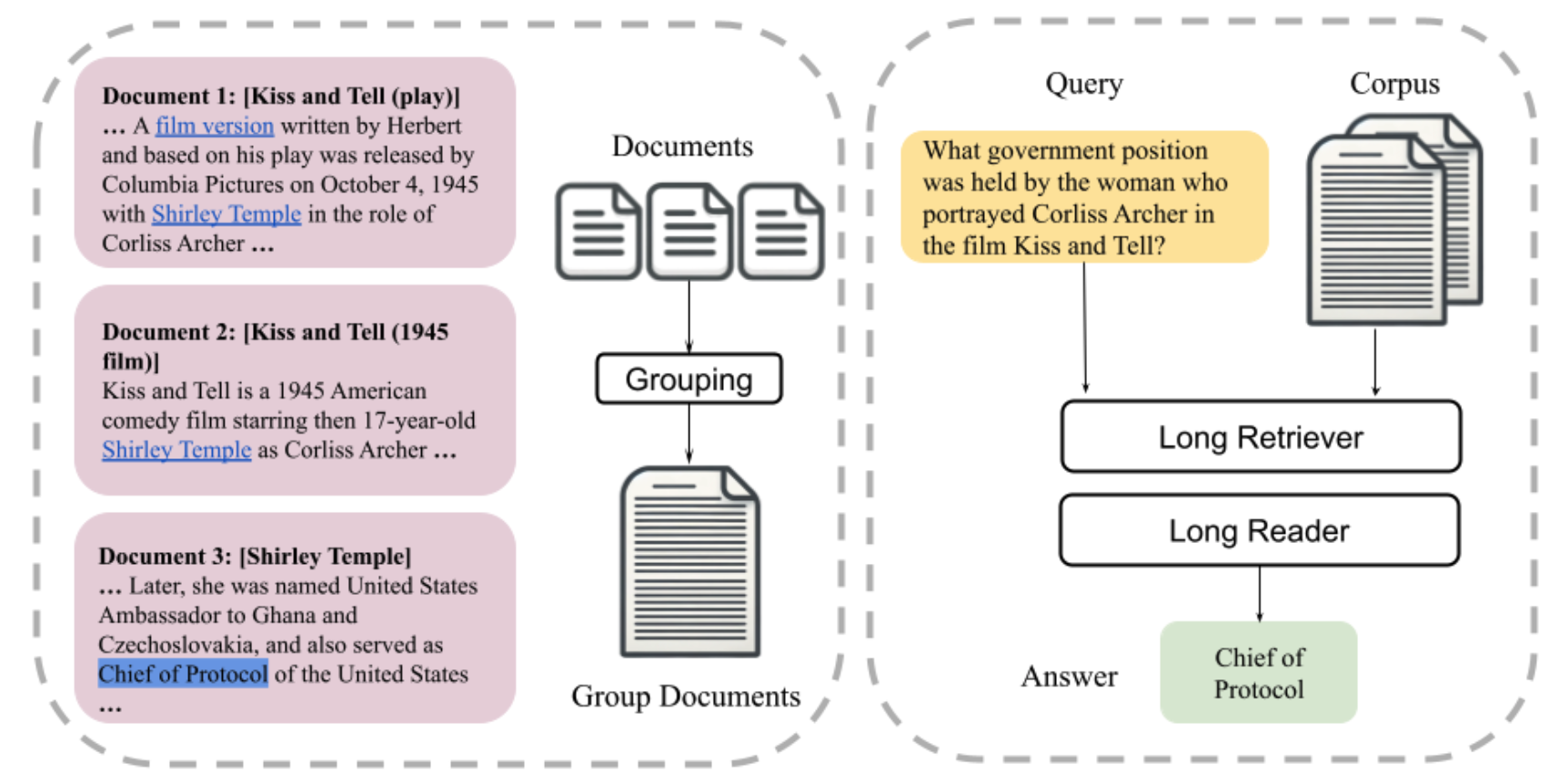
LongRAG는 두 가지 주요 구성 요소로 이루어져 있습니다: Long Retriever(긴 검색기)와 Long Reader(긴 독자). 전통적인 RAG는 많은 수의 짧은 검색 단위를 사용하지만, LongRAG는 긴 검색 단위를 사용하여 검색된 단위가 독자에게 전달되는 수를 몇 개로 제한합니다.
전통적인 RAG는 짧은 단위를 사용하며, 정확한 정보를 포함한 세부적인 단위를 찾는 데 중점을 둡니다. 반면, LongRAG는 회수율(recall)을 중요시하며, 더 거친(granular) 단위로 관련 정보를 검색합니다. 이로 인해 검색기는 정확한 정보를 찾기보다는 관련 정보를 더 넓은 범위에서 찾고, 독자가 이 정보에서 정확한 답을 추출하는 구조로 설계됩니다.
코퍼스(C): LongRAG의 코퍼스는 D개의 문서 집합 {d1, d2, ..., dD}입니다.
긴 검색기의 역할: LongRAG에서 긴 검색기는 질문(q)과 코퍼스(C)를 입력으로 받아 필터링된 텍스트 집합 CF(C의 부분집합)를 반환합니다. 전통적인 RAG에서는 이 CF가 보통 몇 백 토큰으로 구성된 작은 단위입니다. 반면 LongRAG에서는 CF가 4K 토큰 이상인 긴 단위로, 정확하지는 않지만 관련된 정보들을 포함하게 됩니다.
Long Retrieval Unit
4K 토큰 이상을 포함하는 검색 유닛을 만듭니다.
NQ와 HotpotQA는 두 가지 위키백과 기반의 질문-답변 작업입니다. 이들 작업에서 문서 간의 관계를 나타내기 위해 텍스트 내에 내장된 하이퍼링크를 사용하여 문서 간 연결성을 나타냅니다. 이 연구에서는 하이퍼링크를 주요 기준으로 문서 간의 관계를 설정했습니다. 위키백과에서는 문서들 간에 하이퍼링크로 연결된 경우가 많기 때문에, 이를 통해 관련 있는 문서를 쉽게 그룹화할 수 있습니다.

이 알고리즘은 각 문서가 반드시 하나의 그룹에 속하도록 보장하면서, 문서 간 관련성과 토큰 수 제한을 효과적으로 고려한 그룹화 방식을 제시합니다. 특히 관련 문서의 수가 적은 문서부터 순차적으로 처리함으로써, 토큰 수 제한(S)을 준수하면서도 서로 관련된 문서들을 최대한 같은 그룹으로 묶을 수 있습니다. 이러한 단계적 그룹 병합 방식은 대규모 문서 집합을 효율적으로 구조화하는 데 효과적입니다.
예시 조건:
최대 토큰 수(S) = 10, 문서들(D) = {A, B, C, D, E}, 각 문서의 토큰 수는 모두 3이라고 가정
문서 간 관련성:
A는 B, C와 관련 (deg(A) = 2)
B는 A와 관련 (deg(B) = 1)
C는 A, D와 관련 (deg(C) = 2)
D는 C, E와 관련 (deg(D) = 2)
E는 D와 관련 (deg(E) = 1)
알고리즘 실행
먼저 deg(d) 기준으로 정렬: B(1), E(1), A(2), C(2), D(2) 순서로 처리
-
B부터 처리:
related_groups가 비어있음 (아직 생성된 그룹 없음)
새 그룹 g1 = {B} 생성
-
E 처리:
related_groups가 비어있음 (B와 관련 없음)
새 그룹 g2 = {E} 생성
-
A 처리:
B가 g1에 있으므로 g1이 related_groups에 추가
새 그룹 시작: {A}
g1과 병합 가능 (토큰 수 6 ≤ 10)
결과: g1 = {A, B}, g2 = {E}
-
C 처리:
A가 g1에 있으므로 g1이 related_groups에 추가
새 그룹 시작: {C}
g1과 병합 가능 (토큰 수 9 ≤ 10)
결과: g1 = {A, B, C}, g2 = {E}
-
D 처리:
C가 g1에 있고, E가 g2에 있어서 두 그룹 모두 related_groups에 추가
새 그룹 시작: {D}
g1과는 병합 불가 (토큰 수 12 > 10)
g2와 병합 가능 (토큰 수 6 ≤ 10)
결과: g1 = {A, B, C}, g2 = {D, E}
최종 결과
그룹 1: {A, B, C}
그룹 2: {D, E}
Long Retriever
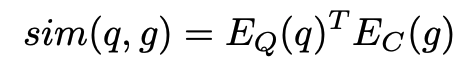
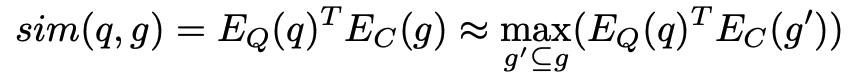
전체 검색 유닛 에 대한 유사도를 계산하는 대신, 여러 청크에 대한 유사도를 계산하고, 그 중 최대 값을 취합니다. 이 방법은 MaxP 디자인(Dai & Callan, 2019)을 따른 것입니다. 간단히 말해서, 검색 유닛 를 더 작은 청크 로 나누어 각 청크와의 유사도를 계산하고, 그 중 가장 높은 유사도를 사용하는 방식입니다.
g′의 크기는 여러 가지 수준으로 설정될 수 있으며 아래 결과에 따라 512 토큰을 기준으로 임베딩을 생성합니다.

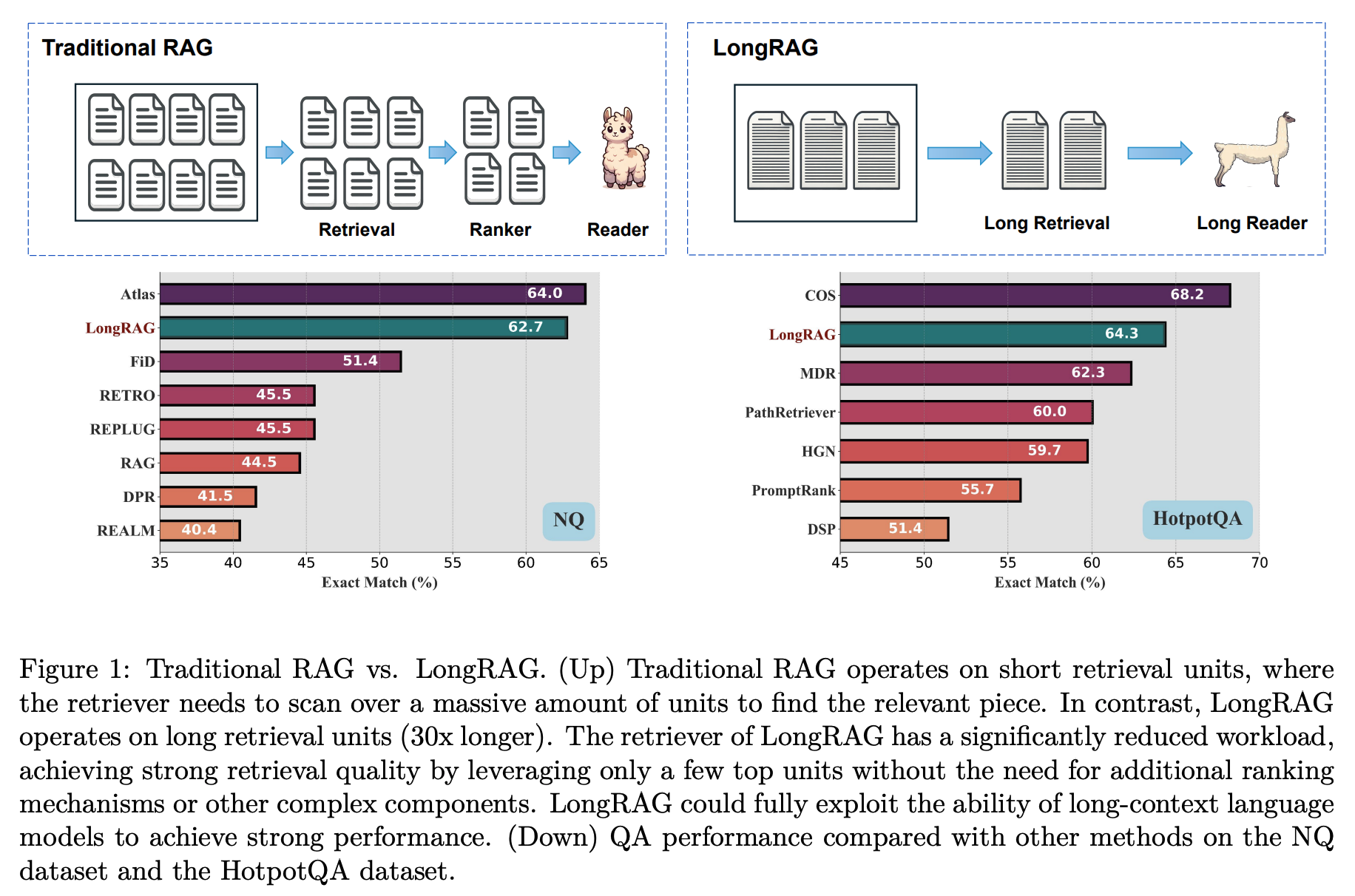
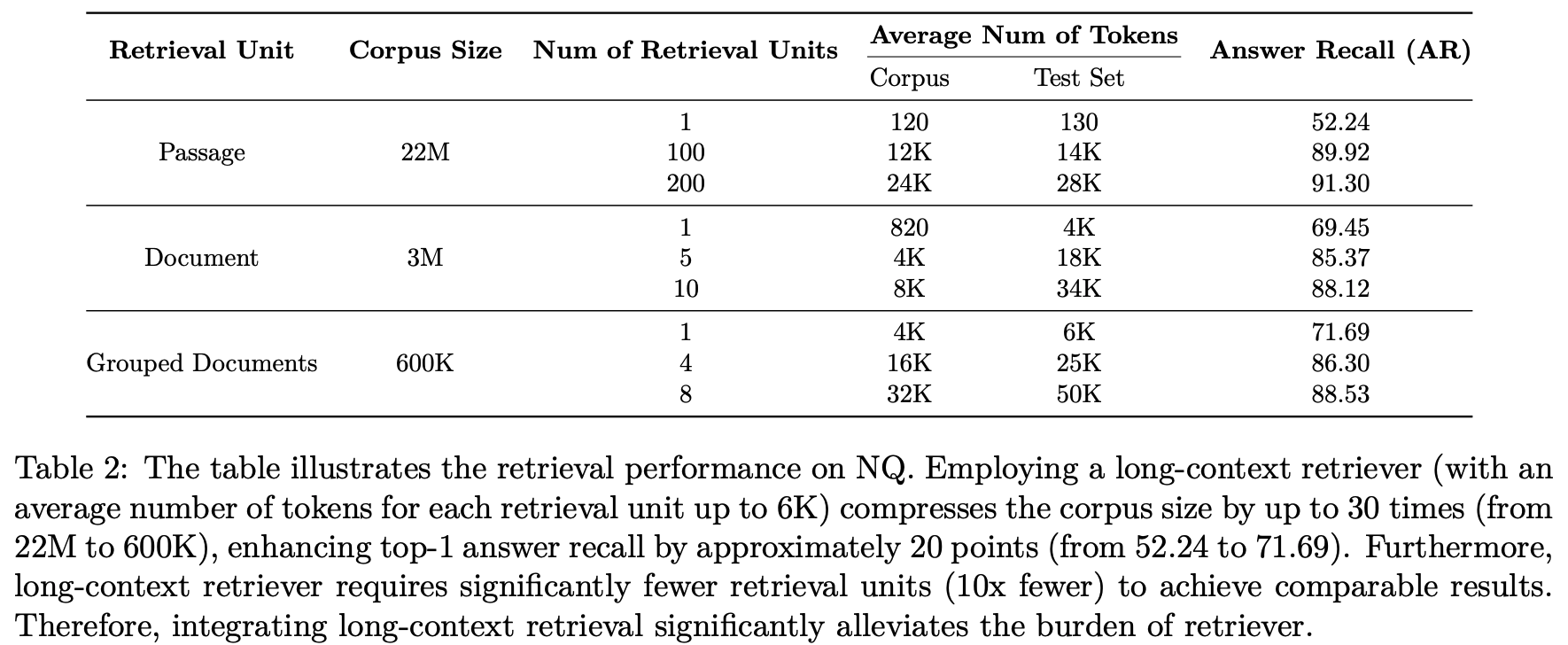
NQ에서의 긴 문맥 검색기를 사용하면(각 검색 단위당 평균 토큰 수가 6K에 달함) 코퍼스 크기를 최대 30배(22M에서 600K로) 압축할 수 있으며, 이는 상위 1번 답변 회수(Top-1 answer recall)를 약 20포인트(52.24에서 71.69로) 향상시킵니다. 또한, 긴 문맥 검색기는 비슷한 성과를 달성하기 위해 필요한 검색 단위 수가 훨씬 적습니다(10배 적음). 따라서 긴 문맥 검색을 통합함으로써 검색기의 부담을 크게 덜 수 있습니다.
NQ 데이터셋에서:
- 패시지 수준의 검색 유닛을 사용할 경우, k는 약 100개 이상이 될 수 있습니다. 이는 각 패시지가 상대적으로 짧기 때문에, 많은 유닛이 필요합니다.
- 문서 수준의 검색 유닛을 사용할 경우, k는 약 10개 정도로 설정됩니다. 문서가 더 길기 때문에, 상대적으로 적은 수의 유닛만 필요합니다.
- 그룹화된 문서를 검색 유닛으로 사용할 경우, k는 보통 4~8개 사이로 설정됩니다. 여러 문서가 하나의 유닛에 포함되어 있기 때문에, 더 적은 수의 유닛으로도 충분한 정보를 제공할 수 있습니다.
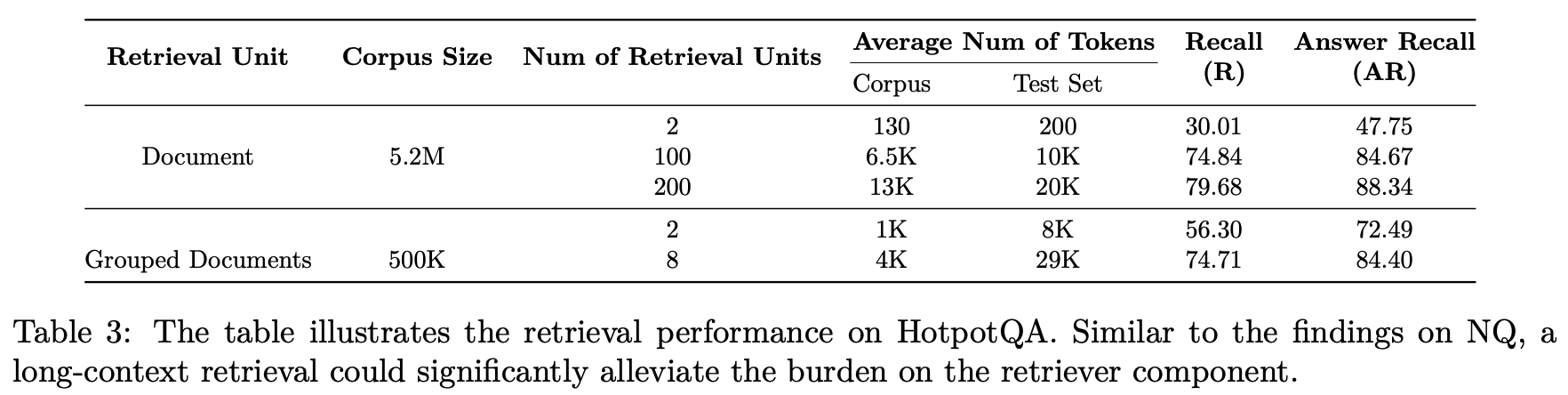
Long Reader
관련된 지침(i), 질문(q), 그리고 긴 검색 결과(CF)를 LLM에 입력하여, LLM이 긴 문맥을 기반으로 추론하고 최종 출력을 생성하도록 합니다. 여기서 중요한 점은 긴 리더로 사용되는 LLM이 긴 문맥을 처리할 수 있어야 하며 과도한 위치 편향을 보이지 않아야 한다는 것입니다. 우리는 긴 문맥 입력을 잘 처리할 수 있는 강력한 능력을 가진 Gemini-1.5-Pro (Reid et al., 2024)와 GPT-4o (OpenAI, 2024)를 긴 리더로 선택했습니다. (Gemini 1.5 Pro: 200k tokens, GPT-4o: 128k tokens)
짧은 문맥과 긴 문맥에 대해 서로 다른 접근 방식을 사용합니다. 짧은 문맥은 보통 1K 토큰 미만을 포함하는데, 이 경우 우리는 리더에게 코퍼스에서 검색된 제공된 문맥을 기반으로 직접 답을 생성하도록 지시합니다. 반면 긴 문맥은 보통 4K 토큰 이상이므로, 짧은 문맥에서 사용한 것과 유사한 프롬프트를 사용하여 모델이 긴 문맥에서 직접 최종 답을 추출하는 방식은 종종 성능 저하를 초래한다는 것을 경험적으로 알게 되었습니다. 대신 가장 효과적인 접근 방식은 LLM을 채팅 모델로 활용하는 것입니다. 처음에는 모델이 긴 답을 출력하는데, 이 답은 보통 몇 마디에서 몇 문장까지 이어집니다. 그 후 우리는 모델에게 그 긴 답에서 추가로 짧은 답을 추출하도록 프롬프트를 제공하여 생성하게 합니다.
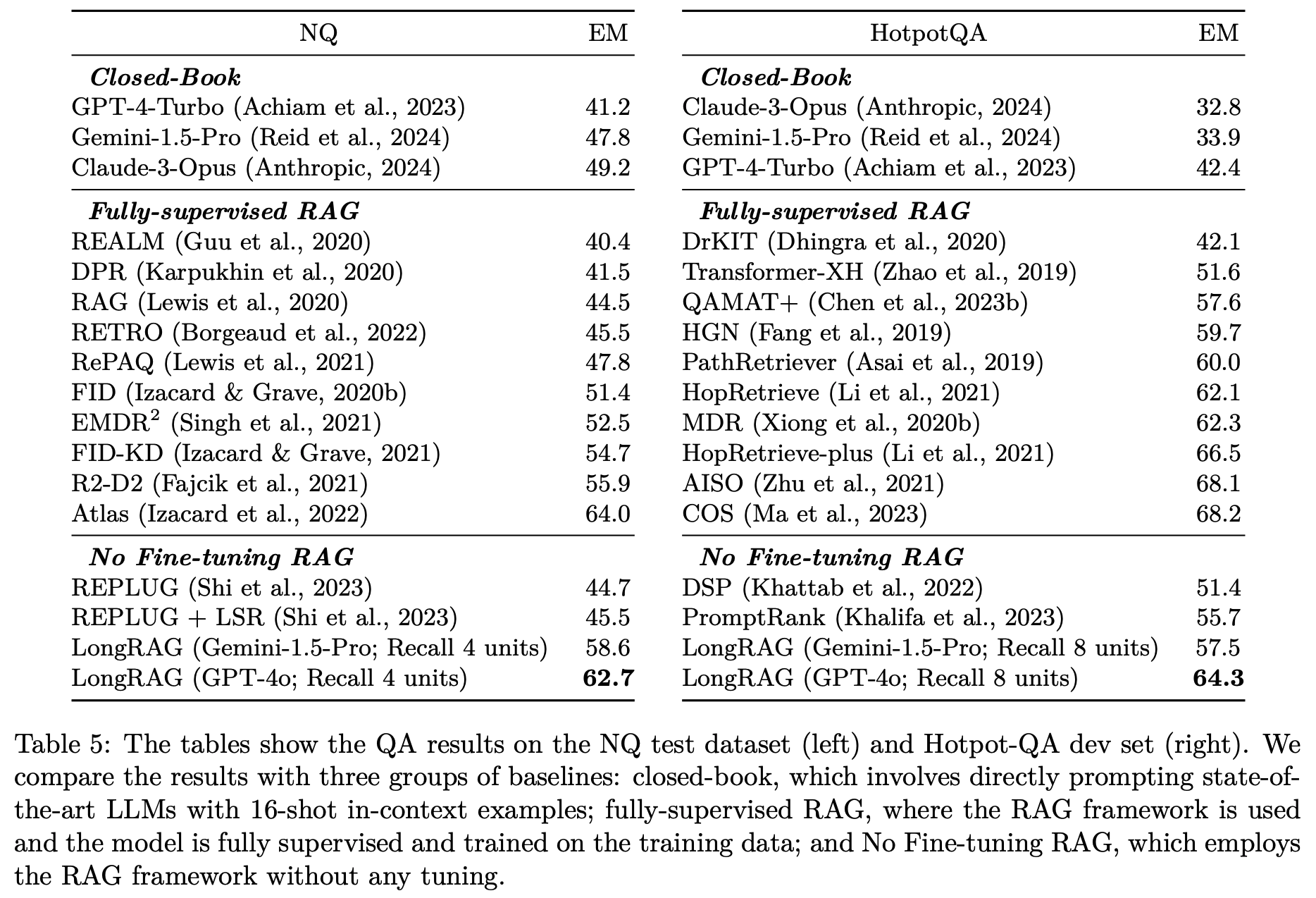
검색 유닛의 개수가 많아질수록 리더에 과부하가 발생하여 성능이 저하될 수 있으며, 적절한 개수의 한계는 Passage-Level에서는 100~200개, Document-Level에서는 5~10개, Grouped Document-Level에서는 4~8개로 나타납니다. 일반적으로 리더가 효과적으로 처리할 수 있는 컨텍스트 길이는 약 30K 토큰이며, 긴 검색 유닛(Document-Level 또는 Grouped Document-Level)을 사용할수록 문맥이 더욱 잘 보존되어 정보 전달이 정확해집니다. 따라서 검색 유닛의 크기와 개수를 적절히 조정하는 것이 리더의 성능을 극대화하는 데 중요합니다.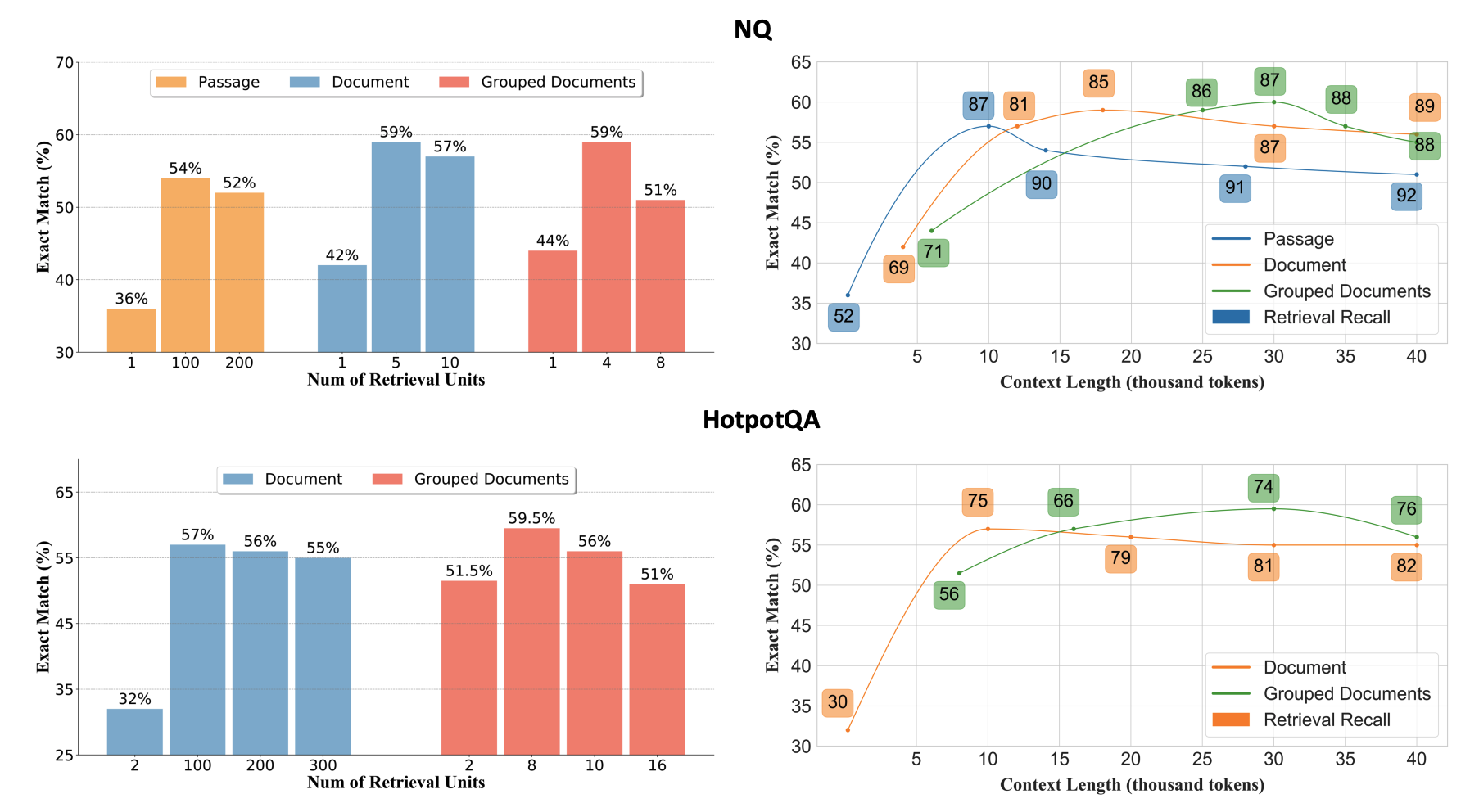
Gemini-1.5-pro, GPT-4-Turbo, GPT-4o, Claude-3-Opus, Claude-3.5-Sonnet, DeepSeek-V2-Chat 등 여섯 가지 리더 모델의 성능을 비교합니다. 실험 결과, GPT-4o가 NQ 데이터셋의 200개 테스트 질문에서 가장 높은 정확 일치(Exact Match) 점수를 기록하며, LongRAG 프레임워크에서 가장 효과적인 리더 모델임을 보여주었습니다. 이는 GPT-4o가 긴 문맥을 처리하고 이해하는 능력이 뛰어나, 중요한 정보를 보다 정확하게 추출할 수 있기 때문입니다. 따라서 주요 실험 결과는 GPT-4o를 기준으로 보고됩니다. 한편, Gemini-1.5-pro, GPT-4-Turbo, Claude-3-Opus, Claude-3.5-Sonnet 또한 유사한 성능을 보이며, LongRAG 프레임워크에서 효과적인 리더 역할을 수행할 수 있음을 확인할 수 있습니다. 반면, DeepSeek-V2-Chat은 오픈소스 LLM 중에서는 가장 우수한 성능을 보이지만, 앞선 다섯 가지 LLM에 비해 성능이 크게 저하되었습니다. 이 실험 결과는 현재 LongRAG 프레임워크가 LLM의 긴 문맥 이해 능력에 크게 의존하고 있음을 시사합니다.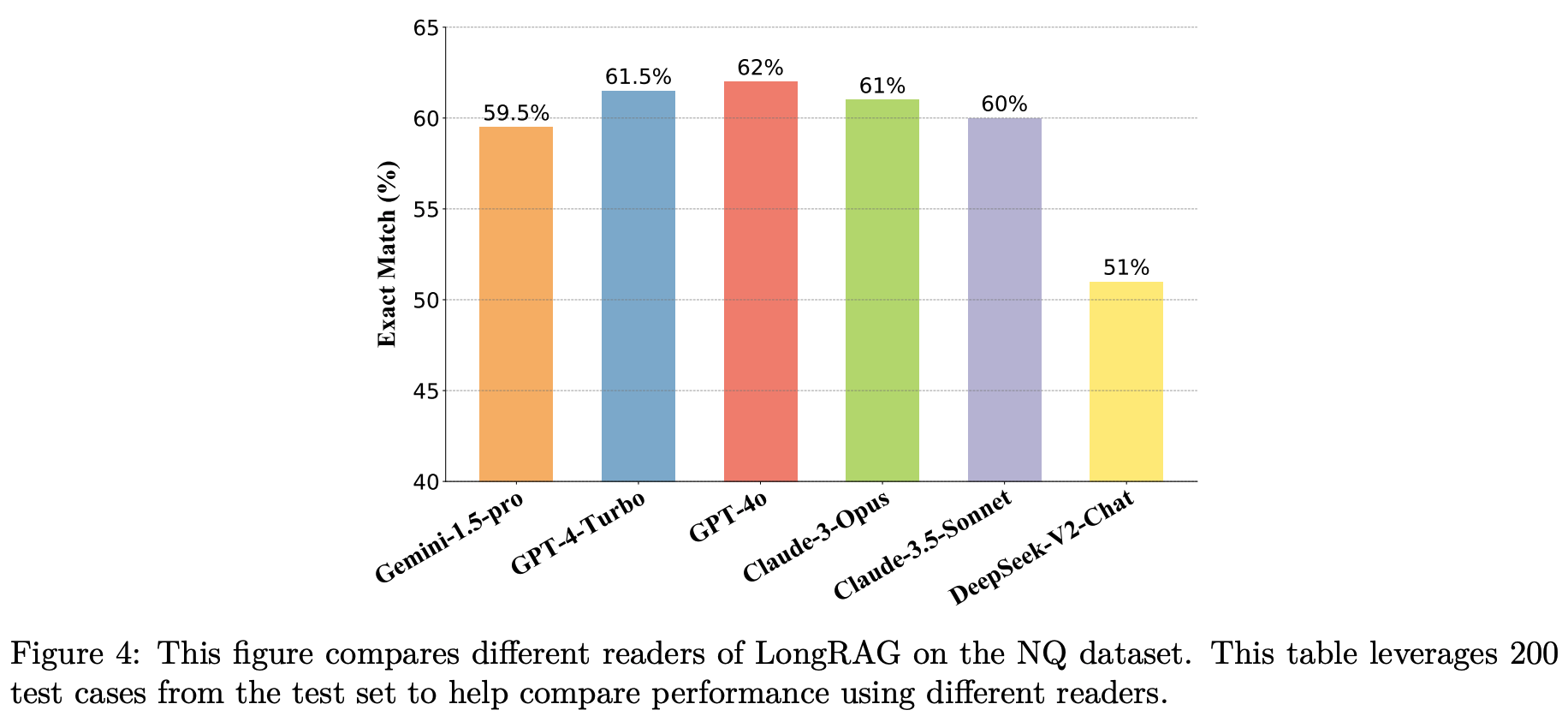
DeepSeek-V2-Chat은 총 2360억 개의 파라미터를 가진 고급 Mixture-of-Experts(MoE) 언어 모델로, 각 토큰당 210억 개의 파라미터가 활성화됩니다. 최대 12만 8000개의 토큰을 처리할 수 있으며 MoE 설계를 통해 기존 모델 대비 학습 비용을 42.5% 절감하고, KV 캐시 사용량을 93.3% 감소시키며, 생성 속도를 5.76배 향상시켰습니다. https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat-0628#4-model-architecture