- In-batch negative를 MLM에 적용시킨 논문
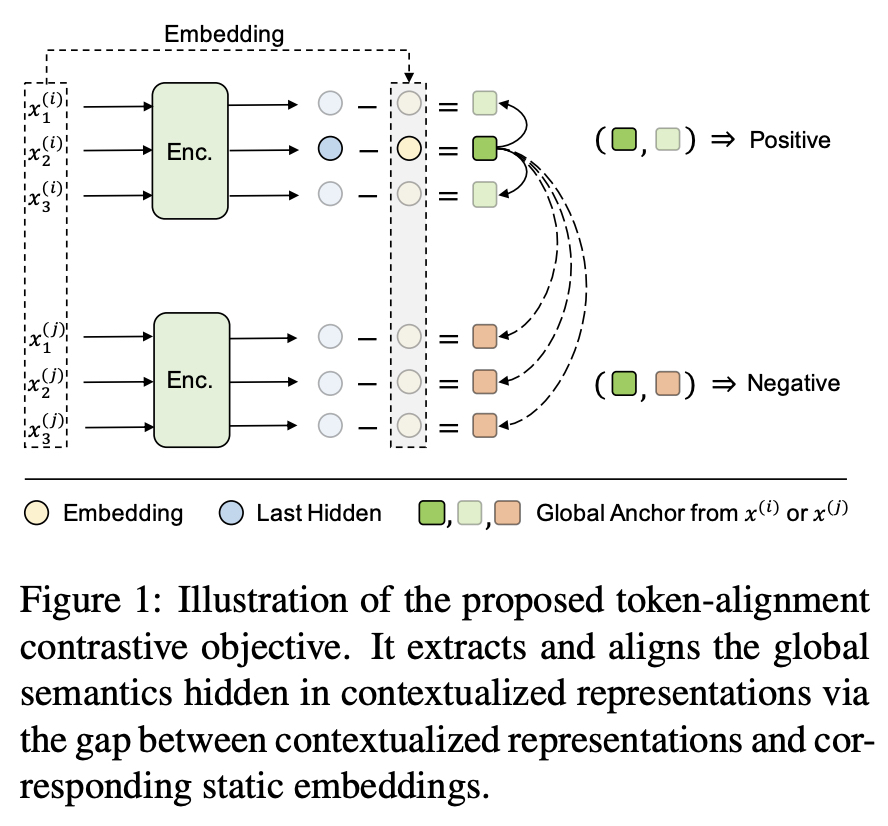
- last hidden - embedding : 온전한 문맥에서 온 의미
- Positive : 같은 문맥
- Negative : 다른 문맥
TACO
Token-alignment Contrastive loss
-
Global bias
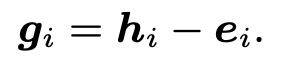
-
nearby tokens c in the same context
- Temperature parameter : 0.07
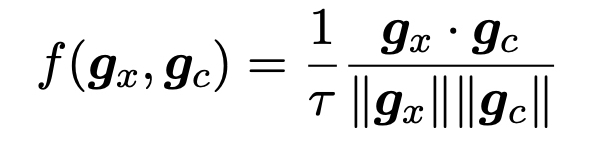
-
In-batch negative 개념이 포함된 항 : Positive pair & Negative pairs
- the k-th negative sample of x and K is the size of negative samples.
- Negative sample size K : 50 (Positive sample size 5)
- l2-norm function
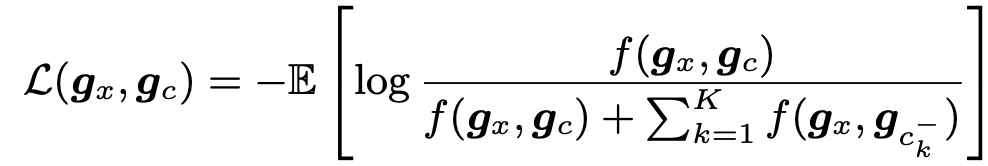
-
S는 배치 안의 token을 의미한다.
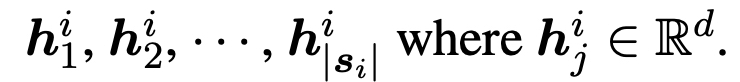
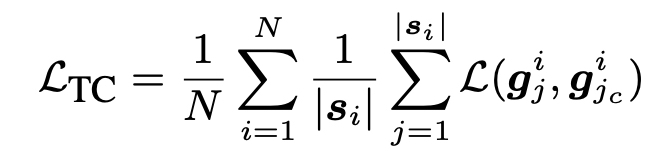
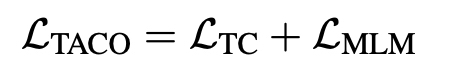
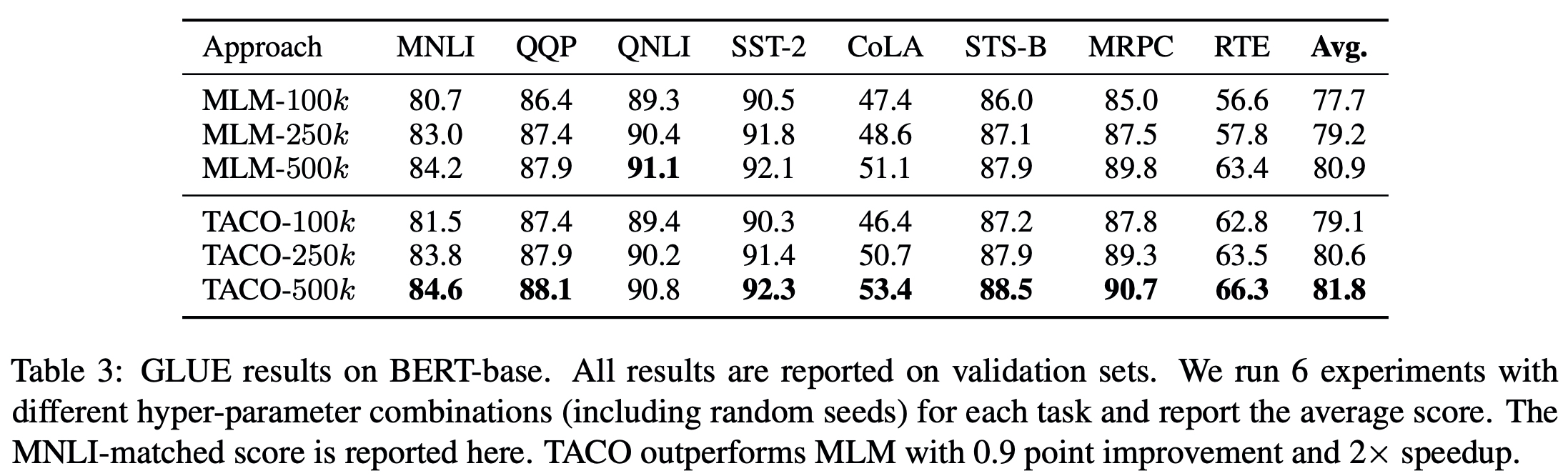
Experiments
-
빠르게 수렴한다. (BERT-small)
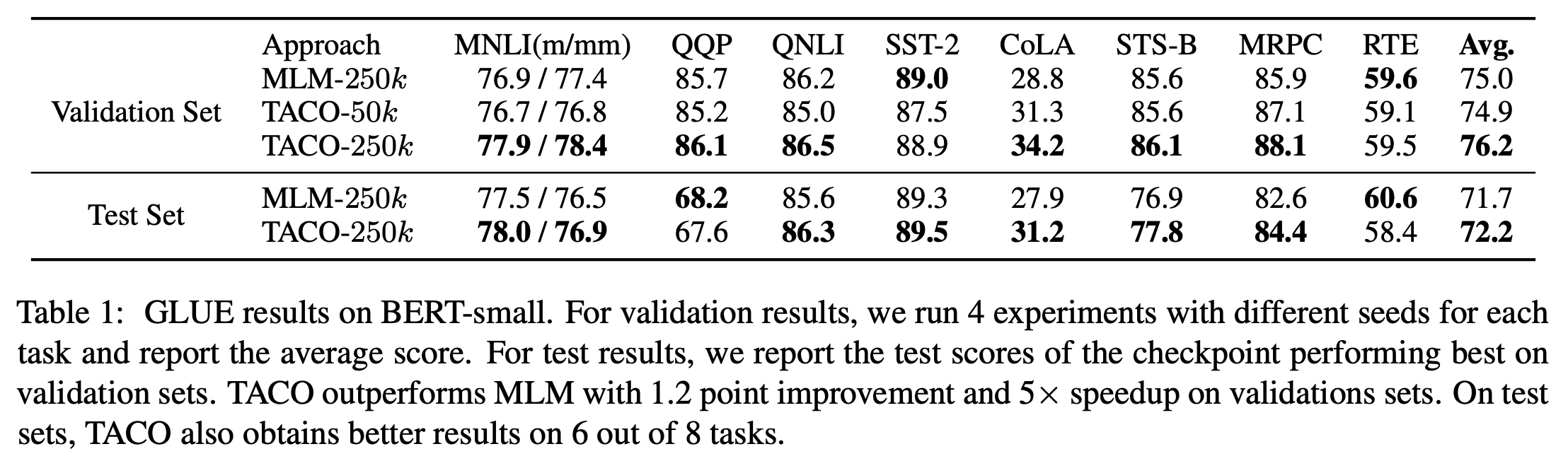
-
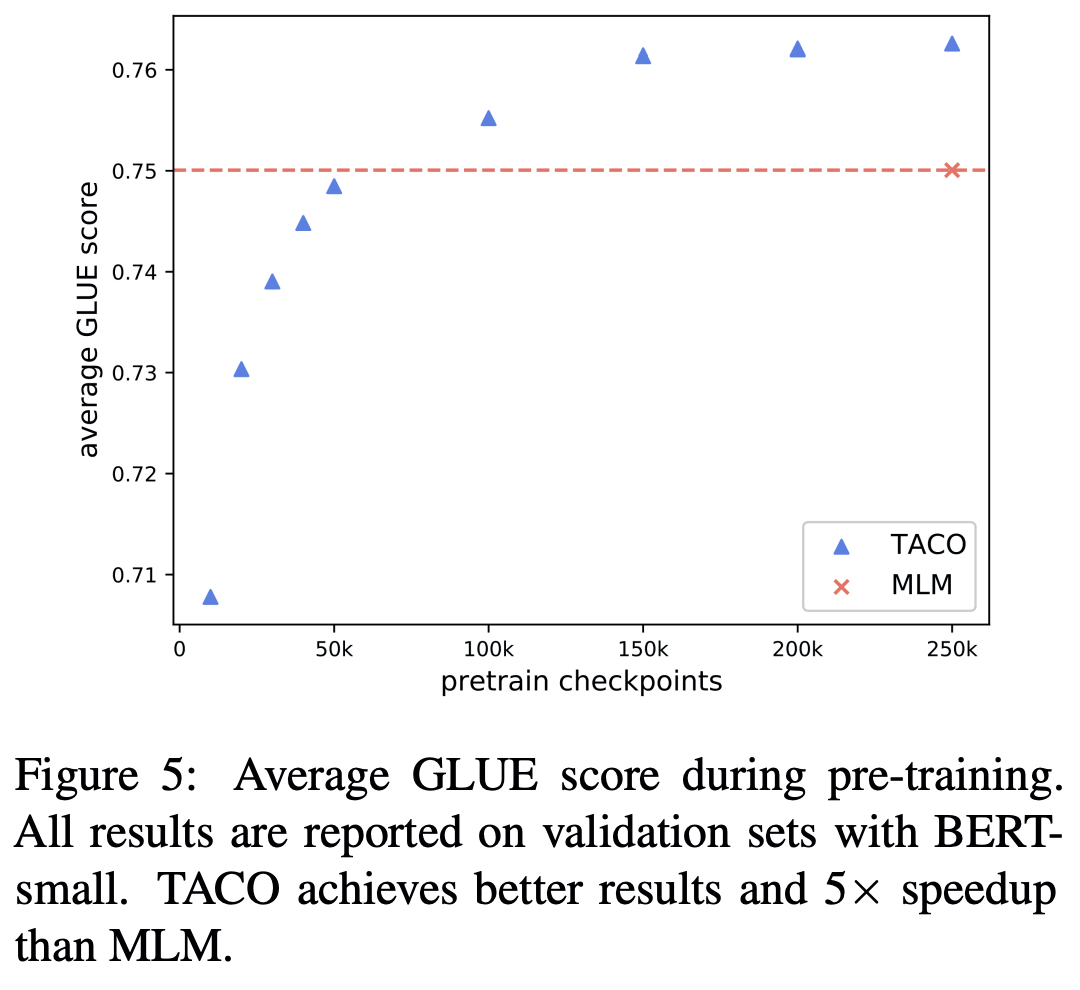
적은 데이터 셋(1/4)으로도 BERT 수치만큼 도달할 수 있다.
-
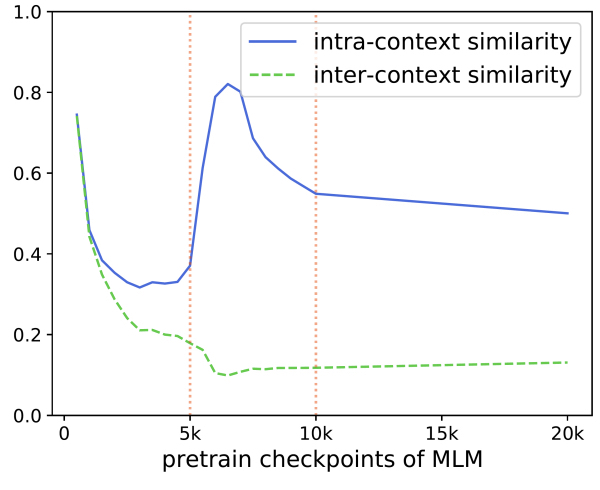
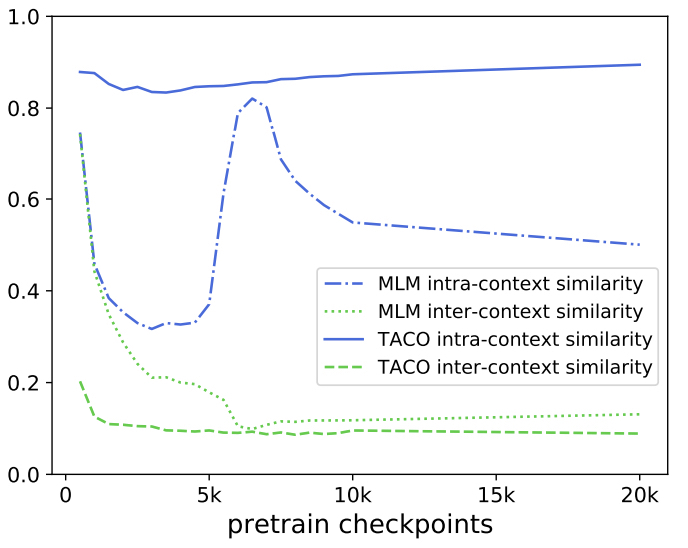
같은 문맥(intra-context)에서 온 토큰들의 유사성 vs 다른 문맥(inter-context)에서 온 토큰들의 유사성
- gap이 클수록 잘 학습되었다고 할 수 있다.
- 초기에는 random initializing 때문에 같이 줄어드는 양상
- 5K~10K, 같은 문맥 내에서의 유사도가 올라간다.
- 하지만 학습 후반부로 갈수록 gap이 줄어든다. (각 문맥 정보에만 너무 몰두됨)

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻