TABLEFORMER
TAPAS 다음으로 나온 논문 (ACL 2022)
-
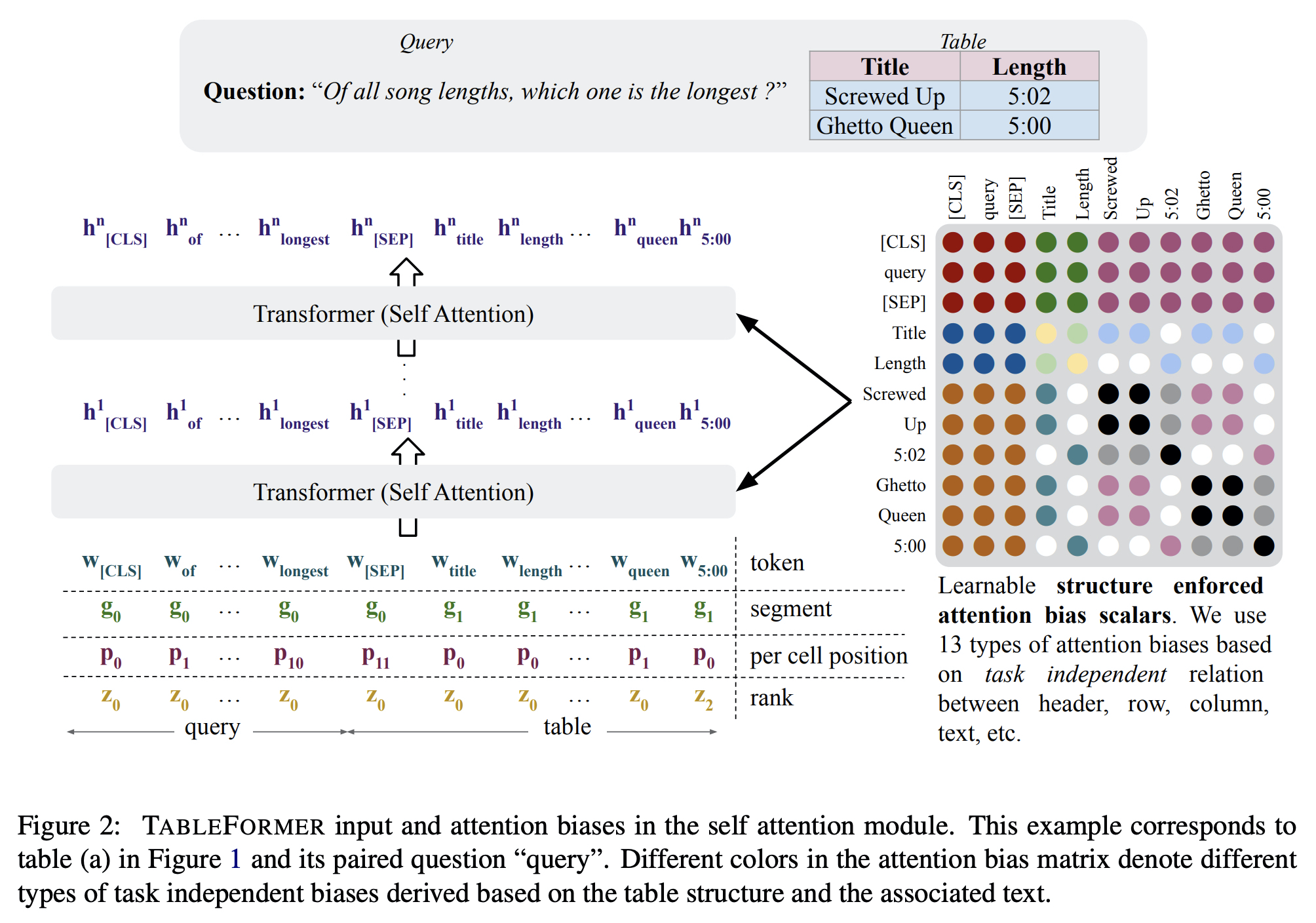
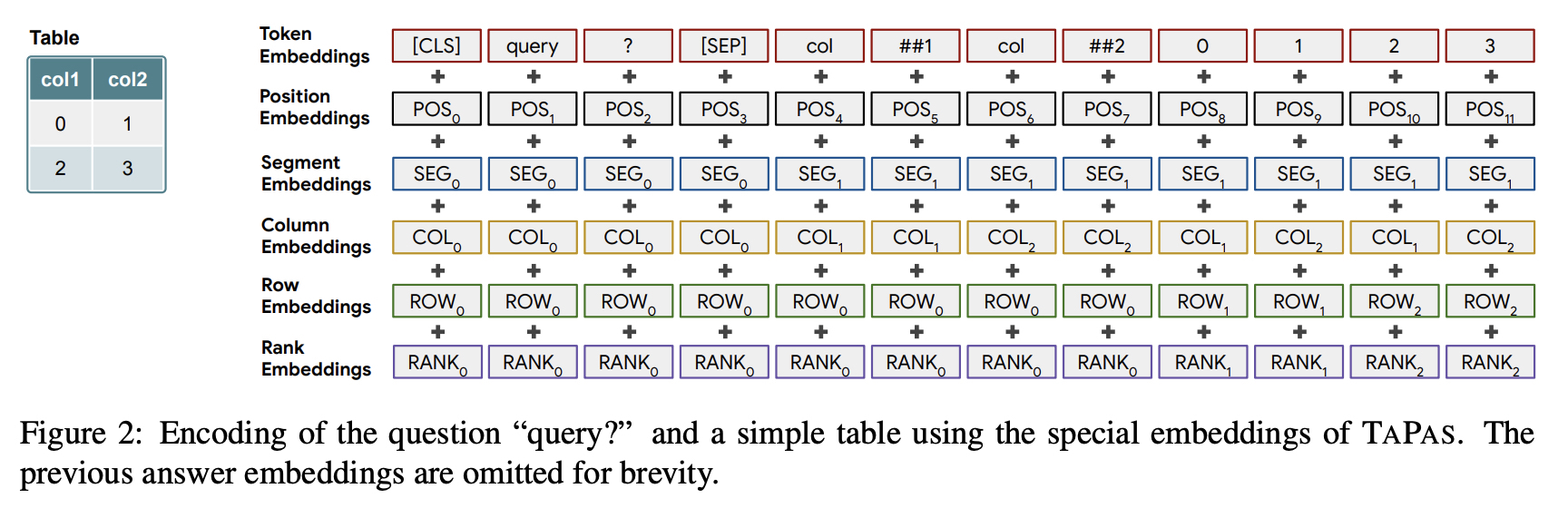
TAPAS 논문은 아래 그림에서 여러가지 임베딩이 결합되어 트랜스포머 구조로 들어간다. Column, Row, Rank 정보를 임베딩을 통해 넣어줌으로써 입력값에 테이블 정보들이 포함되도록 하였다.
-
TABLEFORMER에서는 세 가지 변형을 통해서 TAPAS를 보완하였다.
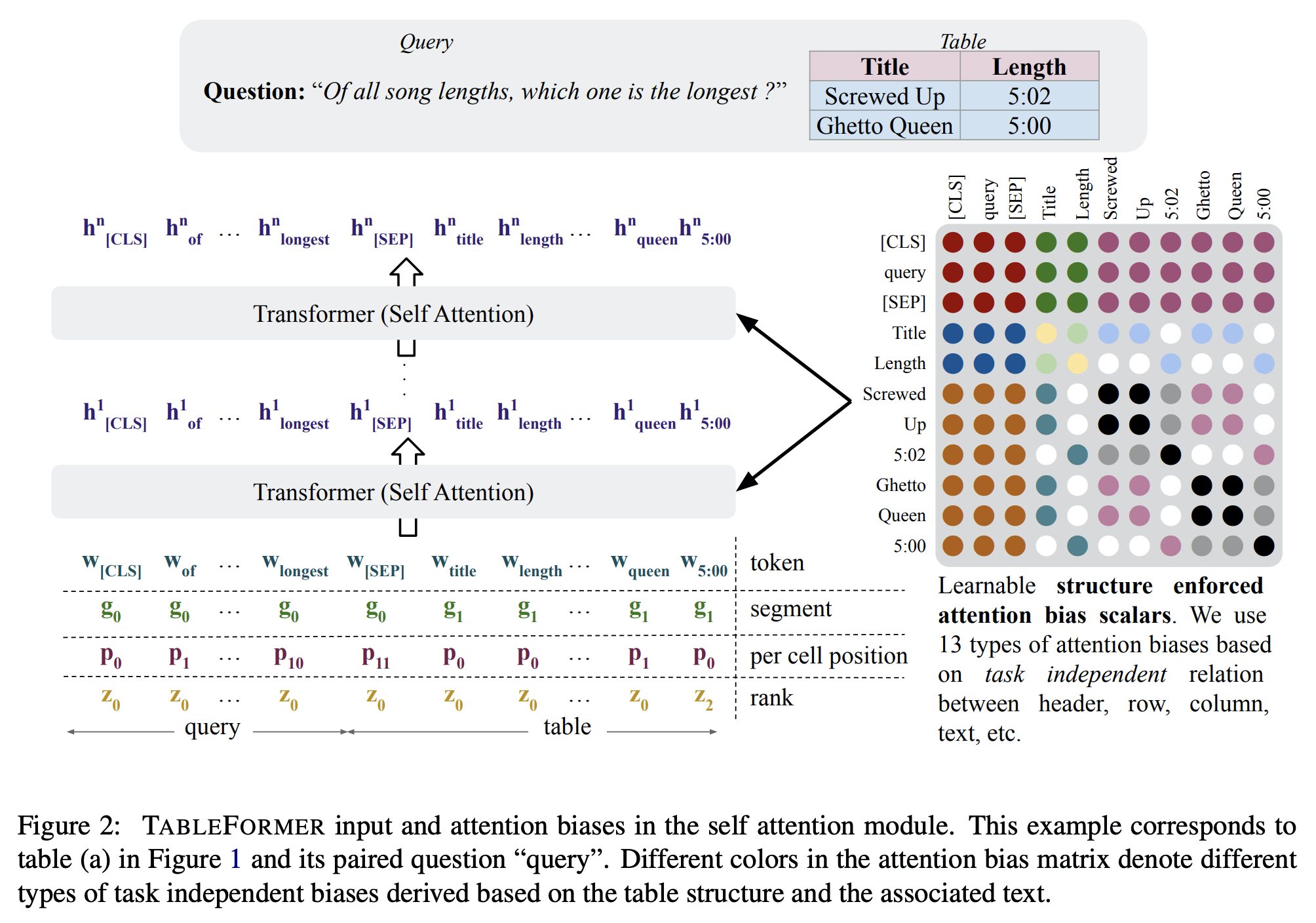
- Row embeddings, Column embeddings을 사용하지 않음으로써 행과 열의 순서를 반영하지 않도록 하였다.
- 위치 정보를 셀 내에서만 작동하도록 했다. (셀 안에서 첫 번째인지 두 번째인지)
- Attention bias를 사용하였다.
- 같은 행이나 열, 같은 header를 가지는 경우 동일한 attention bias를 공유함으로써 attention 연산을 할 때에 해당 정보를 포함하도록 하였다.
Experiments
- TAPAS 보다 높은 점수를 보였으며, 행과 열이 뒤바뀌더라도 점수가 떨어지지 않는 것을 보였다.
- Perturbation Evaluation Set : Robustness 확인하기 위해서 각 테스트 데이터를 이용하여 만들었다. (Row and column perturbations)
SQA
- Sequential QA (SQA) (Iyyer et al., 2017) datasets
- SQA is composed of 6,066 question sequences (2.9 question per sequence on average), constructed by decomposing a subset of highly compositional WTQ questions.
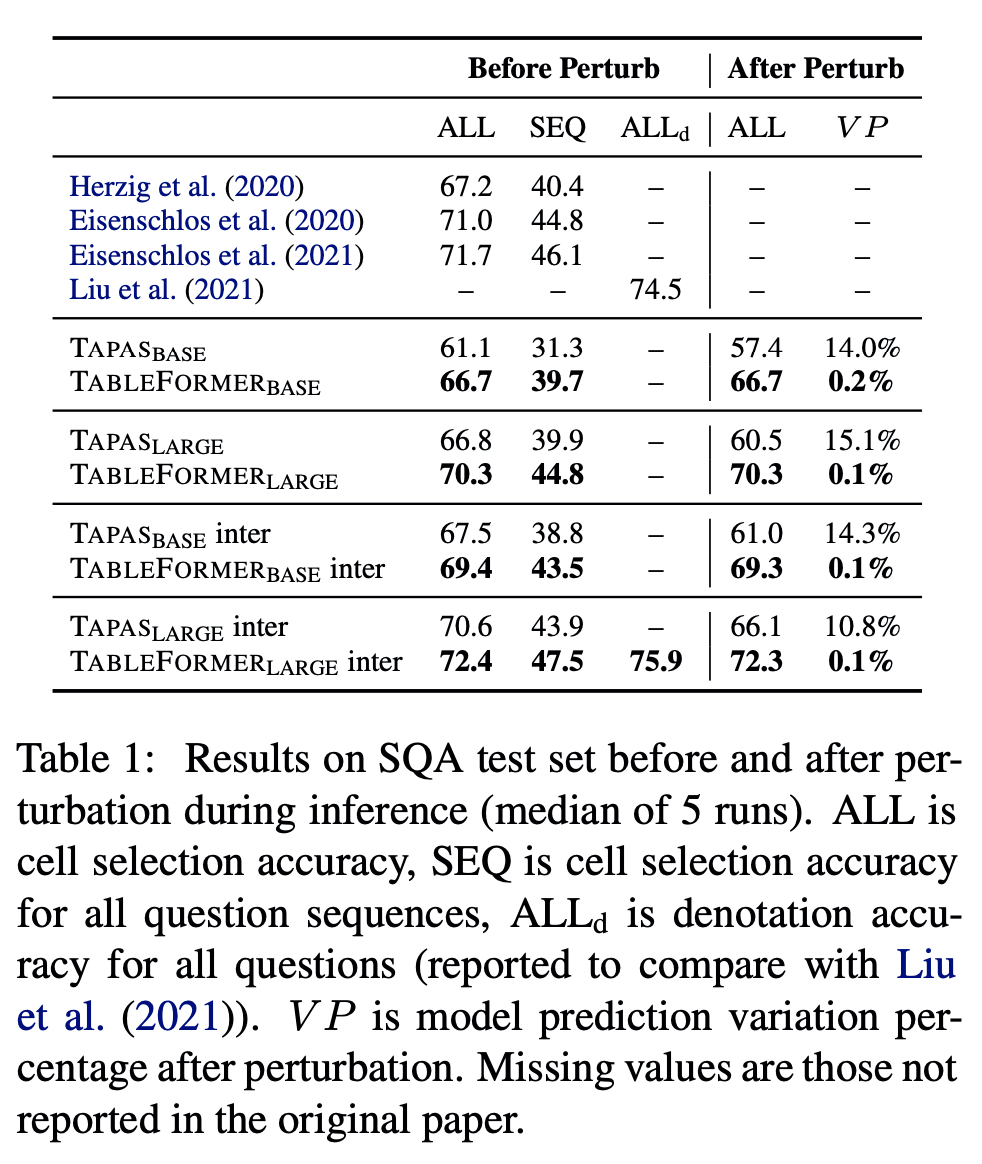
- ALL : cell selection accuracy for all questions
- SEQ : cell selection accuracy for all sequences
- ALL(d) : the denotation accuract for all questions
- VP : a lower bound of example prediction variation
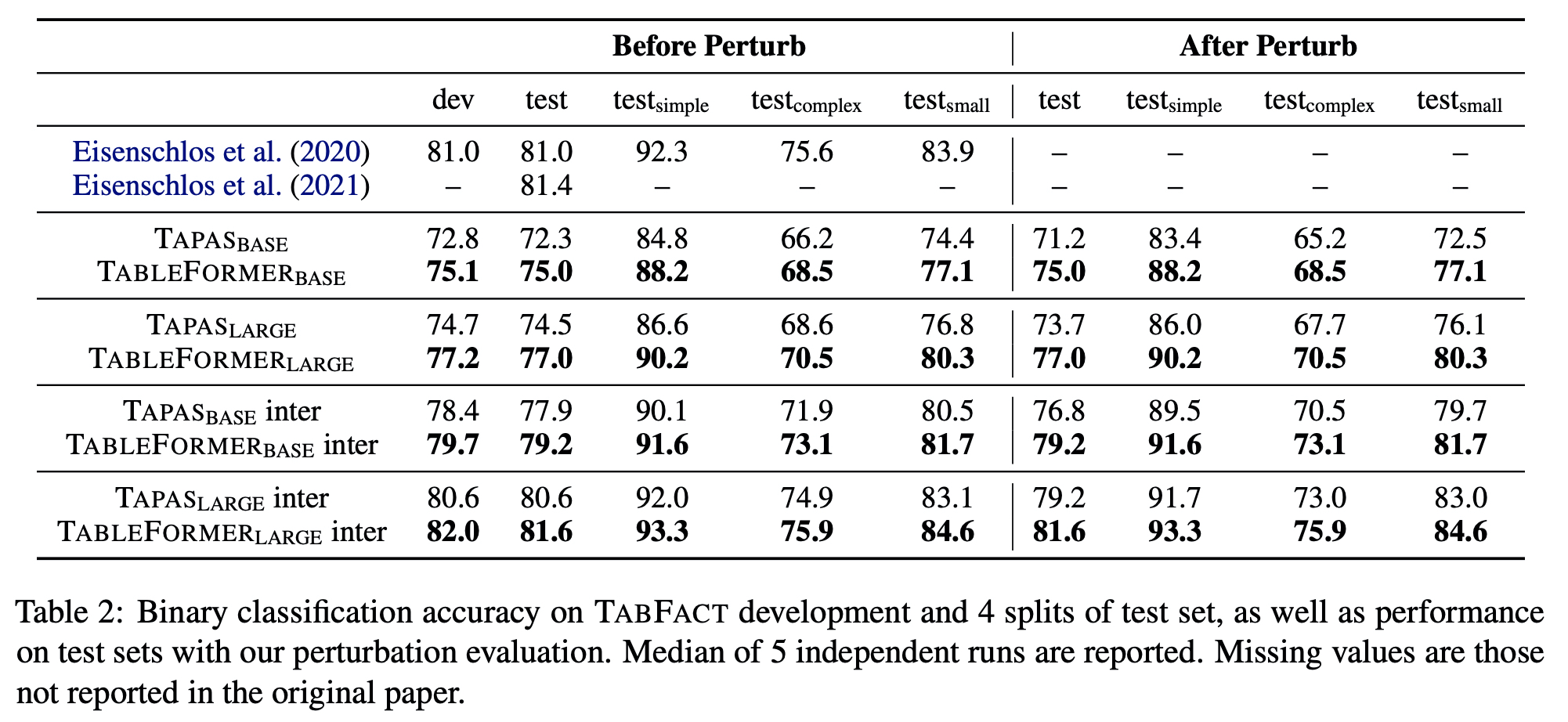
TABFACT
- Table-text entailment task.
- Tables were extracted from Wikipedia and the sentences were written by crowd workers. Among total 118, 000 sentences, each
one is a positive (entailed) or negative sentence.
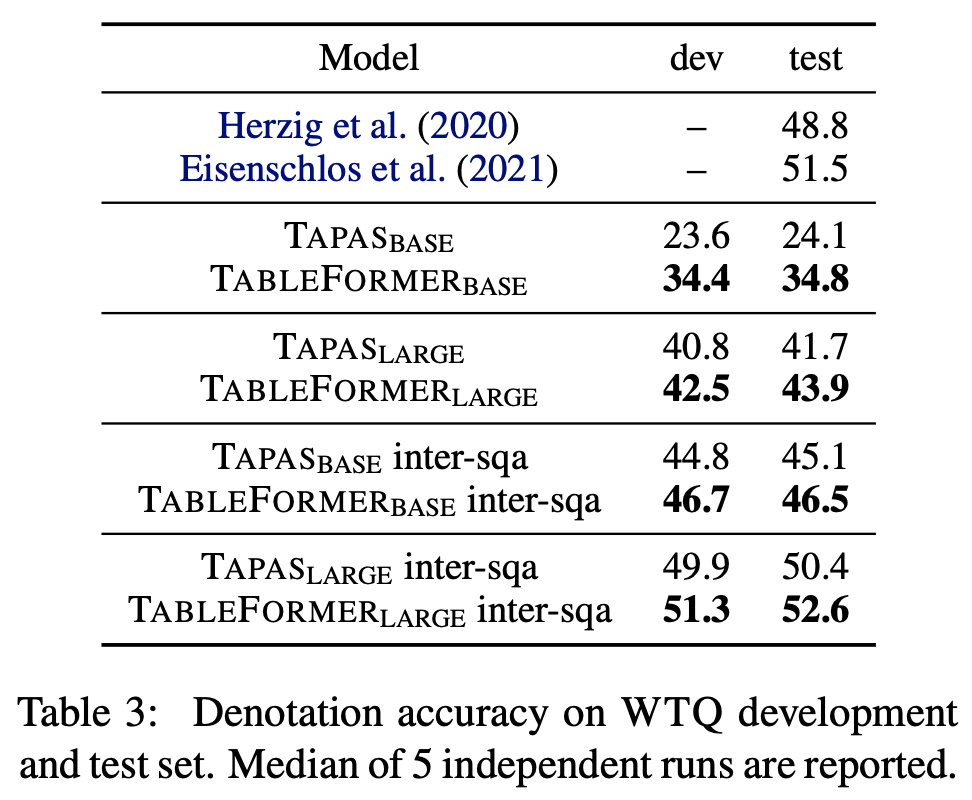
WTQ
- WikiTableQuestions (WTQ) (Pasupat and Liang, 2015)
- WTQ was crowd-sourced based on complex questions on Wikipedia tables.
- To get better performance on WTQ, we follow Herzig et al. (2020) to further pretrain on SQA dataset.

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻