PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
NLP Papers
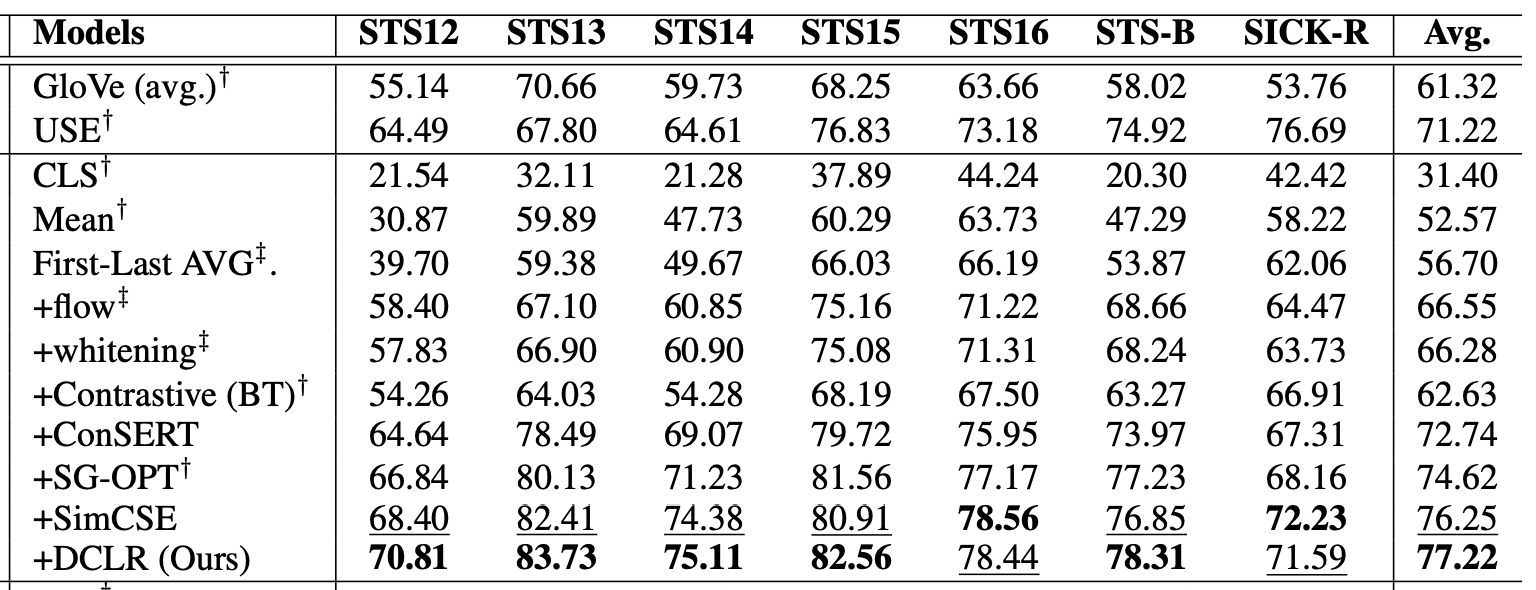
Sentence similarity task에서 가장 높은 점수를 기록한 모델이다.
(EMNLP 2022 main)



PCL모델에 대해서 알아보자.
이 논문에서는 하나의 positive 만을 가지고 contrastive learning을 하면 shortcut 문제가 발생할 수 있고(bias 발생), positive 에서 줄 수 있는 정보량이 한정적이라고 보았다. 이런 점에서 여러 positive를 사용하도록 하였다.
여기에서 제시하는 Peer-Contrastive Learning으로 아래 두 가지를 수행하고자 했다.
- peer-positive contrast
- peer-network cooperation
peer-positive contrast를 통해서는 다양한 positive들을 통해 더 풍부한 정보를 얻도록 하였으며, peer-network cooperation를 통해서는 다른 모델의 정보를 통해서 학습하도록 하였다. 마치 팀플을 하듯이, 다른 사람들의 의견을 통해 실수를 줄이고, 더 좋은 의견들에 대해서는 확신을 가지도록 한 것이다.
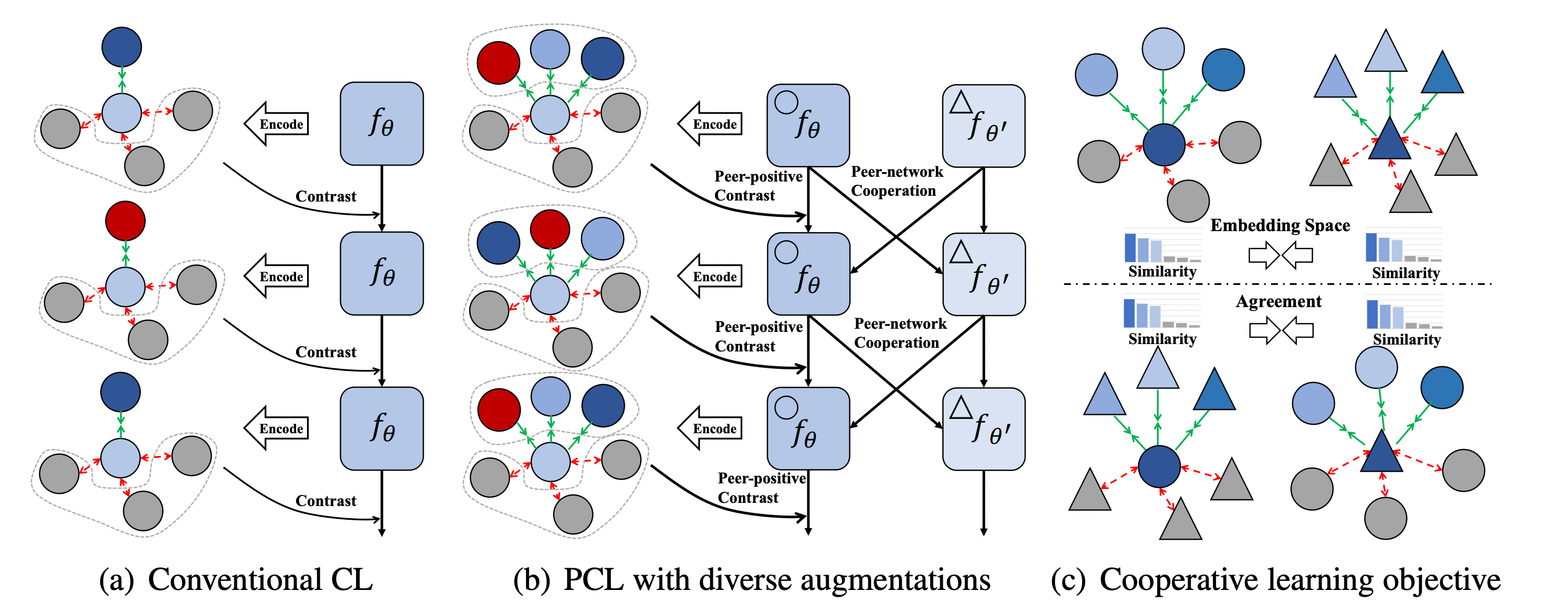
(a)의 가장 위와 아래의 모습처럼 우리가 기대하는 것은 적절한 positive(파란색)를 이용하여 negative(회색)을 멀리 떨어뜨리는 작업을 하려는 것인데, 중간 그림에서 적절하지 않은 positive(빨간색)를 받을 경우에는 학습이 잘 되지 않을 수 있다.
(b)에서처럼 여러가지 positive를 이용해서 이를 보완하고자 했다.
Multi-Augmenting Strategy
'sf+rv+de+rp+sf+rv+de+rp'
원본 데이터 : [CLS] ymca in south australia [SEP]
shuffle
[CLS] in australia ymca south [SEP]
reverse
[CLS] australia south in ymca [SEP]
deletion
[CLS] in south australia [SEP]
repetition
[CLS] in ymca in south australia [SEP]
shuffle
[CLS] in ymca south australia [SEP]
reverse
[CLS] australia south in ymca [SEP]
deletion
[CLS] ymca south australia [SEP]
repetition
[CLS] ymca in south australia australia [SEP]
shuffle
[CLS] ymca in south australia [SEP]
reverse
[CLS] australia south in ymca [SEP]
deletion
[CLS] ymca in australia [SEP]
repetition
[CLS] ymca in south australia australia [SEP]
shuffle
[CLS] in south ymca australia [SEP]
reverse
[CLS] australia south in ymca [SEP]
deletion
[CLS] ymca in australia [SEP]
repetition
[CLS] ymca ymca in south australia [SEP]Contrast among Peer Positives
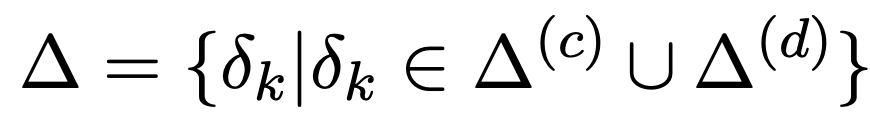
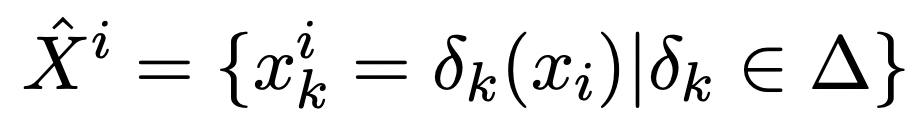
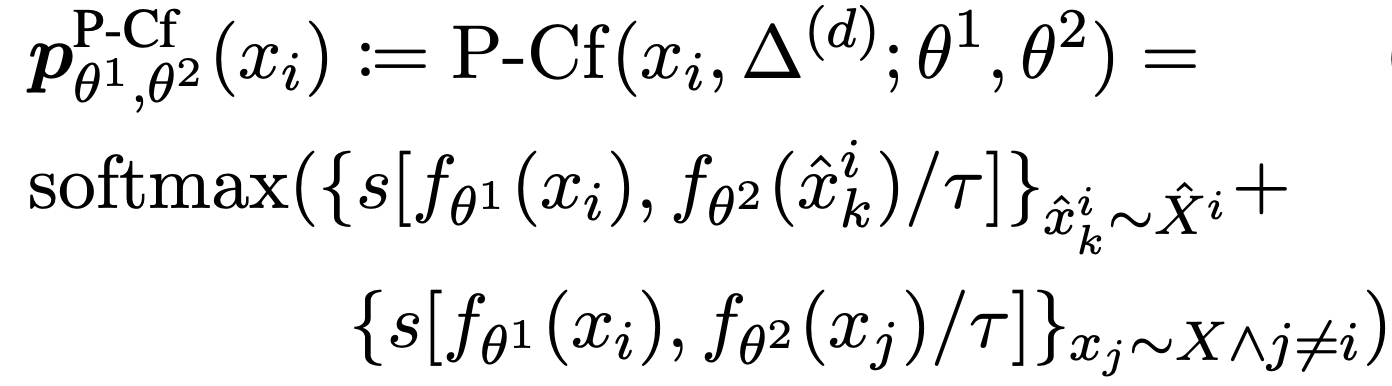
discrete하게 데이터 확장을 시켜서 를 적용한 결과값들, in-batch negative를 활용해서 얻을 수 있는 다른 negative들을 같이 고려해서 학습하게 한다.
Cooperation across Peer Networks
위의 그림 (c)에서 볼 수 있듯이, KLdivergence 이용해서 두 모델에서의 distribution을 이용하여 학습한다.
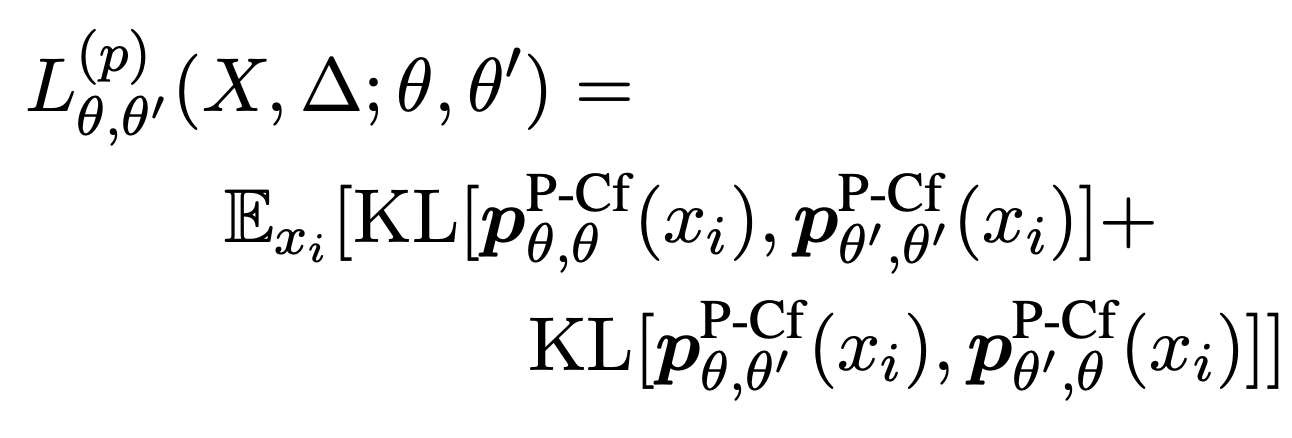
Experiments
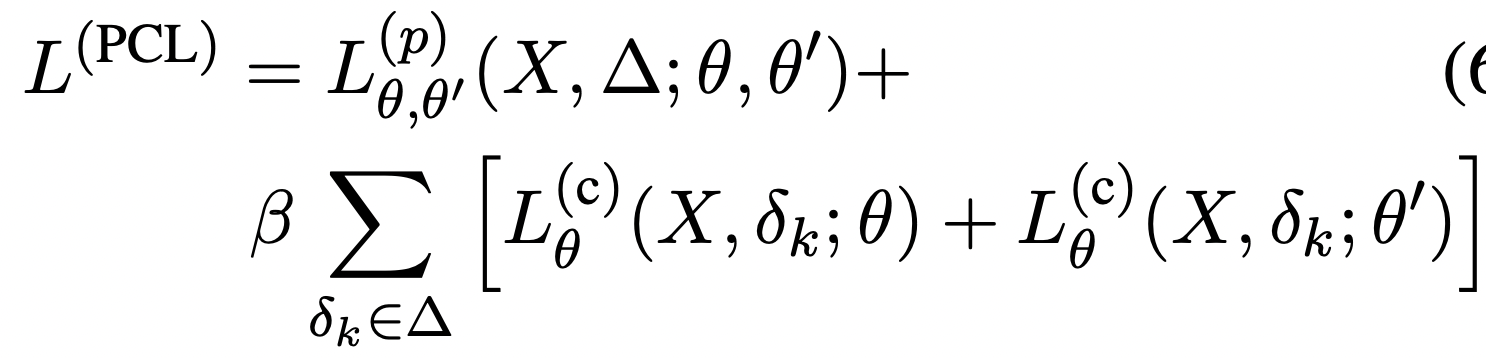
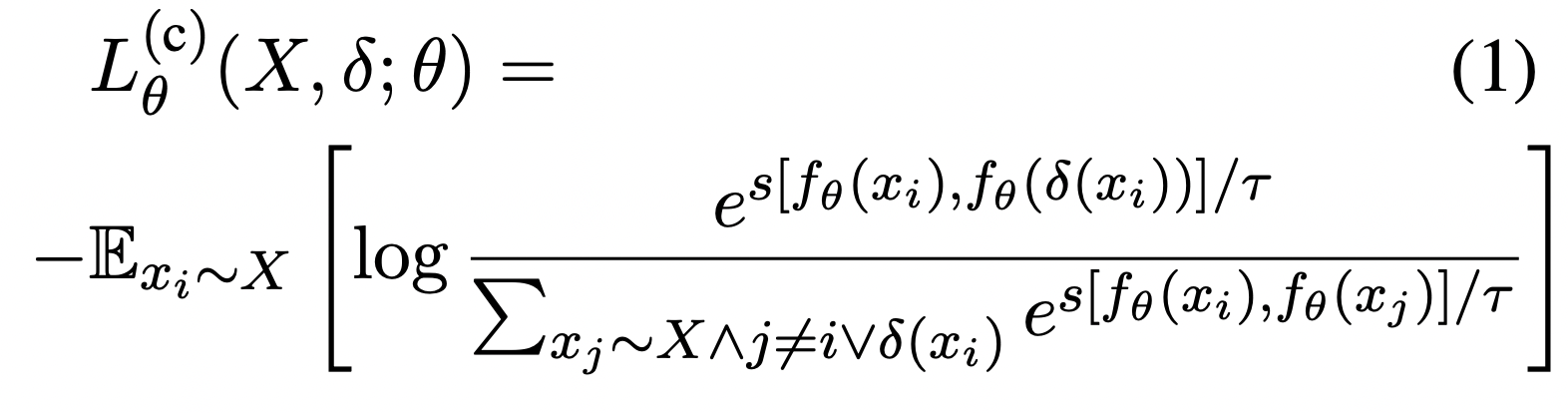
Inference 단계에서는 두 모델이 성능차가 거의 없지만, fair하도록 main 모델 하나만 가지고 점수를 내었다.
Large 모델의 경우에는 너무 커서 두 모델(, )을 tied 했다고 한다.
Analysis
-
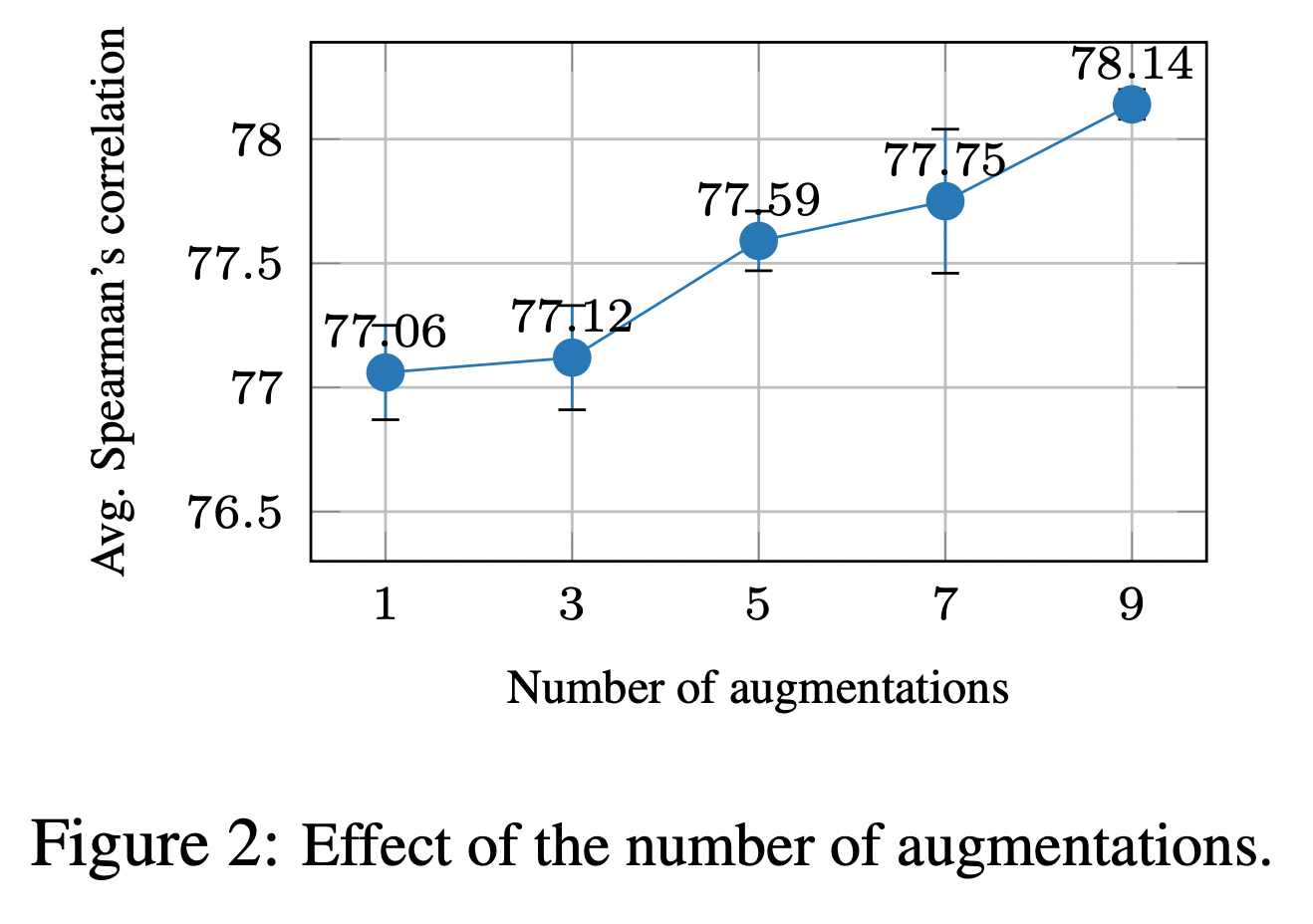
augmentation을 진행할수록 점점 점수가 올라간다. 논문에서는 이런 걸 보면 shortcut이 실제로 존재한다고 말한다.
-
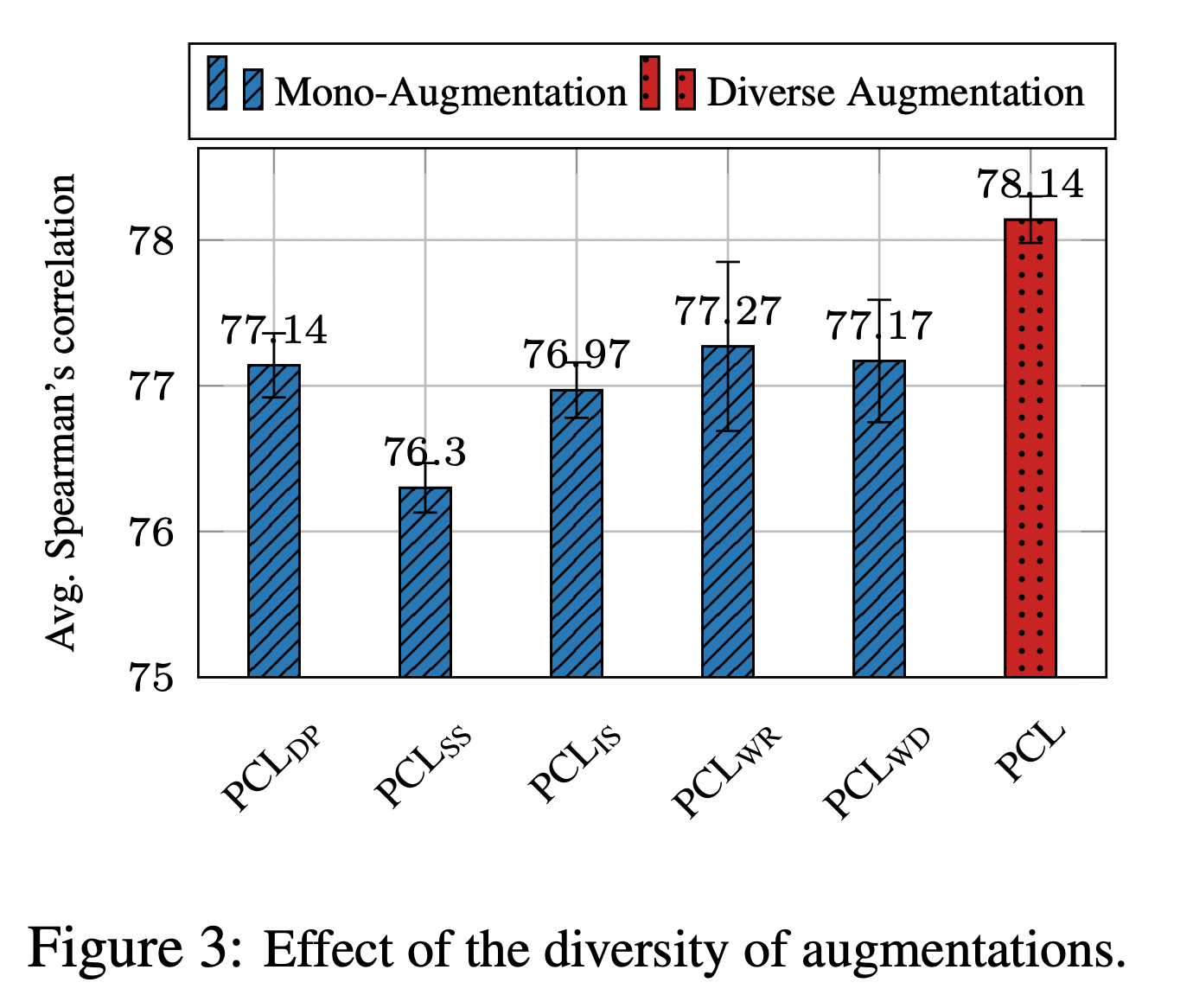
다양한 augmentaion 방식을 사용하는 것이 좋다.
-
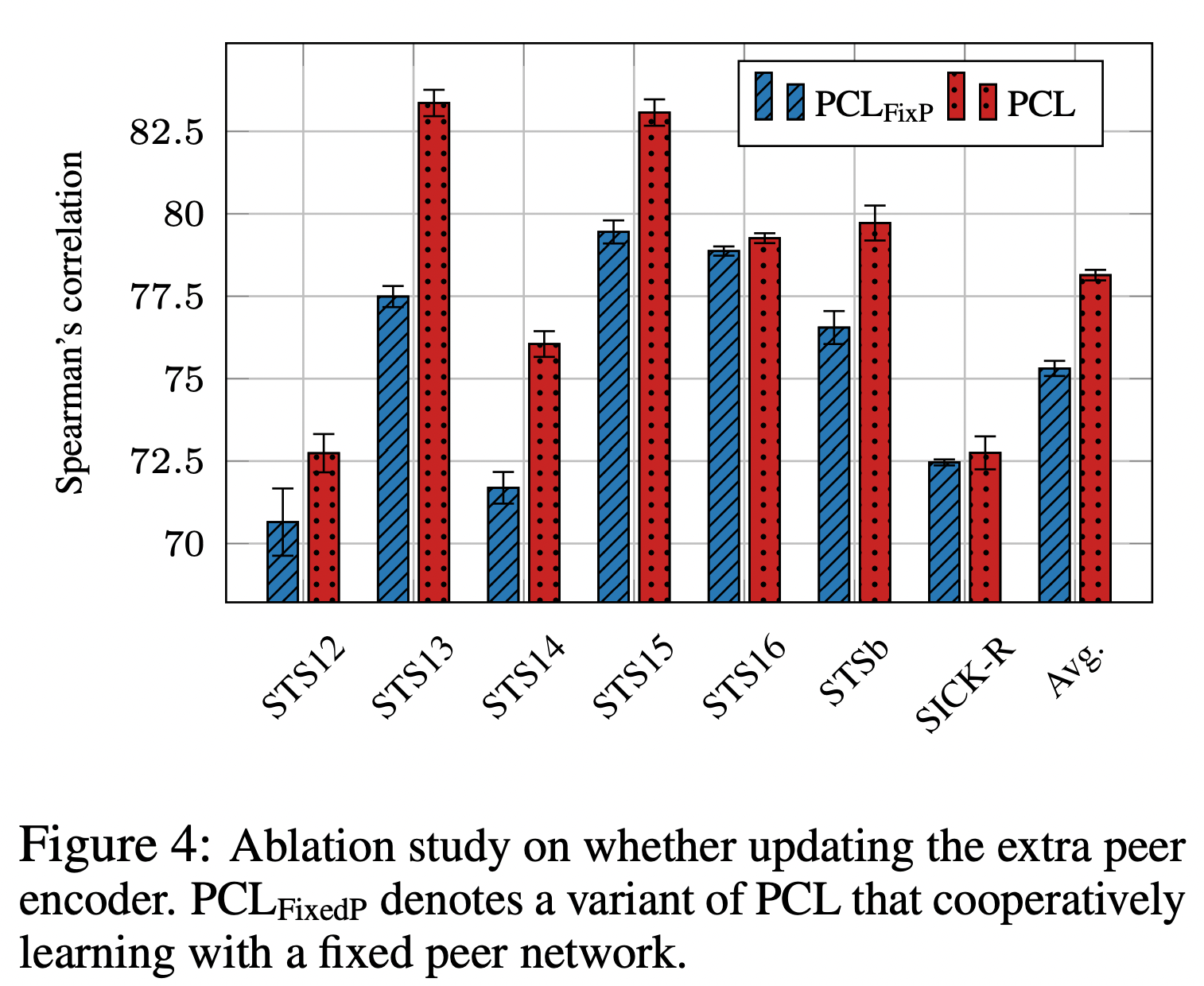
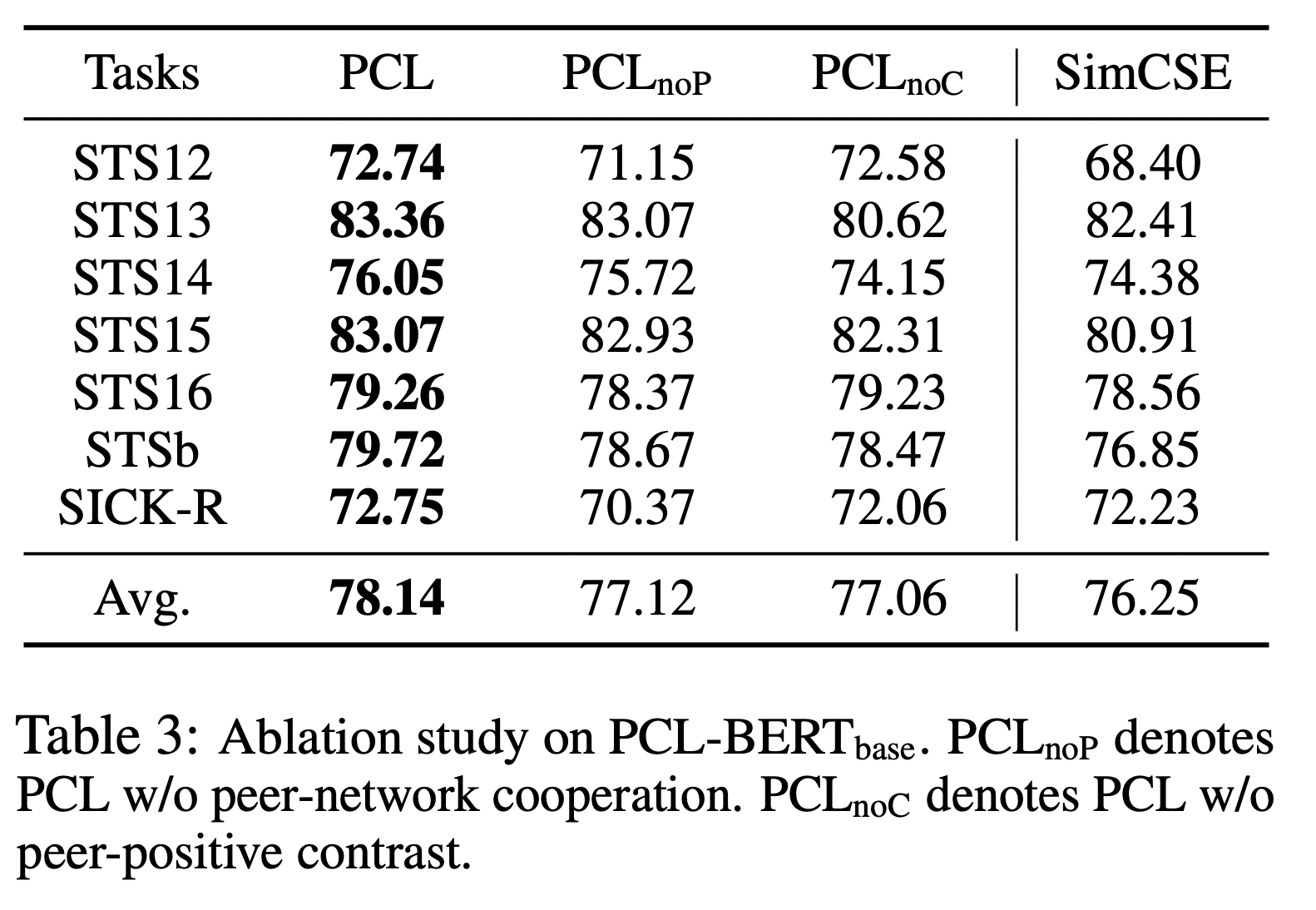
peer-contrast loss 없을 때에가 더 점수가 낮은 것으로 봐서는 peer-cooperation 보다는 좀 더 중요한 역할을 한다고도 볼 수 있다.
-
SimCSE를 가지고 와서 두 번째 모델로 삼고 학습을 시켰을 때에는 space discrepancy가 있어 더 좋은 점수를 내지는 못했다.