LightRAG 논문에서는 기존 RAG(Retrieval-Augmented Generation) 시스템의 주요 한계점으로 평면적 데이터 표현에 의존하는 점, 부적절한 맥락 인식, 단편적인 답변 생성, 확장성 및 효율성 문제, 그리고 동적 환경에서의 적응 문제를 지적하고 있습니다. 기존 시스템은 데이터를 평면적으로 표현하여 복잡한 관계와 상호의존성을 포착하지 못하며, 이로 인해 맥락을 충분히 인식하지 못하고 종종 단편적인 답변을 생성하게 됩니다. 또한, 데이터 규모가 증가함에 따라 검색 품질이 저하되는 확장성 문제와 새로운 데이터를 인덱스에 추가하는 과정이 시간 소모적이라는 비효율성이 존재합니다. LightRAG는 그래프 구조를 텍스트 인덱싱 및 검색 프로세스에 통합하여 이러한 문제를 해결하고자 합니다.
RAG
RAG는 사용자의 질의를 외부 지식 데이터베이스에서 가져온 관련 문서와 결합하여 답변을 생성하는 방식입니다. 이 시스템은 두 가지 주요 컴포넌트로 구성됩니다:
- 검색(유추) 컴포넌트 (Retrieval Component)
이 컴포넌트는 외부 지식 데이터베이스에서 질의에 가장 관련성이 높은 문서를 찾아오는 역할을 합니다. 즉, 사용자의 질의에 맞는 데이터를 "검색"하는 역할을 합니다. - 생성(Generative) 컴포넌트 (Generation Component)
검색된 정보를 바탕으로 언어 모델을 사용해 의미 있고 일관된 답변을 "생성"합니다. 이 컴포넌트는 언어 모델의 능력을 활용하여 문맥에 맞는 답변을 만들어냅니다.
RAG 시스템의 동작 방식은 다음과 같습니다:
- 질의(q)가 주어지면, 검색 컴포넌트(R)가 외부 지식 데이터베이스(D)에서 관련 문서(Dˆ)를 찾습니다.
- 그런 다음 생성 컴포넌트(G)는 검색된 문서와 질의를 바탕으로 최종 답변을 생성합니다.
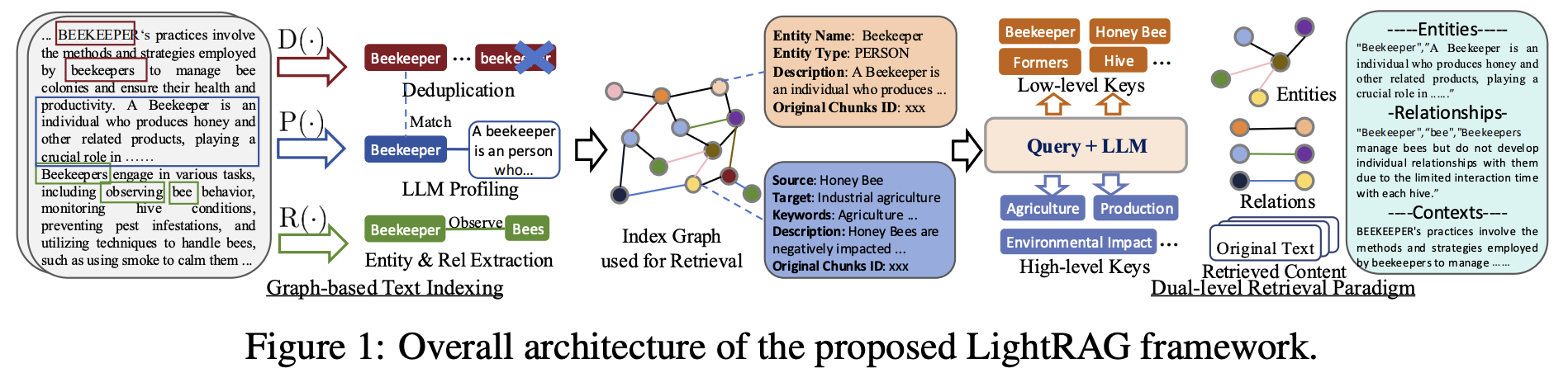
LightRAG: GRAPH-BASED TEXT INDEXING
문서 분할 및 관리
문서(D)는 작은 조각으로 나누어져 각각 Di로 처리됩니다. 이렇게 하면 전체 문서를 한 번에 분석하지 않고도 관련 정보를 빠르게 찾을 수 있습니다.
엔터티와 관계 추출 (Entity and Relationship Extraction)
LLM (대형 언어 모델)을 활용하여 텍스트에서 중요한 엔터티(예: "심장병", "카디오로지스트")와 관계(예: "카디오로지스트는 심장병을 진단한다")를 추출합니다. 이렇게 추출된 엔터티와 관계는 지식 그래프의 노드(엔터티)와 엣지(관계)로 변환됩니다.
지식 그래프 생성 및 인덱싱
추출된 엔터티와 관계는 지식 그래프의 V(노드)와 E(엣지)로 표현됩니다. 이 지식 그래프는 문서들의 연관성, 연결성을 시각적으로 보여줍니다.
텍스트에서 추출된 엔터티와 관계는 키-값 쌍(key-value pairs)으로 구성되어, 효율적인 검색을 위해 인덱스로 활용됩니다.
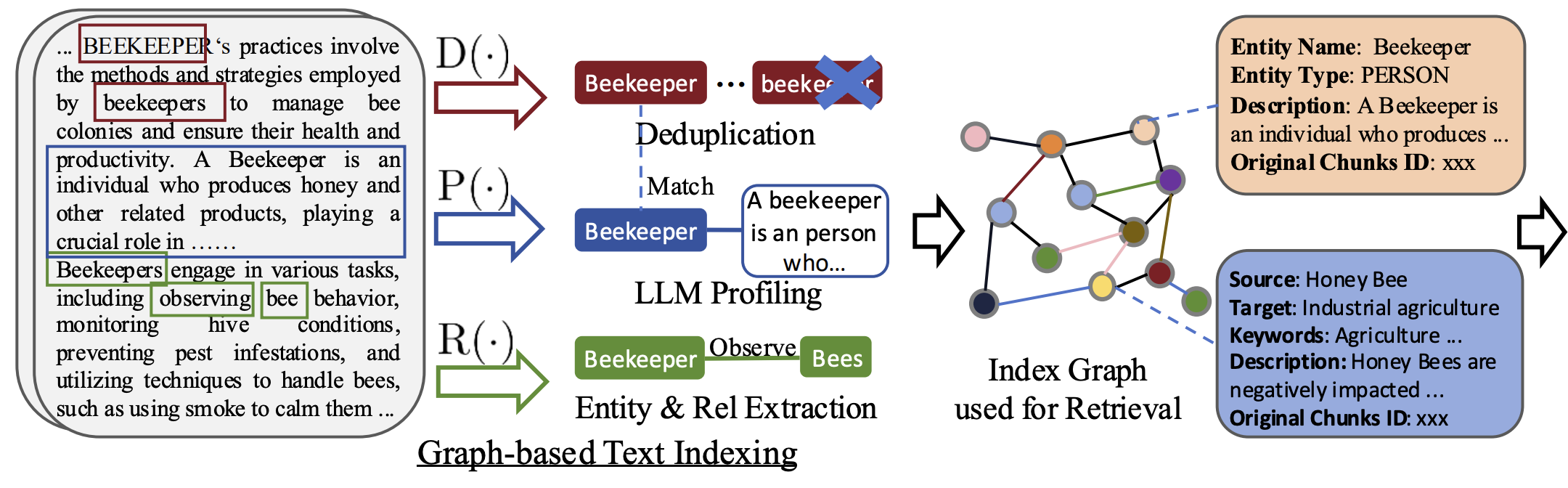
그래프 기반 텍스트 인덱싱 과정은 그게 세 가지 함수로 구성됩니다.
-
엔터티 및 관계 추출 함수 (R(·))
이 함수는 LLM을 사용하여 텍스트에서 엔터티와 관계를 추출합니다. 예를 들어, "카디오로지스트"와 "심장병"을 추출하고, 이들 간의 관계인 "카디오로지스트는 심장병을 진단한다"를 파악합니다. -
키-값 쌍 생성 (P(·))
각 엔터티와 관계에 대해 키-값 쌍을 생성합니다. 키는 검색을 위한 단어나 구문이 되고, 값은 해당 엔터티나 관계에 대한 추가적인 정보를 포함하는 텍스트가 됩니다. -
중복 제거 (D(·))
텍스트 조각에서 중복되는 엔터티와 관계를 찾고 이를 병합하여, 지식 그래프의 크기를 줄이고 그래프 연산을 최적화합니다.
이와 같은 그래프 기반 인덱싱은 두 가지 중요한 장점을 제공합니다. 첫째, 포괄적인 정보 이해입니다. 지식 그래프는 여러 문서 조각에 걸쳐 있는 정보들을 연결하여 복잡한 쿼리에 대해 더 풍부한 답변을 제공할 수 있도록 합니다. 이를 통해 멀티 홉 쿼리 처리 능력이 향상됩니다. 둘째, 향상된 검색 성능입니다. 그래프 기반의 키-값 인덱스는 빠르고 정확한 검색을 가능하게 하여, 기존의 임베딩 매칭 방식이나 텍스트 조각 탐색 방식보다 뛰어난 성능을 보입니다. 이러한 그래프 기반 접근 방식은 정보 검색의 정확도를 높이고, 대량의 데이터를 효율적으로 처리할 수 있게 합니다.
또한, LightRAG는 지식 베이스 업데이트를 통해 데이터를 효율적으로 최신 상태로 유지할 수 있습니다. 새로운 문서가 추가되면, 전체 데이터베이스를 재처리할 필요 없이, 계속해서 업데이트하는 방식으로 기존 그래프에 새로 추가된 데이터를 통합할 수 있습니다. 이 과정에서 기존의 노드와 엣지를 그대로 유지하면서, 새로운 정보를 통합하는 방법을 사용하여 데이터의 일관성을 보장합니다. 이 방법은 연산 오버헤드를 줄이고 빠른 데이터 갱신을 가능하게 하여, 시스템 성능을 극대화합니다.
LightRAG: DUAL-LEVEL RETRIEVAL PARADIGM
Dual-Level Retrieval Paradigm는 LightRAG 시스템에서 정보를 보다 효율적으로 검색하기 위한 접근 방식입니다. 이 접근 방식은 상세한 질의와 추상적인 질의를 처리하기 위해 두 가지 수준의 검색 전략을 적용합니다. 이를 통해 구체적인 정보와 광범위한 개념적 정보를 모두 효과적으로 다룰 수 있습니다.
LightRAG는 질의의 성격에 따라 두 가지 유형으로 구분합니다:
- 구체적인 질의 (Specific Queries): 이 질의는 특정 엔터티나 관계에 대해 상세한 정보를 요구합니다. 예를 들어, “'Pride and Prejudice'의 저자는 누구인가?”와 같은 질문은 특정한 엔터티(이 경우, 저자)에 대해 정확한 정보를 요청합니다.
- 추상적인 질의 (Abstract Queries): 추상적인 질의는 보다 개념적이고 일반적인 주제나 요약을 다룹니다. 예를 들어, “인공지능이 현대 교육에 미치는 영향은 무엇인가?”와 같은 질문은 특정 엔터티에 관한 질문이 아니라, 넓은 범위의 주제에 대한 개념적 답변을 요구합니다.
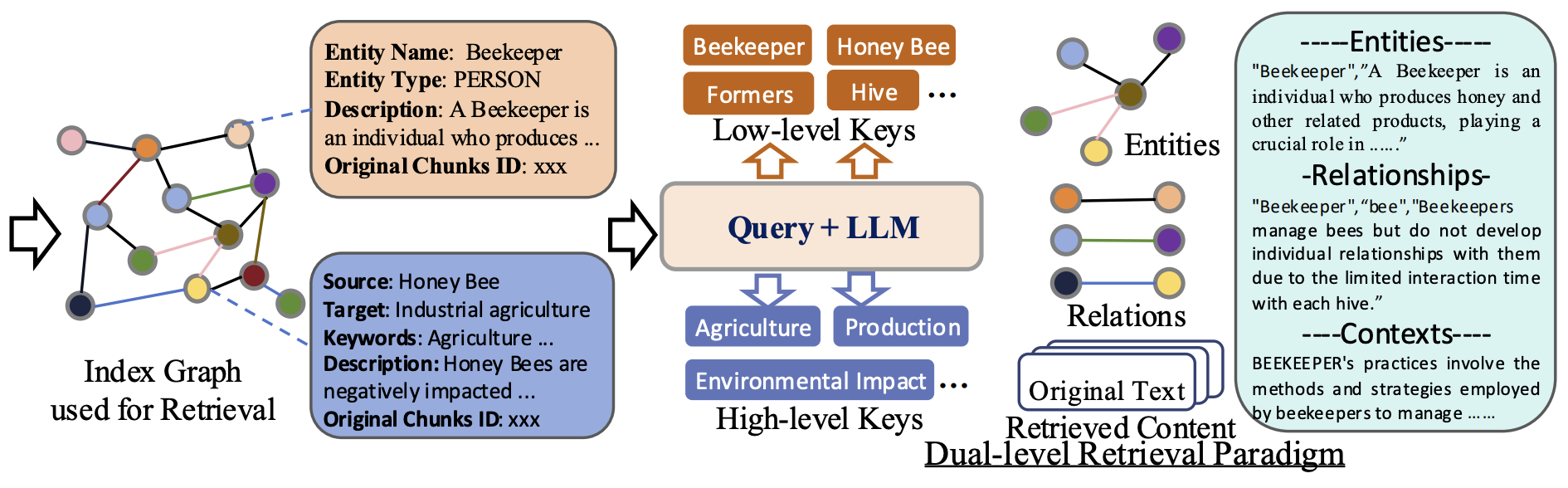
LightRAG는 이러한 다양한 질의 유형을 처리하기 위해 두 가지 검색 수준을 도입합니다:
- 저수준 검색 (Low-Level Retrieval): 이 수준은 특정 엔터티나 관계에 관한 세부적인 정보를 검색하는 데 초점을 맞춥니다. 이때 검색되는 정보는 엔터티의 속성이나 그들 간의 관계와 같은 구체적인 데이터입니다.
- 고수준 검색 (High-Level Retrieval): 고수준 검색은 보다 넓은 주제나 개념을 다룹니다. 이는 여러 엔터티와 관계를 통합하여 상위 개념이나 주제를 다루는 방식으로, 세부 사항보다는 주제나 개념적인 인사이트를 제공합니다.
LightRAG는 그래프 구조와 벡터 표현을 결합하여 검색의 효율성과 정확성을 높입니다.
- 질의 키워드 추출 (Query Keyword Extraction): 주어진 질의에 대해, 검색 알고리즘은 로컬 키워드 (k(l))와 글로벌 키워드 (k(g))를 추출합니다. 로컬 키워드는 구체적인 엔터티나 관계를 의미하고, 글로벌 키워드는 여러 엔터티와 관계가 연결된 넓은 범위의 주제를 의미합니다.
- 키워드 매칭 (Keyword Matching): 알고리즘은 벡터 데이터베이스를 사용하여 로컬 키워드를 관련된 엔터티와 매칭하고, 글로벌 키워드는 관계와 매칭합니다.
- 고차원 관련성 통합 (Incorporating High-Order Relatedness): 검색된 그래프 요소들에 대해 이웃 노드를 추가로 고려하여 검색을 개선합니다. 이 과정에서는 로컬 서브그래프 내에서 이웃 노드들(엔터티나 관계)을 검색하여 관련성을 확장하고, 더 풍부한 검색 결과를 제공합니다. 이때, Nv는 인접 노드, Ne는 인접 관계를 나타냅니다.
LightRAG: RETRIEVAL-AUGMENTED ANSWER GENERATION
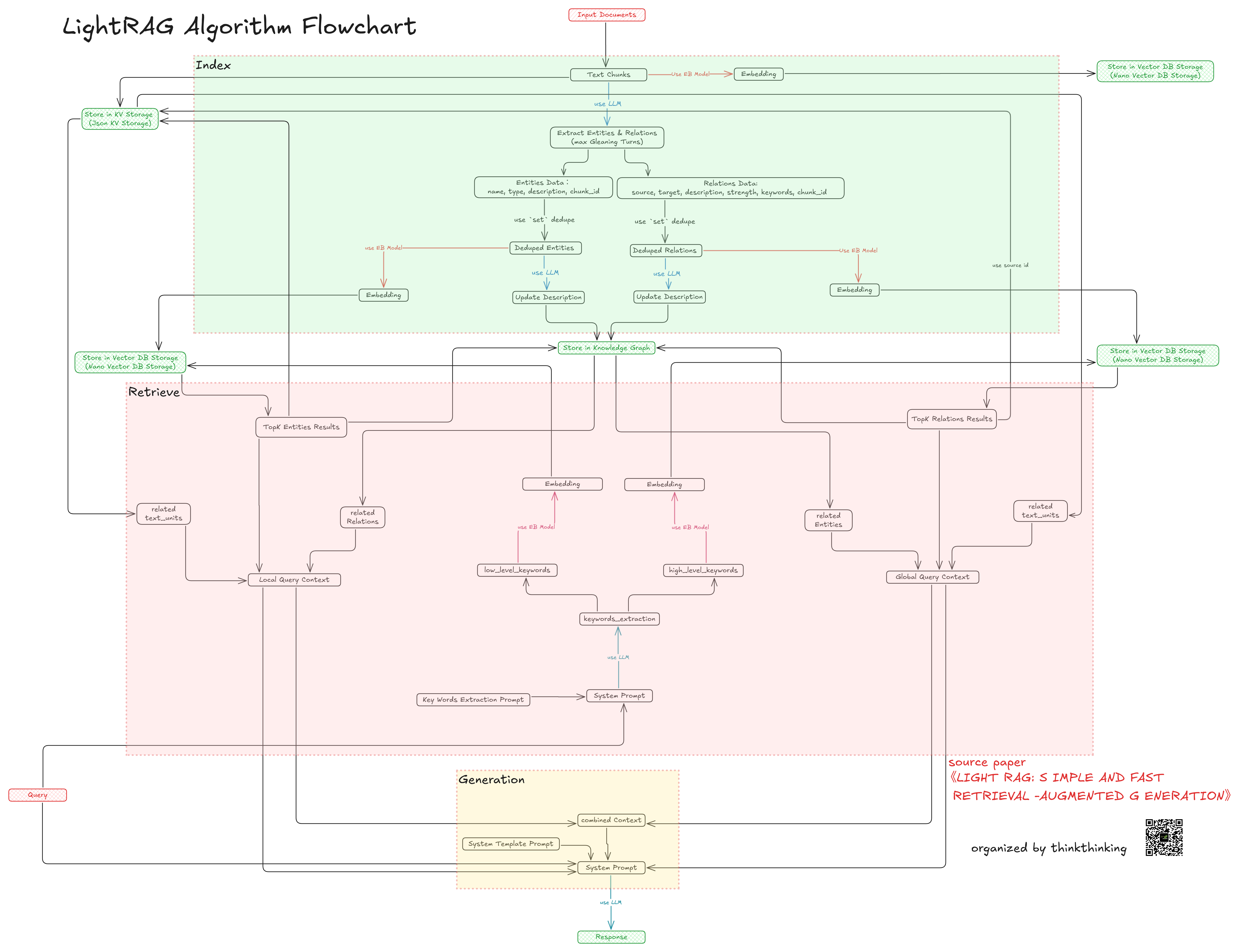
그래프 기반 인덱싱과 그래프 기반 검색
그래프 기반 인덱싱 단계:
이 단계에서는 LLM을 사용해 텍스트의 각 조각에서 엔터티와 관계를 추출합니다. LLM이 호출되는 횟수는 텍스트의 토큰 수에 비례하며, 이 과정에서 별도의 추가적인 오버헤드는 발생하지 않습니다. 즉, 새로운 텍스트가 추가될 때마다 기존 시스템을 크게 변경할 필요 없이 효율적으로 업데이트할 수 있습니다.
그래프 기반 검색 단계:
검색 단계에서는 LLM을 사용하여 질의와 관련된 키워드를 생성한 후, 이 키워드를 이용해 벡터 검색을 수행합니다. LightRAG는 기존의 Retrieval-Augmented Generation (RAG) 시스템과 달리 전체 문서를 검색하는 대신, 엔터티와 관계를 중점적으로 검색합니다. 이 방법은 GraphRAG에서 사용하는 커뮤니티 기반 탐색 방식보다 검색 오버헤드를 크게 줄일 수 있습니다. 따라서 더 효율적인 검색이 가능하며, 결과적으로 시스템의 성능이 향상됩니다.
Experiments
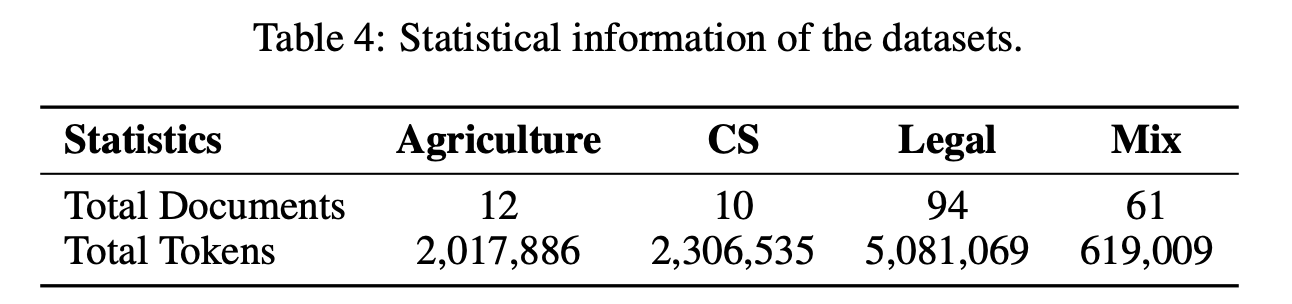
LightRAG의 성능을 종합적으로 분석하기 위해, UltraDomain 벤치마크에서 네 가지 데이터셋을 선택했습니다. UltraDomain 데이터는 428개의 대학 교과서에서 추출되었으며, 농업, 사회 과학, 인문학 등 18개의 다양한 분야를 포괄하고 있습니다. 이 중에서 농업 (Agriculture), 컴퓨터 과학 (CS), 법률 (Legal), 그리고 혼합 (Mix) 데이터셋을 실험에 사용했습니다. 각 데이터셋은 60만에서 500만 토큰 사이로 구성되어 있습니다.
Question Generation
LightRAG의 효과를 평가하기 위해, 고수준의 의미 파악 작업을 위한 RAG 시스템의 성능을 측정하기 위해 다음과 같은 절차를 따릅니다. 각 데이터셋의 모든 텍스트 콘텐츠를 컨텍스트로 통합한 후, Edge et al. (2024)에서 설명한 방법을 채택하여 질문을 생성합니다. 구체적으로, LLM(대형 언어 모델)을 사용하여 5명의 RAG 사용자를 생성하고, 각 사용자에 대해 5개의 작업을 할당합니다. 각 사용자는 자신의 전문성과 성향을 설명하는 텍스트를 통해 동기 부여가 되며, 각 작업은 사용자가 RAG 시스템과 상호작용할 때의 의도를 강조하는 방식으로 설명됩니다.
각 사용자-작업 조합에 대해 LLM은 전체 코퍼스를 이해해야 하는 5개의 질문을 생성합니다. 이 과정은 각 데이터셋에 대해 총 125개의 질문을 생성하게 됩니다. 이를 통해 LightRAG의 성능을 평가하기 위한 고수준의 의미 파악 및 질문 생성 작업을 수행합니다.
Baselines
- Naive RAG (Gao et al., 2023):
Naive RAG는 기존 RAG 시스템에서 표준 기준선으로 사용됩니다. 이 모델은 원본 텍스트를 청크(chunk)로 나눈 후, 텍스트 임베딩을 사용해 벡터 데이터베이스에 저장합니다. 질의가 들어오면, Naive RAG는 벡터화된 표현을 사용하여 텍스트 청크를 검색하고, 가장 유사한 표현을 가진 청크를 직접 검색하여 효율적으로 매칭합니다. - RQ-RAG (Chan et al., 2024):
RQ-RAG는 LLM을 사용하여 입력된 질의를 여러 개의 서브 질의로 분해합니다. 이러한 서브 질의는 검색 정확도를 높이기 위한 기법을 사용하여, 재구성(rewriting), 분해(decomposition), 모호성 해소(disambiguation) 등을 통해 성능을 개선합니다. - HyDE (Gao et al., 2022):
HyDE는 LLM을 사용하여 입력된 질의를 기반으로 가상 문서(hypothetical document)를 생성합니다. 이 가상 문서는 텍스트 청크를 검색하는 데 사용되며, 이후 검색된 청크를 바탕으로 최종 답변을 생성하는 방식입니다. - GraphRAG (Edge et al., 2024):
GraphRAG는 그래프 기반의 RAG 시스템으로, LLM을 사용해 텍스트에서 엔터티와 관계를 추출하고 이를 노드와 엣지로 표현합니다. 그런 후 이들에 대한 설명을 생성하고, 커뮤니티로 노드를 집합하여 글로벌 정보를 집합적으로 캡처합니다. 고수준의 질의를 처리할 때, GraphRAG는 이러한 커뮤니티를 탐색하여 더 포괄적인 정보를 검색합니다.
Implementation and Evaluation Details
Nano vector database를 사용합니다. 또한 LightRAG에서 LLM(대형 언어 모델) 기반 작업을 처리할 때, 기본적으로 GPT-4o-mini를 사용합니다. 실험의 일관성을 보장하기 위해, 청크 크기는 모든 데이터셋에서 1200으로 설정합니다.
고수준의 의미 파악을 요구하는 복잡한 RAG 질의에서 정답(ground truth)을 정의하는 것은 매우 어려운 작업입니다. 이를 해결하기 위해, Edge et al. (2024)의 기존 연구를 바탕으로 LLM 기반의 다차원 비교 방법을 채택합니다.
평가는 네 가지 주요 차원에 따라 이루어집니다. 첫째, 포괄성(Comprehensiveness)은 답변이 질문의 모든 측면과 세부 사항을 얼마나 잘 다루고 있는지를 평가하며, 질문에 대해 충분하고 종합적인 정보를 제공하는지를 측정합니다. 둘째, 다양성(Diversity)은 답변이 여러 관점과 통찰력을 제공하는지를 평가하며, 단일한 해석에 그치지 않고 다양한 시각을 제시하는지를 확인합니다. 셋째, 역량 향상(Empowerment)은 답변이 독자가 주제를 얼마나 잘 이해하고, 이를 바탕으로 정보에 근거한 판단을 내릴 수 있도록 도와주는지를 평가하며, 교육적이고 실질적인 지식을 제공하는지 측정합니다. 마지막으로, 전체 평가(Overall)는 앞서 언급한 세 가지 차원을 종합적으로 고려하여, 가장 우수한 답변을 판별하는 기준으로 사용됩니다.
세 가지 기준 각각에 대해, LLM은 어느 답변이 더 나은지 식별하고, 그 이유를 설명해야 합니다. 최종적으로, 세 가지 차원에서의 성과를 바탕으로 전체 승자가 결정되며, 그 결정에 대한 정당성을 설명하는 자세한 요약이 제공되도록 프롬프트가 작성되었습니다. 
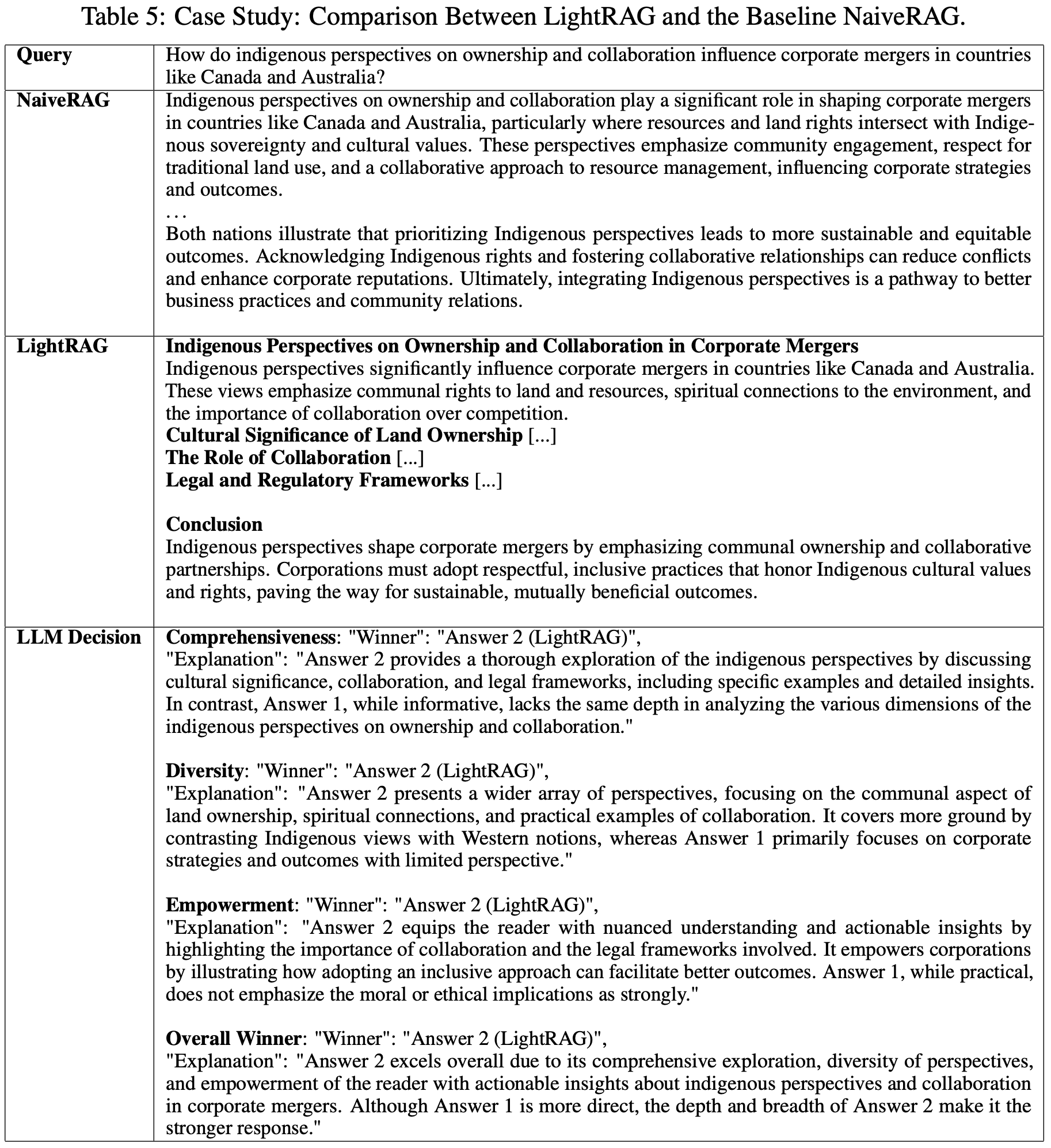
(RQ1): LightRAG는 생성 성능 측면에서 기존의 RAG 기준 방법들과 비교하여 어떤 차이를 보이는가?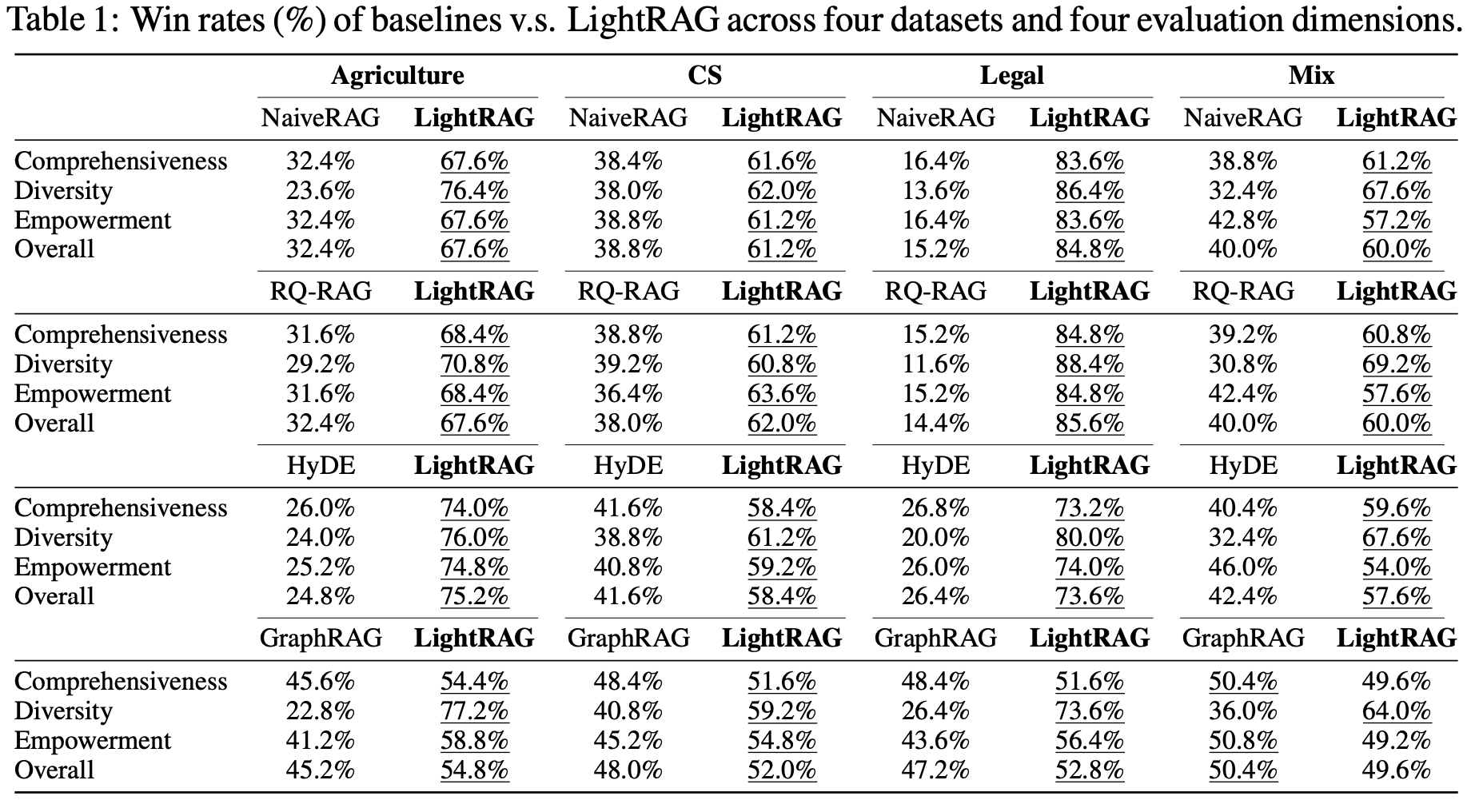 LightRAG는 NaiveRAG, HyDE, RQRAG와 같은 청크 기반 검색 방법보다 일관되게 우수한 결과를 나타냅니다. 이 성능 차이는 데이터셋 크기가 커질수록 더욱 두드러지며, 예를 들어 가장 큰 Legal 데이터셋에서는 LightRAG가 20% 승률에 그치는 기존 모델들과 비교해 압도적인 성능을 보입니다. 이는 LightRAG가 그래프 기반 시스템을 활용해 복잡한 의미론적 의존성을 잘 포착하고, 지식에 대한 종합적 이해를 통해 일반화 성능을 향상시키기 때문입니다.
LightRAG는 NaiveRAG, HyDE, RQRAG와 같은 청크 기반 검색 방법보다 일관되게 우수한 결과를 나타냅니다. 이 성능 차이는 데이터셋 크기가 커질수록 더욱 두드러지며, 예를 들어 가장 큰 Legal 데이터셋에서는 LightRAG가 20% 승률에 그치는 기존 모델들과 비교해 압도적인 성능을 보입니다. 이는 LightRAG가 그래프 기반 시스템을 활용해 복잡한 의미론적 의존성을 잘 포착하고, 지식에 대한 종합적 이해를 통해 일반화 성능을 향상시키기 때문입니다.
또한, LightRAG는 다양성(Diversity) 지표에서 특히 Legal 데이터셋에서 뛰어난 성과를 보이며, 이중 레벨 검색 방식 덕분에 저수준과 고수준 차원에서 모두 정보를 포괄적으로 검색할 수 있어 다양한 응답을 생성할 수 있습니다.
LightRAG는 GraphRAG보다도 우수한 성능을 보이며, 특히 Agriculture, CS, Legal과 같은 큰 데이터셋에서 종합적인 정보 이해를 통해 GraphRAG를 능가합니다.
(RQ2): 이중 레벨 검색과 그래프 기반 인덱싱은 LightRAG의 생성 품질을 어떻게 향상시키는가?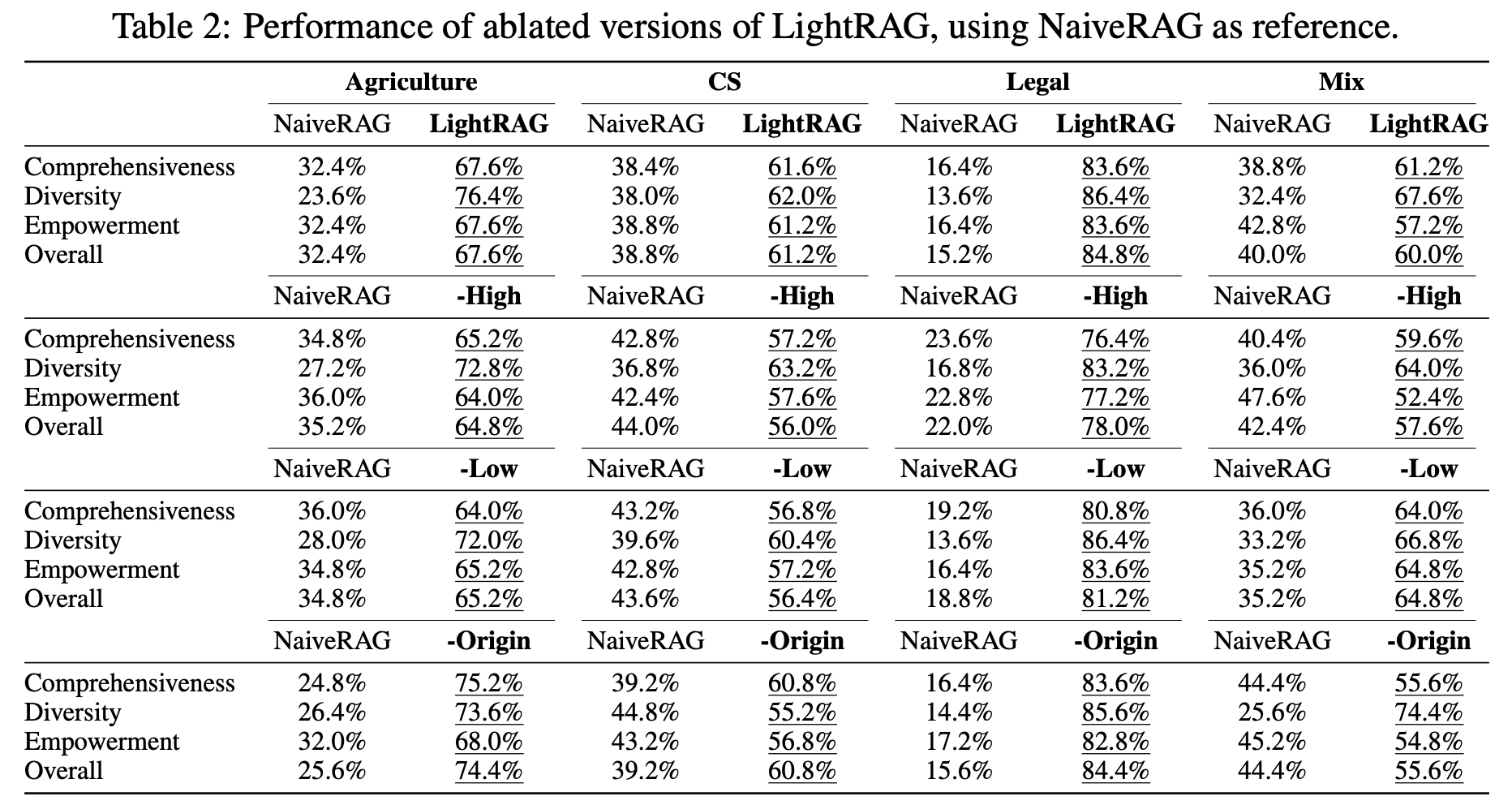 저수준 검색만 사용 (-High variant): 고수준 검색을 제거한 이 방법은 성능이 크게 떨어집니다. 특정 엔티티와 이웃만 분석하기 때문에, 복잡한 쿼리에 필요한 종합적인 통찰을 제공하기 어렵습니다.
저수준 검색만 사용 (-High variant): 고수준 검색을 제거한 이 방법은 성능이 크게 떨어집니다. 특정 엔티티와 이웃만 분석하기 때문에, 복잡한 쿼리에 필요한 종합적인 통찰을 제공하기 어렵습니다.
고수준 검색만 사용 (-Low variant): 고수준 검색은 더 넓은 정보를 다루지만, 구체적인 엔티티에 대한 깊이 있는 분석이 부족해 세부적인 질문에 약합니다.
시맨틱 그래프의 우수성: 원본 텍스트를 제거한 변형(-Origin)은 성능 저하 없이 오히려 일부 데이터셋에서는 향상이 있었습니다. 그래프 기반 색인화가 충분한 컨텍스트를 제공하여, 불필요한 원본 텍스트의 잡음을 제거하고 더 정확한 답변을 가능하게 했습니다.
(RQ3): LightRAG는 다양한 시나리오의 사례들을 통해 어떤 구체적인 장점들을 보여주는가?
- 포괄성 (Comprehensiveness):
LightRAG는 머신러닝 지표에 대해 더 폭넓은 정보를 다루며, 관련 정보를 효과적으로 발견하는 능력을 보여줍니다. 이는 정확한 엔티티 및 관계 추출과 LLM 프로파일링에서 강점을 가진 그래프 기반 색인화 방식 덕분입니다. - 다양성 (Diversity) 및 역량 향상 (Empowerment):
LightRAG는 더 다양한 정보를 제공하고, 독자가 내용을 더 잘 이해할 수 있도록 돕는 교육적인 콘텐츠도 강화되었습니다. 이는 LightRAG의 계층적 검색 방식 덕분인데, 저수준 검색으로 관련된 엔티티를 깊이 탐색하고, 고수준 검색으로 더 넓은 관점을 제공하여 답변의 다양성과 역량을 향상시킵니다. 이 두 접근 방식이 결합되어, 지식 분야에 대한 포괄적인 글로벌 관점을 포착하고 더 나은 RAG 성능을 이루어냈습니다.
결론
이 연구에서는 Retrieval-Augmented Generation (RAG) 시스템의 효율성과 이해도를 향상시키기 위해 그래프 기반 인덱싱 접근법을 통합한 LightRAG를 소개하였습니다. LightRAG는 포괄적인 지식 그래프를 활용하여 빠르고 관련성 높은 문서 검색을 가능하게 하며, 복잡한 쿼리에 대한 깊이 있는 이해를 제공합니다. 또한, LightRAG의 이중 수준 검색 패러다임은 세부적인 정보와 추상적인 정보를 동시에 추출할 수 있어 다양한 사용자 요구에 효과적으로 대응할 수 있습니다. 특히, 계속해서 업데이트하는 기능을 통해 시스템은 새로운 정보가 추가되더라도 항상 최신 상태를 유지하며, 지속적으로 높은 성능을 발휘할 수 있습니다. 이러한 특징 덕분에 LightRAG는 정보 검색 및 생성의 속도와 품질을 현저히 개선하며, LLM 추론 비용을 절감할 수 있는 뛰어난 효율성과 효과성을 보여줍니다.
