Retrieving, Rethinking and Revising: The Chain-of-Verification Can Improve Retrieval Augmented Generation
NLP Papers
이 논문은 바이두에서 나온 2024년 10월 8일 논문입니다.
LLM(대형 언어 모델)은 강력한 텍스트 생성 능력을 갖추고 있지만, 종종 hallucination 문제로 인해 사실과 다른 정보를 제공하는 경우가 발생합니다. 이를 방지하기 위해 RAG(검색 보강 생성) 방법이 도입되었습니다. 하지만 RAG(검색 보강 생성) 방법을 사용하더라도, 여전히 hallucination 문제는 발생하고 있는데 이유로는 아래 두 가지를 들 수 있습니다.
1. 검색기의 한계: 사용자가 입력하는 질문이 명확하지 않거나 불완전할 경우, 검색기가 정확한 정보를 찾아내지 못하는 경우가 있습니다.
2. LLM의 본질적 한계: LLM은 올바른 검색 결과가 있어도 여전히 hallucination(환각) 즉, 잘못된 정보를 생성할 가능성이 있습니다.
이러한 문제를 해결하기 위해, 저자들은 Chain-of-verification, CoV-RAG 접근 방식을 제안했습니다. CoV-RAG는 외부 검색의 정확성을 높이고 내부 생성의 일관성을 강화하는 데 중점을 둡니다. 구체적으로, RAG에 검증 모듈을 통합하여 스코어링, 판단 및 재작성 과정을 수행합니다. 외부 검색 오류를 수정하기 위해 CoV-RAG는 수정된 쿼리를 사용하여 새로운 지식을 검색하고, 내부 생성 오류를 해결하기 위해 QA와 검증 작업을 Chain-of-Thought(CoT) 추론 방식으로 통합합니다. 다양한 대형 언어 모델(LLM)을 대상으로 한 포괄적인 실험 결과, CoV-RAG는 다른 강력한 기준들과 비교하여 효과성과 적응성을 입증하였으며, 특히 여러 LLM 백본을 활용했을 때 기존의 최첨단 성능을 넘어서는 성과를 보여주었습니다.
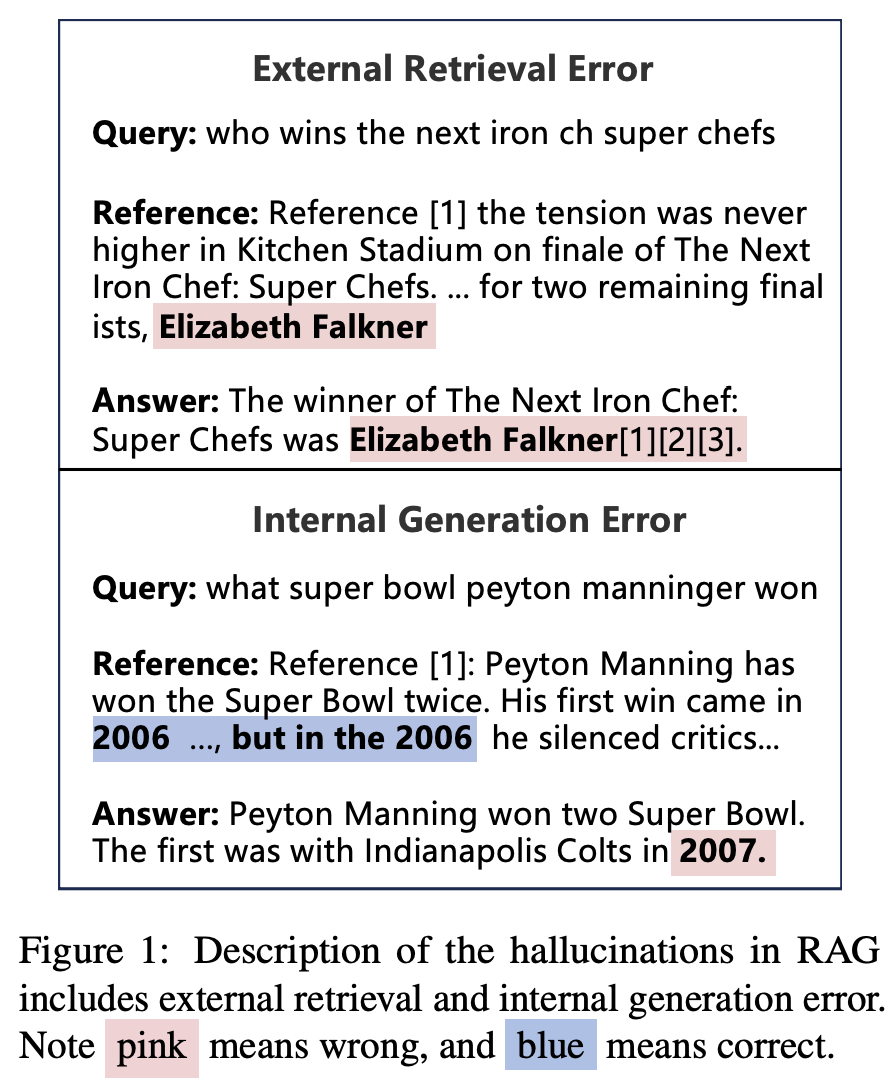
첫 번째 쿼리 "who wins the next iron ch super chefs"에 대해, 모델은 "The winner of The Next Iron Chef: Super Chefs was Elizabeth Falkner"라는 답변을 생성했습니다.
하지만 "The tension was never higher in Kitchen Stadium on finale of The Next Iron Chef: Super Chefs"라고 언급하고 있으며, 이는 문맥에서 올바른 정보를 제공하지 못하고 있습니다. 즉, 검색된 정보가 불완전하거나 부정확해 외부 검색 오류가 발생한 것입니다.
두 번째 쿼리 "what super bowl peyton manninger won"에 대한 모델의 답변은 "Peyton Manning won two Super Bowl. The first was with Indianapolis Colts in 2007."입니다.
여기서 "Peyton Manning won two Super Bowl"라는 부분은 맞지만, "The first was with Indianapolis Colts in 2007"는 잘못된 정보입니다. 사실, Peyton Manning이 처음으로 Super Bowl을 우승한 해는 2007년이 아닌 2006년입니다. 이처럼 모델이 내부적으로 생성한 정보가 정확하지 않아 내부 생성 오류가 발생한 것입니다.
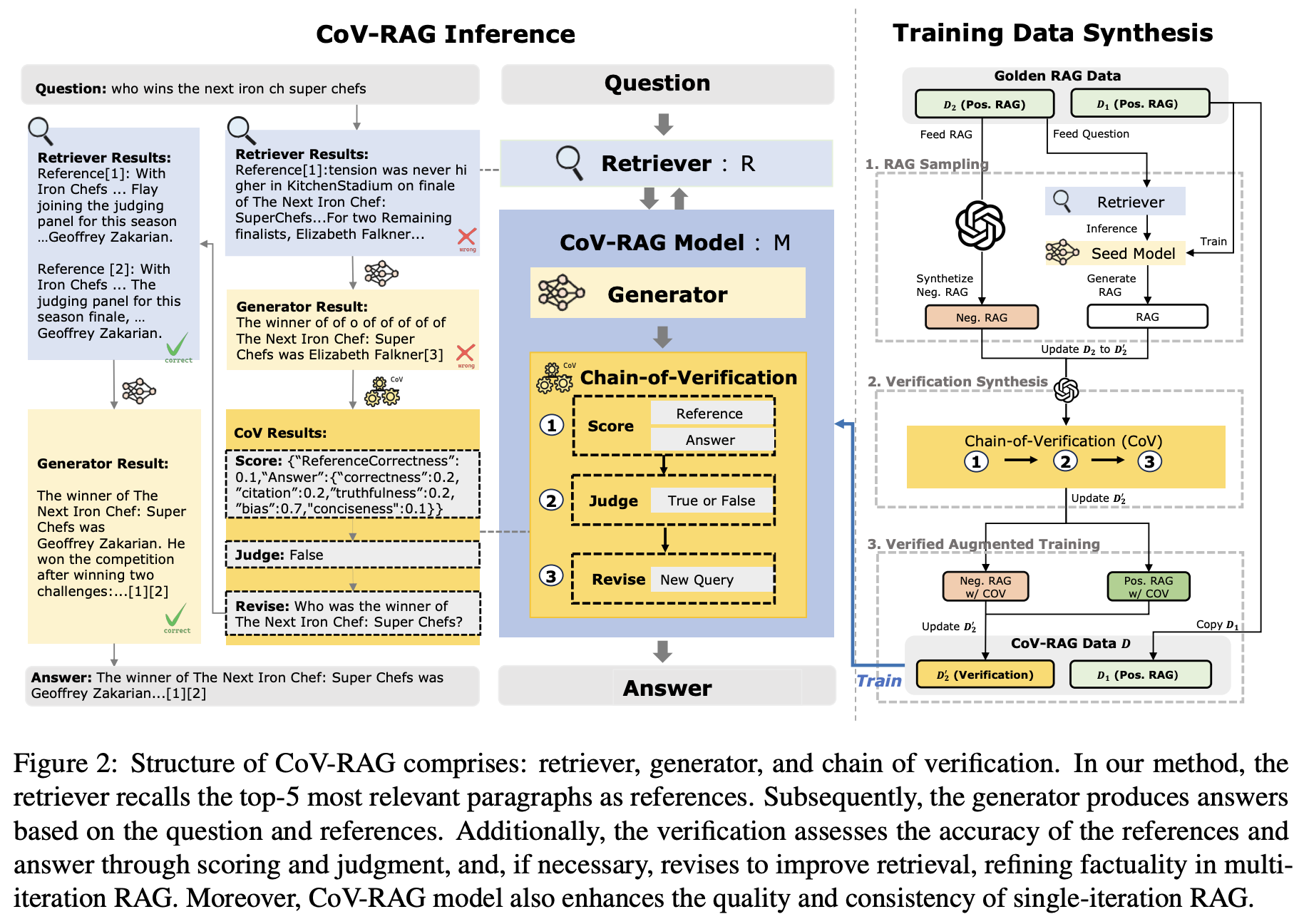
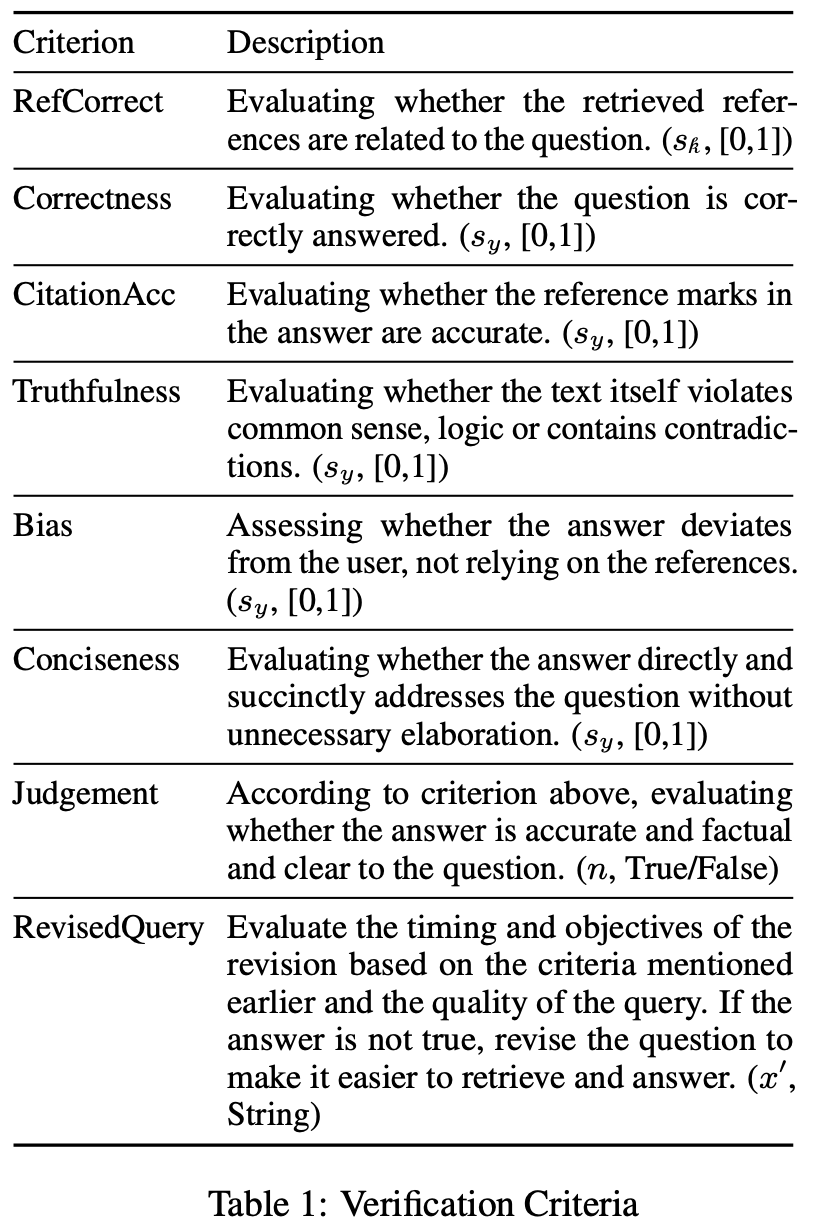
CoV-RAG의 구조는 검색기(retriever), 생성기(generator), 검증 체인(chain of verification)으로 구성되어 있습니다. CoV-RAG가 훈련 및 추론 과정에서 검증 단계를 통해 검색 보강 생성의 효과성을 향상시키는 방법을 보면, 우선, CoV-RAG는 차원별 점수와 판단을 기반으로 오류 유형을 식별하며, 여기에는 참조 정확성(reference correctness), 답변 정확성(answer correctness), 인용 정확성(citation accuracy), 진실성(truthfulness), 편향(bias), 간결성(conciseness) 및 판단(judgment)이 포함됩니다. 외부 맥락 지식과 관련된 오류를 해결하기 위해, CoV-RAG는 정제된 쿼리를 활용하여 다중 반복 QA 설정에서 맥락 지식을 향상시키기 위한 재검색을 수행합니다.
The RAG Framework
RAG(검색 보강 생성)에서는 외부 지식 k, 즉 "참조"는 먼저 입력 쿼리 x와의 관련성을 기준으로 검색기 모듈 R을 사용하여 검색됩니다.
언어 모델 M은 외부 지식 k를 활용하여 쿼리 x에 대한 응답 y를 생성합니다.
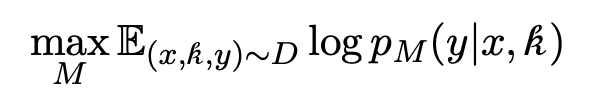
CoV-RAG Inference

CoV-RAG 추론 알고리즘은 크게 다음과 같은 구조로 나눌 수 있습니다:
-
입력 및 참조 검색
- 입력: 사용자가 질문 ( x )를 입력합니다.
- 참조 검색: 검색기 ( R )가 질문 ( x )와 관련된 외부 지식(참조) ( k )를 검색합니다. 이 참조들은 관련성에 따라 정렬됩니다.
-
답변 예측 및 검증
- 답변 예측: 언어 모델 ( M )이 질문 ( x )와 검색된 참조 ( k )를 기반으로 답변 ( )를 생성합니다.
- 검증 예측: 언어 모델 ( M )이 질문, 참조, 그리고 예측된 답변을 바탕으로 검증 결과(참조 점수, 답변 점수, 판단 기준, 수정된 질문)를 예측합니다.
-
재검색 결정
- 재검색 지표 확인: 검증 결과를 통해 외부 맥락 지식을 업데이트할 필요성을 판단하는 재검색 지표 ( )를 얻습니다.
-
재검색 및 최종 답변
- 재검색 필요 시: 만약 재검색 지표가 True라면, 검색기 ( R )가 수정된 질문 ( x' )에 대해 새로운 관련 참조 ( k' )를 검색합니다.
- 새로운 답변 예측: 언어 모델 ( M )이 초기 질문과 새롭게 검색된 참조를 바탕으로 새로운 답변 ( )를 예측합니다.
- 결과 반환: 최종적으로 예측된 답변 ( )를 반환합니다.
이 구조는 입력에서 시작하여 답변을 생성하고 검증, 필요시 재검색을 통해 최종 답변을 제공하는 과정입니다. 이를 통해 CoV-RAG는 외부 지식의 정확성과 내부 생성의 일관성을 모두 향상시키는 것을 목표로 합니다.
- 참조 점수 (): 이 점수는 검색된 외부 참조의 품질을 나타냅니다. 높은 점수를 가진 참조는 질문과의 관련성이 높고, 정확한 정보를 포함하고 있습니다.
- 답변 점수 (): 이 지표는 생성된 답변의 여러 측면을 평가합니다. 여기에는 다음과 같은 요소들이 포함됩니다
- 정확성: 답변이 사실과 일치하는 정도
- 인용 정확성: 참조된 정보를 얼마나 잘 인용했는지
- 진실성: 제공된 정보가 진실인지 여부
- 편향성: 답변에 주관적 견해나 편향이 포함되어 있는지
- 간결성: 답변이 얼마나 명확하고 간결하게 작성되었는지)
- 판단 (n): 모델이 예측한 답변이 정확하고, 사실적이며, 질문에 명확히 답하고 있는지를 평가하는 True/False 결정입니다. 이 단계에서 모델은 답변의 질을 최종적으로 판단합니다.
- 수정된 질문(x′):만약 답변이 수정이 필요하다고 판단되면, x′는 수정된 질문을 나타냅니다.
CoV-RAG Training
Step 1: RAG Sampling
RAG 샘플링의 첫 번째 단계는 다양한 Verification 데이터를 확보하는 것입니다. 다양한 샘플을 수집하여 Verification 과정이 의미 있고 유효하도록 해야 합니다. 만약 모든 RAG 샘플이 정확하다면, Verification 결과는 모두 긍정적이 되어버리며, 이는 Verification 의미를 상실하게 됩니다. 따라서 를 로 업데이트하기 위해 다음 두 가지 과정을 수행합니다.
RAG 훈련 데이터셋을 RAG task위한 , Verification task위한 두 가지로 나눕니다. 에 대해서 검색결과를 얻고, 를 이용하여 얻은 검색결과에 ChatGPT를 이용해서 답변을 생성하도록 했습니다.
Step 2: Verification Data Synthesis
Step 1에서 수집한 RAG 샘플()을 바탕으로 긍정적 및 부정적 RAG 데이터를 생성하고 이를 검증 체인으로 데이터로 만드는 과정입니다. 이 단계에서 GPT-4는 Verification Criteria에 해당하는 값들을 생성했습니다. 를 평가하여 질문, 검색된 참조, 모델이 생성한 답변을 입력으로 받아 긍정적 데이터와 부정적 데이터를 생성하며, 각 데이터에 대한 근거도 제공합니다. 예를 들어, 생성된 데이터는 참조의 정확성("RefCorrect"), 답변의 다양한 평가 점수("AnswerScore"), 최종 판단("Judgment"), 수정된 질문("RevisedQuery")을 포함합니다. 데이터 품질을 보장하기 위해 GPT-4의 주석을 기준 데이터와 정답에 대해 검증하며, 샘플링 결과는 93%의 정확도를 나타냅니다.

이 데이터는 특정 질문에 대한 검증 결과를 나타냅니다. 출력에서 "RefCorrect"는 참조 정보의 정확성을 나타내며, 0.99로 매우 높은 정확성을 의미합니다. "AnswerScore" 객체는 생성된 답변의 다양한 측면을 평가하는 여러 지표를 포함하는데, "Correctness"는 0.51로 절반 정도의 정확성을 나타내고, "CitationAcc"는 0.0으로 인용이 전혀 정확하지 않음을 의미하며, "Truthfulness"는 0.01로 거의 사실이 아님을 나타냅니다. "Bias"는 0.97로 매우 높은 편향을 나타내고, "Conciseness"는 0.89로 답변이 상당히 간결함을 의미합니다. "Judgment"는 전체 평가에 대한 최종 판단을 나타내며 "false"는 모델이 생성한 답변이 정확하지 않다고 판단했음을 의미합니다. 마지막으로, "RevisedQuery"는 수정된 질문으로, 원래 질문이 명확하지 않거나 적절하지 않은 경우 모델이 보다 구체적이고 명확한 질문으로 수정한 것을 나타냅니다.
Step 3: Verified Augmented Training
데이터셋 D를 사용하여 CoV-RAG 모델 M을 훈련합니다. 이 단계에서는 Multi Task Learning을 적용하여 검증 데이터를 포함한 긍정적 및 부정적 데이터가 RAG 작업을 위한 SFT(Supervised Fine-Tuning) 훈련하는데 사용됩니다.
- 데이터셋 D는?
- 왜 Multi task learning일까요?
- QA, Verification 작업에 사용되는 instruction

CoV-RAG는 모델이 단순히 선호도를 파악하는 데 그치지 않고 이러한 선호의 기저에 있는 이유를 이해할 수 있도록 합니다.
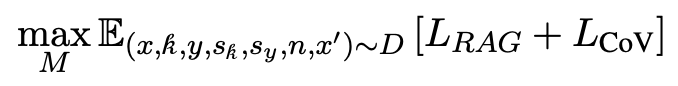
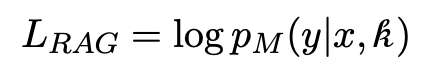
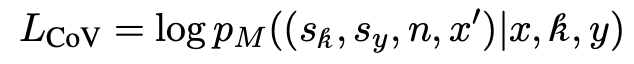
Experiments
CoV-RAG는 사실 기반의 오픈 도메인 질문 답변 영역에서 평가했습니다.
Natural questions{
"id": "797803103760793766",
"document": {
"title": "Google",
"url": "http://www.wikipedia.org/Google",
"html": "<html><body><h1>Google Inc.</h1><p>Google was founded in 1998 By:<ul><li>Larry</li><li>Sergey</li></ul></p></body></html>",
"tokens":[
{"token": "<h1>", "start_byte": 12, "end_byte": 16, "is_html": True},
{"token": "Google", "start_byte": 16, "end_byte": 22, "is_html": False},
{"token": "inc", "start_byte": 23, "end_byte": 26, "is_html": False},
{"token": ".", "start_byte": 26, "end_byte": 27, "is_html": False},
{"token": "</h1>", "start_byte": 27, "end_byte": 32, "is_html": True},
{"token": "<p>", "start_byte": 32, "end_byte": 35, "is_html": True},
{"token": "Google", "start_byte": 35, "end_byte": 41, "is_html": False},
{"token": "was", "start_byte": 42, "end_byte": 45, "is_html": False},
{"token": "founded", "start_byte": 46, "end_byte": 53, "is_html": False},
{"token": "in", "start_byte": 54, "end_byte": 56, "is_html": False},
{"token": "1998", "start_byte": 57, "end_byte": 61, "is_html": False},
{"token": "by", "start_byte": 62, "end_byte": 64, "is_html": False},
{"token": ":", "start_byte": 64, "end_byte": 65, "is_html": False},
{"token": "<ul>", "start_byte": 65, "end_byte": 69, "is_html": True},
{"token": "<li>", "start_byte": 69, "end_byte": 73, "is_html": True},
{"token": "Larry", "start_byte": 73, "end_byte": 78, "is_html": False},
{"token": "</li>", "start_byte": 78, "end_byte": 83, "is_html": True},
{"token": "<li>", "start_byte": 83, "end_byte": 87, "is_html": True},
{"token": "Sergey", "start_byte": 87, "end_byte": 92, "is_html": False},
{"token": "</li>", "start_byte": 92, "end_byte": 97, "is_html": True},
{"token": "</ul>", "start_byte": 97, "end_byte": 102, "is_html": True},
{"token": "</p>", "start_byte": 102, "end_byte": 106, "is_html": True}
],
},
"question" :{
"text": "who founded google",
"tokens": ["who", "founded", "google"]
},
"long_answer_candidates": [
{"start_byte": 32, "end_byte": 106, "start_token": 5, "end_token": 22, "top_level": True},
{"start_byte": 65, "end_byte": 102, "start_token": 13, "end_token": 21, "top_level": False},
{"start_byte": 69, "end_byte": 83, "start_token": 14, "end_token": 17, "top_level": False},
{"start_byte": 83, "end_byte": 92, "start_token": 17, "end_token": 20 , "top_level": False}
],
"annotations": [{
"id": "6782080525527814293",
"long_answer": {"start_byte": 32, "end_byte": 106, "start_token": 5, "end_token": 22, "candidate_index": 0},
"short_answers": [
{"start_byte": 73, "end_byte": 78, "start_token": 15, "end_token": 16, "text": "Larry"},
{"start_byte": 87, "end_byte": 92, "start_token": 18, "end_token": 19, "text": "Sergey"}
],
"yes_no_answer": -1
}]
}{
"answers": ["Jamaican Creole English Language", "Jamaican English"],
"question": "what does jamaican people speak?",
"url": "http://www.freebase.com/view/en/jamaica"
}{
"Data": [
{
"Answer": {
"Aliases": [
"Sunset Blvd",
"West Sunset Boulevard",
"Sunset Boulevard",
"Sunset Bulevard",
"Sunset Blvd."
],
"MatchedWikiEntityName": "Sunset Boulevard",
"NormalizedAliases": [
"west sunset boulevard",
"sunset blvd",
"sunset boulevard",
"sunset bulevard"
],
"NormalizedMatchedWikiEntityName": "sunset boulevard",
"NormalizedValue": "sunset boulevard",
"Type": "WikipediaEntity",
"Value": "Sunset Boulevard"
},
"EntityPages": [
{
"DocSource": "TagMe",
"Filename": "Andrew_Lloyd_Webber.txt",
"LinkProbability": "0.02934",
"Rho": "0.22520",
"Title": "Andrew Lloyd Webber"
}
],
"Question": "Which Lloyd Webber musical premiered in the US on 10th December 1993?",
"QuestionId": "tc_33",
"QuestionSource": "http://www.triviacountry.com/",
"SearchResults": [
{
"Description": "The official website for Andrew Lloyd Webber, ... from the Andrew Lloyd Webber/Jim Steinman musical Whistle ... American premiere on 9th December 1993 at the ...",
"DisplayUrl": "www.andrewlloydwebber.com",
"Filename": "35/35_995.txt",
"Rank": 0,
"Title": "Andrew Lloyd Webber | The official website for Andrew ...",
"Url": "http://www.andrewlloydwebber.com/"
}
]
}
],
"Domain": "Web",
"VerifiedEval": false,
"Version": 1.0
}{
"id": "a9011ddf",
"question": "What is the seventh tallest mountain in North America?",
"translations":
{
"ar": "ما سابع أعلى جبل في أمريكا الشمالية؟",
"de": "Wie heißt der siebthöchste Berg Nordamerikas?",
"ja": "北アメリカで七番目に高い山は何ですか?",
"hi": "उत्तर अमेरिका में सातवां सबसे लंबा पर्वत कौन सा है?",
"pt": "Qual é a sétima montanha mais alta da América do Norte?",
"es": "¿Cuál es la séptima montaña más alta de Norteamérica?",
"it": "Qual è la settima montagna più alta del Nord America?",
"fr": "Quelle est la septième plus haute montagne d’Amérique du Nord ?"
},
"questionEntity":
[
{
"name": "Q49",
"entityType": "entity",
"label": "North America",
"mention": "North America",
"span":
[
40,
53
]
},
{
"name": 7,
"entityType": "ordinal",
"mention": "seventh",
"span":
[
12,
19
]
}
],
"answer":
{
"answerType": "entity",
"answer":
[
{
"name": "Q1153188",
"label":
{
"en": "Mount Lucania",
"ar": null,
"de": "Mount Lucania",
"es": "Monte Lucania",
"fr": "mont Lucania",
"hi": null,
"it": "Monte Lucania",
"ja": "ルカニア山",
"pt": "Monte Lucania"
}
}
],
"mention": "Mount Lucania"
},
"category": "geography",
"complexityType": "ordinal"
}
단순 LLM(GPT-3), RAG 모델(같은 검색을 사용하는 ChatGPT, Perplexity.ai, WebGLM), 그리고 재작성(RRR), 반영 및 순위를 이용한 방법(Self-RAG)보다 우수한 성능을 보여줍니다.
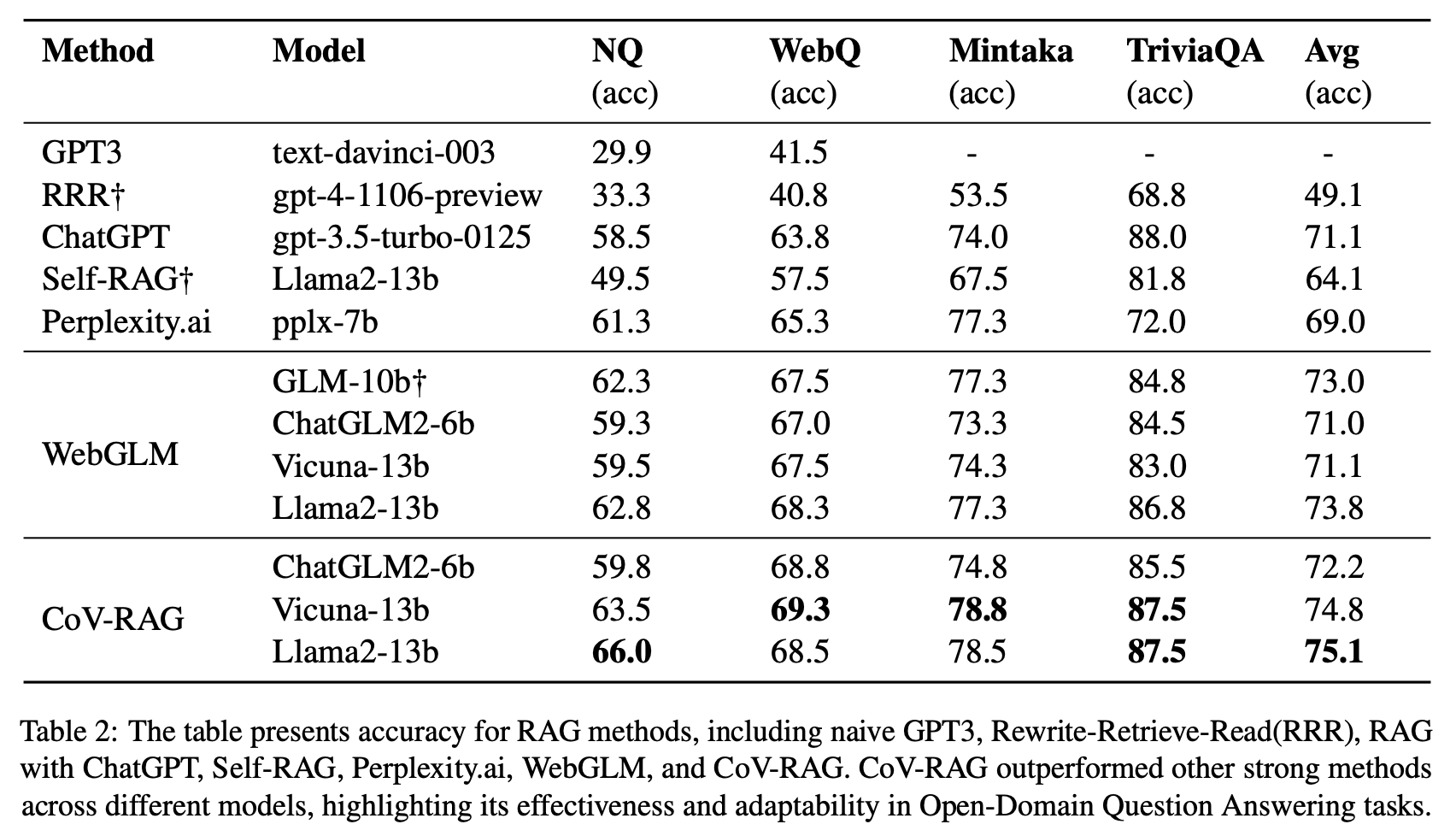
- CoV-RAG방법이 단순 LLM(GPT-3), 재작성(RRR), RAG 모델(같은 검색을 사용하는 ChatGPT, Perplexity.ai, WebGLM), 그리고 순위를 이용한 방법(Self-RAG)보다 우수한 성능을 보임.
- WebGLM과 비교했을 때, CoV-RAG의 검증 체인 메커니즘은 일관되게 더 높은 정확도를 나타냄.
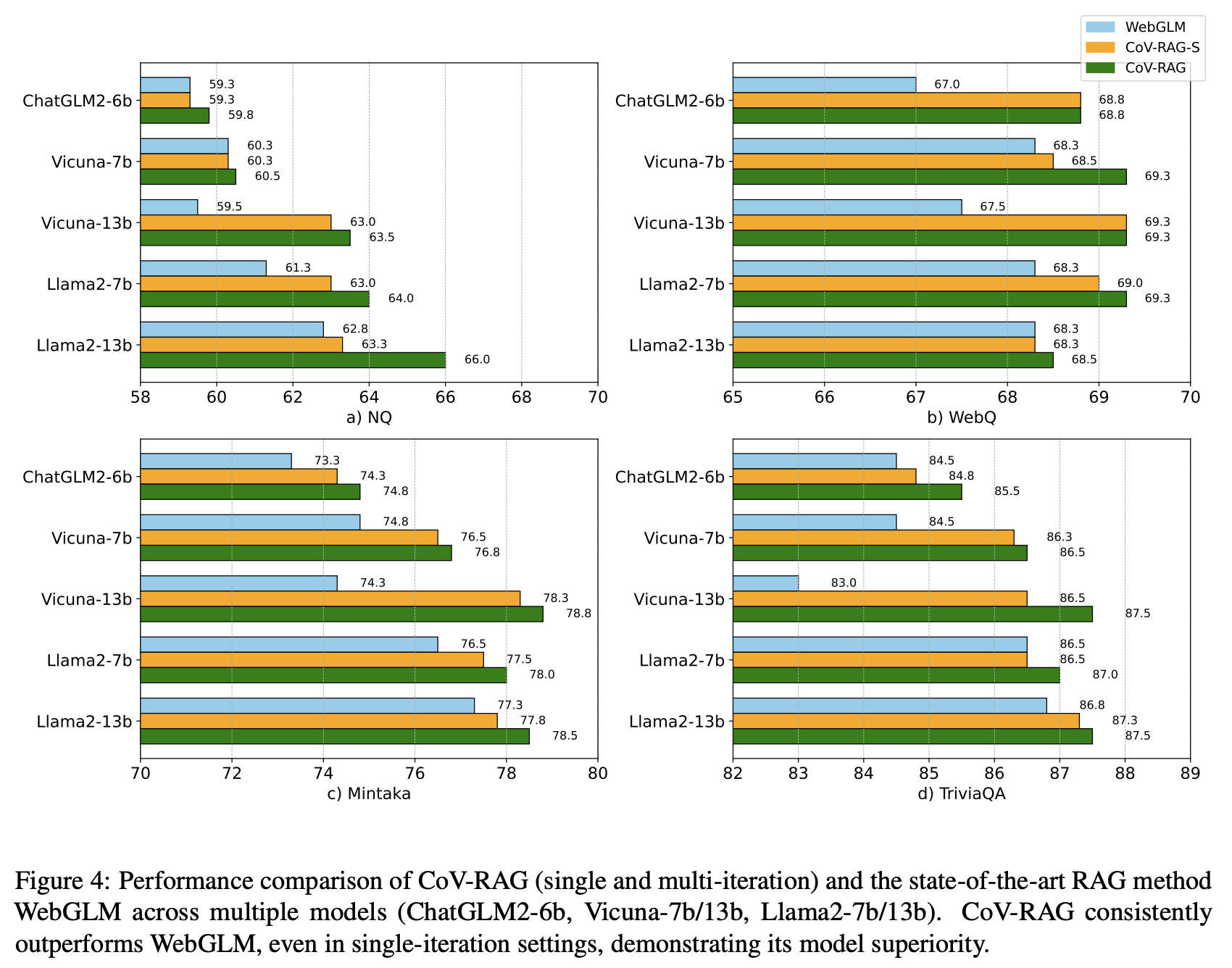
- 모델 사이즈나 종류가 다르더라도 균일하게 CoV-RAG가 가장 높은 성능을 보여줌.
- CoV-RAG-S(재검색 없이 단일 반복), CoV-RAG를 비교할 때에도 단일 반복보다 더 효과적임을 확인할 수 있음.
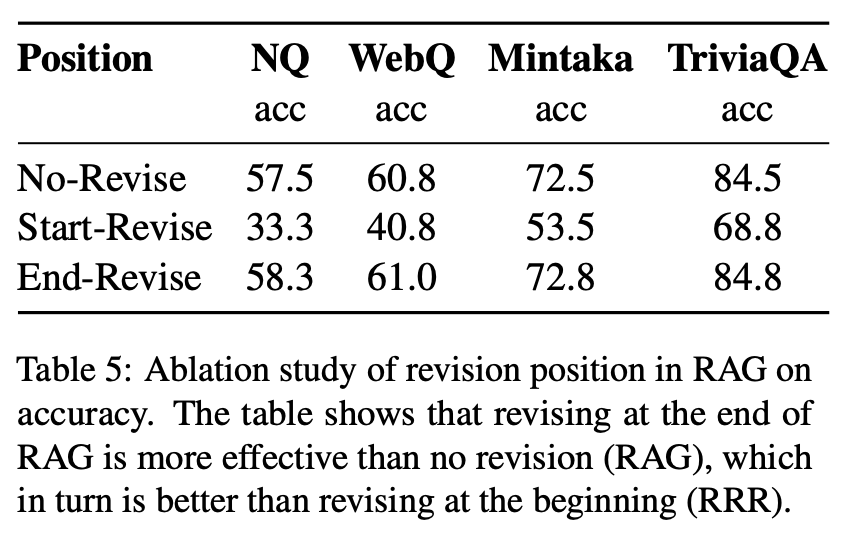
Revising Position
RAG에서 CoV의 효과를 평가한 결과, "End-Revise" 방식이 RAG 출력 후 수정하는 과정에서 가장 높은 정확도를 나타냈습니다. 반면, "Start-Revise"는 검색기에 부적합한 지나치게 긴 질문을 생성하고 원래 질문에서 벗어나는 경향이 있었습니다. 그러나 "End-Revise"는 일반 RAG 이후 질문을 다듬어 더 정확한 재검색과 향상된 성과를 이끌어냈습니다. 이러한 결과는 CoV-RAG에서처럼 과정의 끝에서 수정을 수행하는 것이 효과적임을 잘 보여줍니다.
Chain Structure
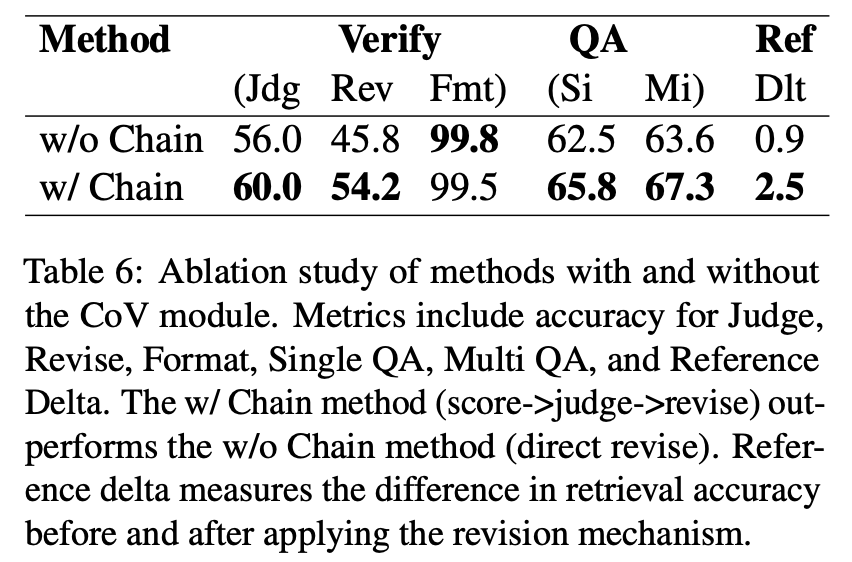
CoV 모듈이 있는 방법(w/ Chain)과 없는 방법(w/o Chain)의 성능을 비교했습니다.
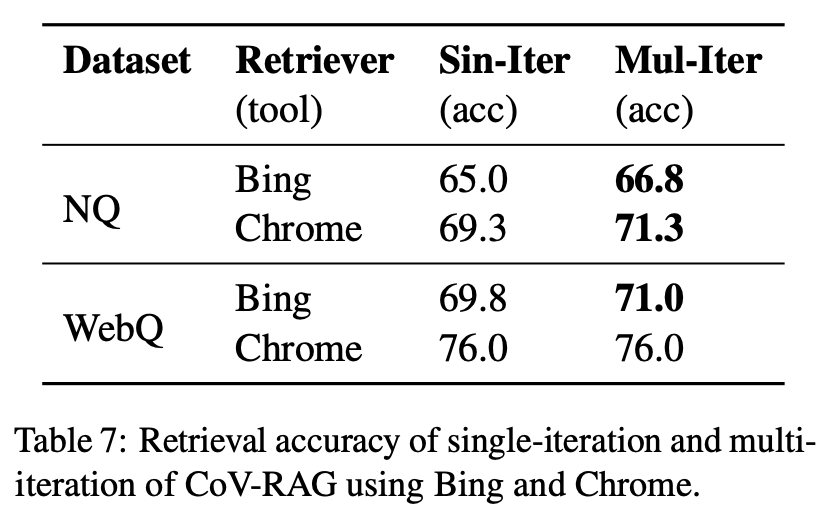
CoV-RAG using Bing and Chrome
검색 정확도 향상을 두 가지 검색 도구(Bing과 Chrome)를 사용하여 평가하였습니다. 첫 번째 단계에서는 웹 엔진(예: Google/Bing)을 통해 URL이 검색되고, HTML 콘텐츠가 크롤링되어 관련 텍스트가 추출됩니다. 두 번째 단계에서는 LLM이 추출된 콘텐츠를 정제하여 가장 관련성이 높은 정보를 식별합니다. 결과적으로 Bing을 사용할 경우 NQ 데이터셋에서 검색 정확도가 65.0%에서 66.8%로 개선되었고, Chrome에서는 69.3%에서 71.3%로 증가했습니다. 다중 반복 검색이 정확한 맥락 지식을 효과적으로 포착하여 더 나은 쿼리 응답을 이끌어낸다는 것을 확인할 수 있습니다.