이 논문은 디코더 전용 대규모 언어 모델(LLM)을 텍스트 임베딩 모델로 변환하는 새로운 간단한 비지도 학습 방법인 LLM2Vec를 제안합니다. LLM2Vec을 통해 디코더 전용 LLM을 강력한 텍스트 인코더로 변환할 수 있습니다. LLM2Vec은 1) 양방향 어텐션 활성화, 2) 마스크된 다음 토큰 예측, 3) 비지도 대조 학습의 세 가지 단계로 구성됩니다.
1.3B에서 7B 매개변수 범위의 3개 LLM에 LLM2Vec을 적용하고, 변환된 모델을 영어 단어 및 시퀀스 수준 작업에서 평가했습니다. 단어 수준 작업에서 인코더 전용 모델을 큰 폭으로 능가했으며, Massive Text Embeddings Benchmark(MTEB)에서 높은 성능을 달성했다고 합니다. 현재는 9위에 랭크되어있습니다.
LLM2Vec
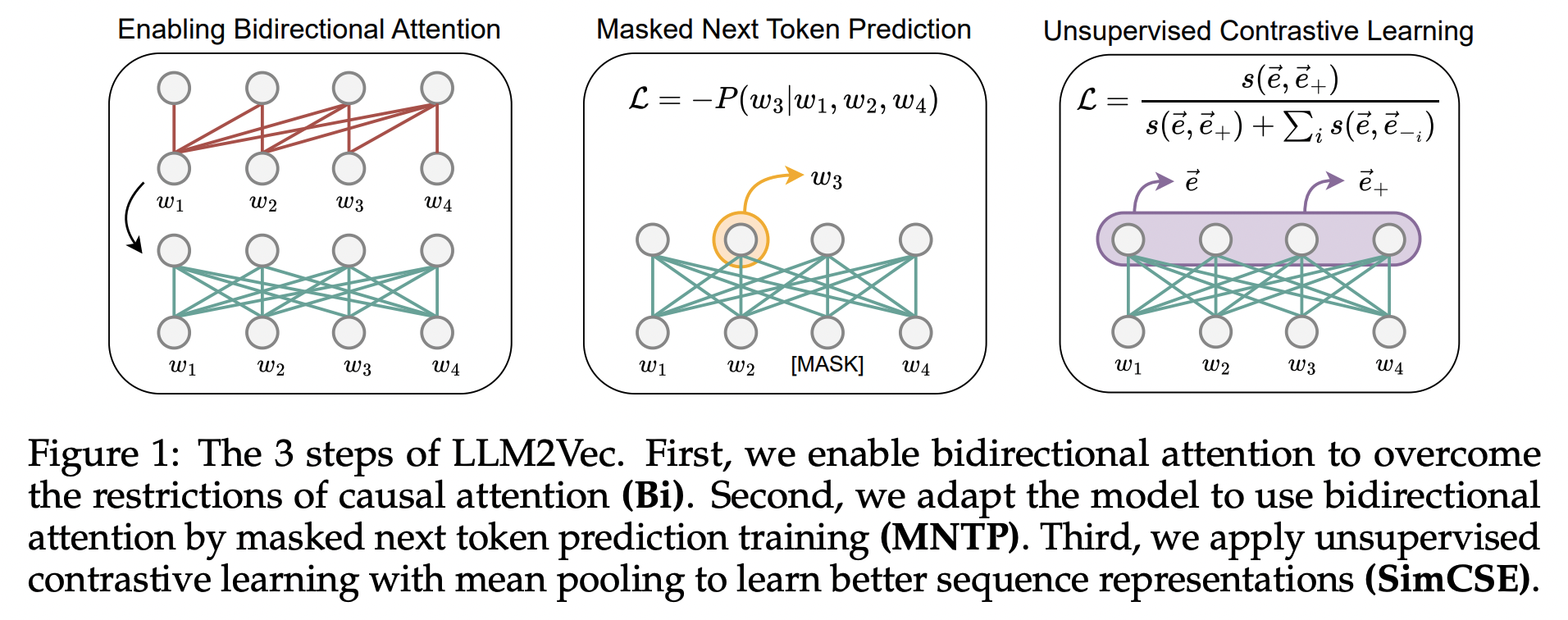
Three simple ingredients
LLM2Vec는 다음 세 가지 단순한 단계로 구성됩니다:
- 양방향 주의력 활성화 (Bi)
- 디코더 전용 LLM의 causal attention mask 전체를 1로 대체하여 각 토큰이 다른 모든 토큰에 접근할 수 있도록 합니다. 이렇게 하면 단방향에서 양방향 LLM으로 변환합니다.
- 마스크된 다음 토큰 예측 (MNTP)
- bidirectional attention을 모델에 반영하기 위해서 입력 시퀀스에서 일부 토큰을 마스킹한 후, 모델이 과거와 미래 컨텍스트를 기반으로 마스크된 토큰을 예측하도록 학습합니다.
- 마스크된 토큰 예측 시 직전 위치의 표현을 사용하여 손실을 계산합니다.
- 비지도 대조 학습 (SimCSE)
- 시퀀스 표현 능력 향상을 위해 SimCSE를 적용하여 동일 시퀀스의 두 표현 간 유사도를 최대화하고 다른 시퀀스 표현과의 유사도는 최소화합니다.
- 이를 통해 디코더 전용 LLM이 문장의 맥락을 인코더 모델처럼 이해할 수 있도록 학습합니다.
이 세 단계를 차례로 적용하여 디코더 전용 LLM을 텍스트 인코더로 변환하는 것이 LLM2Vec의 핵심입니다.
Transforming decoder-only LLMs with LLM2Vec
-
실험 모델
- 1.3B 파라미터의 Sheared-LLaMA-1.3B (S-LLaMA-1.3B)
- 7B 파라미터의 Llama-2-7B-chat (LLaMA-2-7B)
- 7B 파라미터의 Mistral-7B-Instruct-v0.2 (Mistral-7B)
-
학습 데이터
- MNTP 단계: Wikitext-103 데이터셋
- SimCSE 단계: Gao et al. (2021)이 공개한 위키피디아 문장 서브셋
-
마스크된 다음 토큰 예측 (MNTP)
- 입력 시퀀스의 일부 토큰을 랜덤하게 마스킹
- LoRA를 사용하여 이전 토큰 표현으로 마스크된 토큰 예측
- 1000스텝, 배치 사이즈 32로 1회 학습 (7B 모델은 90분 소요)
-
비지도 대조 학습 (SimCSE)
- 동일 시퀀스에 드롭아웃 2번 적용하여 긍정 예시 생성 (dropout 2번 적용?)
- 배치 내 다른 시퀀스를 negative로 활용 (In-batch negatives)
- MNTP 학습 후 LoRA 가중치 병합 및 새로운 LoRA 파라미터 초기화
- 1000스텝 학습 (7B 모델은 2.5시간 소요, 배치 128 : 80GB A100 GPU)
세 가지 디코더 전용 LLM 모델에 MNTP와 SimCSE 단계를 차례로 적용하여 LLM2Vec 변환을 수행했습니다.
LLM2Vec-transformed models are strong unsupervised text embedders
Evaluation on word-level tasks
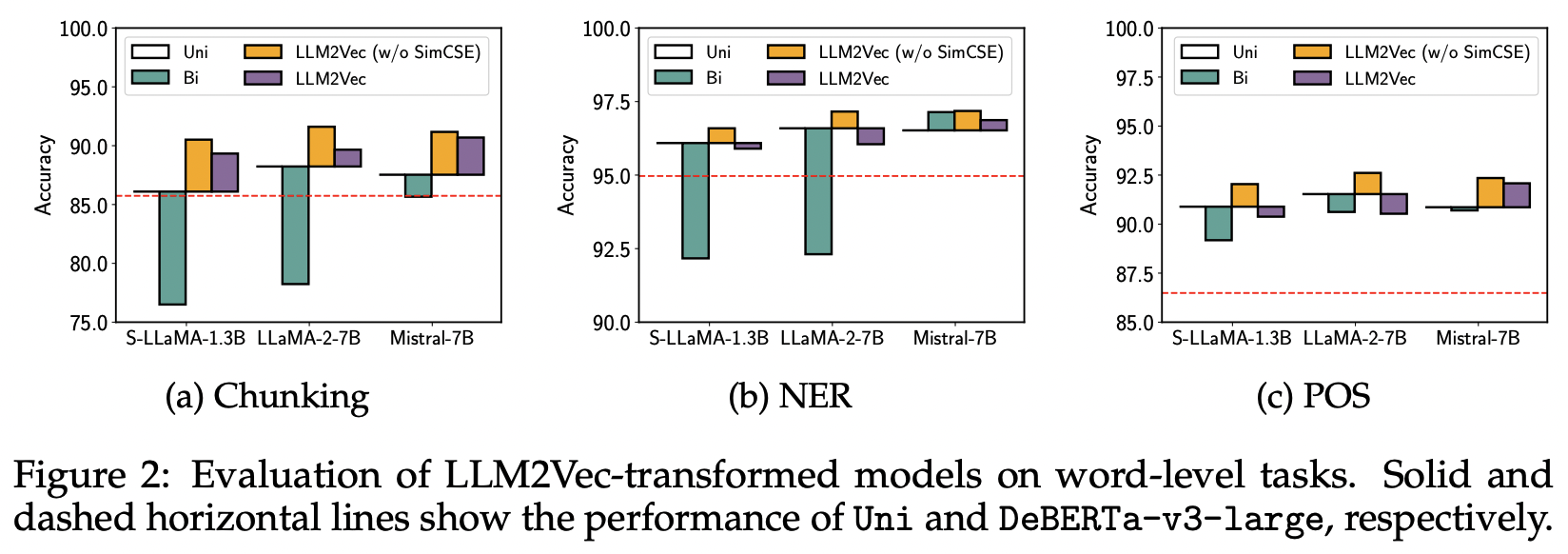
LLM2Vec을 단어 단위, 시퀀스 단위의 문제에 대해서 구분해 성능을 살펴보겠습니다.
단어 수준 작업(chunking, NER, POS)에서 LLM2Vec 변환 모델의 성능을 인코더 모델에서 우수한 성능을 가지는 DeBERTa-v3-large와 비교합니다. (Figure 2, 빨간 점선이 DeVERTa-v3-large)
-
LLM 자체(Uni)만으로도 인코더 모델보다 좋은 성능을 보였습니다(모델 크기와 학습 데이터 양의 영향).
-
초록색 : Bidirectional attention을 단순히 적용하면 대부분 모델의 성능이 크게 낮아졌지만, Mistral-7B는 영향이 적었습니다.
-
주황색 : Bidirectional attention에 MNTP(w/o SimCSE)를 추가로 적용하면 모든 모델과 작업에서 성능이 향상되었습니다. Chunking 작업에서 S-LLaMA +5%, LLaMA-2-7B +4%, Mistral-7B +4% 향상합니다.
-
보라색 : 그러나 MNTP에 SimCSE를 추가하면 단어 수준 작업에서는 성능이 떨어졌습니다. SimCSE는 시퀀스 수준 작업을 위해 표현을 변경시키기 때문이라고 볼 수 있습니다.
LLM2Vec 변환을 통해 디코더 전용 LLM의 단어 수준 표현 능력이 향상되었고, 인코더 모델을 능가하는 성능을 보였습니다.
Evaluation on sequence-level tasks
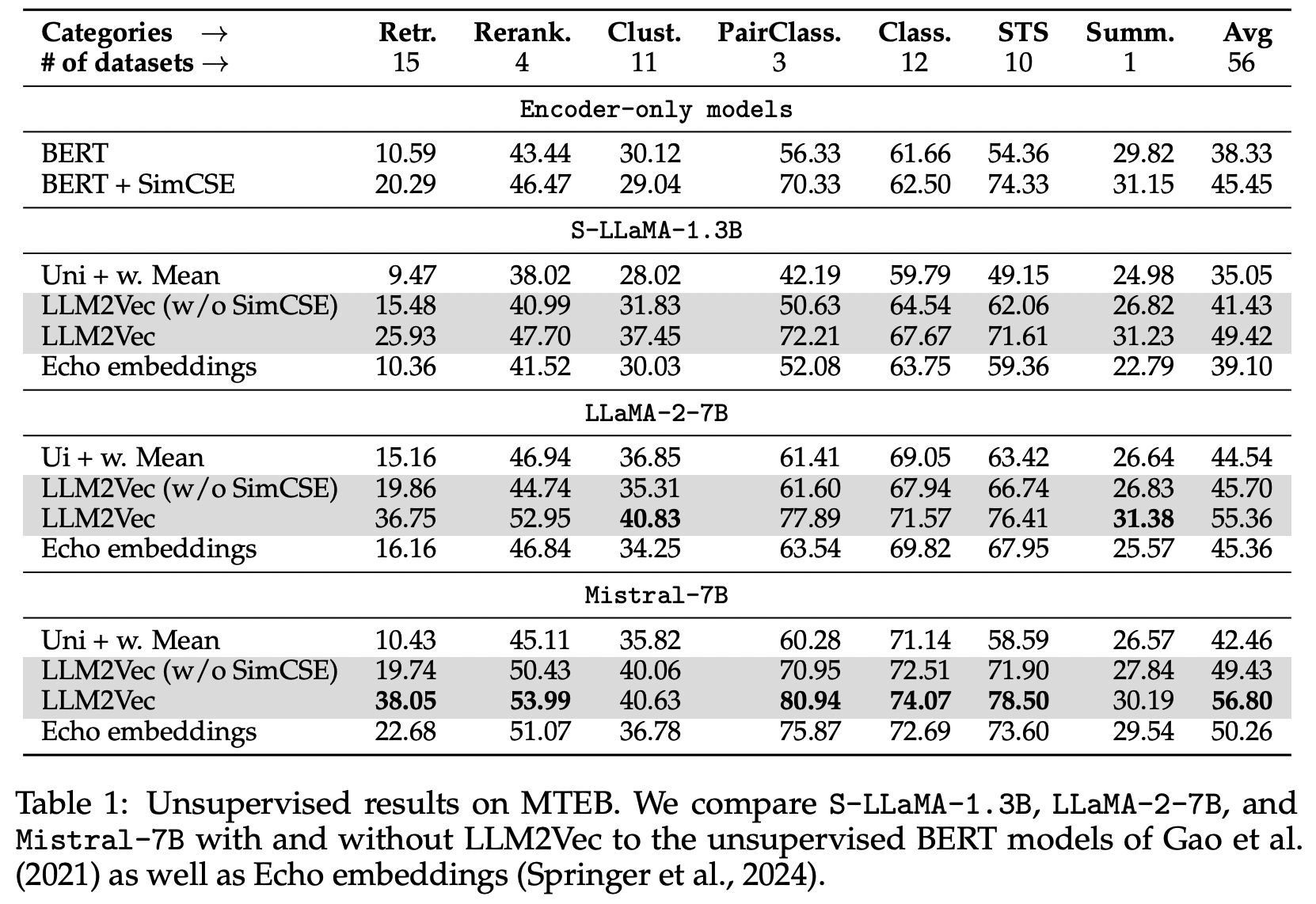
Massive Text Embedding Benchmark (MTEB)에서 LLM2Vec 변환 모델을 평가했습니다.
- MTEB는 56개 데이터셋으로 구성된 7개 카테고리를 가진 임베딩 테스크입니다.
MTEB 작업에서 LLM 자체(Uni)는 텍스트 임베딩 생성에 기존 인코더 모델 대비 비교적 낮은 성능을 가집니다. Bidirectional attention을 단순 적용하면 S-LLaMA-1.3B와 LLaMA-2-7B의 성능이 저하되었지만, Mistral-7B는 향상되었습니다.
SimCSE를 적용하면 MTEB 점수가 S-LLaMA-1.3B, LLaMA-2-7B 및 Mistral-7B의 성능이 각각 49.8%, 23.2% 및 37.5% 으로 향상됩니다. 특히 7B 파라미터의 Mistral 모델은 LLM2Vec을 적용한 후 상위 비지도 모델 중 가장 높은 56.80 점수를 기록했습니다.
(참고: Echo 임베딩은 입력을 반복하므로 시퀀스 길이를 두 배로 만들어 추론이 상당히 느리다는 단점이 있습니다.)
이렇게 LLM2Vec를 통해 디코더 전용 LLM을 MTEB 벤치마크에서 기존 비지도 방법을 능가하는 성능을 가지는 텍스트 임베딩 모델로 전환할 수 있습니다.
How does LLM2Vec affect a model?
LLM2Vec helps models to capture information from future tokens
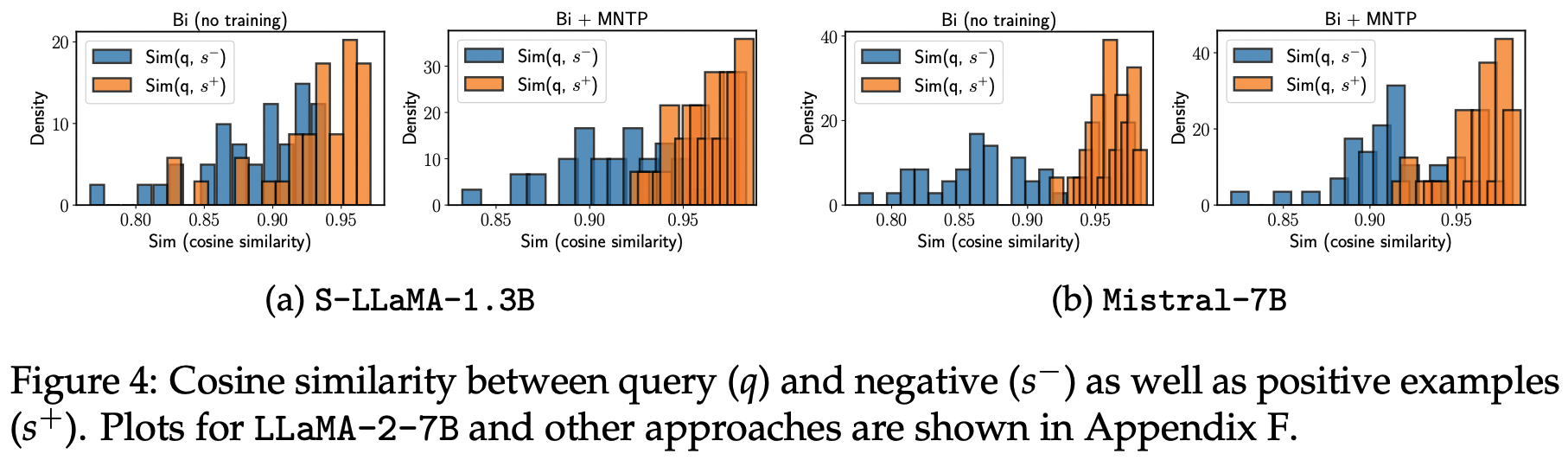
문장의 의미가 다른 문장 쌍을 분류하는 실험을 통해 LLM2Vec 변환 모델이 시쿼스 정보를 얼마나 잘 포착하는지 분석했습니다.
35 개의 문장 쌍 {(qi, s+i, s−i)} (i=1부터 35까지)가 있습니다. 여기서 qi는 (Ai, Bi), s+i는 (Ai, Ci), 그리고 s−i는 (Ai, Di)입니다. 실험 데이터셋은 접두사(Ai)가 동일하지만, 이어지는 문장 Bi와 Ci는 의미가 유사하고 Bi와 Di는 의미가 다른 35개의 문장 3중으로 구성되었습니다.
-
S-LLaMA-1.3B의 경우:
- Bidirectional attetention과 MNTP 학습만으로도 긍정 예시와 부정 예시를 명확히 구분할 수 있었습니다.
-
Mistral-7B의 경우:
- 모든 설정에서 쿼리와 긍정 예시 간 유사도가 쿼리와 부정 예시 간 유사도보다 컸습니다.
이 결과는 LLM2Vec 변환을 통해 디코더 전용 LLM이 미래 토큰 정보를 효과적으로 포착할 수 있게 되었음을 보여줍니다.
Why does bidirectional attention without training work for Mistral models?
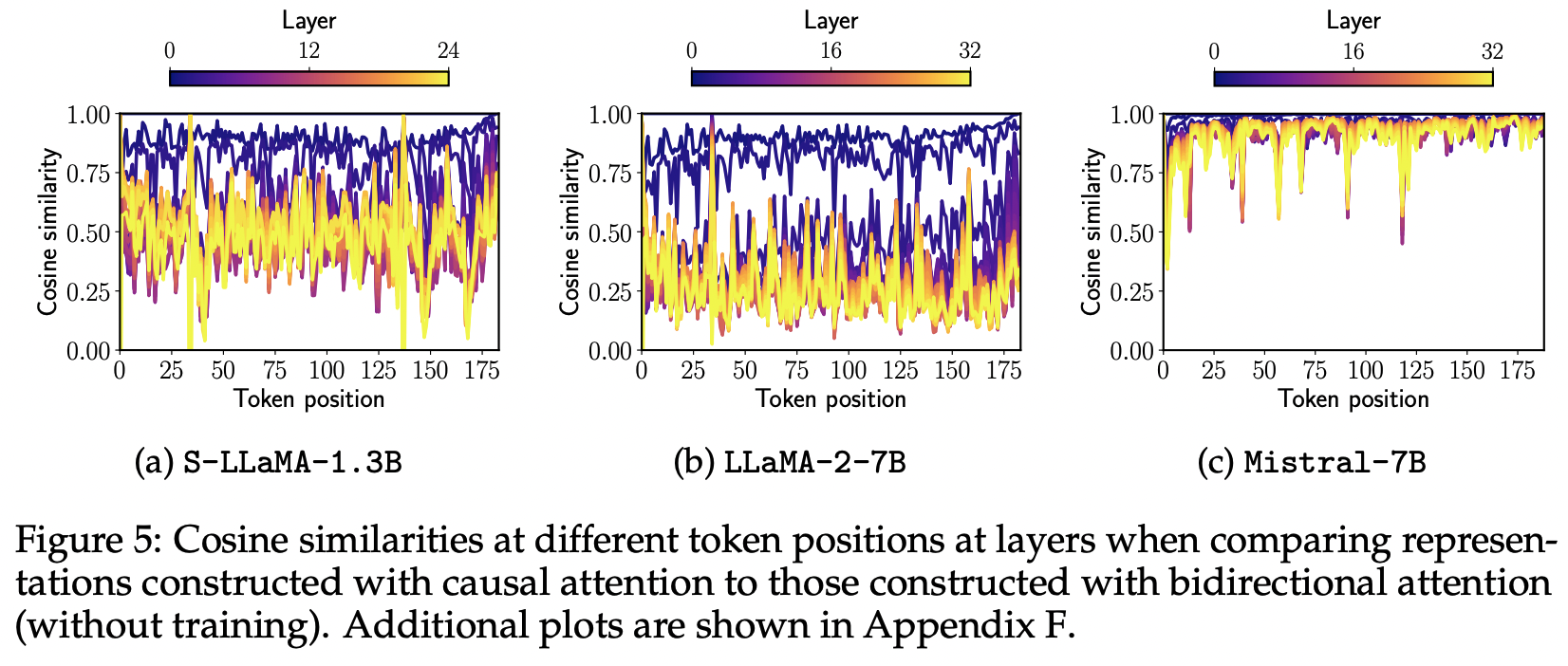
Mistral-7B 모델의 경우, 학습 없이 Bidirectional attention을 활성화하는 것만으로도 성능이 향상되는 흥미로운 현상이 발견되었습니다. 이를 분석하기 위해 단일 입력 문장에 대해 각 모델의 hidden representation을 계산했습니다.
Unidirectional representation()과 Bidirectional representation() 간 코사인 유사도를 계산한 결과,
-
S-LLaMA-1.3B와 LLaMA-2-7B의 경우, Bidirectional attention을 적용하면 은닉 표현이 크게 변화하여 Hc와 Hbi 간 유사도가 낮았습니다.
-
하지만 Mistral-7B의 경우에는 Hc와 Hbi 간 유사도가 매우 높게 나타났습니다.
-
이 결과와 Mistral-7B의 비지도 성능을 고려할 때, Mistral 모델은 사전 학습 과정에서 일부 Bidirectional attention과 관련된 기법을 사용했기 때문이라고 말합니다. (Mistral 의 특징 중 하나인 Grouped-Query Attention과 관련이 있음)
Combining LLM2Vec with supervised contrastive learning
LLM2Vec leads to strong performance on the MTEB leaderboard
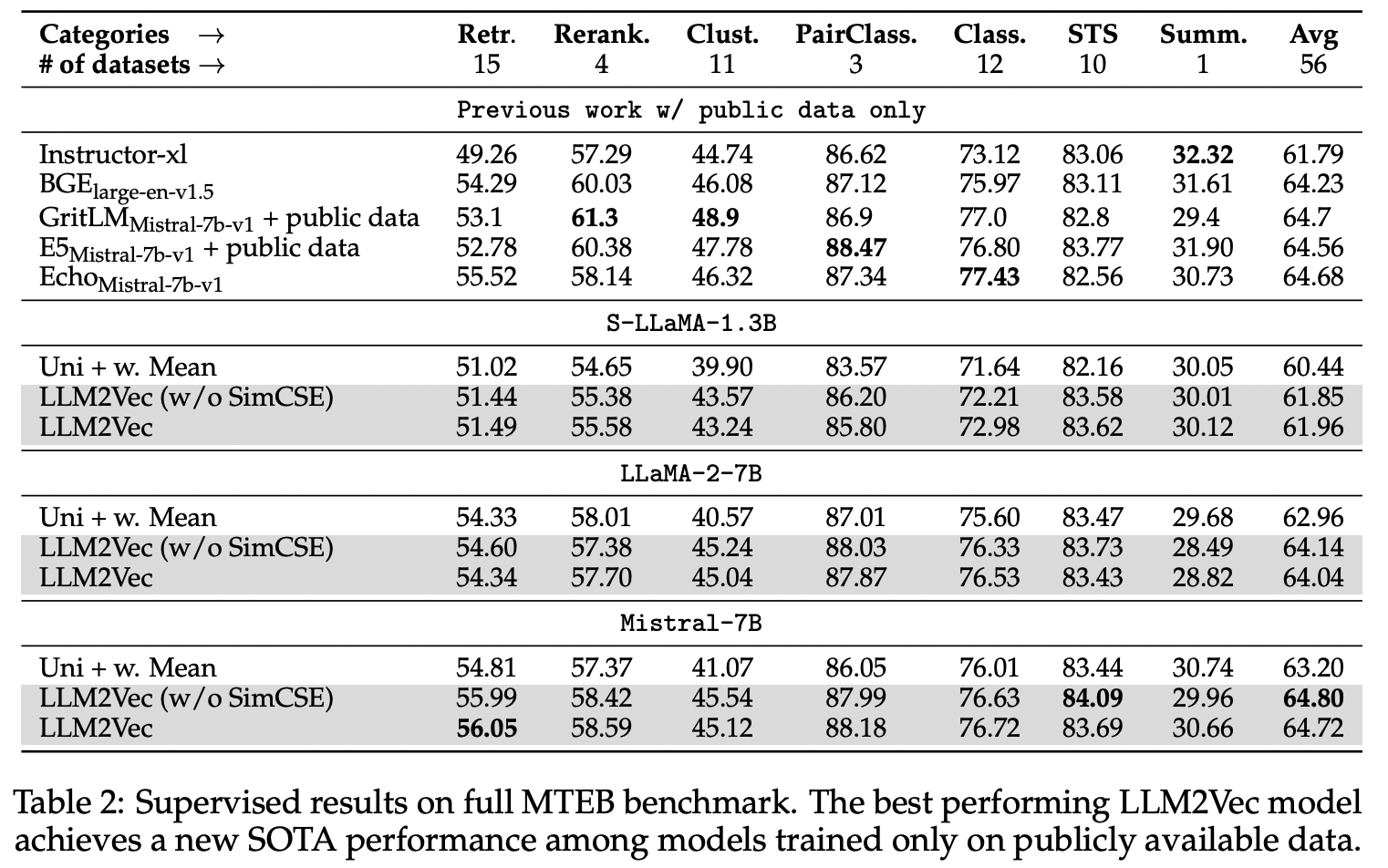
LLM2Vec와 지도 대조 학습을 결합하여 평가했습니다. 지도 학습에는 약 150만 개 샘플로 구성된 E5 dataset (Wang et al., 2023)을 사용했습니다. in-batch negatives를 훈련 과정에 포함시켜 LoRA 방식으로 파인튜닝을 진행했습니다.
-
세 모델 모두에서 LLM2Vec 변환이 기본 모델(Uni) 대비 성능 향상을 가져왔습니다.
-
SimCSE 기법을 더하는 것은 지도 학습에서 크게 중요하지 않았고, 일부 모델에서는 MNTP만 적용한 것보다 성능이 약간 낮았습니다.
- LLM2Vec 변환된 Mistral-7B 모델이 공개 데이터로 학습한 모델 중 가장 좋은 성능을 보여주었습니다.
마무리
LLM2Vec은 decoder-only 언어모델을 텍스트 임베딩 모델로 변환하는 방법입니다. 이 방법을 적용한 Mistral-7B 모델이 MTEB 벤치마크에서 현재 9위로 좋은 성능(비지도학습 기준으로는 가장 높은 성능)을 보였습니다. LLM2Vec은 단순하면서도 계산 효율성이 높다는 장점을 가지고 있습니다.
