MTEB에서 성능을 내기위해서 Linq에서는 E5-Mistral, Mistral-7B-v0.1를 사용했습니다.
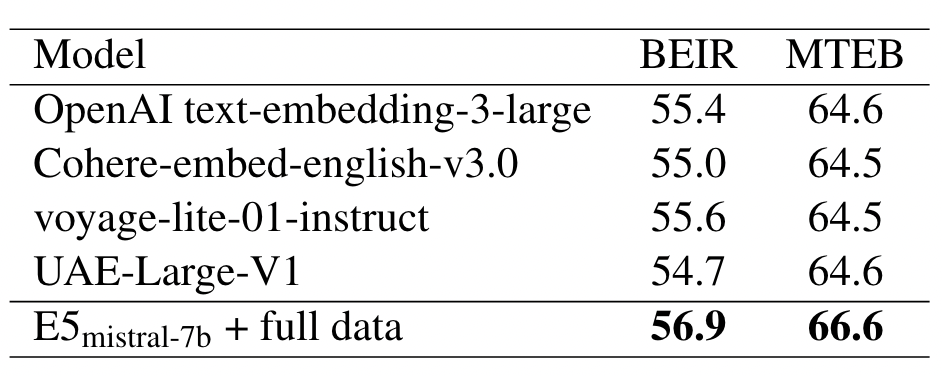
E5-Mistral 모델의 성능은 56.9였습니다. 정제된 데이터셋을 추가함으로써 SFR 모델의 성능이 59.0으로 증가하였으며, 더 정교한 합성 데이터셋을 이용함으로써 이 리포트에서 공개한 모델은 60.2까지 향상되었습니다.
Linq의 리포트를 더 잘 이해하기 위해서, 먼저 E5-Mistral 모델과 SFR 점수를 살펴보겠습니다.
E5-Mistral (Microsoft)
-
이 논문에서 저자들은 합성 데이터만으로 1,000스텝 미만의 훈련을 통해 고품질 텍스트 임베딩을 얻는 새롭고 간단한 방법을 소개합니다. 저자들은 93개 언어에 걸쳐 수십만 개의 텍스트 임베딩 작업에 대해 다양한 합성 데이터를 생성하기 위해 LLM(대규모 언어모델)을 활용했습니다. 이후 표준 대비 손실(contrastive loss)을 사용하여 오픈소스 디코더 전용 LLM을 합성 데이터로 finetuning했습니다.
-
합성 데이터와 라벨 데이터를 혼합하여 finetuning했습니다하면, 이 모델은 BEIR와 MTEB 벤치마크에서 당시 최고 수준의 결과를 내었습니다. 고품질 텍스트 임베딩을 보다 간편하고 효율적으로 얻을 수 있음을 보여줍니다.
-
Synthetic Data Generation
- 다양한 합성 데이터를 생성하기 위해 저자들은 임베딩 작업을 여러 그룹으로 분류하는 간단한 분류법을 제안합니다.
- 비대칭 작업은 쿼리와 문서의 길이가 다른 경우입니다. 예를 들어 짧은 쿼리-긴 문서, 긴 쿼리-짧은 문서 등이 있습니다. 여기에서는 2단계 프롬프트를 사용합니다. 1) LLM에게 작업 목록을 만들게 하고 2) 그 작업 정의를 바탕으로 구체적인 쿼리-문서 예시를 생성하게 합니다.

- 대칭 작업은 쿼리와 문서의 길이가 비슷한 경우입니다. 예를 들어 단일어 의미 유사도, 번역 문장 검색 등입니다. 여기서는 1단계 프롬프트를 사용해 바로 쿼리-문서 예시를 생성합니다.
- 두 경우 모두에서 다양성을 높이기 위해 프롬프트 템플릿에 플레이스홀더를 포함시켰습니다. 예를 들어 "{query_length}", "{language}" 등의 값을 무작위로 바꿔가며 프롬프트를 만듭니다.
- 이렇게 생성된 합성 데이터는 JSON 형식에 맞지 않거나 중복된 것은 제거합니다. 결과적으로 높은 품질과 다양성을 가진 대규모 합성 데이터셋을 얻을 수 있습니다.
- 150,000개의 고유 지시문으로 500,000개의 예시를 생성했습니다. 이 중 25%는 GPT-3.5-Turbo에 의해, 나머지는 GPT-4에 의해 생성되었습니다. 총 토큰 소비량은 약 1억 8천만 개입니다. 주된 언어는 영어이지만, 총 93개 언어를 포괄하고 있습니다. 자원이 부족한 하위 75개 언어의 경우 평균 1,000개의 예시가 있습니다.
-
Training
- 관련 쿼리-문서 쌍(q+, d+)이 주어지면, 먼저 다음과 같은 지시문 템플릿을 원본 쿼리 q+에 적용하여 새로운 쿼리 q+inst를 생성합니다.
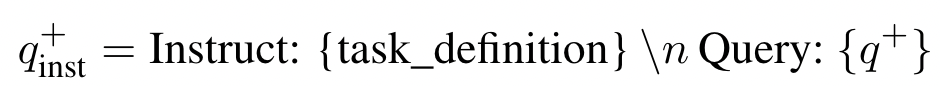
- 여기서 "{task_definition}"은 임베딩 작업에 대한 한 문장 설명을 위한 플레이스홀더입니다. 생성된 합성 데이터의 경우 구상 단계의 출력을 사용합니다. MS-MARCO와 같은 다른 데이터셋의 경우에는 작업 정의를 직접 작성하여 데이터셋의 모든 쿼리에 적용합니다. 문서 쪽에는 어떤 지시문 접두사도 추가하지 않습니다. 이렇게 하면 문서 인덱스를 사전에 구축할 수 있고, 쿼리 쪽만 변경하여 수행할 작업을 customize할 수 있습니다.
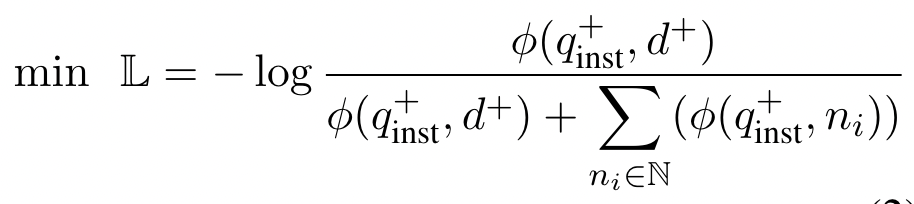
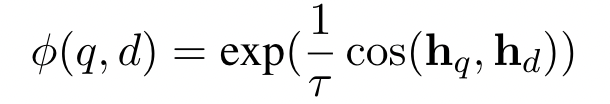
- 작은 temperature 값(예 : 0.02)을 사용할 때의 장단점:
- 장점: 유사도 점수의 작은 차이도 매우 큰 영향을 미치게 되어 모델이 미세한 유사도 차이를 잡아내는 데 민감해집니다.
- 단점: 점수 분포가 너무 뾰족해져서 소수의 극단적인 점수만 지배적이 되고, 다른 중간 점수들은 무시될 수 있습니다.
- 관련 쿼리-문서 쌍(q+, d+)이 주어지면, 먼저 다음과 같은 지시문 템플릿을 원본 쿼리 q+에 적용하여 새로운 쿼리 q+inst를 생성합니다.
SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning (Salesforce)
-
SFR-Embedding-Mistral 모델은 다양한 작업에서의 데이터로 훈련되었습니다.
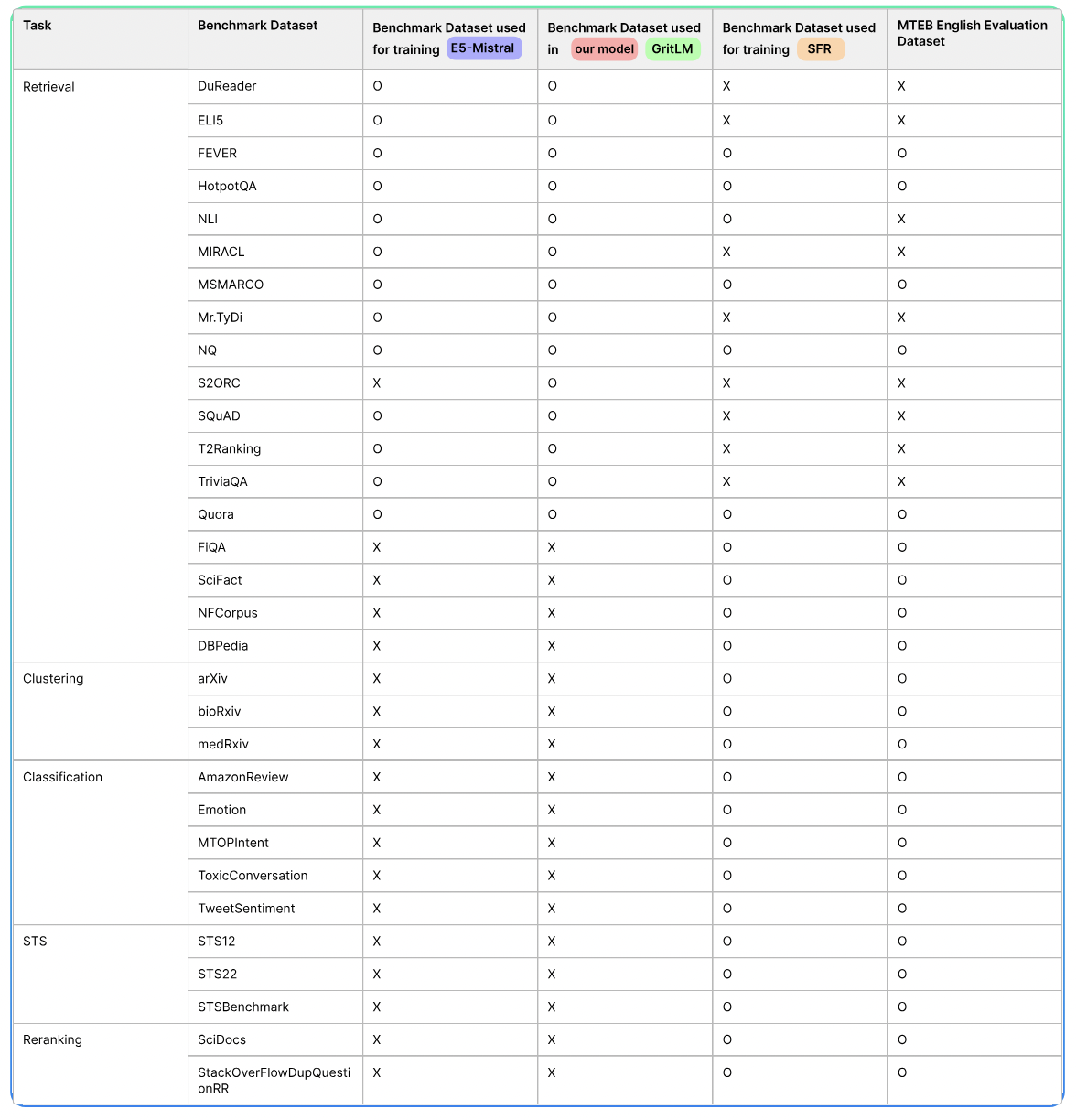
- 검색 작업에 대해서는 MS-MARCO, NQ, FiQA, SciFact, NFCorpus, DBPedia, FEVER, HotpotQA, Quora 및 NLI에서 데이터를 활용합니다.
- 클러스터링 작업에는 arXiv, bioRxiv 및 medRxiv의 데이터를 사용하며, MTEB 클러스터링 프레임워크에서 개발 및 테스트 세트를 제외하기 위한 필터를 적용합니다.
- 분류 작업에서는 AmazonReview, Emotion, MTOPIntent, ToxicConversation 및 TweetSentiment의 데이터셋을 활용합니다.
- Semantic Textual Similarity (STS)의 영역에서는 STS12, STS22 및 STSBenchmark를 사용합니다.
- 재랭킹 작업에 대해서는 SciDocs와 StackOverFlowDupQuestions의 데이터를 사용합니다.
-
e5-mistral-7b-instruct 모델로 훈련했습니다.
- batch size 2048
- learning rate 1e-5
- warmup 100 steps
- 7 hard negatives
- query length 128, document length 256
- training 15 hours on A100 GPU * 8
- LoRA adapters (rank 8, 21M trainable parameters)
-
Multi-task Training Benefits Generalization
- 클러스터링 태스크와 결합되었을 때 검색 성능이 크게 향상되는 것을 관찰했으며, 다중 태스크로부터의 지식 전달을 통해 효과를 더욱 높일 수 있습니다. 클러스터링 데이터로 학습하면서 문서를 상위 레벨 태그로 명시적으로 유도하게 되면, 임베딩 모델이 정보를 더 효과적으로 탐색하고 검색할 수 있게 됩니다.
- 클러스터링 레이블이 모델에게 상위 개념에 기반하여 임베딩을 정규화하도록 유도하기 때문에, 서로 다른 도메인 간 데이터 분리가 개선되는 것으로 추측됩니다. 더불어 다중 태스크 학습과 모델을 특정 태스크에 적응시키는 방식을 활용하면 일반화 능력도 강화될 수 있습니다.
-
Task-Homogeneous Batching
- 이 기법은 단일 태스크에서 나온 샘플로만 구성된 배치를 생성합니다. 결과적으로, 배치 내 부정적 샘플이 더욱 어려워지는데, 이는 배치 내 다른 예시들이 테스트 시나리오와 매우 유사하기 때문입니다. 실험 결과에 따르면, 태스크 동종 배치를 활용했을 때 검색 태스크에서 상당한 성능 향상이 있었으며, 특히 0.8점 가량 증가했습니다.
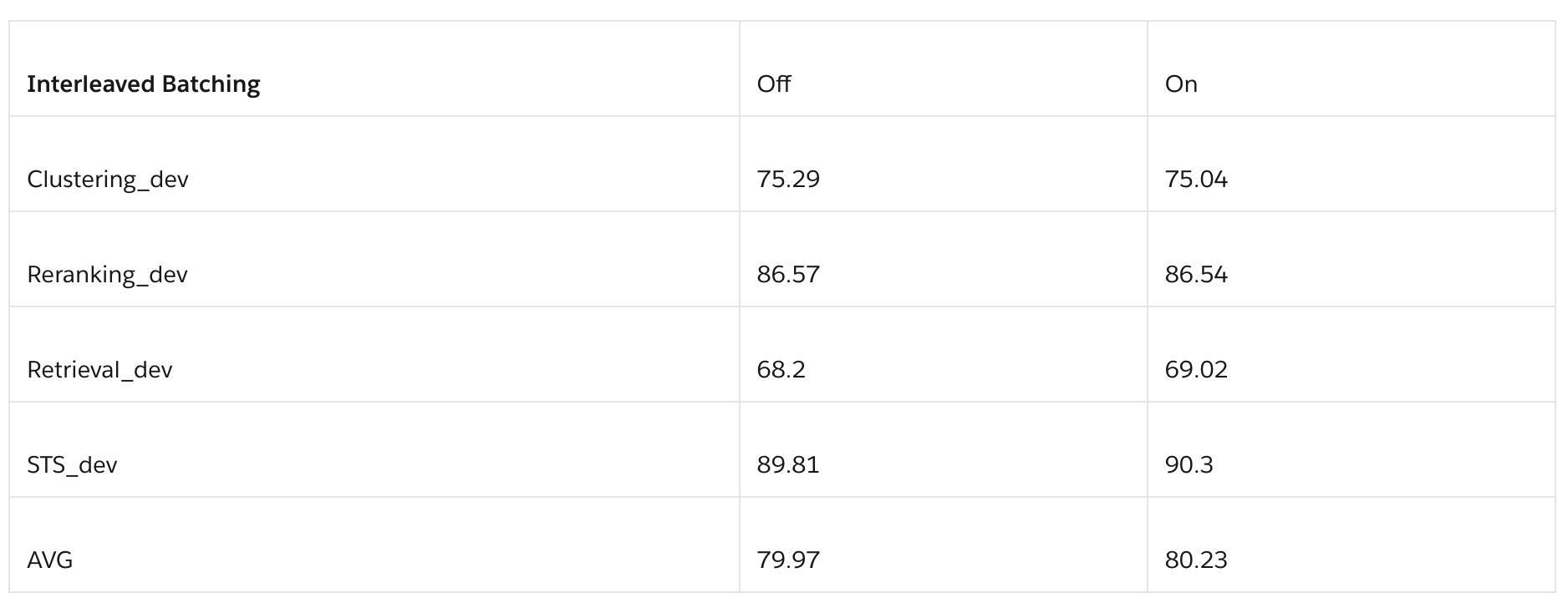
- 이 기법은 단일 태스크에서 나온 샘플로만 구성된 배치를 생성합니다. 결과적으로, 배치 내 부정적 샘플이 더욱 어려워지는데, 이는 배치 내 다른 예시들이 테스트 시나리오와 매우 유사하기 때문입니다. 실험 결과에 따르면, 태스크 동종 배치를 활용했을 때 검색 태스크에서 상당한 성능 향상이 있었으며, 특히 0.8점 가량 증가했습니다.
-
Impact of Hard Negatives
-
Strategy to Eliminate False Negatives
- 의미적으로는 해당 긍정 문서와 동일하지만 false negative로 취급되는 경우입니다. 하드 네거티브를 정확하고 효율적으로 선택하는 전략은 임베딩 학습에 있어 중요한데, 이를 통해 모델이 쿼리와 가장 관련 있는 문서를 식별할 수 있게 됩니다. 결과에 따르면 30~100 범위에서 성능이 향상되는 것으로 나타납니다. 아래 표를 보면 하위 랭크(50-100 범위)의 네거티브 샘플이 모델을 충분히 혼란스럽게 하지 못한다고 볼 수 있습니다.
- 좋은 하드 네거티브는 긍정 샘플과 유사하여 모델이 두 샘플을 구별하기 어려워야 합니다. 모델이 미묘한 차이를 학습하고 개선될 수 있어야한다는 점에서 모델 학습을 위한 적절한 난이도를 갖춘 좋은 하드 네거티브를 선별하는 것이 중요합니다.
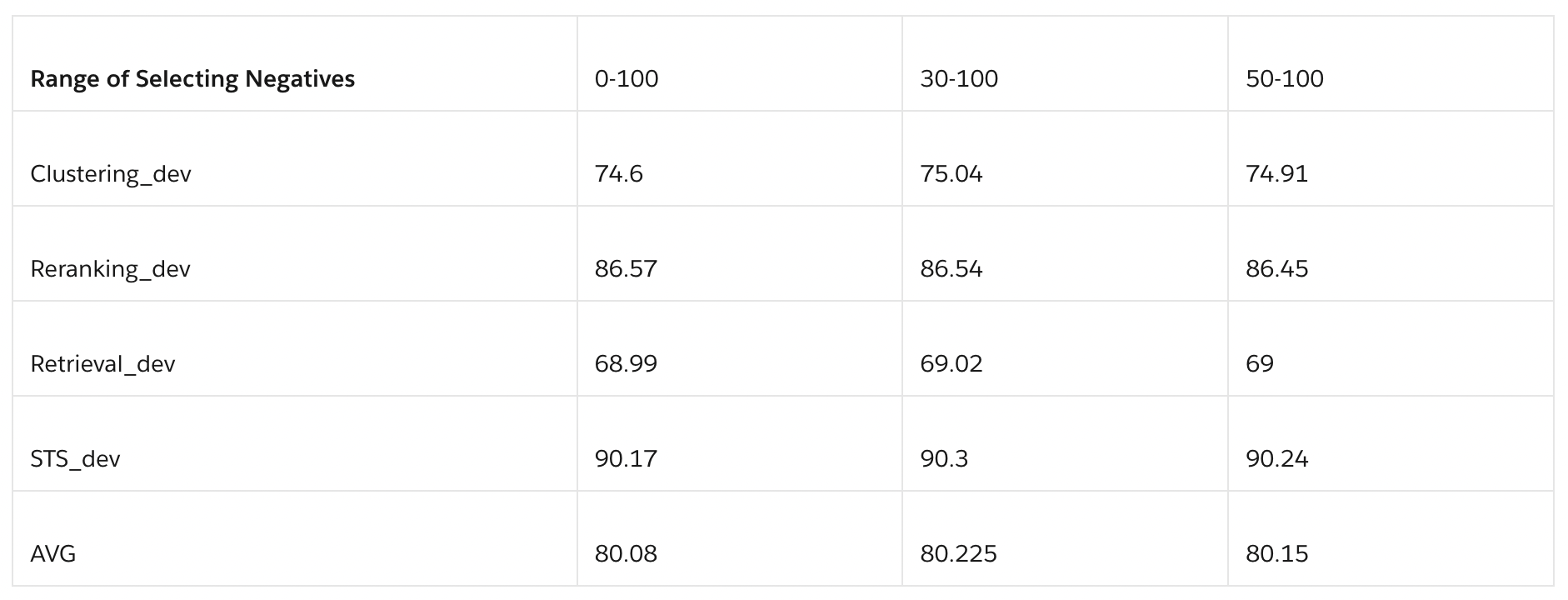
-
Number of Hard Negatives
- 하드 네거티브의 수는 모델의 학습 동력에 상당한 영향을 미칩니다. 더 많은 하드 네거티브 프롬프트를 포함하면 모델이 더 미묘한 차이를 구별할 수 있게 되어 일반화 능력이 향상될 수 있습니다. 그러나 연구 결과에 따르면 하드 네거티브의 수에 관계없이 훈련 과정 자체는 비교적 안정적인 것으로 나타났습니다.
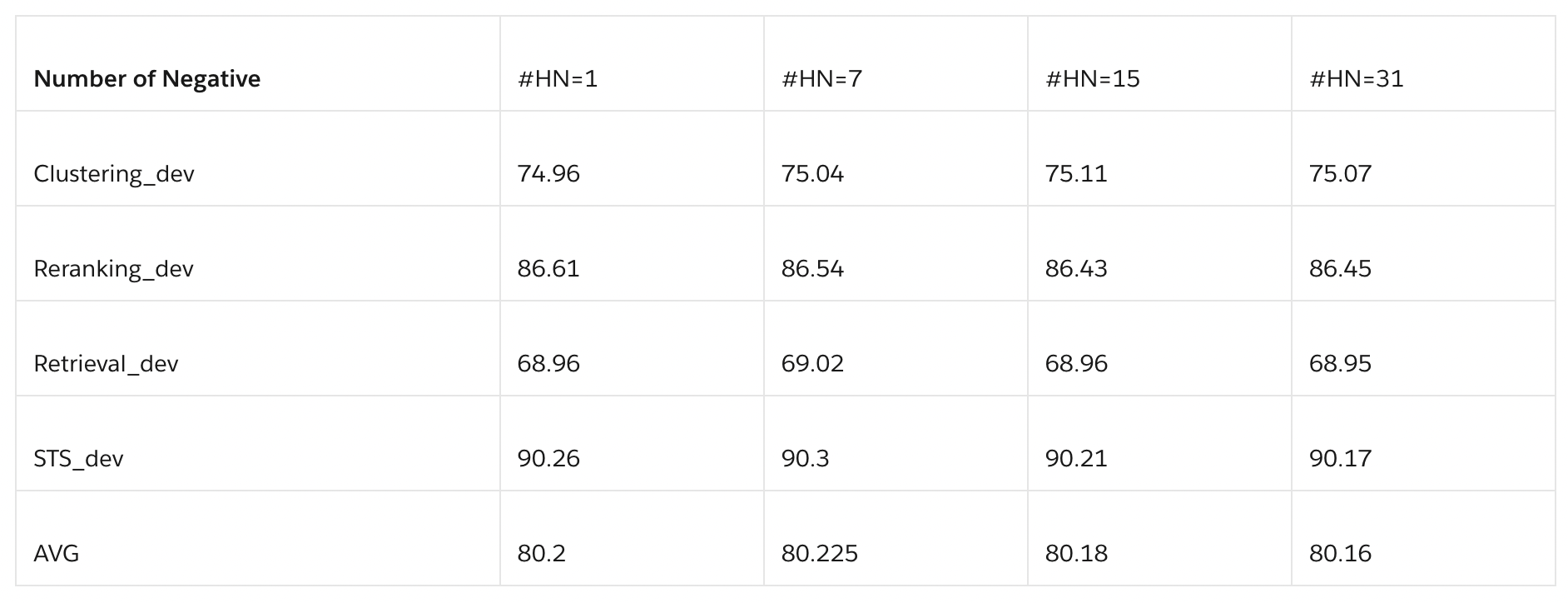
- 하드 네거티브의 수는 모델의 학습 동력에 상당한 영향을 미칩니다. 더 많은 하드 네거티브 프롬프트를 포함하면 모델이 더 미묘한 차이를 구별할 수 있게 되어 일반화 능력이 향상될 수 있습니다. 그러나 연구 결과에 따르면 하드 네거티브의 수에 관계없이 훈련 과정 자체는 비교적 안정적인 것으로 나타났습니다.
-
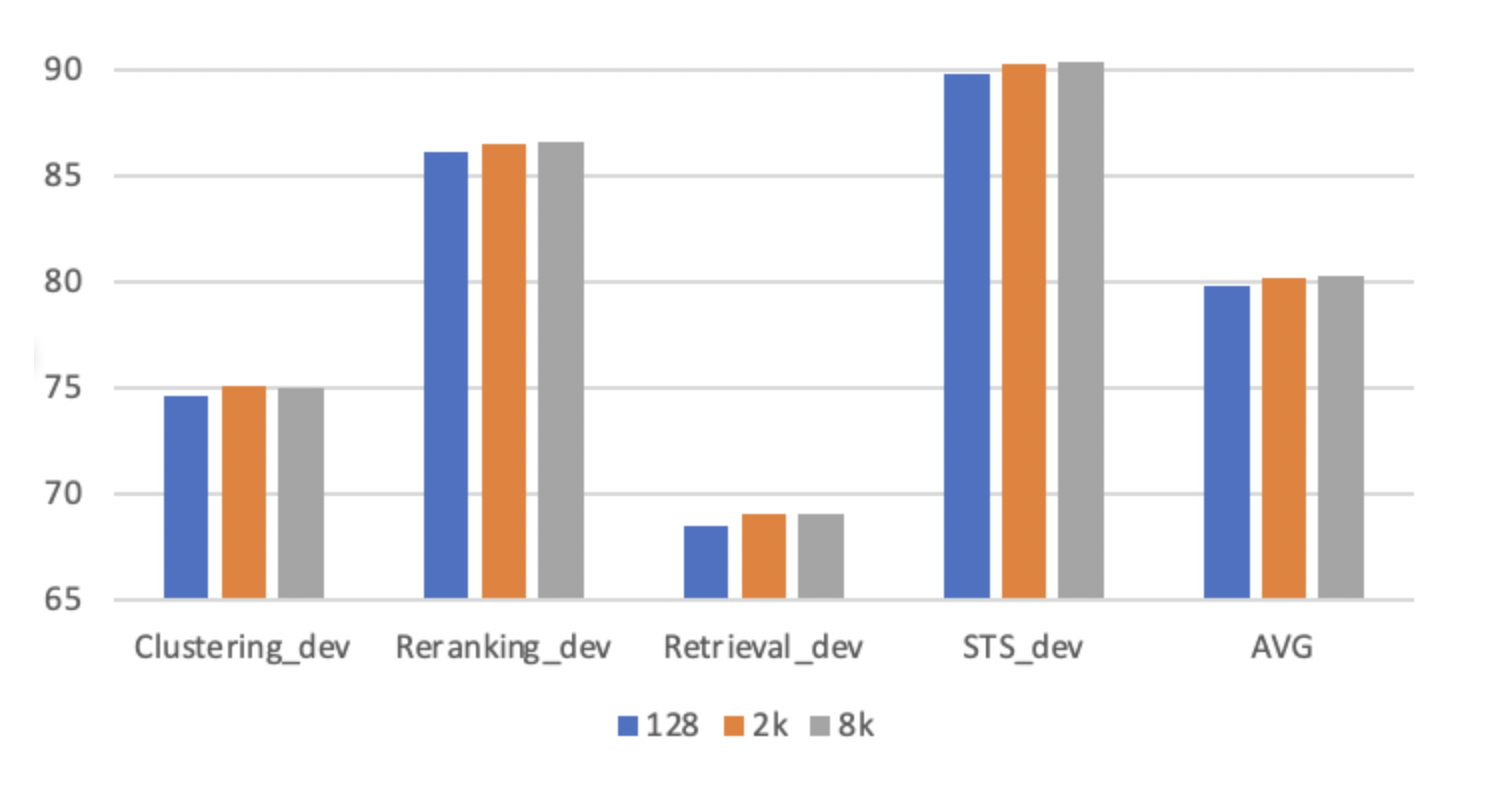
Impact of Batch Size
- 더 큰 배치 크기를 활용하는 것이 유리한 것으로 나타났는데, 이는 주로 더 어려운 부정적 사례를 많이 포함할 수 있기 때문입니다. GradCache를 사용하여 큰 배치 크기로 학습할 수 있었습니다. 배치 크기가 128, 2048, 8192일 때의 영향을 평가하기 위해 실험을 진행했습니다. 큰 배치 크기(2K+)를 활용하면 일반적으로 미세조정에 사용되는 작은 배치 크기(예: 128)에 비해 상당한 성능 향상이 있습니다. 하지만 배치 크기를 2048에서 8192로 늘리면 성능 변화가 크지 않습니다.
- 연구 결과에서는 2048 수준의 배치 크기가 최적의 성능을 내는 것으로 보입니다. 8192로 배치 크기를 늘려도 추가적인 이득이 없었기 때문입니다. 계산 효율성 측면에서도 2048이 적절한 선택이었을 것으로 예상됩니다.
-
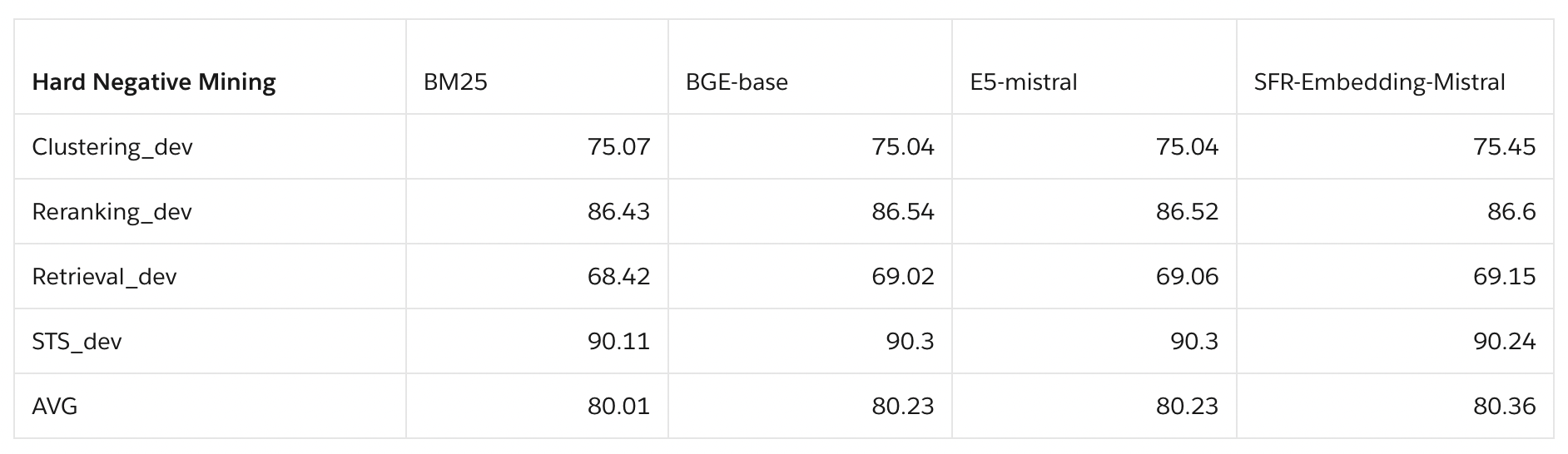
Teacher models for hard negative mining
- 더 발전된 모델을 교사 모델로 사용하면 하드 네거티브의 질을 높일 수 있습니다. 강력한 모델일수록 긍정 샘플과 하드 네거티브의 미묘한 차이를 더 잘 포착할 수 있기 때문입니다. 이를 통해 학생 모델이 보다 세분화된 패턴을 학습하고 일반화 능력을 기를 수 있습니다.
- 다중 라운드 훈련을 적용하면 하드 네거티브 채굴과 모델 정제 과정을 반복적으로 수행할 수 있습니다. 첫 라운드에서 SFR-Embedding-Mistral로 하드 네거티브를 채굴한 후, 이를 활용하여 SFR-Embedding-Mistral 자체를 개선시킵니다. 그리고 향상된 모델로 다시 하드 네거티브를 채굴하는 방식입니다. 이 과정을 반복하면 점차 모델과 하드 네거티브의 품질이 향상될 것입니다.
-
Linq-Embed-Mistral Report
-
이 리포트는 "LLM(대형 언어 모델) 생성 데이터를 검색 성능 향상에 활용할 수 있을까요? 생성 데이터를 검색 성능 향상에 활용할 수 없다면, 데이터의 품질을 어떻게 향상시킬 수 있을까요?" 와 같은 질문을 해결하는 과정을 담았습니다.
-
Linq-Embed-Mistral의 주요 기여점은 다음과 같습니다:
-
데이터 정제 방법: 정교한 데이터 제작, 필터링 및 네거티브 마이닝을 포함하는 데이터 정제 방법을 사용하여 Linq-Embed-Mistral 모델이 오해의 소지가 있는 문서를 식별하는 능력을 크게 향상시켰습니다. 이러한 데이터 정제 방법들은 벤치마크 데이터셋의 품질을 개선하고 GPT-4가 생성한 합성 데이터셋의 문제를 해결함으로써 Linq-Embed-Mistral 모델이 더 정확하고 신뢰할 수 있는 결과를 보장하도록 합니다.
-
Homogeneous Task Ordering & Mixed Task Fine-tuning: Homogeneous Task Ordering는 과제 순서의 영향을 명확히 파악하게 해주며, Mixed Task Fine-tuning은 모델이 이전에 학습했던 정보가 손실되지 않도록 합니다.
-
효율적인 평가 설계: 4비트 정밀도와 경량 검색 평가 세트를 사용하는 효율적인 평가 방법을 설계했습니다. 이 방법은 검증 과정을 가속화하며, 전체 규모의 평가와 비교했을 때 성능 차이가 거의 없습니다. Linq-Embed-Mistral의 효율적인 평가 설계는 단일 GPU가 하나의 체크포인트를 평가하는 데 약 5시간이 걸리며, 특히 검색 작업은 약 4시간이 소요됩니다.
-
- GPT-4-Turbo와 E5-Mistral의 합성 데이터 전략에서의 문제점
- E5-Mistral에서 사용한 각 분야에 대해서 부족한 점을 분석합니다.
- STS (Semantic Textual Similarity)
- 중복된 문장을 생성하는 경향이 있으므로 중복을 제거해야 합니다.
- 다양한 주제의 유사한 쿼리가 생성됩니다.
- 생성된 긍정 예제 중 일부는 어려운 음성보다 품질이 낮을 수 있습니다.
- STS 작업에서는 긍정과 부정 예제 간의 점수 차이가 작을 때 거짓 음성이 발생할 수 있습니다.
- 부정적인 예제는 상위 수준의 용어를 사용하여 제한될 수 있으며, 반사실적인 문장 및 부정 패턴이 부족할 수 있습니다.
- Long-Short (Classification)
- GPT-4-turbo는 특정 키워드가 포함될 때 특정 단어를 높은 확률로 생성하는 경향이 있습니다.
- 생성된 데이터에서는 다양한 작업에 따라 출력 레이블의 다양성이 충분히 표현되지 않을 수 있습니다.
- Short-Long (Retrieval)
- 단어 길이 불일치: 특히 비영어 언어에서 GPT-4-turbo는 단어 길이를 제어하는 데 어려움을 겪습니다.
- 자기 설명 문제: 생성된 문단의 긍정/부정에 대한 이유를 함께 추가합니다.
- 쿼리 포함: 때로는 쿼리 자체가 문단에 포함됩니다.
- 어려운 음성 품질: 생성된 어려운 음성 중 일부는 주어진 쿼리와 관련성이 적지만, 일부는 여전히 일반적이거나 부분적으로 답변 가능한 응답을 제공합니다.
- 주어진 긍정 품질: 주어진 긍정적인 문단이 모호할 때가 있으며, 더 관련성 있는 긍정적인 샘플이 다른 문단 풀에 존재할 수 있습니다.
- Short-Short (Matching)
- 어려운 음성에서의 내용 반복: 어떤 어려운 음성은 긍정과 내용이 똑같이 반복되어 있어 진짜 음성으로 분류하기 어려습니다.
- 개체 정보의 부족: 생성된 데이터에는 개인 이름, 장소 이름, 영화 제목, 게임 제목 등과 같은 개체 정보가 부족합니다.
- 구어체 부족: 생성된 데이터에는 실제적이고 공감 가능한 문장을 만들기 위해 필요한 구어체가 부족합니다.
- Long-Long (Matching)
- 어려운 음성에서의 내용 반복: 일부 어려운 음성은 긍정과 내용이 똑같이 반복되어 있어 진짜 음성으로 분류하기 어렵습니다.
- 과도하게 어려운 음성: 생성된 어려운 음성이 종종 너무 어려워서 명확하게 구분할 수 있는 음성이 부족합니다.
- Bitext (Multilingual Translation)
- 거짓 음성 빈도 상승: 다국어 설정에서, 거짓 음성이 실수로 양성으로 분류되는 경우가 많이 발생합니다.
-
데이터 정제 방법을 사용하여 텍스트 검색을 개선하고자 했습니다.
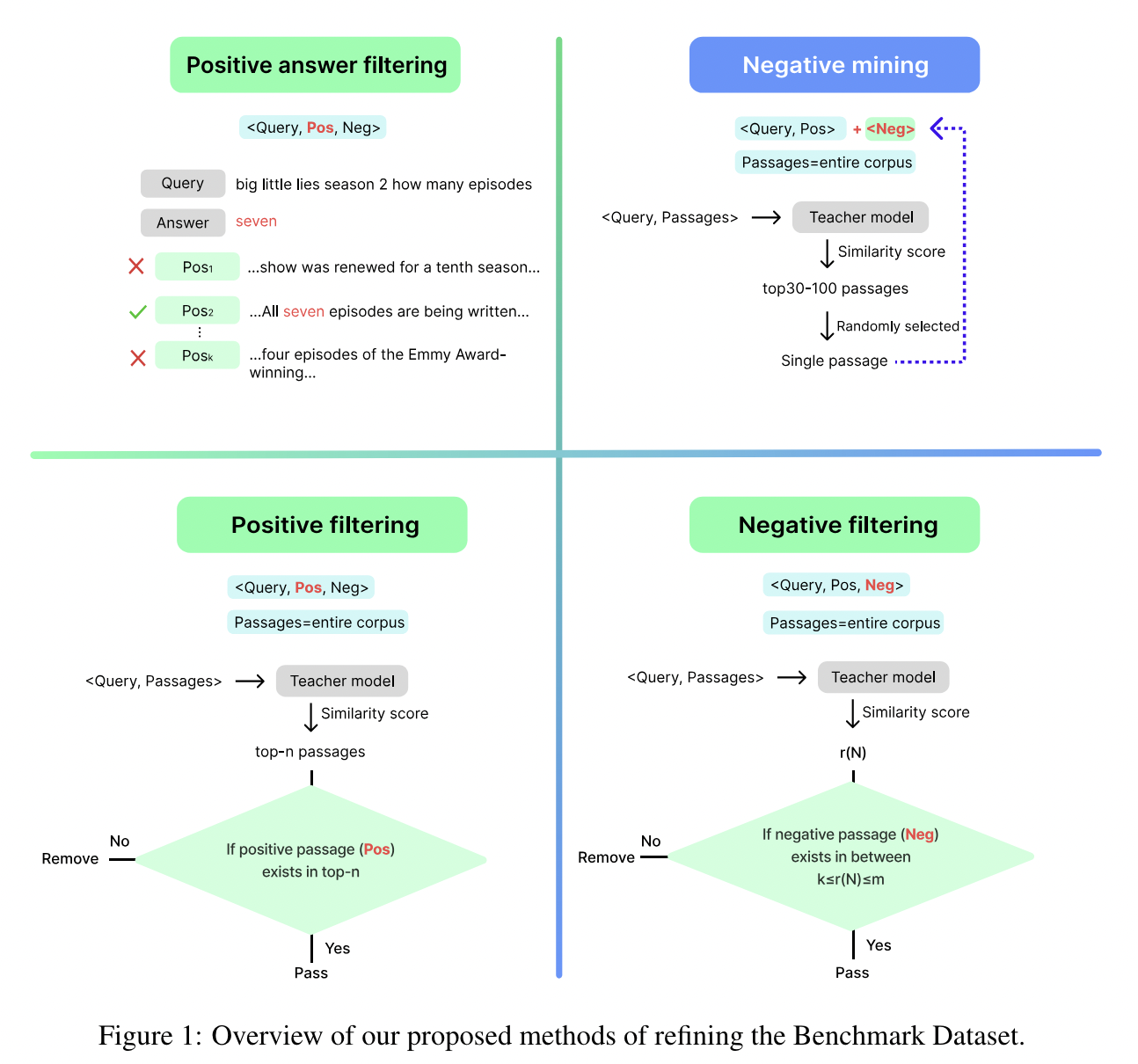
- 데이터 소스 선택: 여러 데이터 소스가 있는 경우 (예: KILT 또는 DPR의 HotpotQA), 각 소스를 테스트하고 가장 적합한 것을 선택했습니다.
- 긍정적인 답변 필터링: 답변을 포함하는 문단만 사용합니다.
- 긍정 필터링: 교사 모델의 상위-n 순위 내에 있는 긍정적인 예제만 사용합니다.
- 부정 샘플링: 교사 모델의 상위 30-100 순위 내에서 샘플을 선택하여 부정 예제로 사용합니다.
- 부정 필터링: 교사 모델을 사용하여 다양한 전략을 구현하며, 부정적인 예제(N)가 특정 범위 내의 순위(r)에 있을 때만 고려됩니다. 즉, (k ≤ r(N) ≤ m)입니다.
- 데이터 소스 선택: 여러 데이터 소스가 있는 경우 (예: KILT 또는 DPR의 HotpotQA), 각 소스를 테스트하고 가장 적합한 것을 선택했습니다.
-
Training
- Contrastive Loss
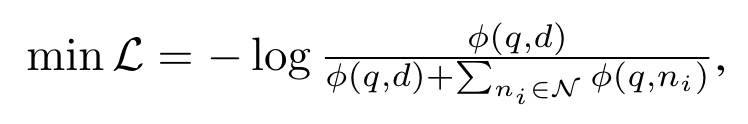
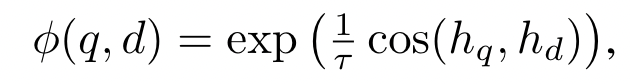
- E5-Mistral-7b-instruct 모델을 batch size 2080, learning rate 1e-4
- SRF는 쿼리 128, 문서 256 sequence length 썼지만 여기에서는 4k (평가는 512)
- SFR와 같이 Task-Homogeneous Batching 사용합니다.
- SFR은 각 쿼리에 7개의 어려운 부정 예제를 사용하는 것이 최상의 결과를 얻는다고 했지만, 여기에서는 데이터 품질이 향상됨에 따라 더 많은 어려운 부정 예제로 인한 결과가 감소하는 경향을 보였습니다. 결론적으로 hard negative 한 개만 사용합니다.
- top 30-100 negative samples
- Contrastive Loss
-
Homogeneous Task Ordering and Mixed Task Fine-tuning
- 초기에 동질적 작업 세밀 조정을 한 에폭 동안 수행한 후, Mixed Task Fine-tuning을 몇 단계 동안 진행합니다. 이 구조화된 접근법은 다양한 작업에 걸쳐 학습을 최적화하여 성능 변동을 줄이고 현재 단계에서 미훈련된 작업에 대한 치명적인 잊혀짐의 영향을 감소시키도록 설계되었습니다.
- 평가세트 간소화
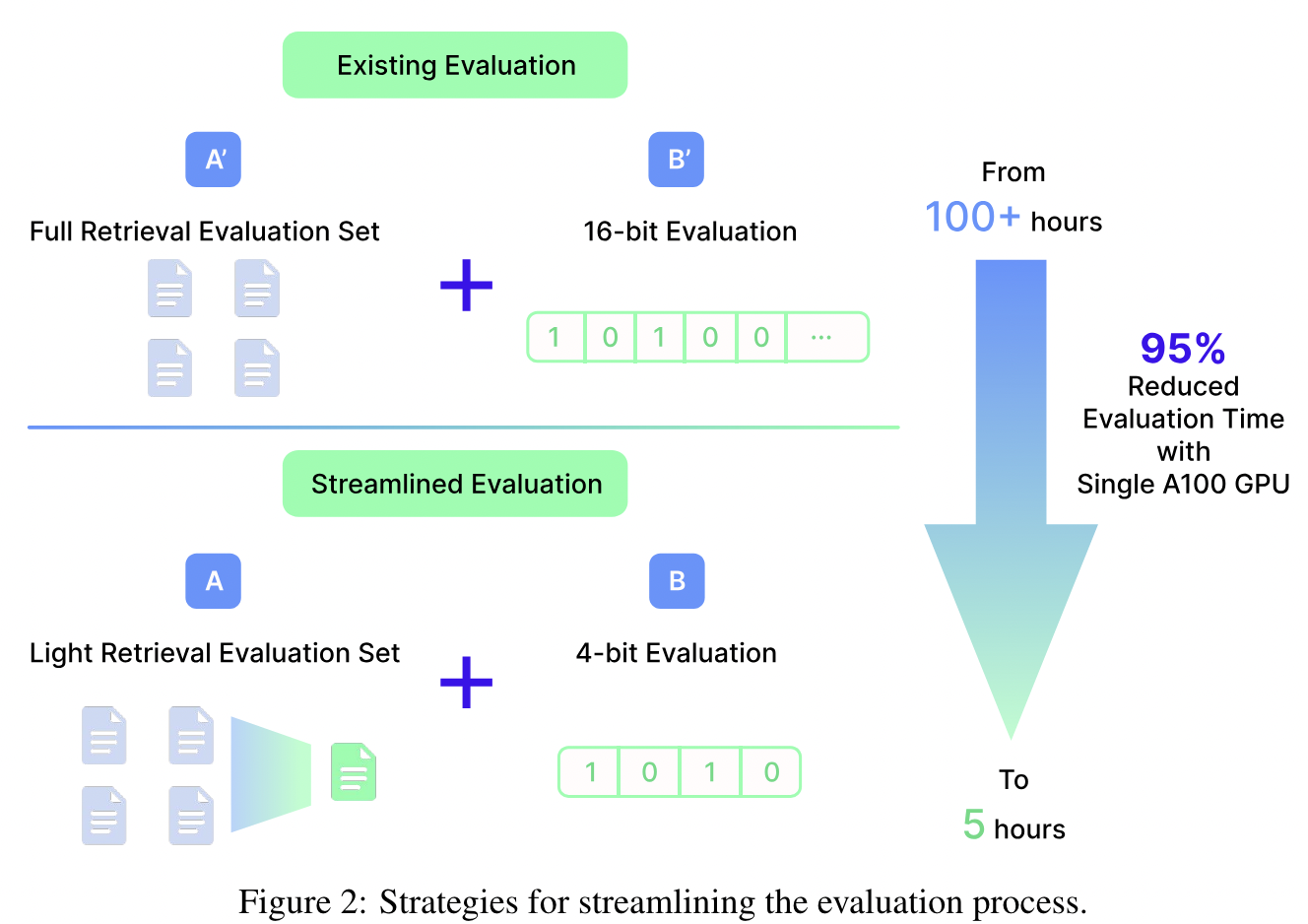
- 모델의 성능을 빠르게 확인하기 위해, 완전한 평가 세트에 대한 성능과 비교할 때 무시할 만한 성능 차이를 가진 가벼운 검색 평가 세트를 설계했습니다. 이 접근 방식을 통해 정확도를 크게 희생하지 않고도 검색 작업에 대한 모델의 성능을 효율적으로 평가할 수 있으므로, 전체적인 평가 프로세스를 최적화합니다.
- 4비트 정밀도를 사용하여 평가하면 16비트 정밀도를 사용하는 경우보다 단일 GPU가 더 많은 샘플을 처리할 수 있습니다. 이로 인해 처리 속도가 상당히 향상되며, 저희의 GPU 설정에서 최대 약 40%의 향상이 관찰되었습니다.
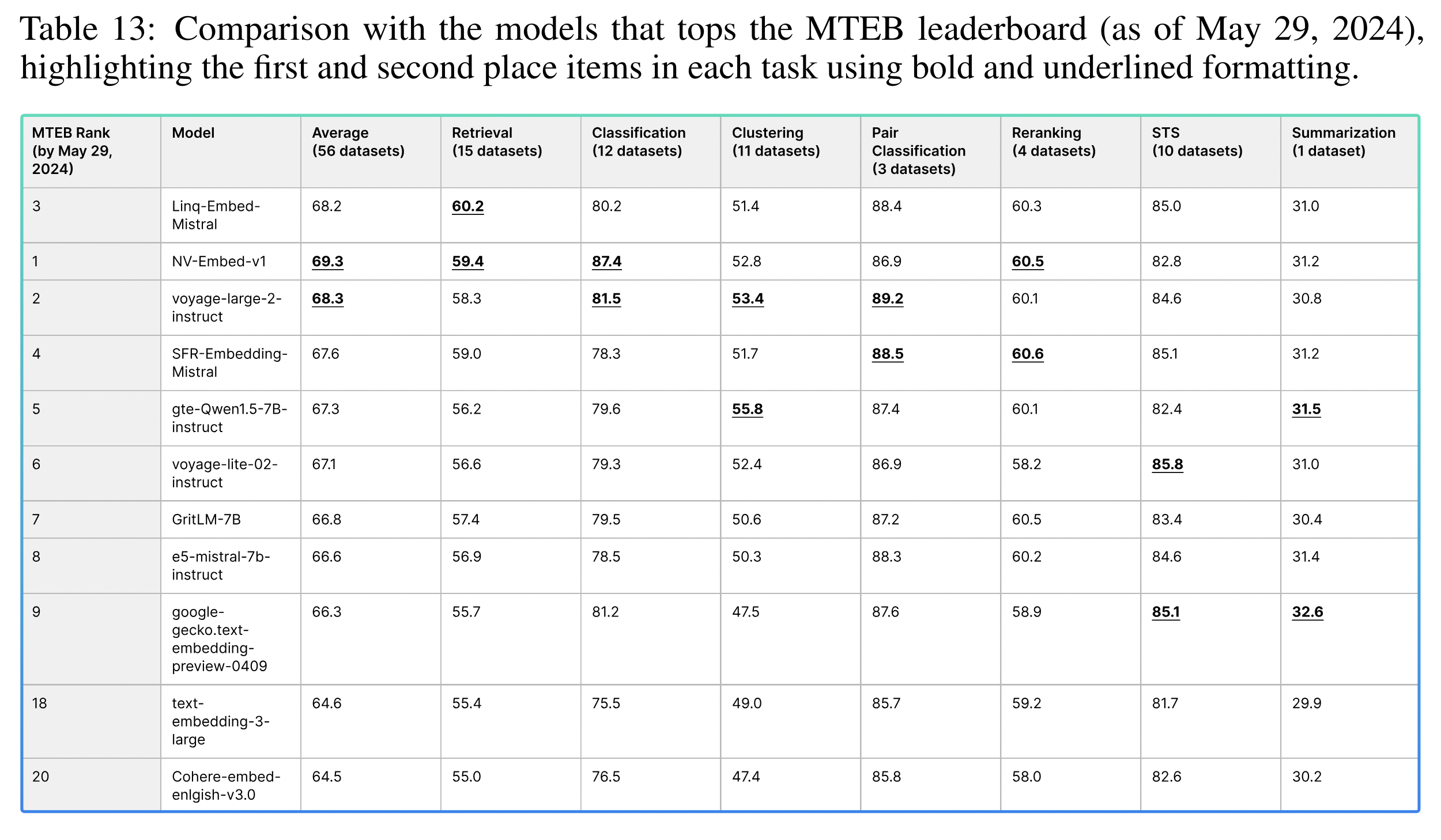
- Linq-Embed-Mistral은 MTEB 벤치마크에서 우수한 성과를 보여줍니다. 56개의 데이터셋을 대상으로 한 평균 점수는 68.2점으로, 이는 MTEB 리더보드에 공개된 모델 중 1위에 해당하며 전체적으로는 3위입니다.
- 이 모델은 검색 작업에서 상당한 성능 향상을 보여줍니다. 검색 작업에서 MTEB 리더보드에 기재된 모든 모델 중 1위를 차지하며, 성능 점수는 60.2점입니다.
- Mistral 모델 시리즈 내에서는, 기본 Mistral 아키텍처를 기반으로 한 일련의 모델 중 SFR이 MTEB 작업의 특별히 선별된 데이터셋을 추가함으로써 E5-Mistral의 성능을 향상시킵니다. 이에 반해, 우리의 접근 방식은 더 정교한 합성 데이터셋을 생성하고 통합하는 데만 중점을 두고 있습니다. 이로써 우리 모델의 점수는 E5-Mistral의 56.9에서 SFR의 59.0으로 올라가 60.2로 향상되었습니다.