최근 AI와 자연어 처리(NLP) 분야에서는 정보 검색과 생성 기술의 융합을 통해 더 정교하고 유용한 시스템을 개발하려는 노력이 계속되고 있습니다. 이와 관련하여 Google DeepMind는 Retrieval-Augmented Generation (RAG) 기술을 더욱 발전시키는 새로운 접근법을 제안하였습니다. RAG는 대형 언어 모델(LLM)과 외부 지식 소스를 결합하여 더 정확하고 최신의 답변을 제공하는 기술로, 최근에는 모델의 성능을 높이기 위해 다양한 개선 방안이 모색되고 있습니다.
이번 논문에서는 Speculative RAG를 소개합니다. 핵심적인 내용은 다음 네 가지로 정리할 수 있습니다.
-
두 개의 모델 사용: Speculative RAG는 두 가지 다른 언어 모델을 사용합니다. 하나는 더 큰 일반적인 모델(Generalist LM)이고, 다른 하나는 더 작고 전문화된 모델(Specialist LM)입니다.
-
초안 생성: 검색된 문서의 subset 대상으로 작은 전문 모델(Specialist LM)이 여러 개의 초안을 생성합니다. 생성된 초안은 Generalist LM의 input token을 줄이면서도 서로 다른 문서 집합을 기반으로 하기 때문에 다양한 관점을 제공할 수 있습니다. 이렇게 하면 긴 문맥에 대한 위치적 편향(position bias)을 줄이도록 돕습니다.
-
검증: 큰 일반 모델(Generalist LM)이 이 초안들을 한 번에 검토하여 가장 정확한 답변을 선택합니다. 이 과정은 더 효율적이고 빠르게 진행됩니다. (역할분담)
-
성능 개선: Speculative RAG는 TriviaQA, MuSiQue, PubHealth, ARC-Challenge와 같은 벤치마크에서 최신 기술보다 더 높은 정확도를 보이면서, 지연 시간을 51%까지 줄이는 성과를 기록했습니다. PubHealth에서는 정확도를 12.97%까지 향상시켰습니다.
Speculative RAG로 해결하고자 하는 주요 문제는 RAG 시스템의 효율성과 정확도를 개선하는 것입니다. 구체적으로, 다음과 같은 문제들을 해결하려고 합니다:
-
긴 문맥으로 인한 편향: 기존의 RAG 시스템은 긴 문맥을 처리할 때, 문서의 특정 부분에 편향될 수 있습니다. 이는 전체 문맥을 잘 이해하지 못하고, 결과적으로 부정확한 답변을 생성할 가능성이 있습니다. Speculative RAG는 여러 개의 짧은 초안을 생성하고 이를 종합함으로써 이러한 편향을 줄이려 합니다.
-
문서 집합의 다양성: 여러 개의 초안을 생성하여 다양한 문서 집합을 활용함으로써, 특정 문서 집합에 의존하지 않고 폭넓은 정보를 반영할 수 있습니다. 이는 문서 집합의 편향을 줄이고, 보다 균형 잡힌 정보 제공을 가능하게 합니다.
-
효율적인 처리: 대형 언어 모델(LLM)을 직접 사용하는 것은 계산 자원과 시간이 많이 소모됩니다. Speculative RAG는 작은 전문화된 모델(Specialist LM)을 사용하여 여러 초안을 동시에 생성하고, 큰 일반 모델(Generalist LM)을 사용하여 이를 검토함으로써 전체적인 처리 시간을 단축합니다.
-
정확도 향상: 기존 RAG 시스템은 문서 검색과 생성 과정에서 발생할 수 있는 다양한 오류를 수정하기 어려운 경우가 많습니다. Speculative RAG는 여러 관점에서 생성된 초안들을 검토하고 종합하여, 더 높은 정확도의 답변을 제공하는 것을 목표로 합니다.
Previous Works
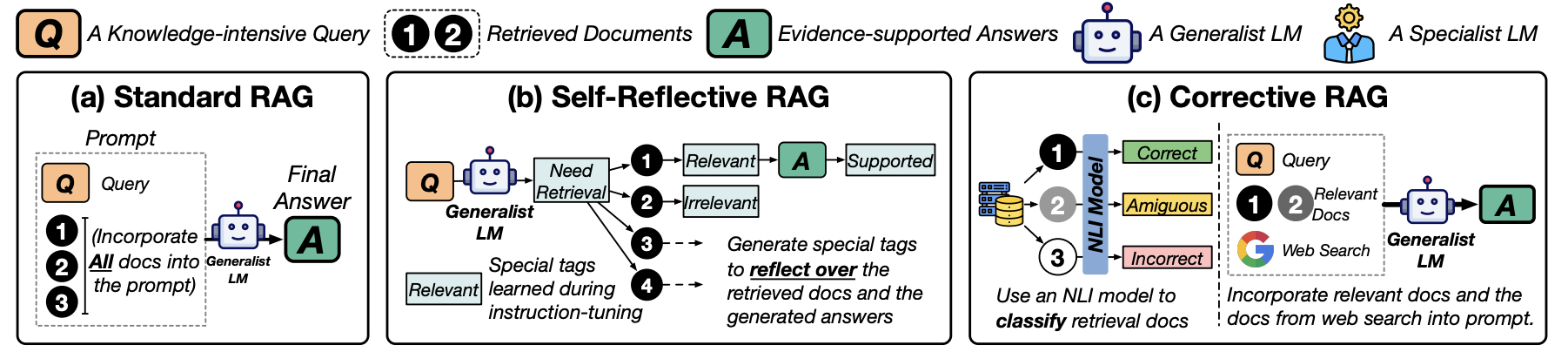 (a) Standard RAG : increasing input length, slowing inference 특징으로 합니다.
(a) Standard RAG : increasing input length, slowing inference 특징으로 합니다.
(b) Self-Reflective RAG : LLM special tags (Relavant, Irrelevant) 에 따른 Answer 생성합니다. 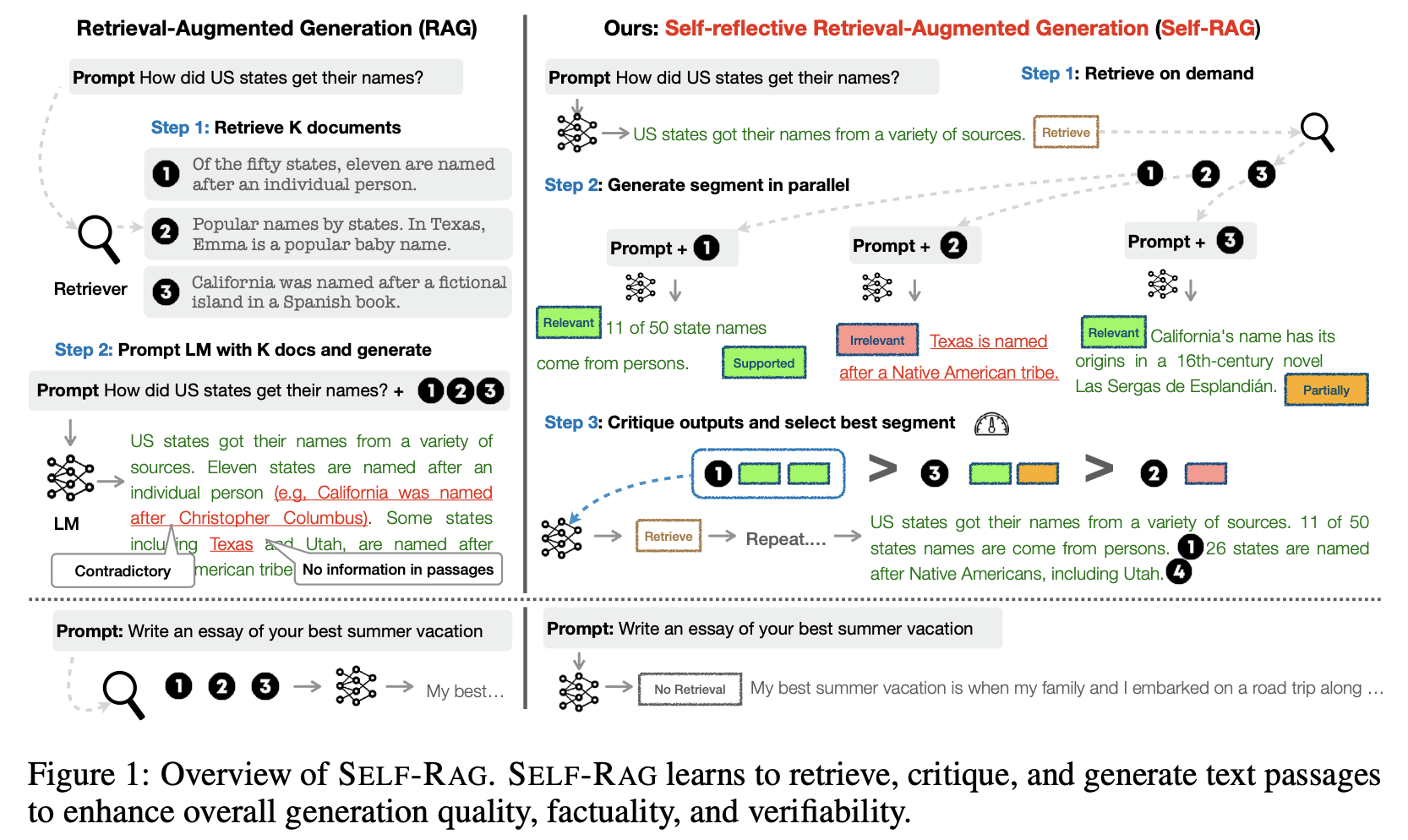
(c) Corrective RAG : classification을 통해서 LLM에 document (필요하다면 Web search까지) 전달합니다. https://velog.io/@hansoljang/Corrective-Retrieval-Augmented-Generation
Speculative Retrieval Augmented Generation through Drafting
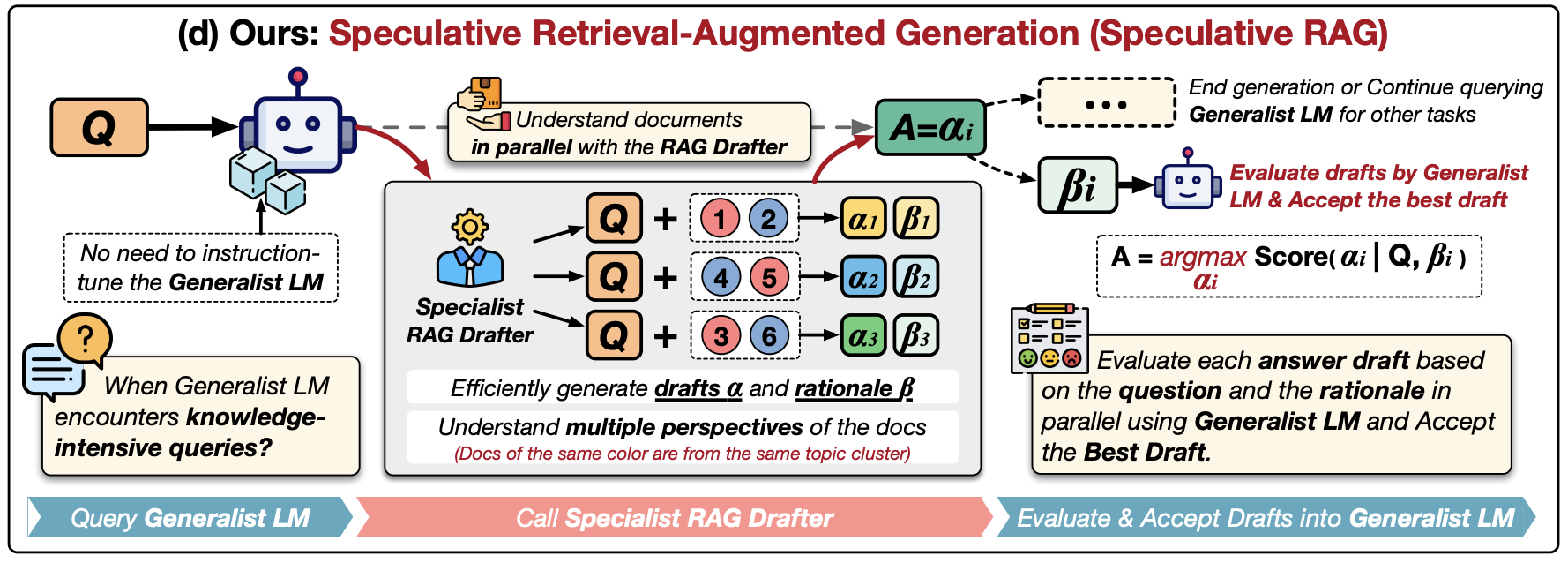
- A smaller specialist LM, the RAG drafter
Rapidly generate multiple answer drafts based on retrieved results - A larger generalist LM, the RAG verifier
- Assess these drafts
- Select the best one based one its rationale
- Integrate it into the generation results
Specialist RAG Drafter
Instruction tuning
Drafter를 훈련시켜 답변 초안과 근거를 모두 생성하도록 하여 맥락 문서를 더 잘 이해하도록 합니다. Instruction tuning 과정에서는 (Q, A, D) 세 쌍을 사용하는데, 여기서 Q는 일반 질의, A는 응답, D는 검색된 지원 문서입니다.
근거 E는 문서에서 핵심 정보를 추출하고 응답이 질의에 대해 합리적인 이유를 설명합니다. 이렇게 Instruction tun을 거친 모델은 전문적인 RAG Drafter로 활용됩니다. 이 모델은 주어진 질문과 관련 문서를 바탕으로, 논리적인 근거와 함께 타당한 답변을 생성하는 능력을 갖추게 됩니다.
Multi-Perspective Sampling
다양한 관점의 정보를 포함하는 답변을 생성하고 복잡한 질문에 대해 더 포괄적이고 균형 잡힌 답변을 제공할 수 있도록 an instruction-aware embedding model (Peng et al., 2024) 과 the K-Means clustering algorithm (Jin & Han, 2011)를 사용하였습니다.
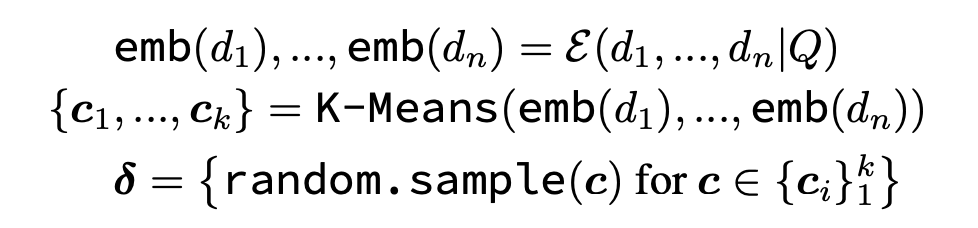
- E : an instruction-aware embedding model
- Q : the posed question
- n : the number of retrieved documents
- k : the number of clusterings
E 모델은 Q를 Instruction으로 삼아 임베딩을 생성합니다. 생성된 임베딩을 바탕으로 클러스터링을 수행하는데, 이는 쿼리가 모호할 때 다양한 내용을 모으고 문서의 반복을 줄이며 다양성을 높이기 위함입니다.
K-means clustering은 데이터를 k개의 그룹으로 나누는 알고리즘입니다. 먼저, 클러스터의 수 k를 설정하고 데이터 공간에서 임의로 k개의 초기 중심점을 선택합니다. 그 다음, 각 데이터 포인트를 가장 가까운 중심에 할당하여 클러스터를 형성합니다. 이후 각 클러스터의 중심을 해당 클러스터에 속한 데이터 포인트들의 평균 위치로 업데이트합니다. 이 과정을 중심점들이 더 이상 이동하지 않을 때까지 반복하여 안정된 클러스터를 형성합니다. 이 방법을 통해 데이터는 유사성을 기반으로 그룹화되며, 각 클러스터는 해당 그룹의 대표적 특성을 나타내는 중심점을 갖게 됩니다. 위 수식에서 {, ..., }: 클러스터링의 결과로, , , ..., 는 k개의 클러스터를 의미합니다.
이렇게 형성된 클러스터들에서 각 클러스터에서 하나의 문서를 샘플링하여 문서 하위 집합 δ를 구성합니다. 이 하위 집합 δ는 다양한 내용의 k개의 문서로 이루어져 있으며, 이를 통해 더 풍부한 정보와 다양한 관점을 확보할 수 있습니다. 최종적으로, 우리는 이러한 문서 하위 집합을 총 m개 구성합니다.
RAG Drafting
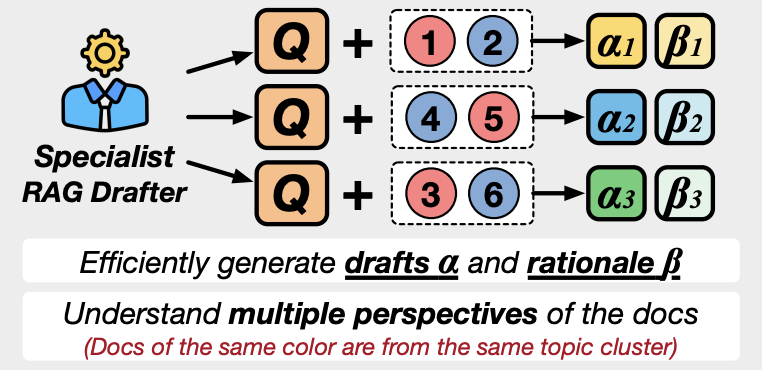
RAG Drafting 과정에서는 m개의 문서 하위 집합( = {, .., })에 대해 각각의 답변 초안(정답과 근거)을 생성합니다.
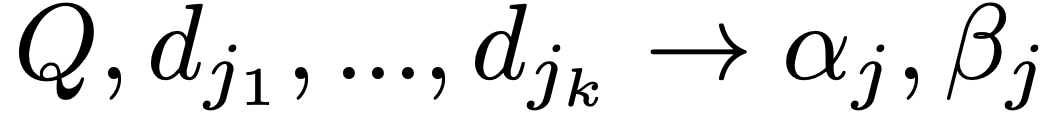
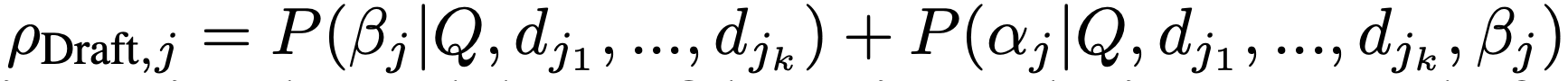
Generalist RAG Verifier
RAG drafter 가 생성한 초안과 근거를 평가하기 위해, 일반적인 언어 모델(LM)인 를 사용하여 가장 신뢰할 수 있는 초안-근거 쌍을 선택합니다. 신뢰도가 낮은 초안-근거 쌍을 필터링하고, 최상의 답변을 선택하여 초안-근거($$) 쌍을 선정합니다.
Evaluation Scores (within one forward pass)
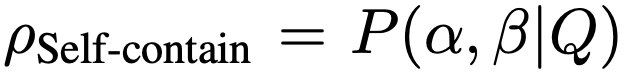

Self-consistency score는 초안과 근거가 질문의 요구사항이나 상황에 맞춰 초안과 근거가 관련성이 있는지를 평가합니다. 예를 들어, 질문이 특정 주제에 대한 설명을 요구하는데 초안과 근거가 그 주제와 관련이 없다면, 일관성이 부족하다고 평가될 수 있습니다.
Self-reflection score는 답변 초안의 신뢰성을 평가하는 데 중점을 둡니다. 이를 위해 “이 근거가 답변을 지원한다고 생각하십니까? 예 또는 아니오?”라는 Prompt를 사용하여, 근거가 실제로 초안을 효과적으로 뒷받침하는지 여부를 판단합니다. 이 점수는 초안과 근거 간의 적절한 연결성과 논리적 일관성을 확인하여, 최종 답변의 신뢰성을 높이는 데 도움을 줍니다.
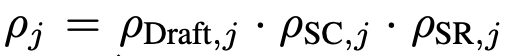
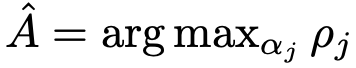

Experiments
훈련 데이터셋은 다양한 출처에서 수집된 인스턴스를 기반으로 구축됩니다. Open-Instruct processed data (Wang et al., 2023a)과 knowledge-intensive datasets (Petroni et al., 2021; Stelmakh et al., 2022; Mihaylov et al., 2018)에서 샘플링한 데이터를 사용하며, 각 데이터 쌍에 대해 최대 10개의 문서를 검색하고 Gemini-Ultra를 통해 근거를 생성합니다. 이 과정을 통해 총 40,000개의 데이터셋을 확보하였습니다.
RAG drafter에는 Mistral7B (v0.1)를 기본 언어 모델로 사용하며, Self-RAG와 CRAG의 성능을 Mistral7B (v0.1)로 재현하였습니다. 각 데이터에 대해 최대 10개의 문서를 검색하고, Gemini-Ultra를 사용하여 근거를 생성합니다. 이 과정에서 Contriever-MS MARCO를 사용하여 문서를 검색합니다.
Speculative RAG를 TriviaQA, MuSiQue, PubHealth, 그리고 ARC-Challenge 네 가지 공개 벤치마크에서 평가했습니다. TriviaQA와 MuSiQue는 Open-domain 질문 응답 데이터셋으로, 각각 단일 증거와 다중 문서 기반의 추론을 요구합니다. PubHealth는 다양한 생의학 주제를 다룬 의학적 주장을 검증하는 데이터셋이며, ARC-Challenge는 초중등 과학 시험 문제로 구성된 다중 선택 질문 데이터셋입니다. Open-domain 질문 응답에서는 생성된 응답에 정답이 포함되어 있는지를 평가하고, 주어진 선택지나 정해진 답변 집합 내에서 최적의 답변을 선택하는 방식에서는 생성된 답변의 정확도를 측정합니다.
TriviaQA, PubHealth, ARC-Challenge에서는 상위 10개의 문서를 검색하고, 각 쿼리에 대해 5개의 초안을 생성하며(각 초안은 2개의 문서 하위 집합을 기반으로 함), MuSiQue 데이터셋에서는 상위 15개의 문서를 검색하고 10개의 초안을 생성합니다(각 초안은 6개의 문서 하위 집합을 기반으로 함).
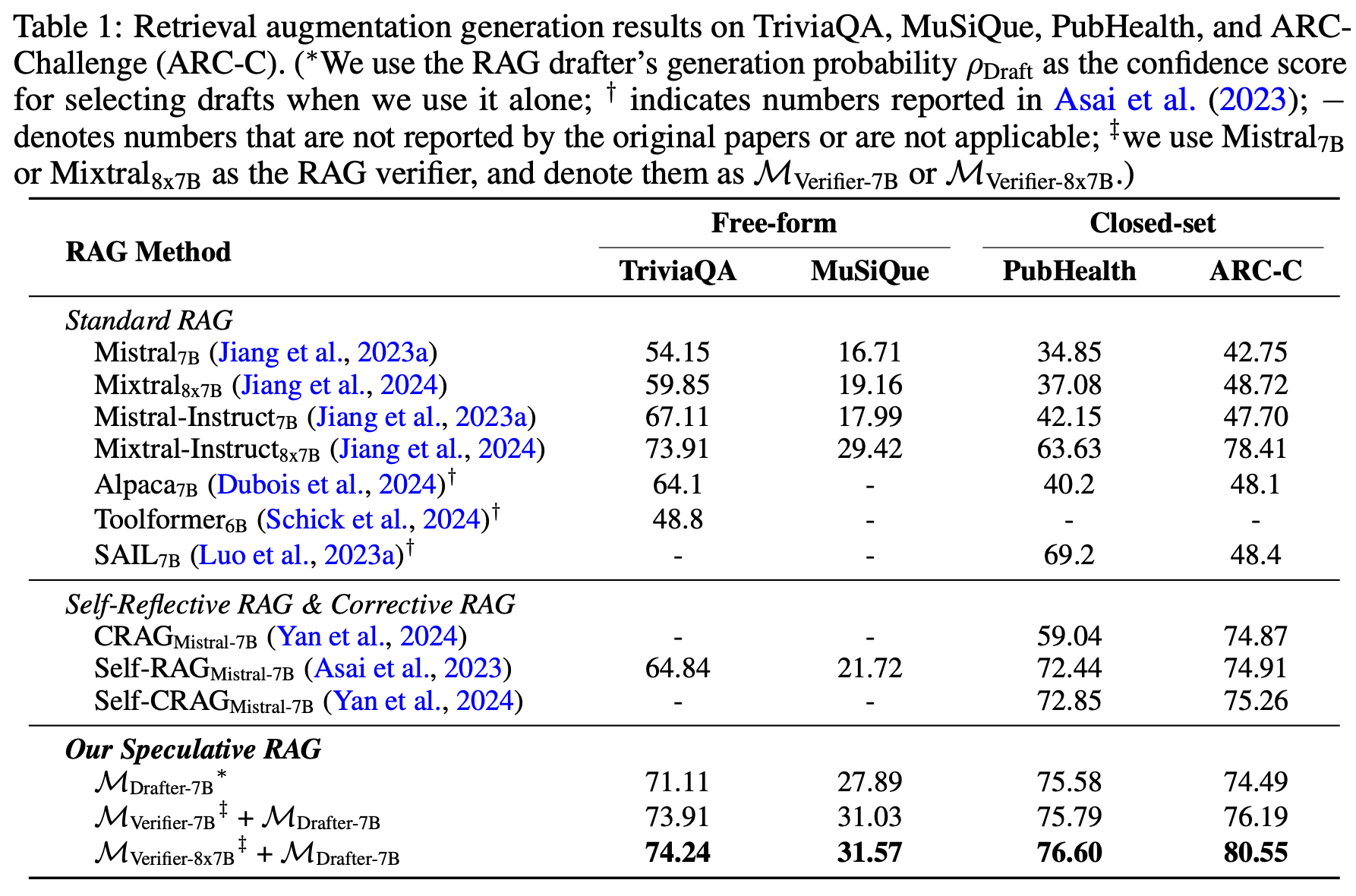
MVerifier-8x7B와 MDrafter-7B 조합은 standard RAG model인 Mixtral-Instruct8x7B를 TriviaQA에서 0.33%, MuSiQue에서 2.15%, PubHealth에서 12.97%, ARC-Challenge에서 2.14% 초과 성과를 보입니다. 또한 Self-Reflective, Corrective RAG과 비교했을 때에도 MDrafter-7B 만으로도 보다 좋은 성능을 보입니다.
Mistral7B와 Mixtral8x7B를 비교했을 때 TriviaQA에서 14.39%, MuSiQue에서 12.41%, PubHealth에서 39.52%, ARC-Challenge에서 31.83% 성능 향상을, Mistral7B와 비교했을 때 각각 19.76%, 14.32%, 40.94%, 33.44%의 성능 향상이 관찰되었습니다. 이 점은 샘플링된 문서에서 중복을 최소화함으로써, RAG drafter는 검색 결과에서 다양한 관점을 바탕으로 더 높은 품질의 답변 초안을 생성한다고 이해할 수 있습니다.
MDrafter-7B와 MVerifier-7B + MDrafter-7B를 비교할 때, 성능이 현저히 개선되는 것을 확인할 수 있습니다. MVerifier-7B 성능만으로도 Verification을 통한 정답 생성이 성능향상에 유의미함을 볼 수 있습니다.
Latency Analysis
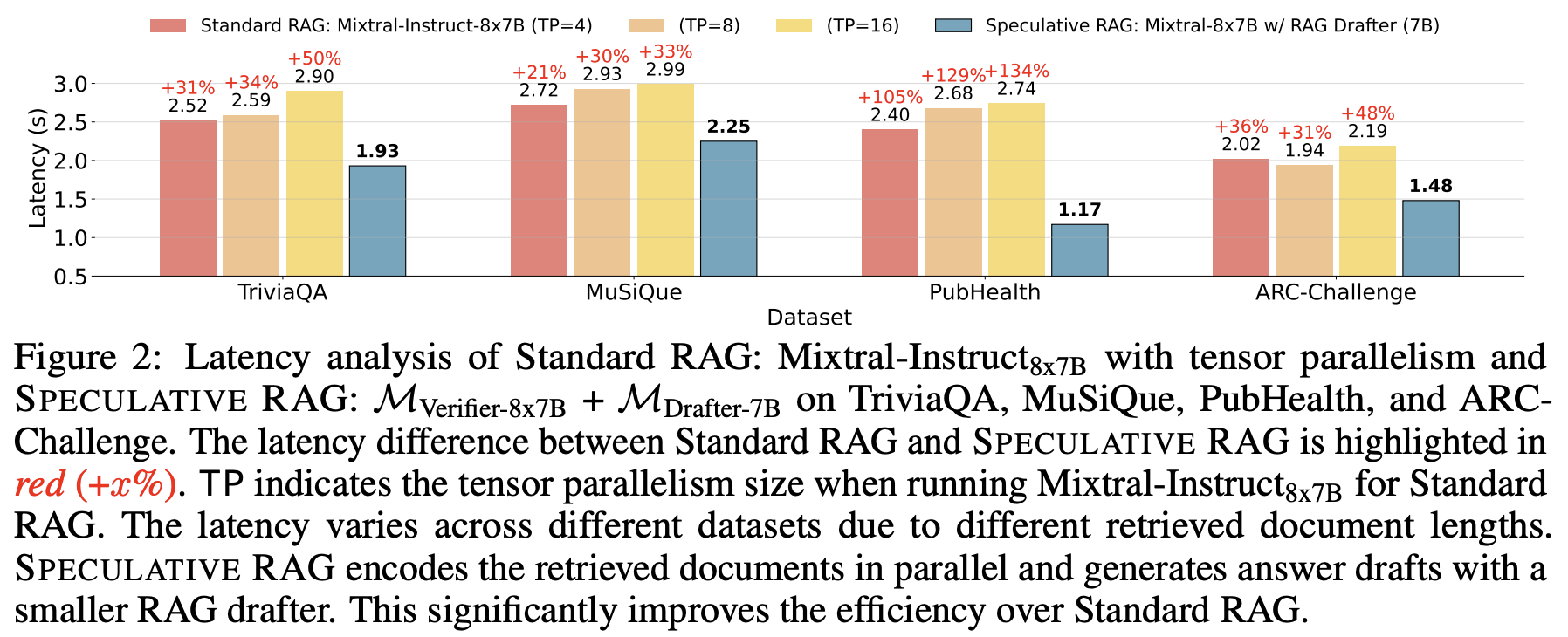
각 데이터셋에서 무작위로 100개의 사례를 샘플링하였으며 Speculative RAG의 경우 MVerifier-8x7B와 MDrafter-7B를, Standard RAG의 경우 Mixtral-Instruct8x7B를 사용하여 성능을 비교했습니다.
Speculative RAG는 모든 데이터셋에서 일관되게 가장 낮은 지연 시간을 기록했습니다. 특히, TriviaQA에서는 23.41%, MuSiQue에서는 17.28%, PubHealth에서는 51.25%, ARC-Challenge에서는 26.73%까지 지연 시간을 줄였습니다.
Ablation Studies
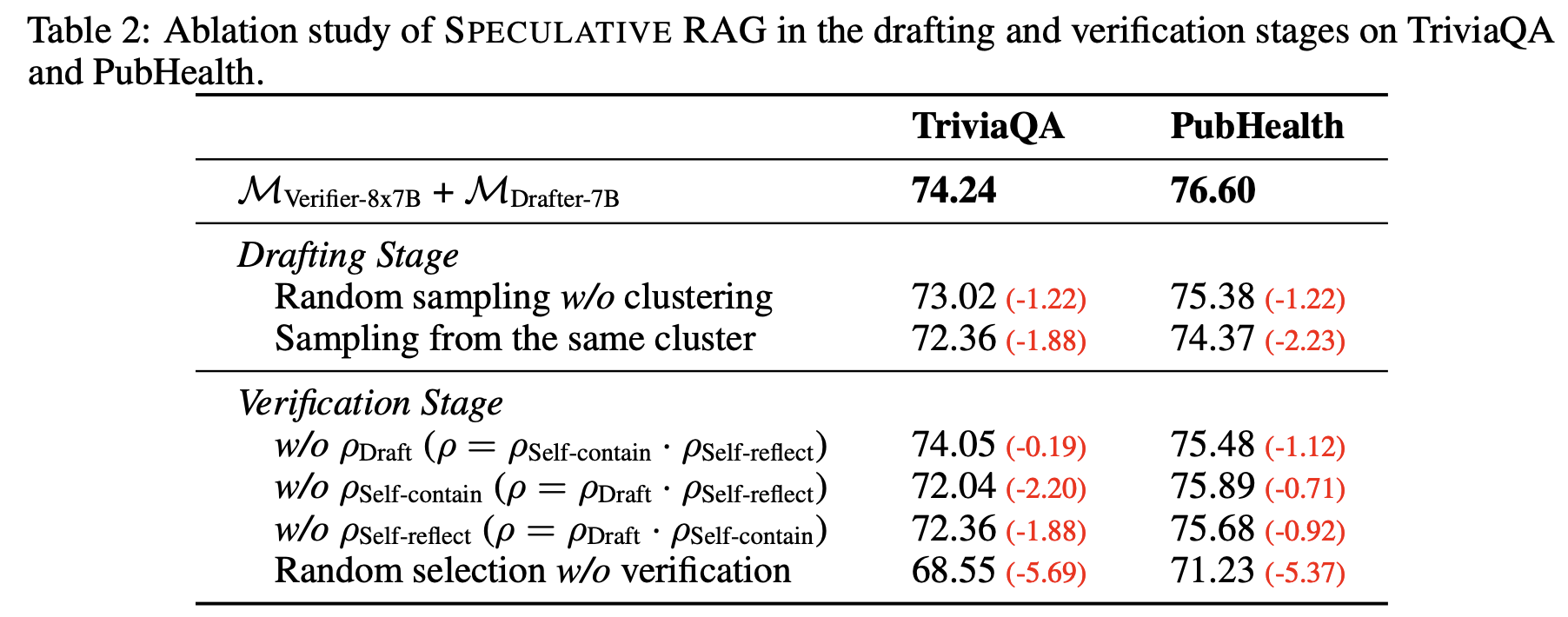
- Impact of multi-perspective sampling
- 클러스터링을 진행하지 않았을 때에 성능이 저하되는 것을 확인할 수 있습니다.
- 동일한 클러스터에서 샘플링을 수행하면 다양한 관점의 부족으로 인해 성능이 현저히 저하되는 것으로 나타났습니다.
- Scoring method during verification
- ρDraft 제거: ρDraft를 제거하면 TriviaQA에서 0.19%, PubHealth에서 1.12%의 성능 감소가 발생합니다. 이는 작은 RAG drafter의 제한된 검증 능력 때문일 수 있습니다.
- ρSelf-contain 또는 ρSelf-reflect 제거: ρSelf-contain 또는 ρSelf-reflect를 제거하면 TriviaQA에서 약 2.0%, PubHealth에서 약 0.8%의 성능 저하가 나타납니다. 이는 두 스코어가 서로 다른 중요한 추론 측면을 포착하며 검증에 필수적임을 나타냅니다.
- 무작위 선택의 문제: Verification 없이 무작위로 선택할 경우, TriviaQA에서 5.69%, PubHealth에서 5.37%의 성능 저하가 발생하여 검증의 중요성을 강조합니다.

- Effects of Generated Rationale
- 생성된 근거의 역할: Speculative RAG에서는 RAG drafter가 생성한 근거 β를 답변 초안 α의 신뢰성을 판단하는 지표로 사용합니다. 이 근거는 관련된 포인트를 강조하고, 중복된 정보를 생략하며, 초안과 지원 문서 간의 논리적 간격을 메웁니다.
- 근거 대신 검색된 문서 사용: ρ = Score(α|Q, δ)로 대체, 근거에 검색된 문서 추가: ρ = Score(α|Q, β, δ)로 추가하여 Accuracy, Latency 측정했을 때 더 긴 검색된 문서를 포함하는 것이 항상 성능을 향상시키지는 않으며, 지연 시간이 증가하는 경향이 있습니다. 이 점은 생성된 근거가 이미 높은 품질을 가지고 있으며, 지원 문서와 생성된 답변 초안 간의 효과적인 다리 역할을 한다는 것을 시사합니다.
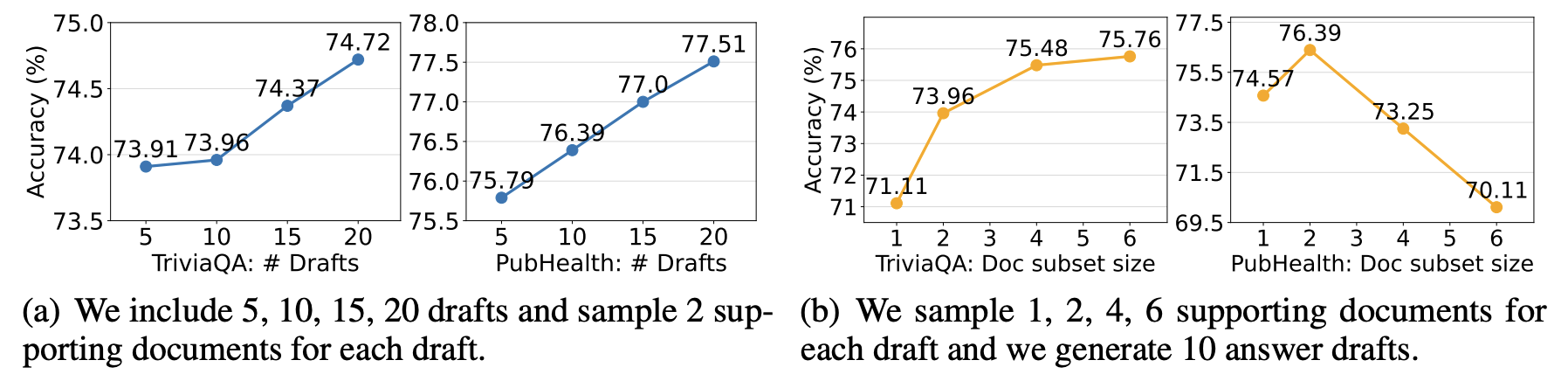
- Effects of Draft Number and Document Subset Size
- 초안 수를 늘리면 성능이 개선되는 경향이 있음을 보였습니다. 이는 다양한 관점을 더 넓게 다룰 수 있기 때문입니다.
- 초안 생성을 위해 샘플링하는 문서의 수를 1, 2, 4, 또는 6개로 변화시켜 그 영향을 평가했습니다. 문서 수를 늘리는 것이 항상 성능 개선으로 이어지지는 않았습니다. (TriviaQA의 경우, 복잡성으로 인해 더 많은 지원 문서가 도움이 될 수 있습니다.)
