XLNet에서 해결하고자 한 BERT의 문제점 : BERT pretraining 과정에서 사용하는 MASK 토큰이 finetuning 할 때에는 쓰이지 않는다.
(MLM leverages bidirectional context of masked tokens efficiently, but ignores the dependency among the masked (and to be predicted) tokens)
- 이 문제를 permuted language modeling (PLM)으로 해결하고자 했다.
XLNet 발생하는 또 다른 문제점 : pretraining 진행 시, 전체 위치 정보를 사용하지 않는다는 점에서 position discrepancy가 생기는 문제를 가진다.
- MPNet은 위 두 모델의 장점을 취하고 한계를 보완하는 방식의 pretraining 기법을 제안한다. (160GB 데이터셋으로 pretraining을 진행하였다. )
XLNet 이해하기 : https://ratsgo.github.io/natural%20language%20processing/2019/09/11/xlnet/
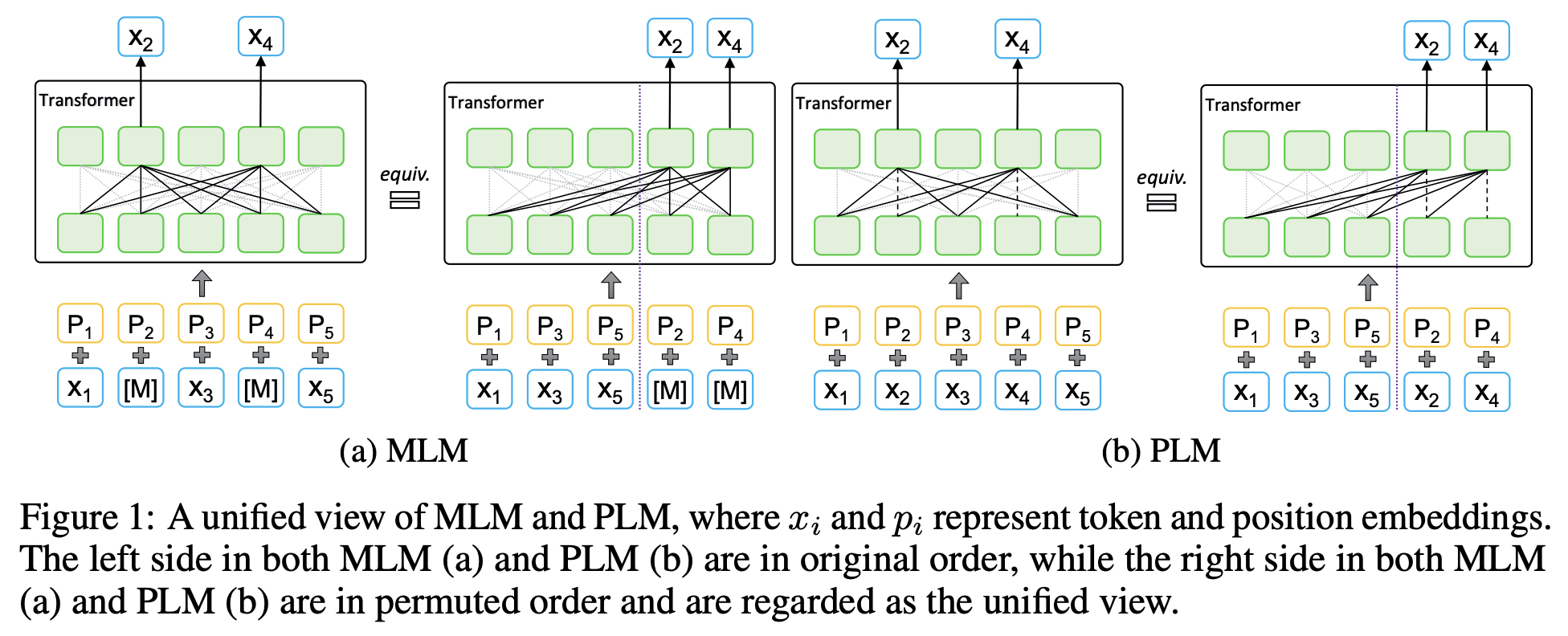
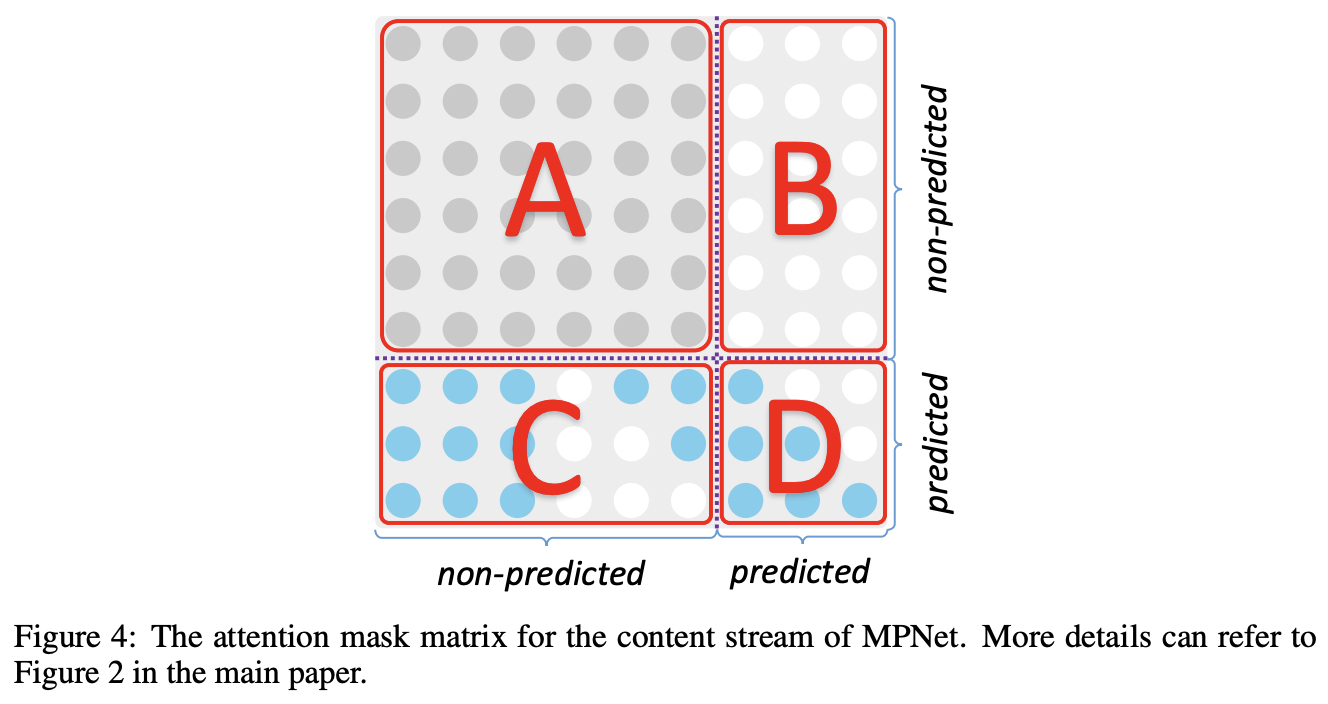
A Unified View of MLM and PLM
- rearranges and splits the tokens into non-predicted and predicted parts
- the non-masked tokens are put on the left side while the masked and to be predicted tokens are on the right side of the permuted sequence for both MLM and PLM.
MPNet
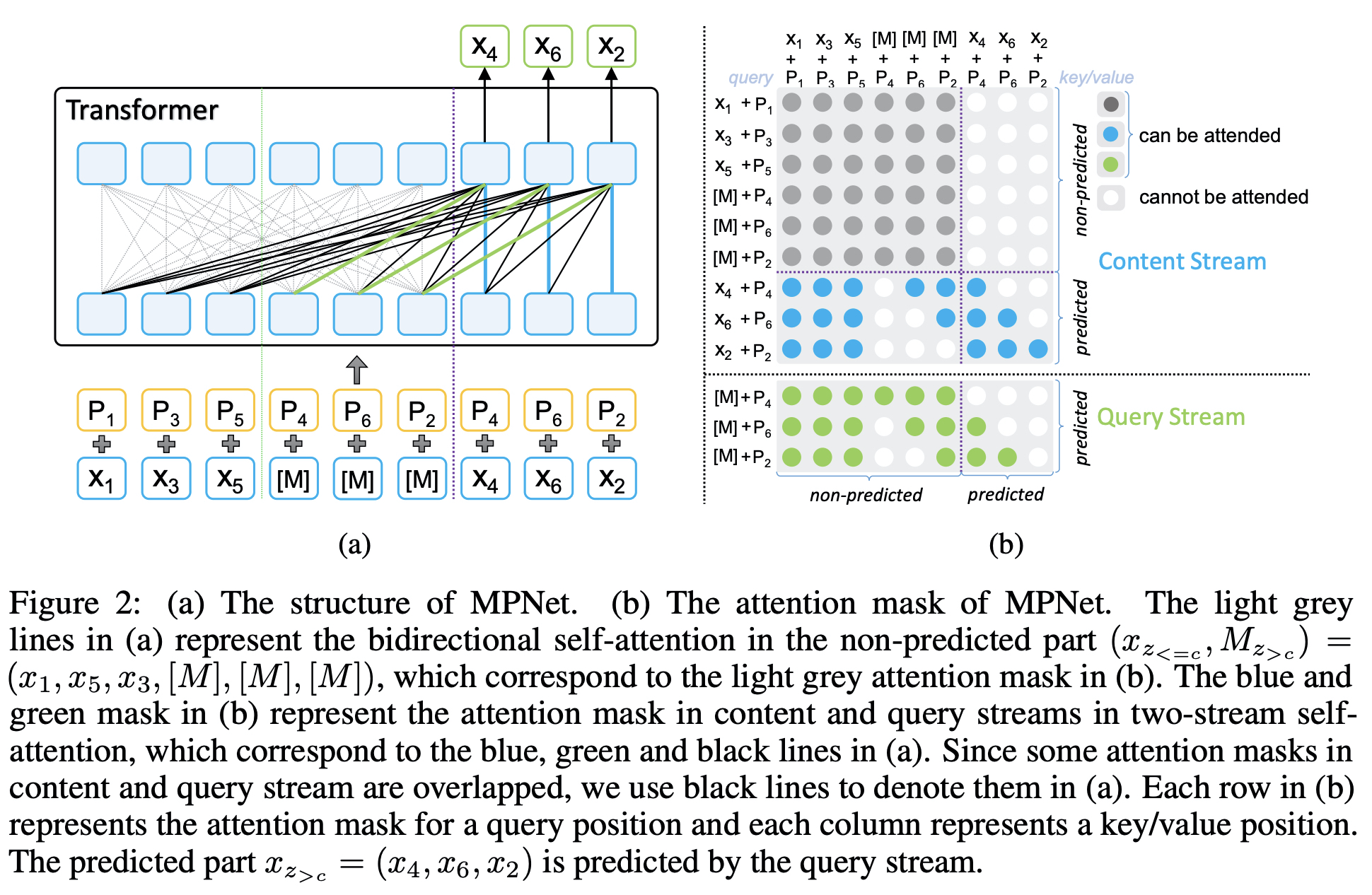
- For a token sequence x = (x1, x2, · · · , x6) with length n = 6, we randomly permute the sequence and get a permuted order z = (1, 3, 5, 4, 6, 2) and a permuted sequence xz = (x1, x3, x5, x4, x6, x2)
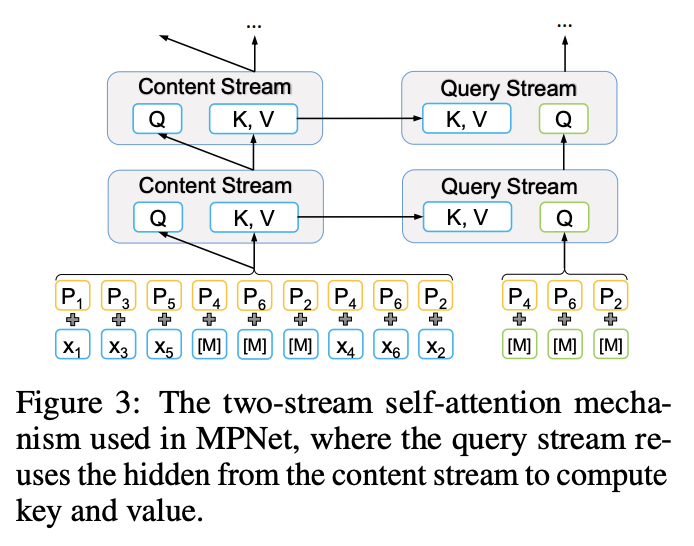
- Position compensation
Results
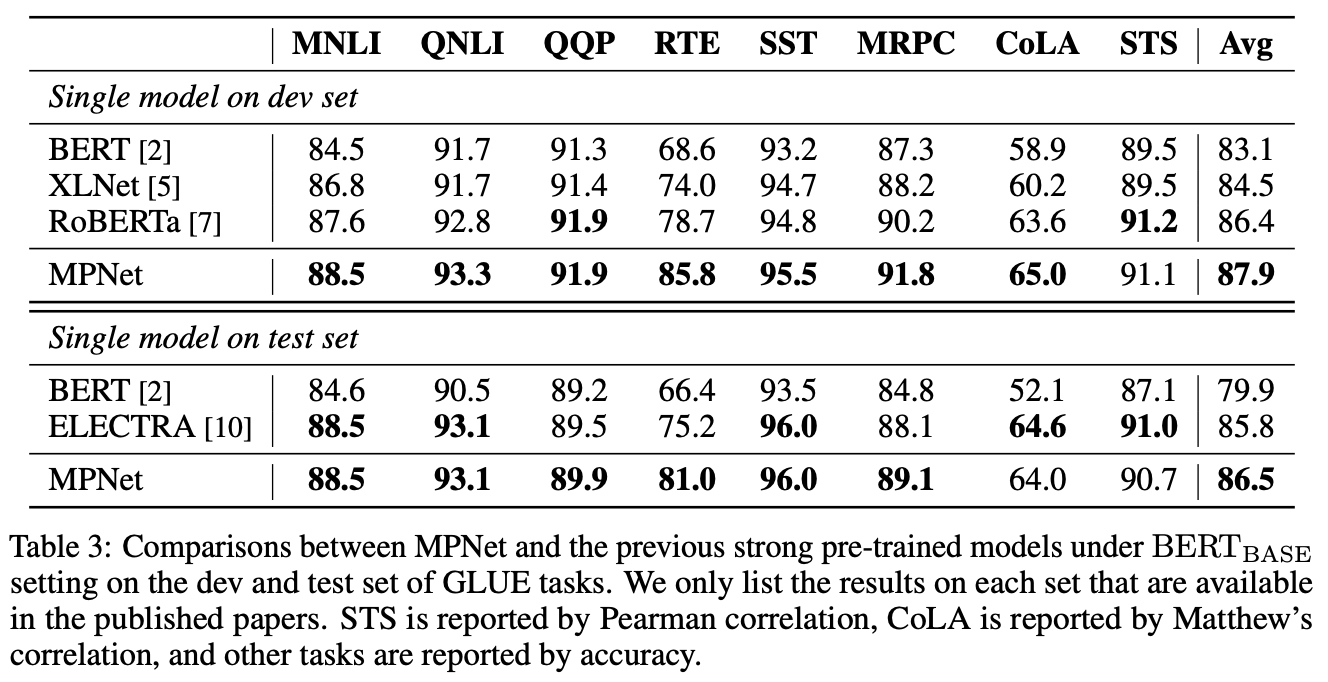
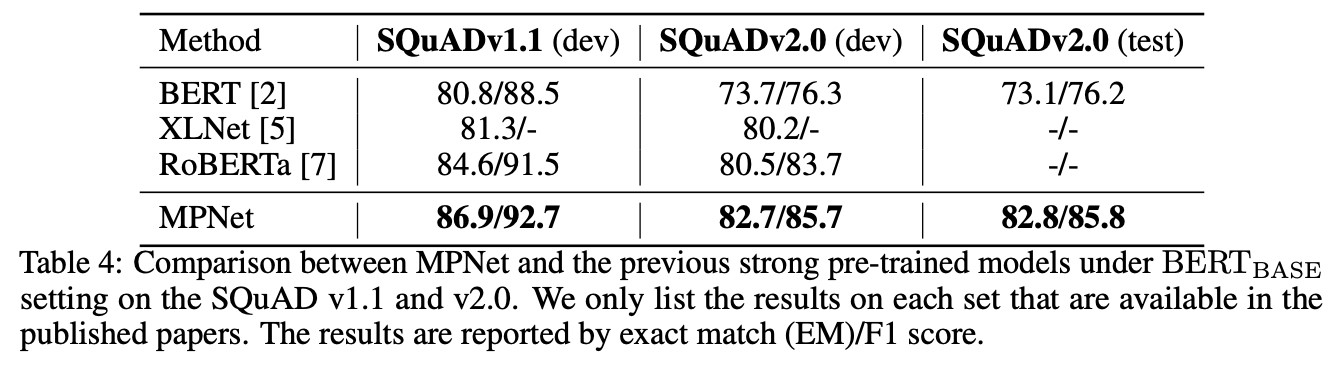
- GLUE
- SQuAD
Analysis
-
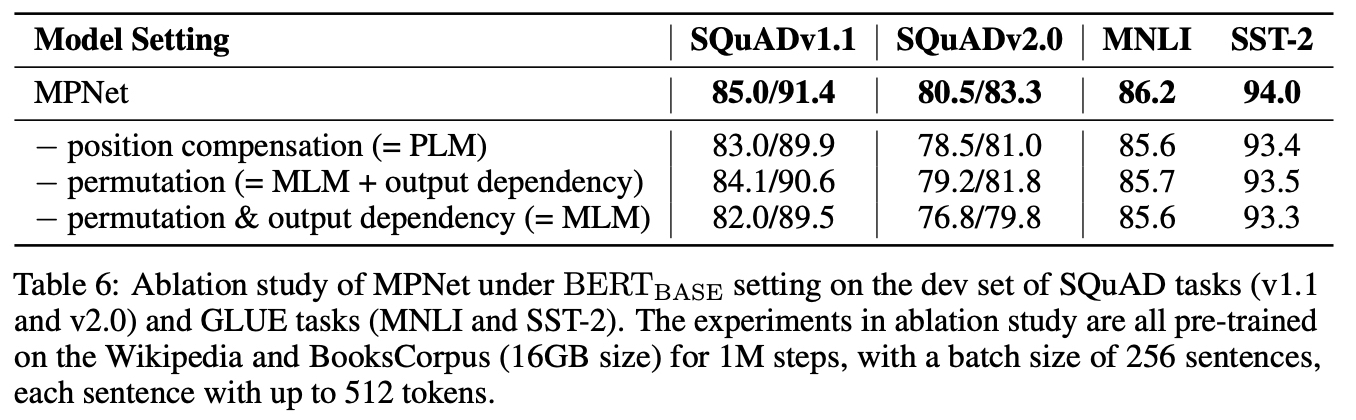
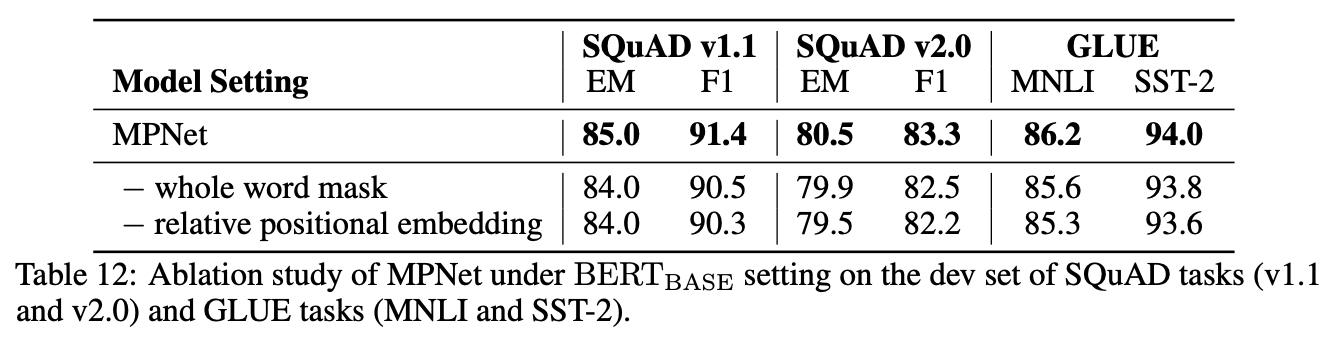
Abalation
-
Training Efficiency
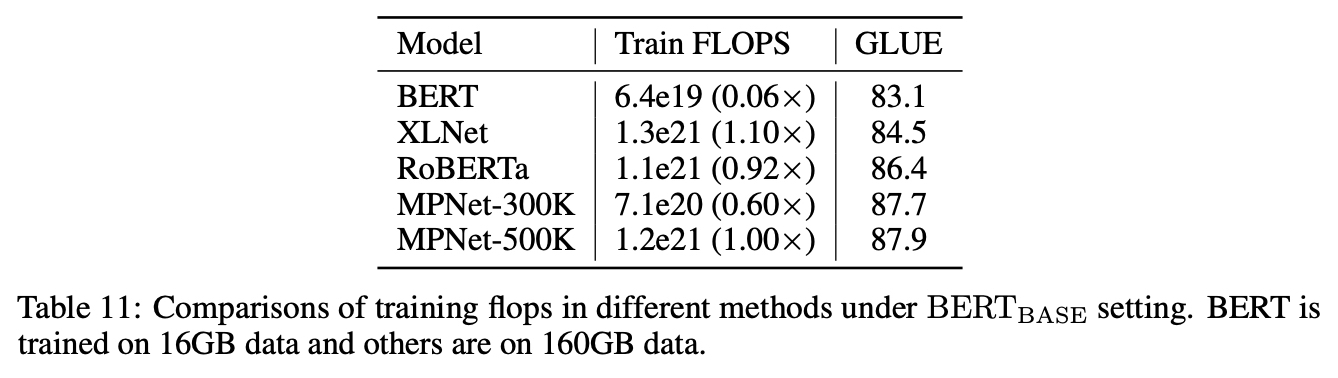
- Training Speedup

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻