NORMFORMER : Improved Transformer pretraining with extra normalization
Under review at ICLR 2022
Facebook AI Research
(문제) Pre-LayerNorm Transformer : gradients at early layers are much larger than at later layers.
(해결) Three normalization operations
- Head-wise scaling of self-attention outputs
- A Layer Norm after self attention
- A Layer Norm after the first fully connected layer
Previous work
일반적인 트랜스포머 구조에서는 post normalization 방법을 사용한다.
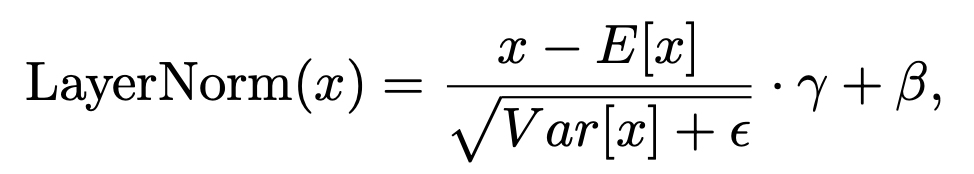

Xiong et al.(2020)에서는 이런 구조가 뒷 레이어들에 더 큰 그래디언트를 준다는 것을 밝혔다.
(앞 레이어들은 비교적 작은 그래디언트를 가지게 됌)
이런 점에서 제안한 것이 Pre-LayerNorm 이다.
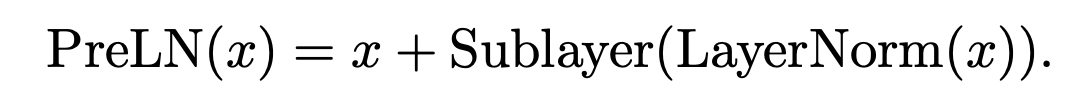
이렇게 layer normalization을 앞에서 시행함으로써
- 더 큰 러닝레이트
- warmup 을 줄여도
성능이 좋아졌다.
Pre-LN 의 안정성이 Post-LN 보다는 올라갔다고 할 수 있지만,
부작용처럼 앞에 레이어의 그래디언트가 뒷 레이어들의 그래디언트보다 더 커지는 현상이 발견되었다.
이 논문에서는 현상을 밝히고, 세 가지 normalization 사용으로 그래디언트가 모든 레이어에서 크게 변화하지 않도록 하여 성능을 향상시키는 것을 보여줄 것이다.
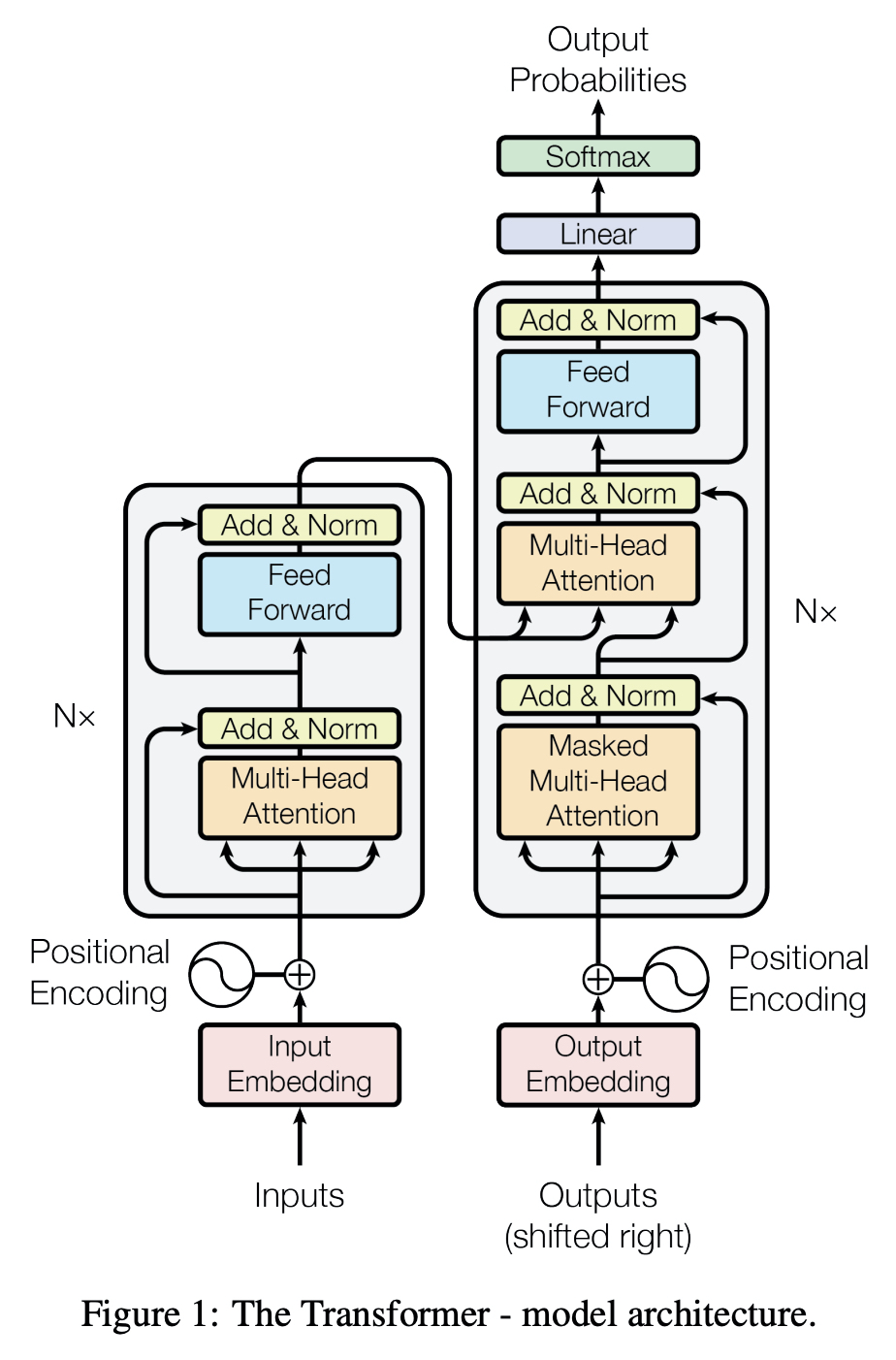
Attention is all you need 페이퍼에 있는 트랜스포머 모델의 구조도이다.
이 구조도를 보면, Multi-head attention과 feed forward 뒤에 add&Norm 으로 layer normalization이 그 뒤에 붙어있는 것을 확인할 수 있다.
Pre-LN의 경우 아래 그림과 같이 residual connection을 두고 앞에 layer normalization이 나와있다. 먼저 수행을 하고, 그 뒤 연산들을 하는 구조로 되어있다. 그 뒤에 붙은 Feed forward도 마찬가지이다.
이 논문에서 제시하는 모델은 NormFormer인데, 이 모델을 보면 Pre-LN처럼 Multi-head attention 연산 전과 Feed forward 전에 layer normalization이 수행되는 것은 같지만
- Multi head attention scaling
- Post attn layernorm
- FFN layernorm 이 추가되었다는 점이 다르다.
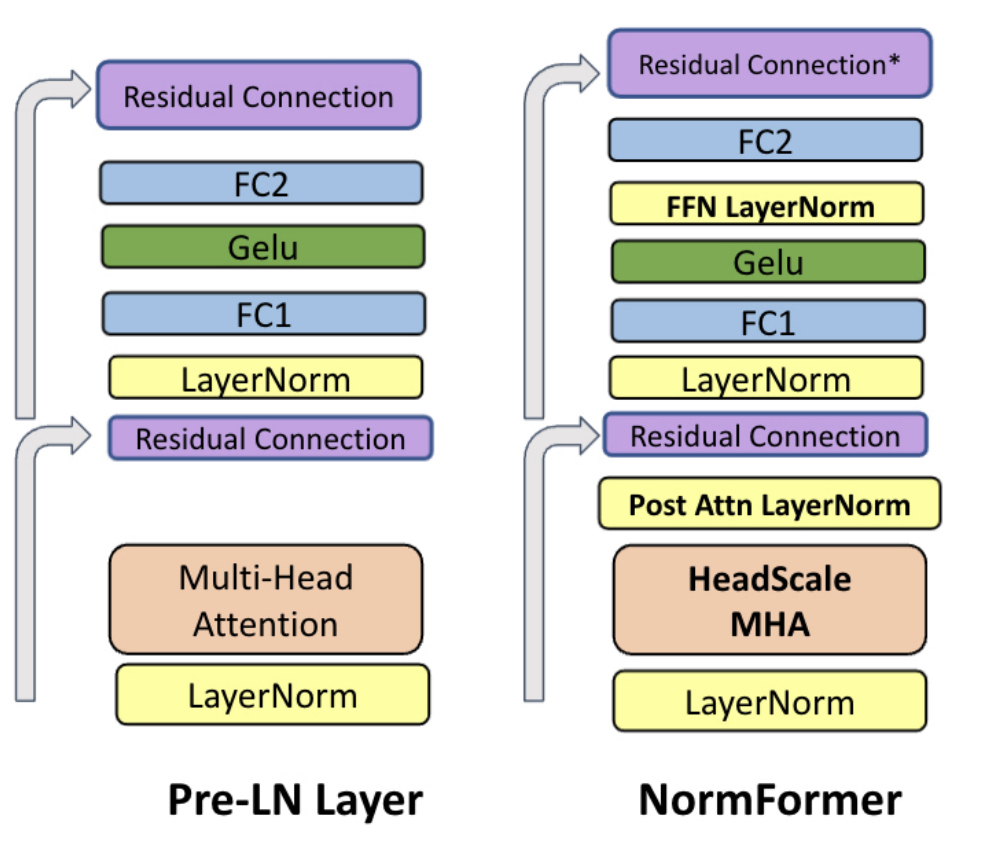
NORMFORMER
Scaling Attention Heads
트랜스포머의 Multi head attention은 다음과 같은 수식으로 계산된다.
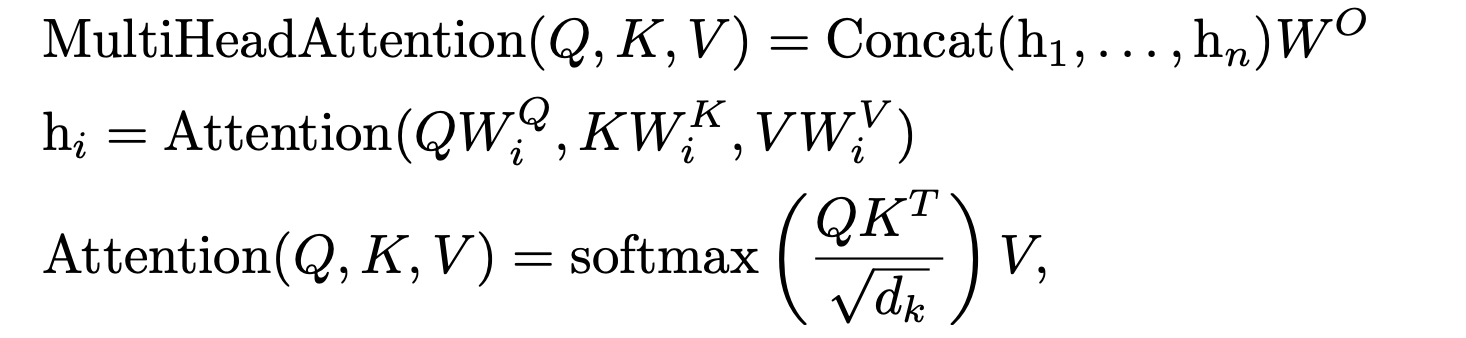
이 논문에서 제안하는 NormFormer는 이 부분을 스케일링하는데, coefficients 스칼라값을 각각 곱해서 head에 따라 다른 가중치를 준다. 이 값은 1로 초기화되어 학습된다.
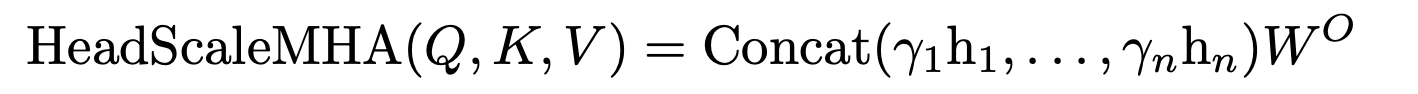
Additional Layer Normalization and Putting it All Together
볼드체의 Layer normalization이 추가되었다.
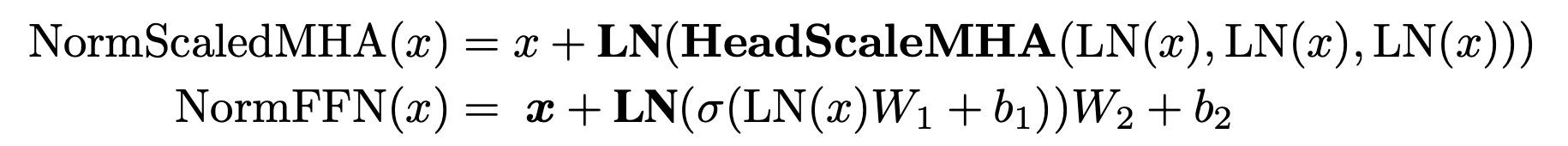
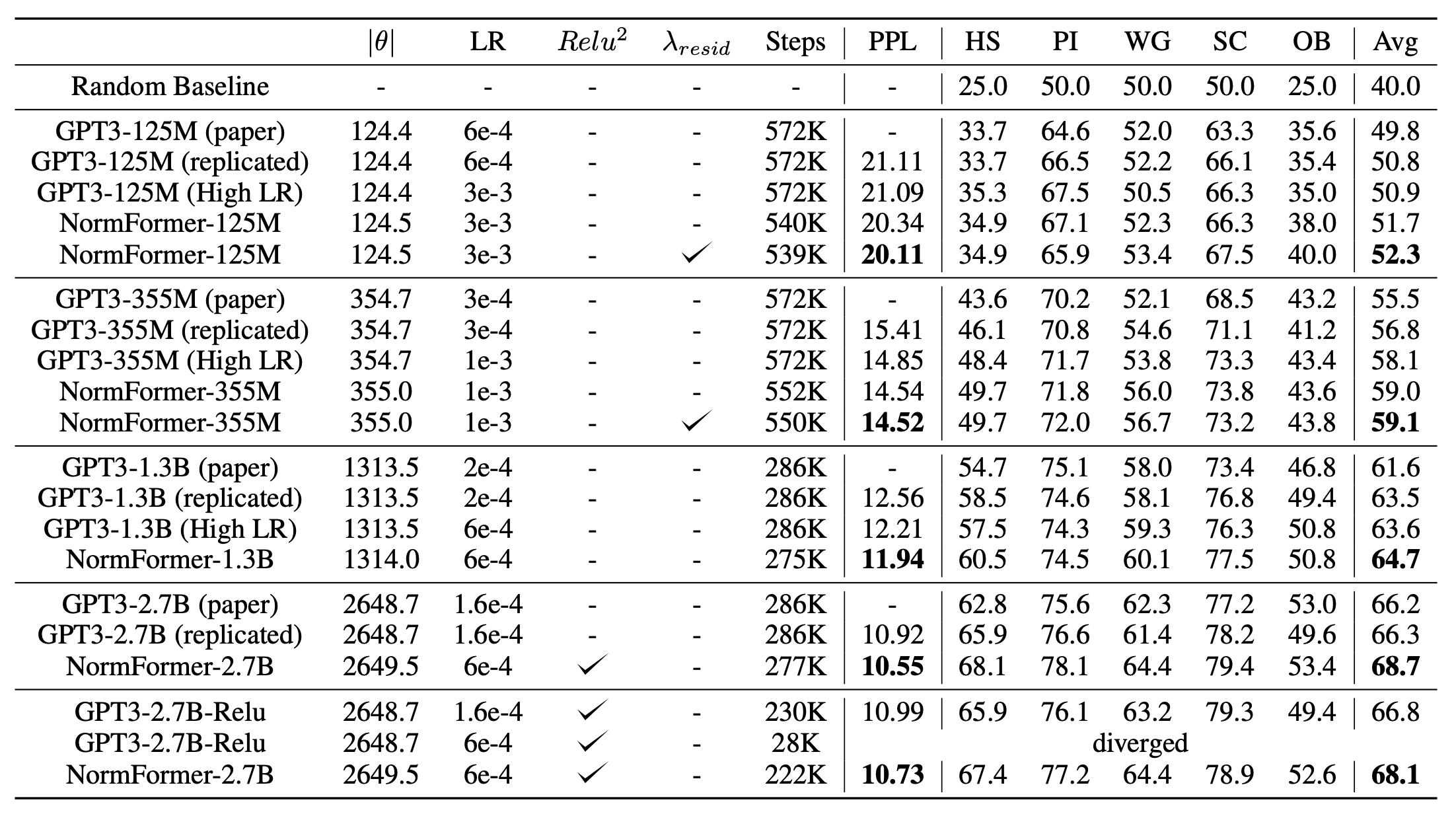
Experiments : CLM
결과표를 보면, 모델 사이즈별로 실험을 진행했는데 전부 다 NormFormer가 더 낮은 PPL, 더 좋은 성능을 가졌음 을 알 수 있다. (다섯 개의 실험은 Zeroshot 실험으로 진행되었다.)
- WinoGrande (Sakaguchi et al., 2020), StoryCloze (Mostafazadeh et al., 2016), OpenBookQA (Mihaylov et al., 2018), HellaSwag (Zellers et al., 2019) and PIQA (Bisk et al., 2020)
Learning rate
이 논문에서는 기존 GPT3 에서 사용한 러닝레이트가 너무 작다는 점도 지적하는데, 그래서 더 큰 러닝레이트로도 학습한 결과를 같이 담고 있다.
실험에 사용한 러닝레이트는 {1e−4, 6e−4, 3e−4, 6e−4, 1e−3, 3e−3}이며, GPT3 모델에서도 사용할 수 있는 좀 더 큰 러닝레이트의 경우 실험결과를 같이 올려두었다. GPT3의 경우 러닝레이크가 커져 발산하기도 했는데, NormFormer에서는 좀 더 큰 러닝레이트를 사용하더라도 Normalization을 워낙 잘 해서 더 큰 러닝레이트로도 안정적으로 학습이 된다고 말하고 있다.
Residual scaling
Residual lambda가 들어간 것이 가장 작은 두 모델에 있어서는 더 좋은 성능을 가졌다고 보이는데, 이 방법은 Residual scaling으로 이전 연구(Zhu et al., 2021; Liu et al., 2020)에서 Post-LN을 안정화시키기 위해서 사용했던 방법이다. 람다 값은 1로 초기화되어 학습된다.
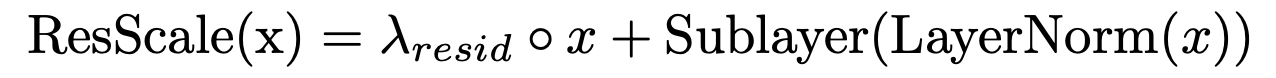
다만 모델이 커질수록 이 방법을 사용했을 때에 성능이 더 좋지 않았다고 한다. (1.3B 이상)
Large scale experiments
GELU를 사용해서 기존실험을 진행했고, 로도 실험을 진행했다.
Parameters
125M 실험에서 기존 768 차원의 벡터들을 780차원으로 변경하면 127M로 파라미터가 늘어나고, PPL이 0.08 낮아져 좋아지지만, Normformer의 경우 100,000개의 파라미터가 더 생기고 0.83 차로 모델이 좋아진다.
Experiments : MLM
RoBERTa 기준으로 실험을 진행하였다. (GPT2 기준의 vocab 형태를 가짐)
CC100, Book 코퍼스, 위키피디아, 처리된 Common Crawl 데이터로 학습을 했다.
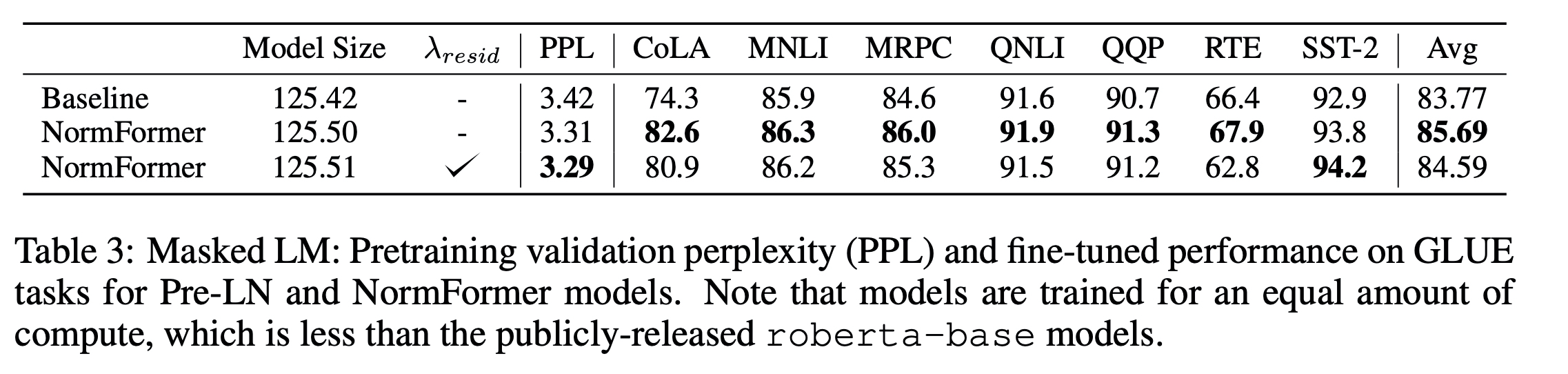
Residual scaling을 한 것이 PPL이 점수를 살짝 낮춰서 더 결과가 좋지만, finetuning 결과까지 감안한다면 그렇게 성능을 올린다고 보기는 어렵다.
Analysis
Training faster
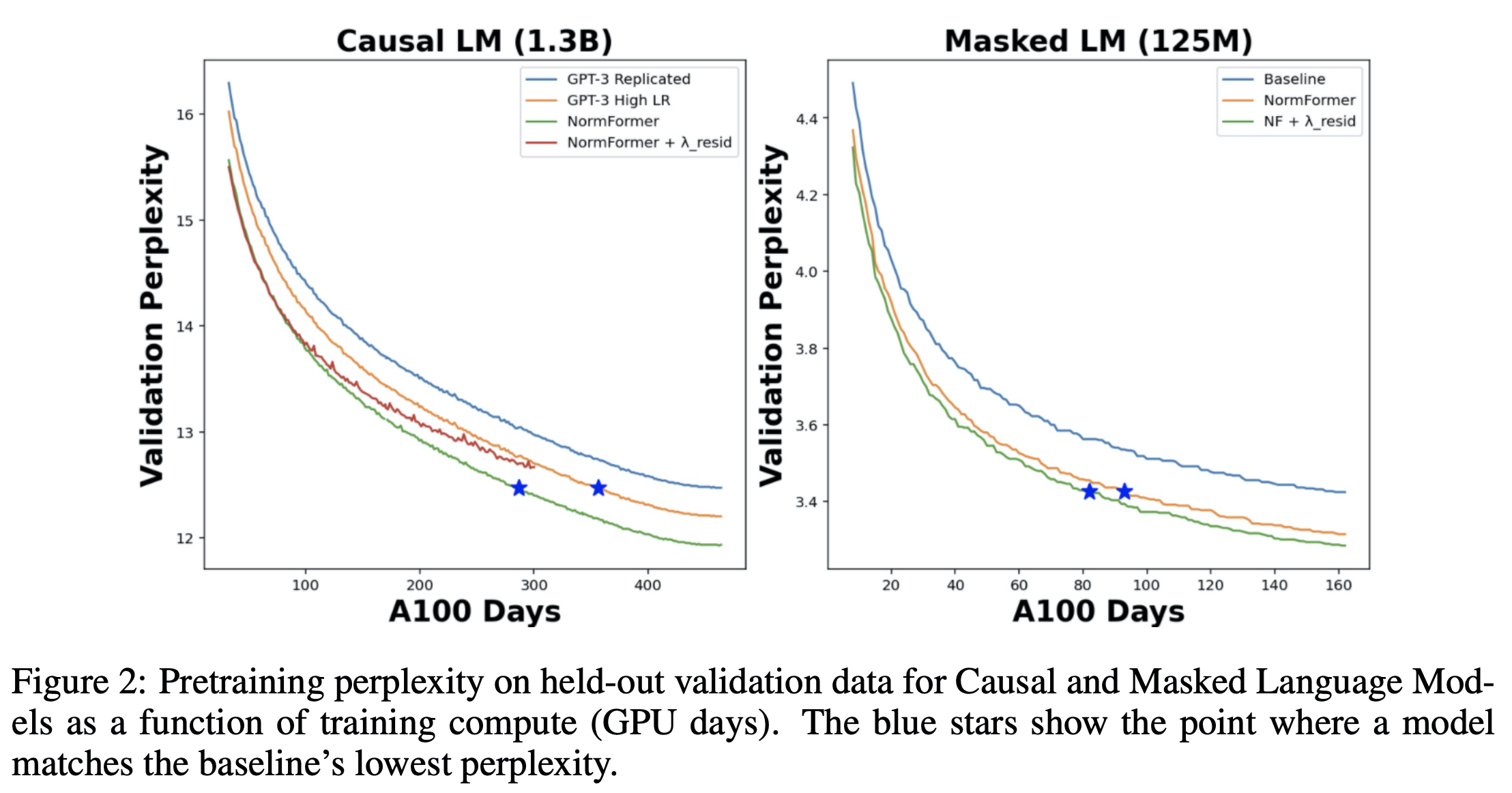
파란색 라인의 GPT3의 PPL을 Normformer를 적용한 경우에 더 빠르게 달성했음을 볼 수 있다.
Gradients
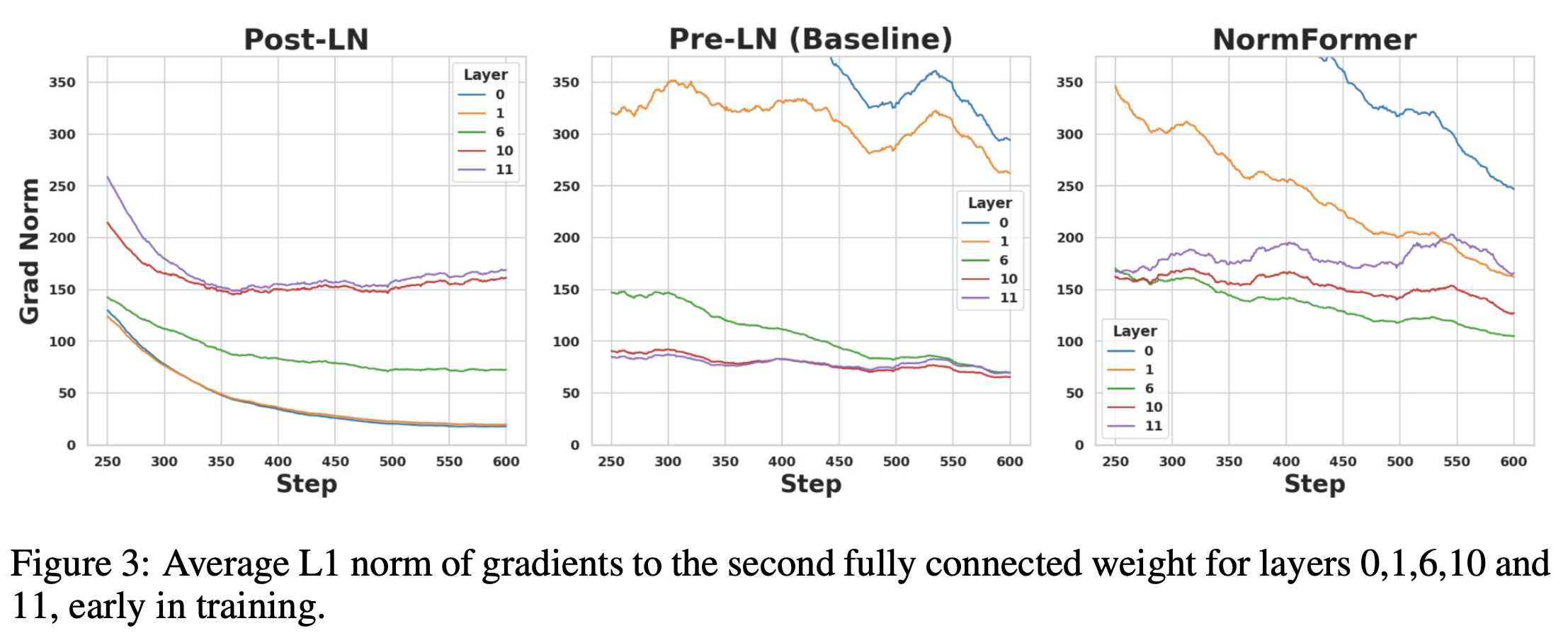
그래디언트들의 L1 norm 평균값을 보면,
Post-LN의 경우 뒤 레이어의 값들이 더 큰 수를 가지는 경향을 확인할 수 있다. 학습이 진행되면서 앞 레이어의 그래디언트값은 작은 값들로 계속해서 떨어진다.
Pre-LN은 그 반대의 모습을 보이는데,
NormFormer는 위엣 것은 내려오고, 아래 있던 수치들은 올라가서 그 간격이 줄어들었다는 것을 눈으로 확인할 수 있다.
Scaling
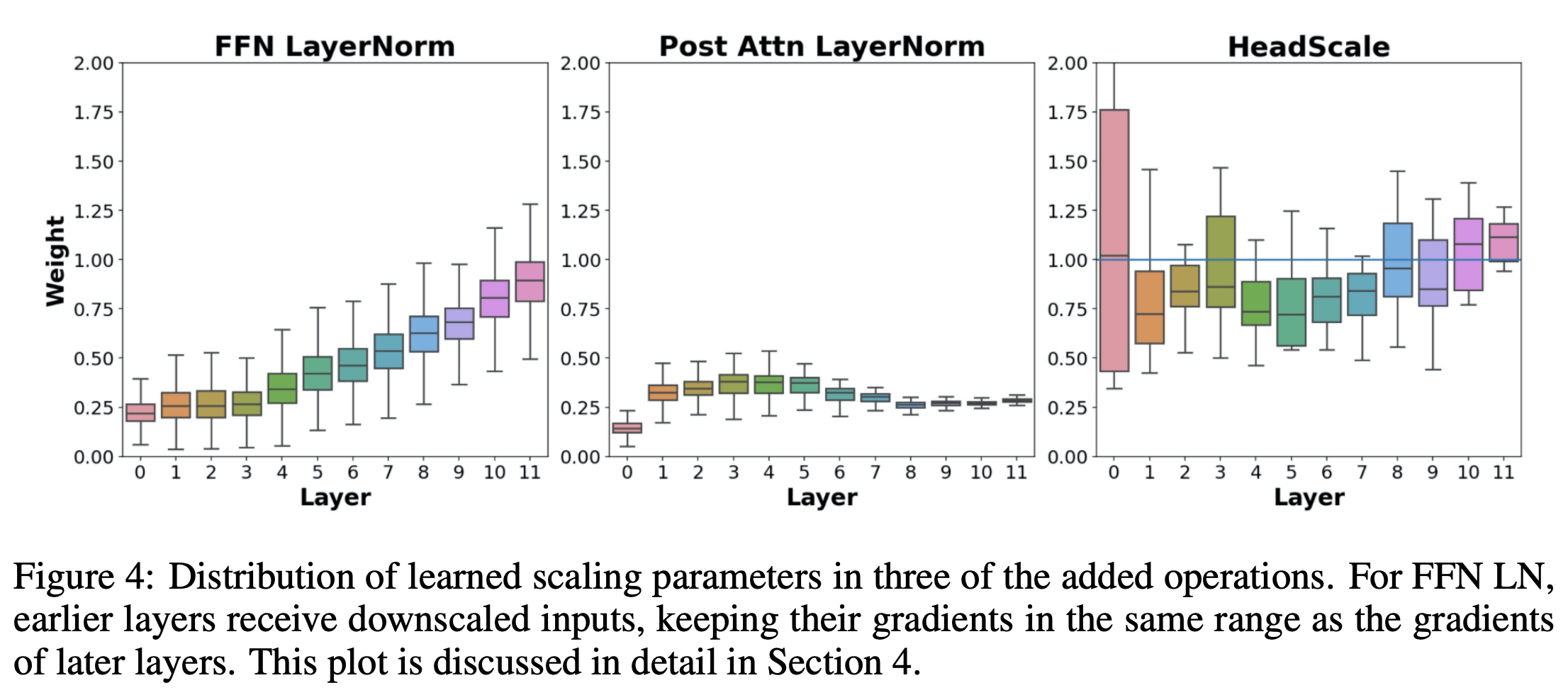
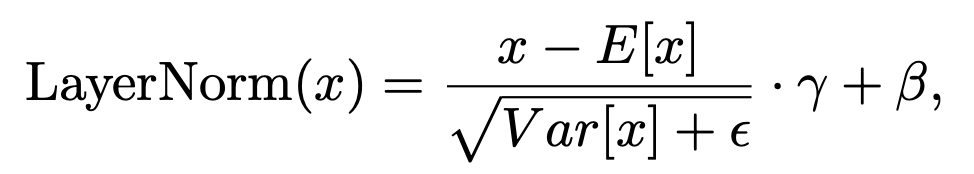
FFN에 대해서는 앞 쪽 레이어를 많이 줄여주고 있고(뒤 레이어 값들보다 크기 때문), Post Attn에서는 전체적으로 downscaling을 하고 있음을 알 수 있다.
가장 오른쪽 그래프는 위 수식의 coefficient에 해당하는 값의 분포이다. variation이 비교적 큰 것을 보면, 더 잘 초기화된 head에게 가중치는 준다고 보인다.
Residual scaling
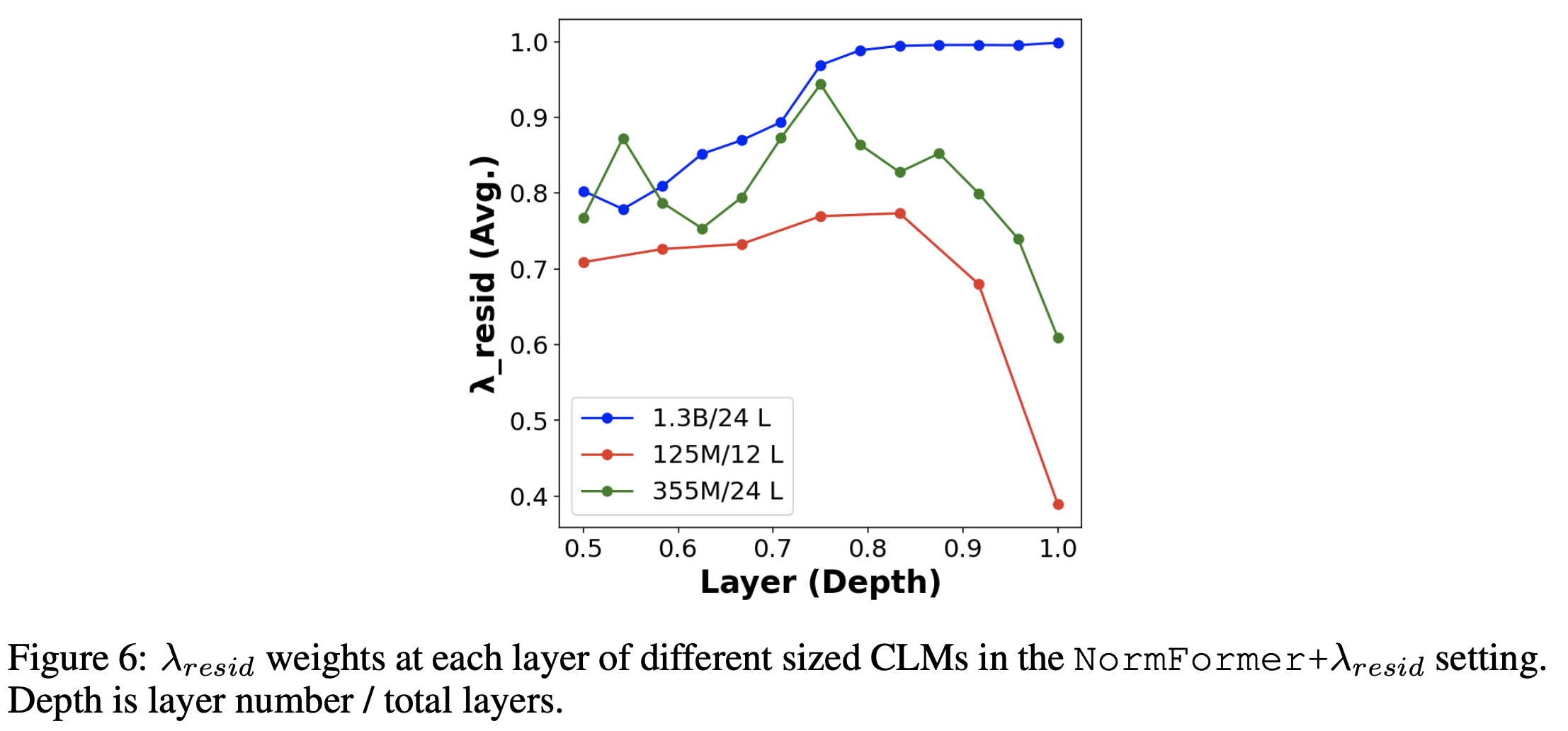
오른쪽 끝으로 갈수록 수치가 확 떨어지는건 레이어가 올라갈수록 residual을 덜하게 한다는 것을 의미한다.
Abalations
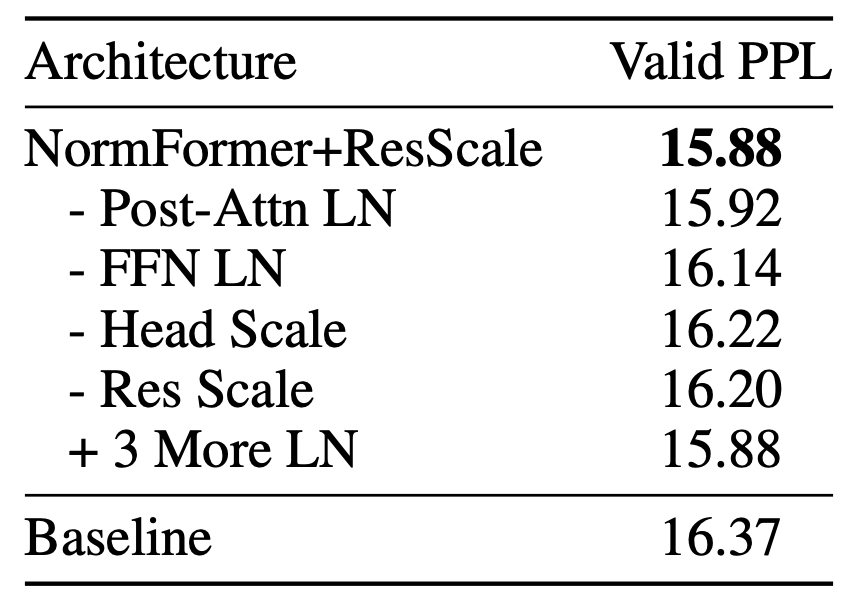
이 표에서는 가장 점수차가 크게 나는 Head Scale이 NormFormer에서 사용하는 세 가지 방법 중 가장 효과적인 방법임을 보여주었다.
