Rerank 관련, google 에서 공개한 논문이다.
- query-document 대한 ranking score 를 준다.
- “pairwise(positive 1개, negative 1개 씩의 로스계산)” or “listwise(positive 1개, negative 여러개로의 로스계산)” ranking losses 사용한다. (pairwise가 negative 딱 하나만 가지고 학습하는 것은 아님)
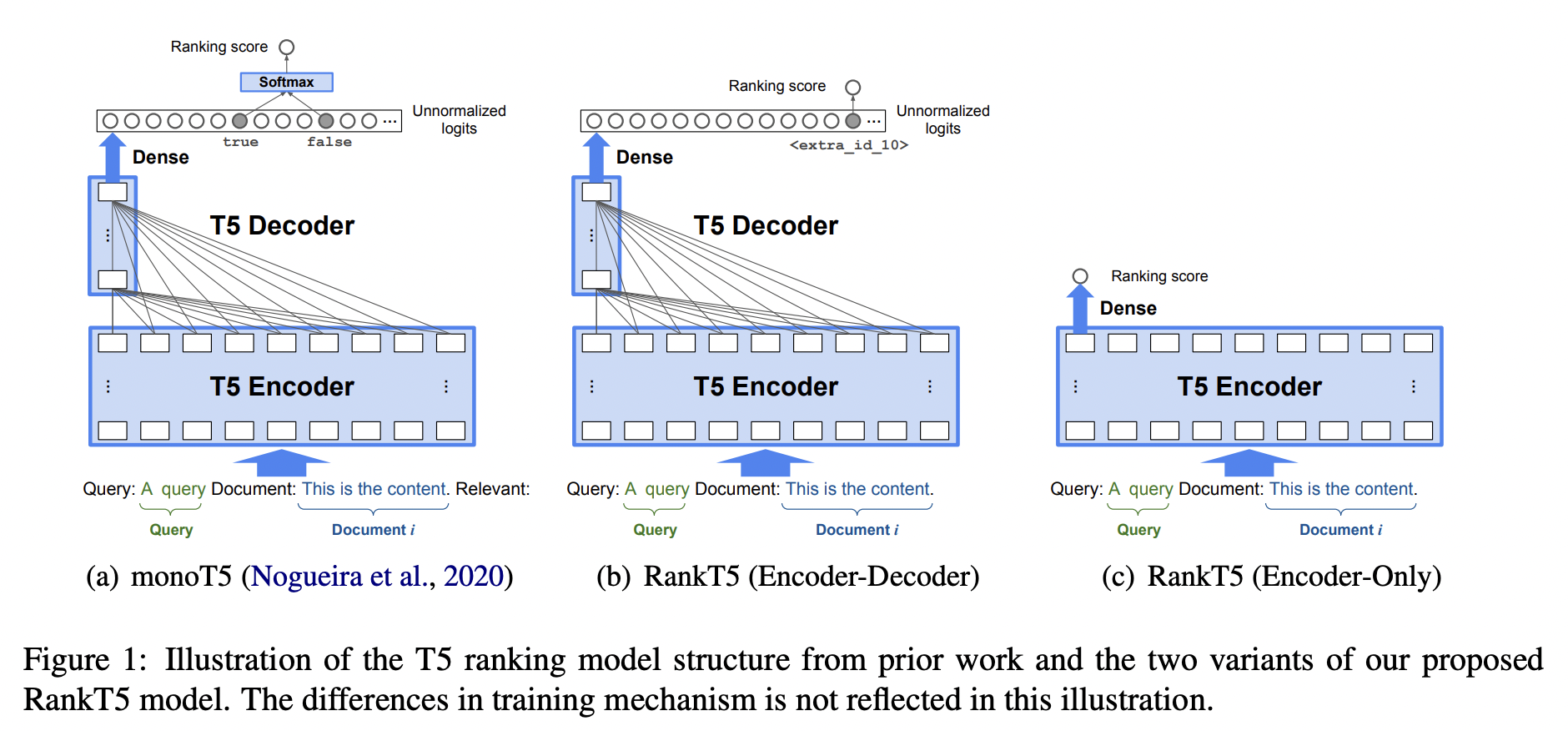
- monoT5 와의 차이점
- monoT5에는 "Relevant:" 포함된다.
- query-positive document 들어가면 true 라는 토큰을 생성하게 한다.
query-negative document 경우, false 라는 토큰을 생성한다. - RankT5는 특수토큰(<extra_id_10>)에 대한 로짓값을 사용해서 Ranking score 를 만든다. 이 때에 Unnormalized logits을 이용해서 랭킹스코어를 만드는데, 이 때에는 softmax 를 취하지 않는다.
- monoT5 (a) 보다 RankT5 (b)가 더 좋은 이유
- monoT5에서는 softmax를 통해서 ranking loss 를 계산하는데, (b)에서는 dense 레이어를 통해서 나온 로짓값 그 자체를 Ranking loss 를 사용하기 때문에 backpropagation을 통한 학습이 더 잘 되었다고 이해할 수 있다.
Training
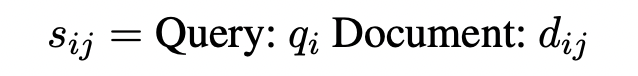
1. Encoder-Decoder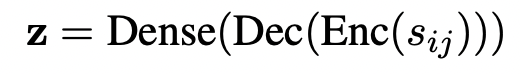

2. Encoder-Only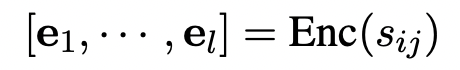
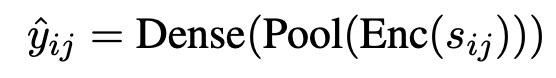
Loss
- Pointwise cross entropy (PointCE)
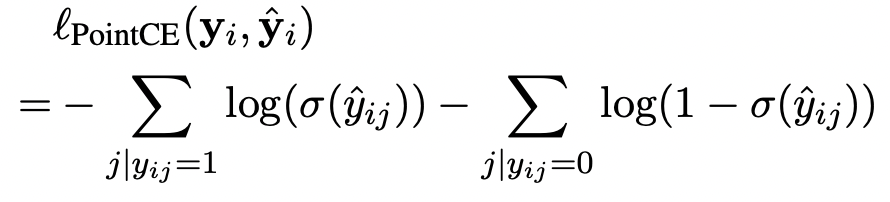
- Pairwise logistic (Pair)
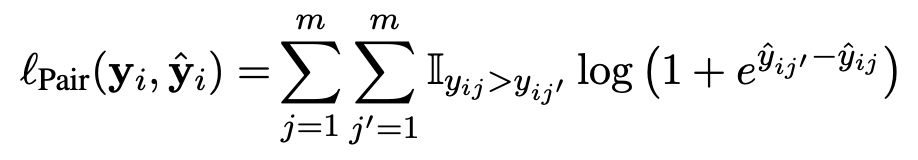
- Listwise softmax cross entropy (Softmax)
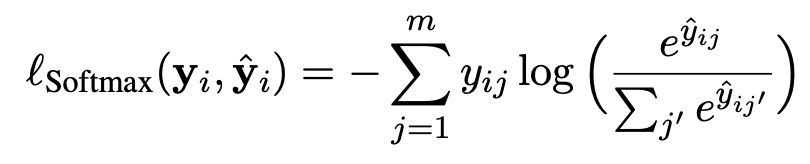
- Listwise poly-1 softmax cross entropy (Poly1)
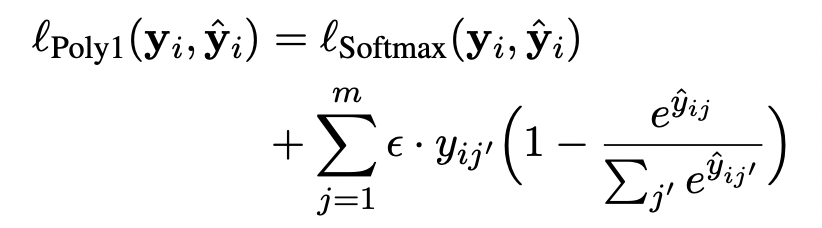
Experiments
- Retriever 모델은 GTR 사용(GTR 모델은 간단하게 말하면, T5의 인코더만 이용해서 contrastive learning 진행한 모델이다.)
- negative sample 999개를 랜덤 샘플로 가져와서 사용했다.
- positive 1개, negative 35개
- t5 large 가져와서 사용함.
Results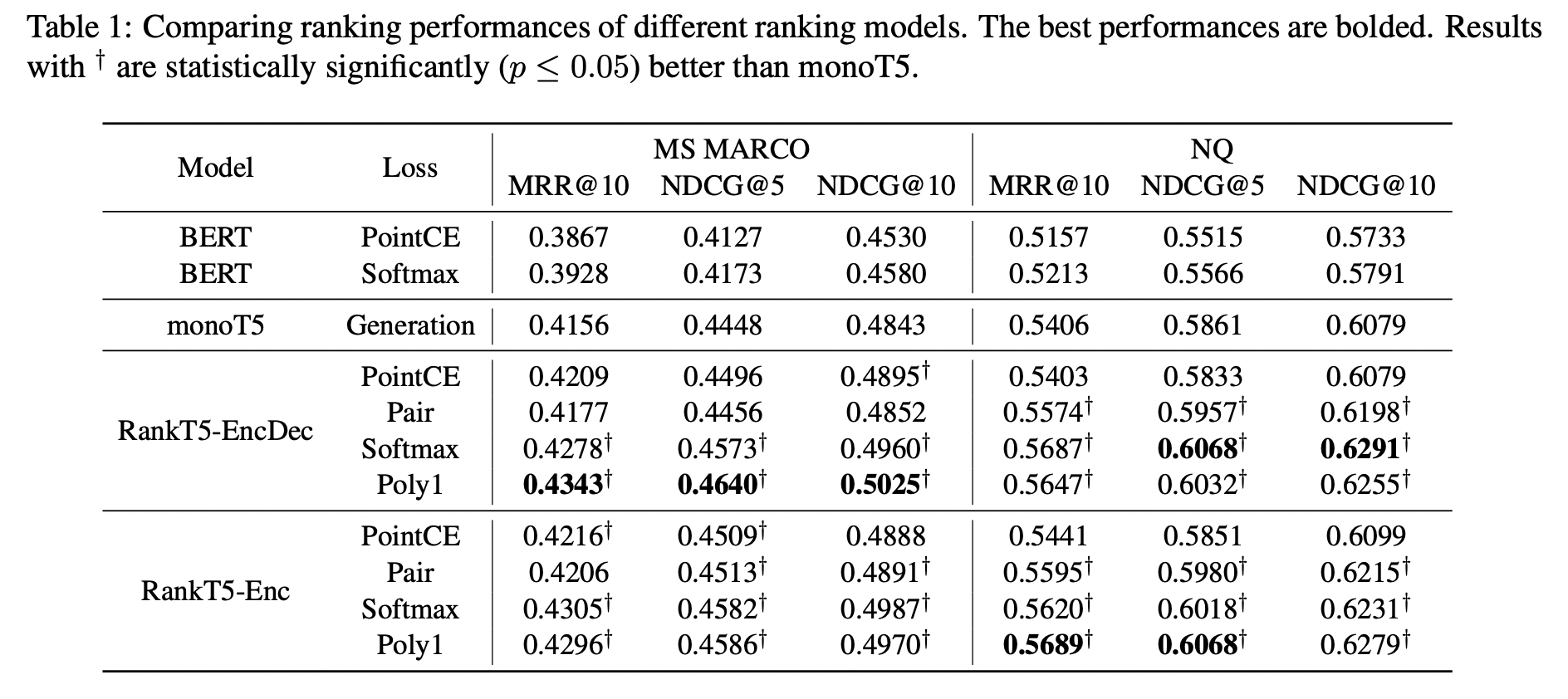
- RankT5-EncDec, RankT5-Enc 의 점수차이는 크지 않다.
- RankT5-EncDec의 경우 Poly 1 loss 사용했을 때의 점수가 가장 좋다.

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻