데이터가 없을 때 어떻게 dense retrieval을 하기 위한 방법을 고민한 논문
데이터가 없는 상황에서는 필요한 데이터를 먼저 마련해야한다.
Hypothetical Document Embeddings (HyDE)
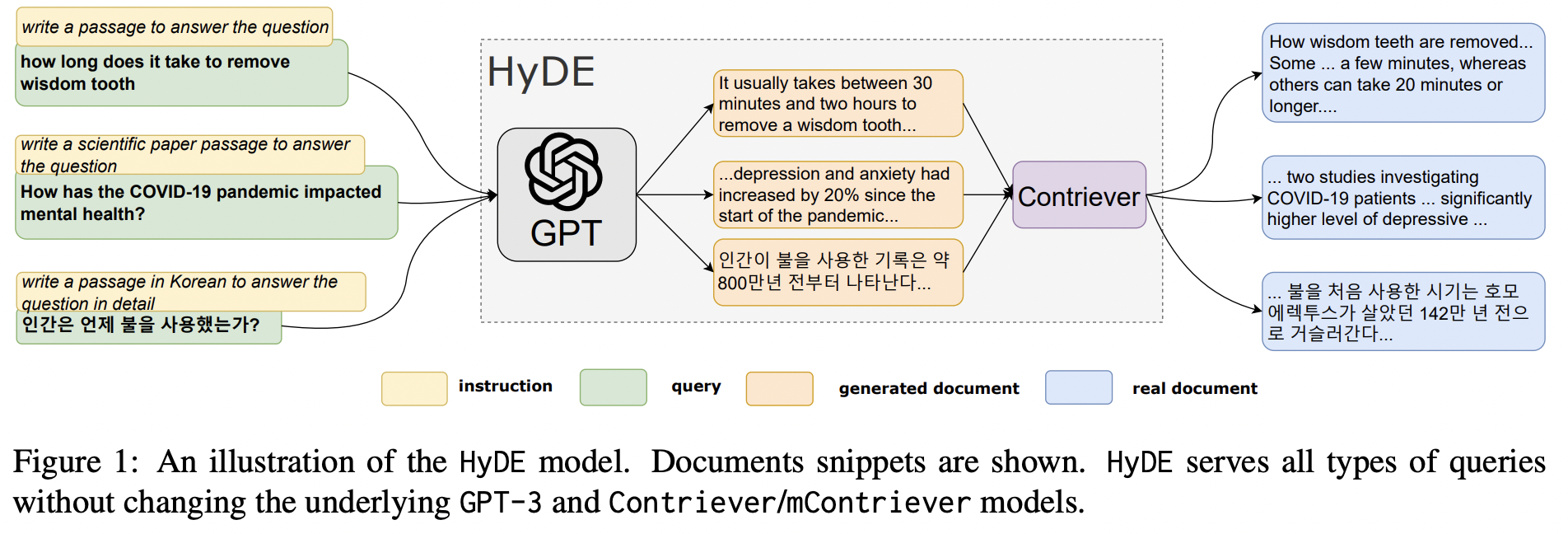
질문을 넣어서 본문을 만들도록 함. 노란색깔 박스에서 볼 수 있듯이 instruction이 들어가고 있다. 데이터셋마다 다른 instruction을 사용한다.
질의 하나에 여러가지 문서가 나오고 한 질의에서 나온 여러가지 문서들의 임베딩을 구해서 각 질의에서 나온 문서들의 평균 임베딩을 구한다. (hallucination을 막기 위해서 이렇게 평균을 취하는 방식으로 진행하고 있음)
여기에서 훈련은 하고 있지 않다. 추론과정만을 사용해서 데이터를 모으는 과정을 보여주고 있다.
Contriever : unsupervised 학습된 biencoder 모델
- unsupervised model은 다양하게 굉장히 많이 있지만 Contriever는 contrastive learning을 이용해서 biencoder 학습한 unsupervised model이다.
여기에 이 논문의 내용을 바로 이해할 수 있도록 도와주는 데모가 있다.
https://github.com/texttron/hyde/blob/main/hyde-demo.ipynb
이게 얼마나 쓸 만한지에 대해서 보여준다. finetuning 한 모델에서 건져오는 passage 만큼이나 문서를 가져올 수 있다.
Experiments
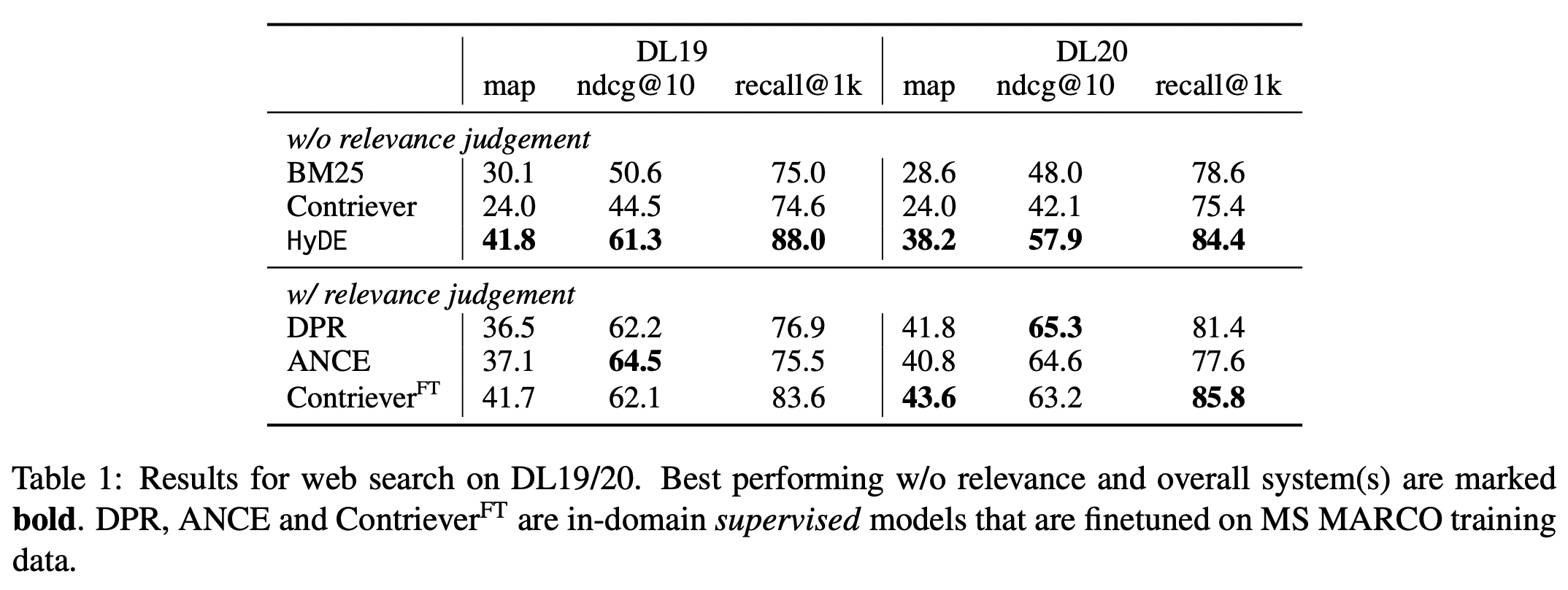
Web Search (TREC DL19 and TREC DL20)
Low Resource Retrieval
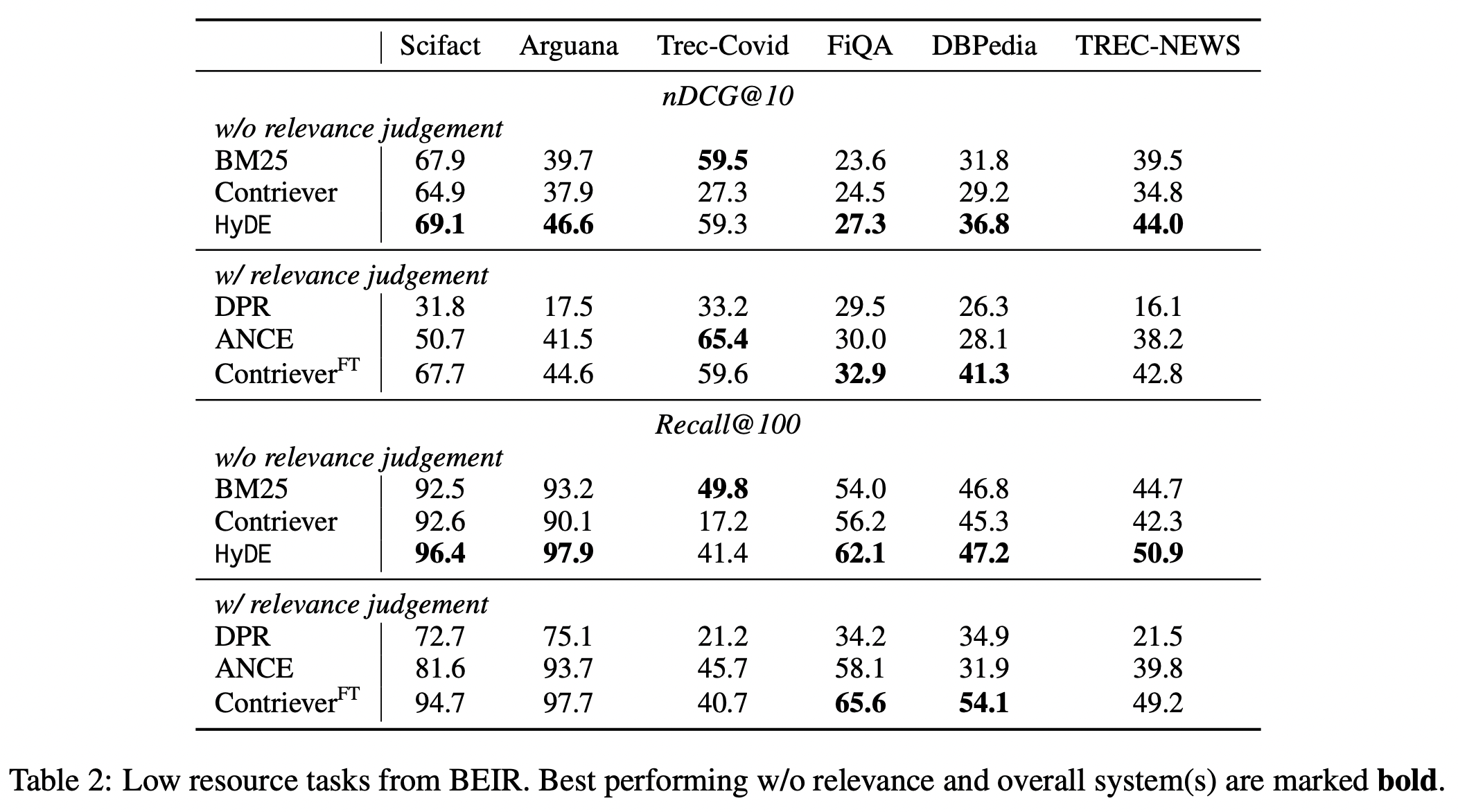
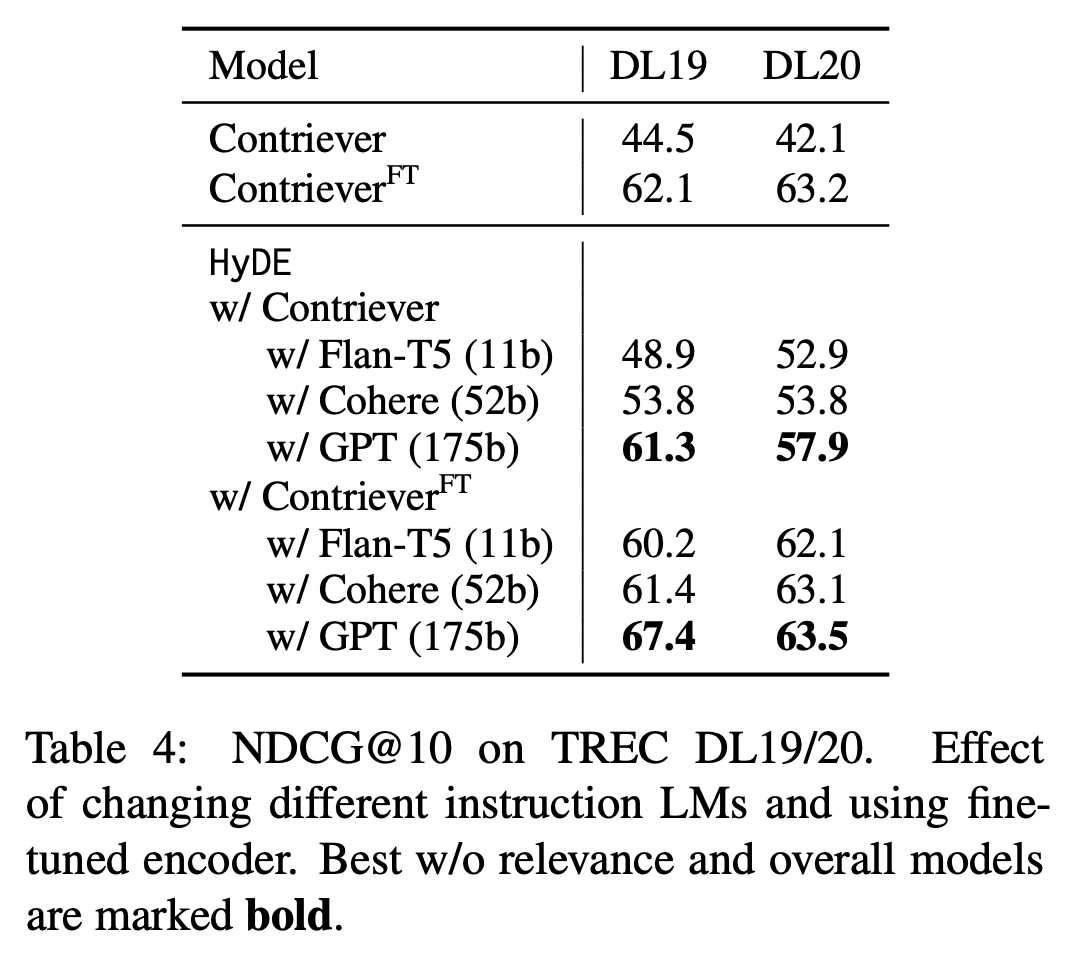
위 두 개의 테이블을 보면, finetuning 모델의 성능보다 높은 성능을 보이기도 한다. (아무래도 finetuning이 더 높은데, 성능이 이 부근까지 오른다는 점은 실제로 활용 가능성이 있다고 해석할 수 있다.)
추가
생성은 instruct-GPT 가 가장 성능 상 좋다.