- Query expansion을 비교적 간단한 방식으로 진행하여 MS-MARCO, TREC DL에서의 점수를 올렸다.
- 이 페이퍼에서 제시한 방법의 결과인 데이터는 아래에 공개되었다.

- 위 그림에서 볼 수 있듯이 쿼리가 주어졌을 때, document에 해당하는 부분을
“Write a passage that answers the given query:”프롬프트를 이용해 생성한다.
네 개의 데이터(k=4)를 프롬프트 뒤에 추가해서 데이터를 생성한다.
Sparse Retrieval
- 쿼리가 보통 다큐먼트에 비해서 굉장히 짧기 때문에 쿼리 쪽 가중치를 더 주기 위해서 단순히 쿼리를 반복해서 다큐먼트와 붙여서 새로운 쿼리를 만든다. 이 때의 반복은 다섯 번 하였다(n=5).
이렇게 만든 새로운 쿼리 (다큐먼트를 포함한)를 가지고 bm25 retrieval를 하였다.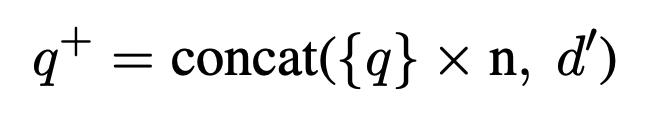
Dense Retrieval
- 새로 생성한 다큐먼트를 string concat하는 방식으로 쿼리를 구성한다.
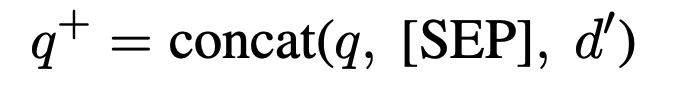
실험구성 (두 가지 세팅으로 실험을 구성하였다.)
1. BERT로 모델 initialize, BM25를 hard negative로 삼는 DPR 방법
2. KL divergence를 이용하여 cross-encoder teacher model로 distillation 하는 방법
평가
- in-domain evaluation : MS-MARCO passage ranking, TREC DL 2019, 2020으로 모델을 평가하였다.
- out-domain evaluation : five low-resource datasets from the BEIR benchmark (zero-shot)
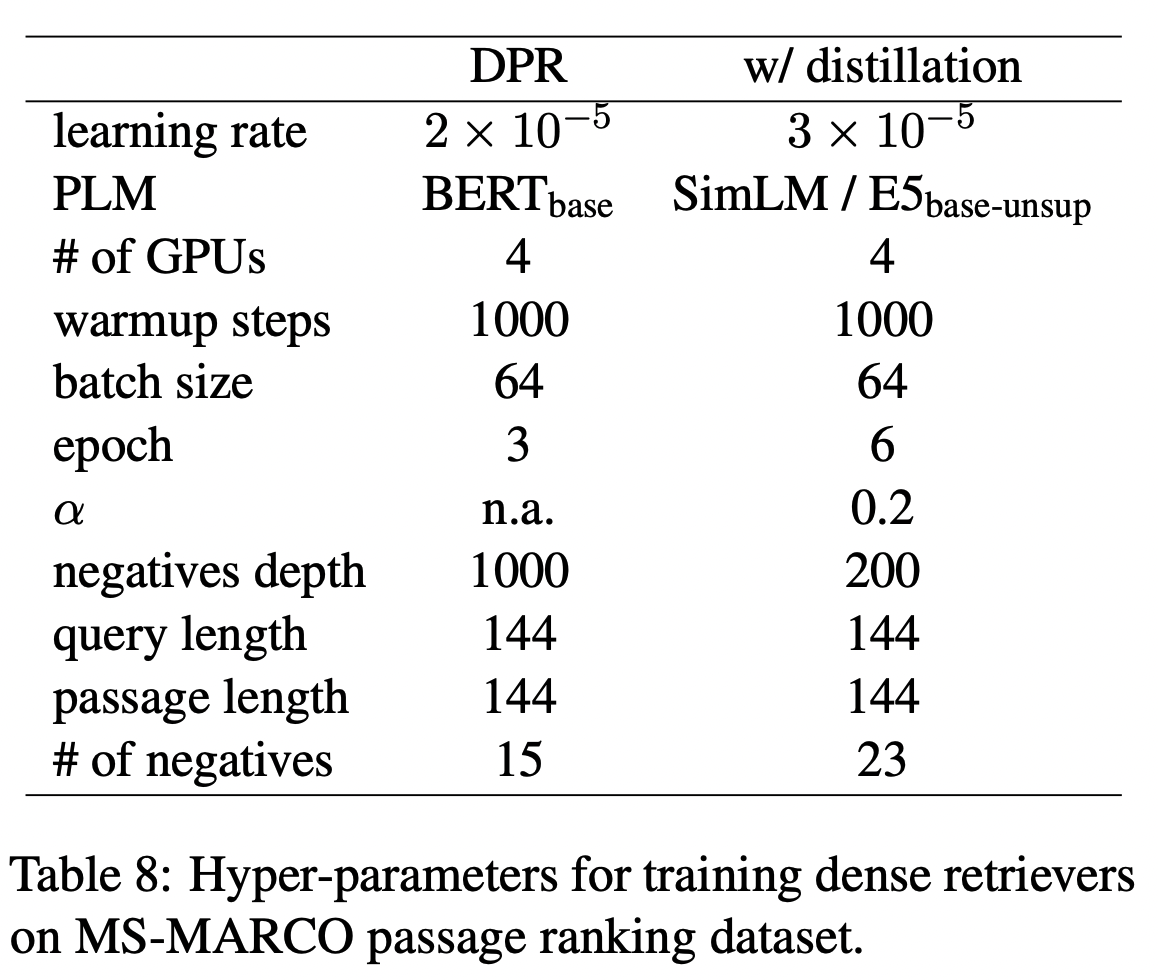
실험 하이퍼파라미터
- query length 144
- LLMs 4 in-context examples
실험
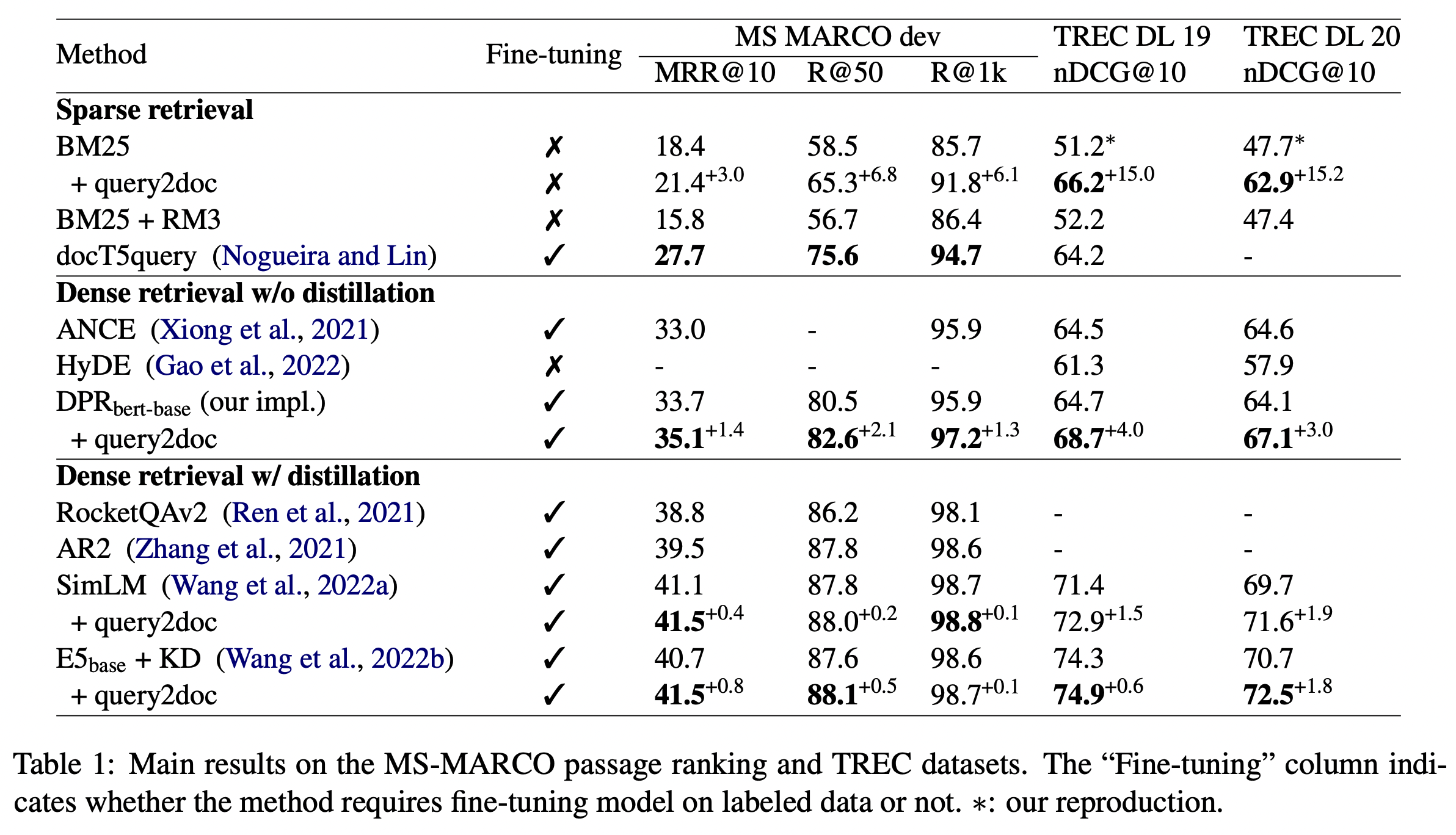
- BM25 + query2doc 일 경우가 BM25 보다 높다. (특히 TREC 데이터 경우에는 15프로의 높은 상승을 보여줌, entity 중심 쿼리가 많은데 이 경우 lexical match가 많을수록 엄청난 도움이 된다.)
- 하지만 docT5query 점수가 MS MARCO dev 에서는 더 높다. 이 경우 query generator를 해당 데이터에 맞춰 finetuning 하기 때문에 더 좋은 점수가 나온 것으로 보인다.
- dense retrieval 실험에서는 query2doc이 베이스라인들보다 가장 높은 점수를 가진다.
- 하지만 distillation이 결합되면 그만큼 성능이 좋아지지는 않는다. distillation에서 얻는 이득을 미리 얻은 셈이라고도 볼 수 있다.
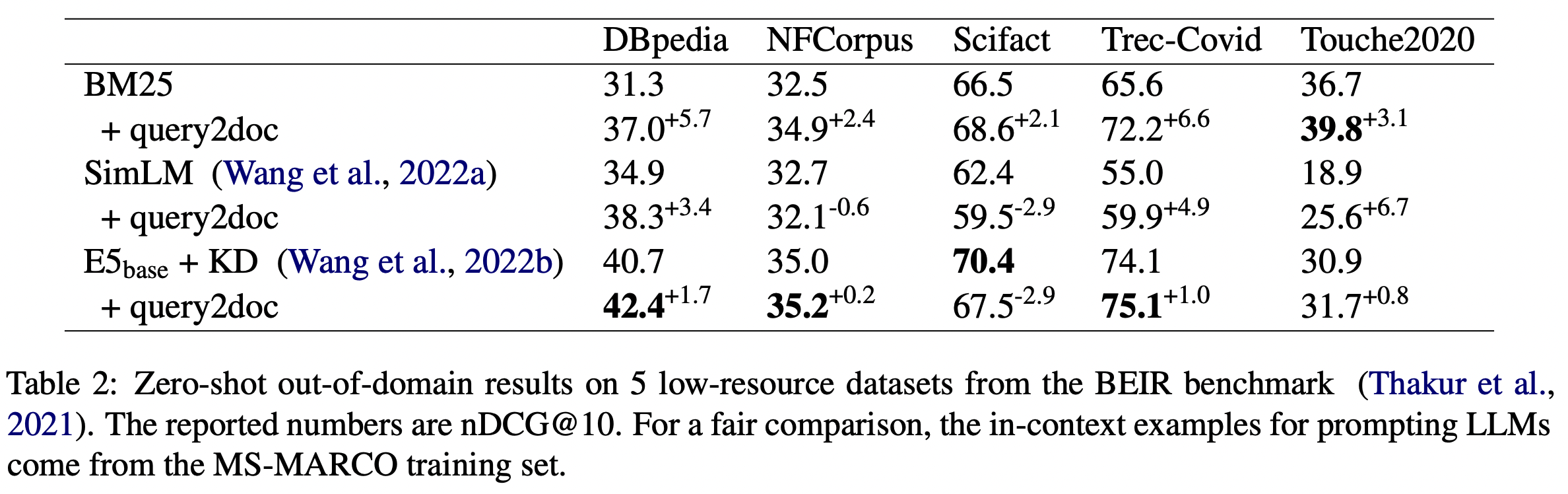
- DBpedia 데이터셋의 경우 위의 TREC 데이터셋처럼 entity 중심의 데이터인 점에서 점수상승이 크게 있었지만
- NFCorpus, Scifact 의 경우 점수가 줄어드는 양상도 보였다. (distribution mismatch)
(질문) distribution mismatch (BM25와의 다른 경향성)
On the NFCorpus and Scifact datasets, we observe a minor decrease in ranking quality. This is likely due to the distribution mismatch between training and evaluation.
- 여기에서 말하는 distribution mismatch 란 무엇일까?
- training data, evaluation data 간의 차이를 말한다. 키워드는 유사하지만 word 분포가 너무나 다른 경우를 굳이 가정해야 위와 같은 실험결과를 말한 distribution mismatch 관점에서 해석할 수 있다.
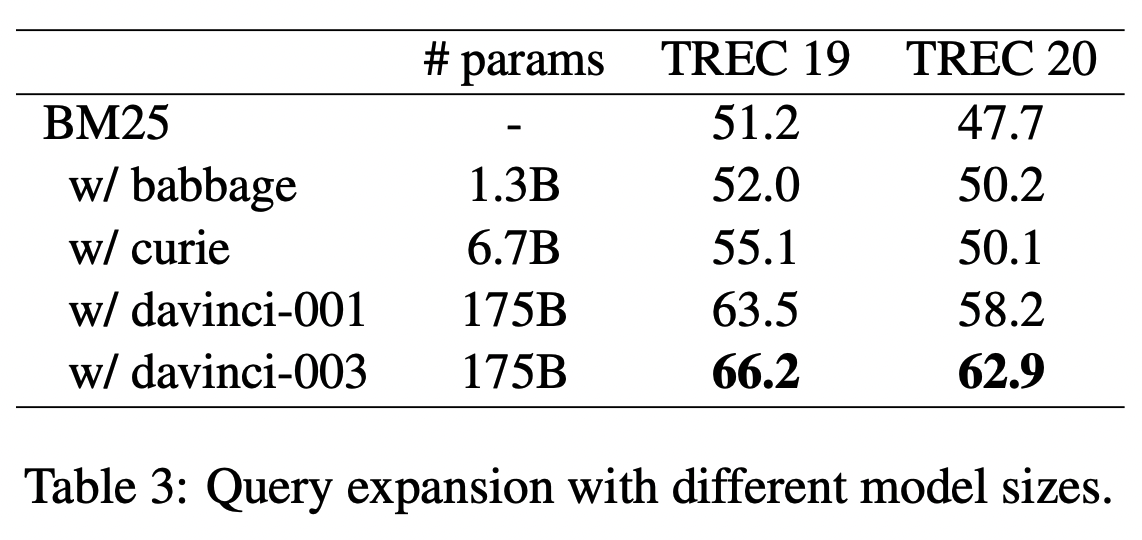
Scaling up LLMs is Critical
- 1.3B부터 175B를 비교해볼 때의 파라미터가 더 클수록 점수가 더 높아진다.
- davinci-001은 davinci-003의 초기버전이고, davinci-003의 경우 더 좋은 훈련데이터와 instruction tuning을 더 적용한 버전이다.
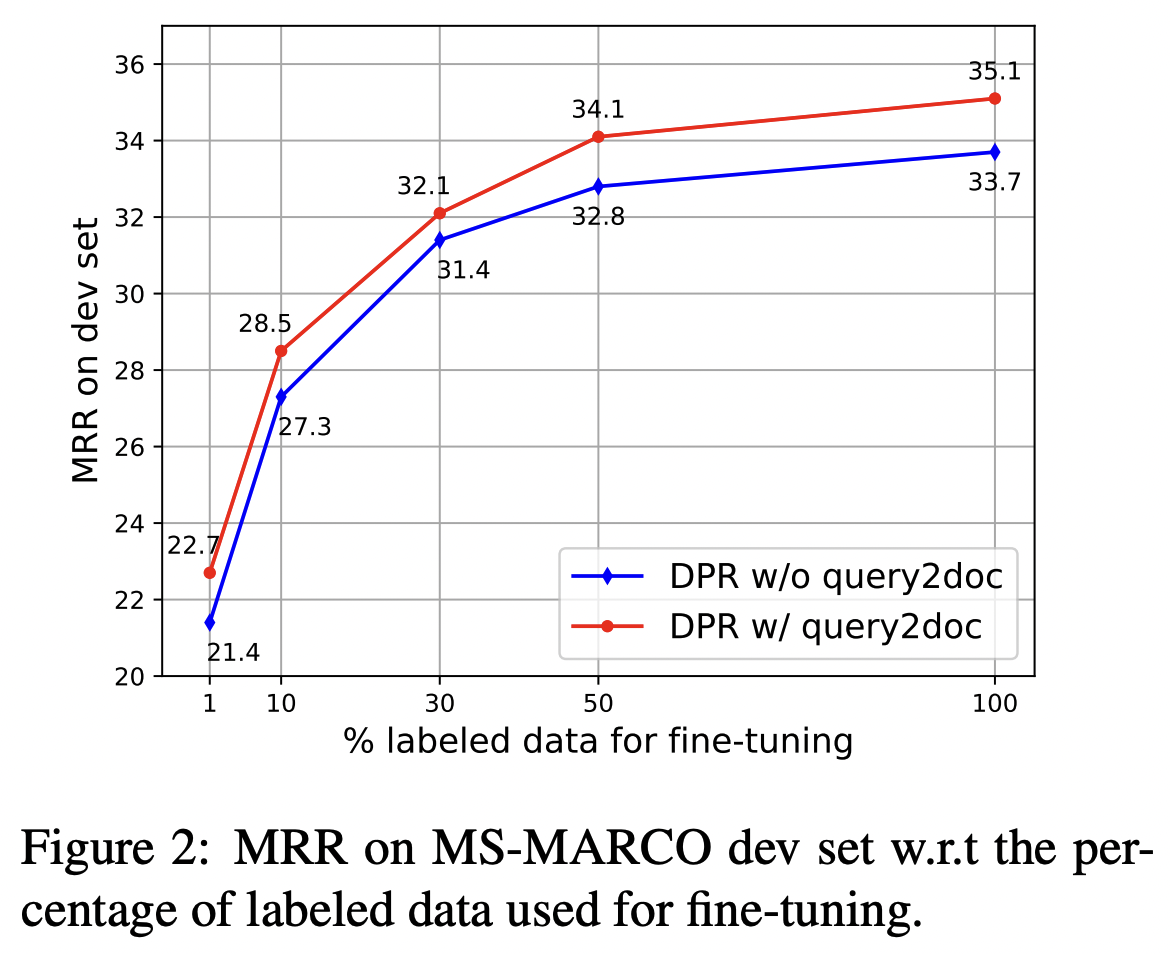
Performance Gains are Consistent across Data Scales
- 모든 경우에서 DPR + query2doc이 베이스라인인 DPR 보다 더 좋은 점수를 보인다.
How to Use Pseudo-documents
- 쿼리랑 다큐먼트를 붙여서 새로운 쿼리로 삼고 여기에서는 학습을 진행했는데, 다큐먼트만 사용했을 때의 점수가 떨어지는 경향을 보면 이 둘을 같이 상호작용하면서 점수를 높이는 것으로 볼 수 있다.

Case Analysis
- LLM에서 생성된 결과는 더 디테일하고 정확한 정보가 들어가있지만 query와의 lexical mismatch가 적은 편이다.
- 하지만 LLM에서 잘못된 것을 사실처럼 말하는 현상은 찾아내기가 어렵다는 문제가 있다.

한계점
- 너무 느리기 때문에 실생활 적용이 매우 어렵다.


산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻