Retriever-Readers와 같은 구조가 아니라 단순 LLM만 이용하는 상황에서 ODQA를 잘하기 위한 두 가지 연구를 소개한다.
먼저 결과부터 보면, 아래는 EM 수치를 기준으로 올려진 표이다.
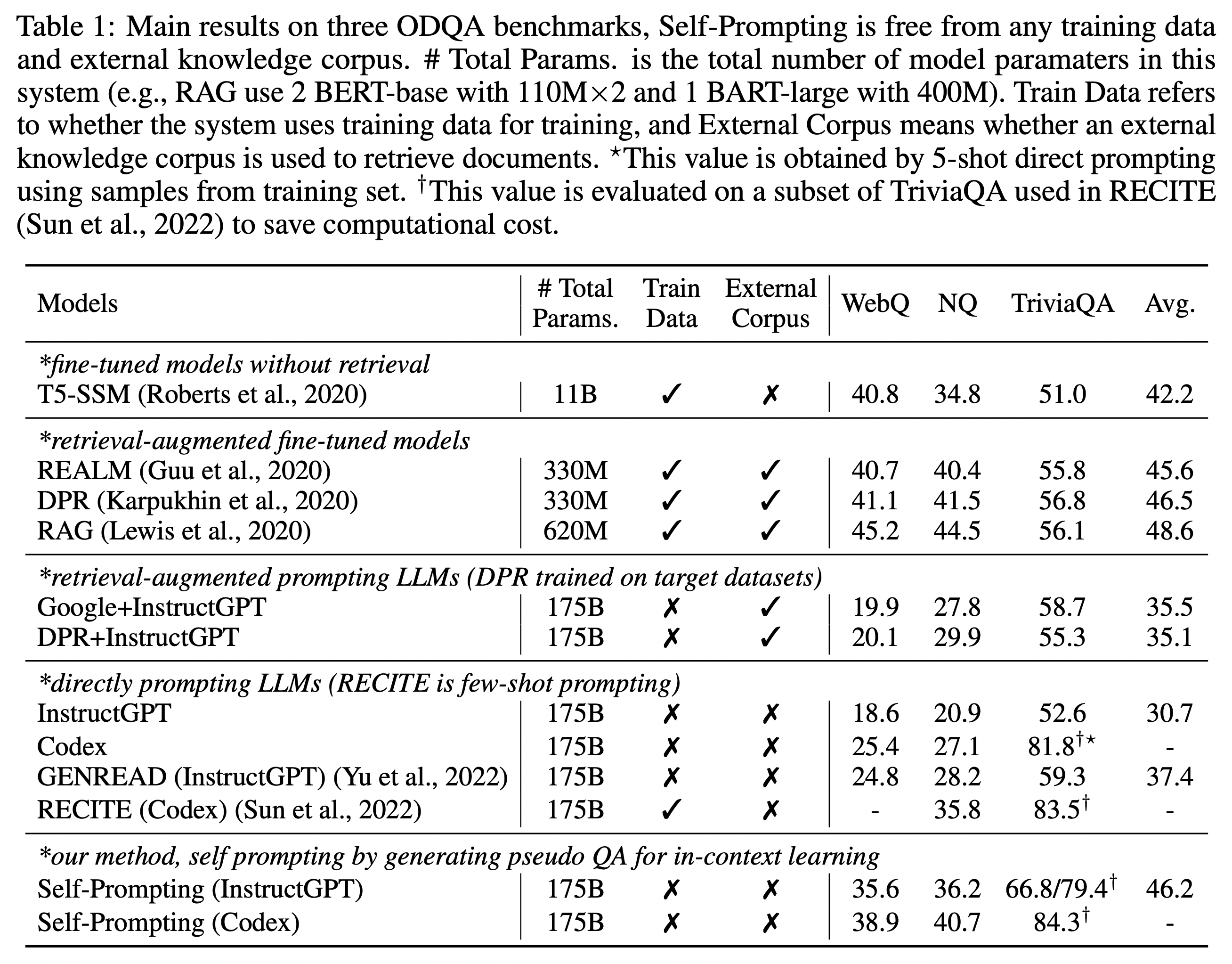
Retriever-Readers 구조로 가장 잘 알려진 모델인 DPR과 비교를 해보면, 이 포스팅에서 설명할 두 연구인 RECITE, Self-Prompting의 점수가 NQ, TriviaQA에서 근소하거나 상승한 수치를 가짐을 확인할 수 있다. WebQ 데이터셋의 경우에는 DPR 수치가 아직은 좀 더 높다.
WebQ datasets
WebQ 데이터셋에 대해서는 해당 웹사이트에서 받아볼 수 있을 것 같은데
(https://worksheets.codalab.org/worksheets/0xba659fe363cb46e7a505c5b6a774dc8a)
6,642 개의 질문과 답변 쌍이 있다고 한다. 질문은 보통 하나의 named entity를 가지고 있으며 웹에서 유명한 것들을 대상으로 하는 질문들이라고 한다.
다음은 WebQ 데이터셋의 예시이다.
{"url": "http://www.freebase.com/view/en/justin_bieber", "targetValue": "(list (description \"Jazmyn Bieber\") (description \"Jaxon Bieber\"))", "utterance": "what is the name of justin bieber brother?"},
Models
이 표에서 T5-SSM은 당시 T5에 salient span masking을 적용해 만든 가장 큰 모델이었던 11B 모델 finetuning 한 것이고, InstructGPT(Ouyang et al., 2022)는 chat-gpt api에서는 text-davinci-001, Codex(Chen et al., 2021)는 코드를 이해할 수 있는 GPT-3 모델로 code-davinci-002로 진행되었다. (현재는 shutdown 상태)
RECITATION-AUGMENTED LANGUAGE MODELS
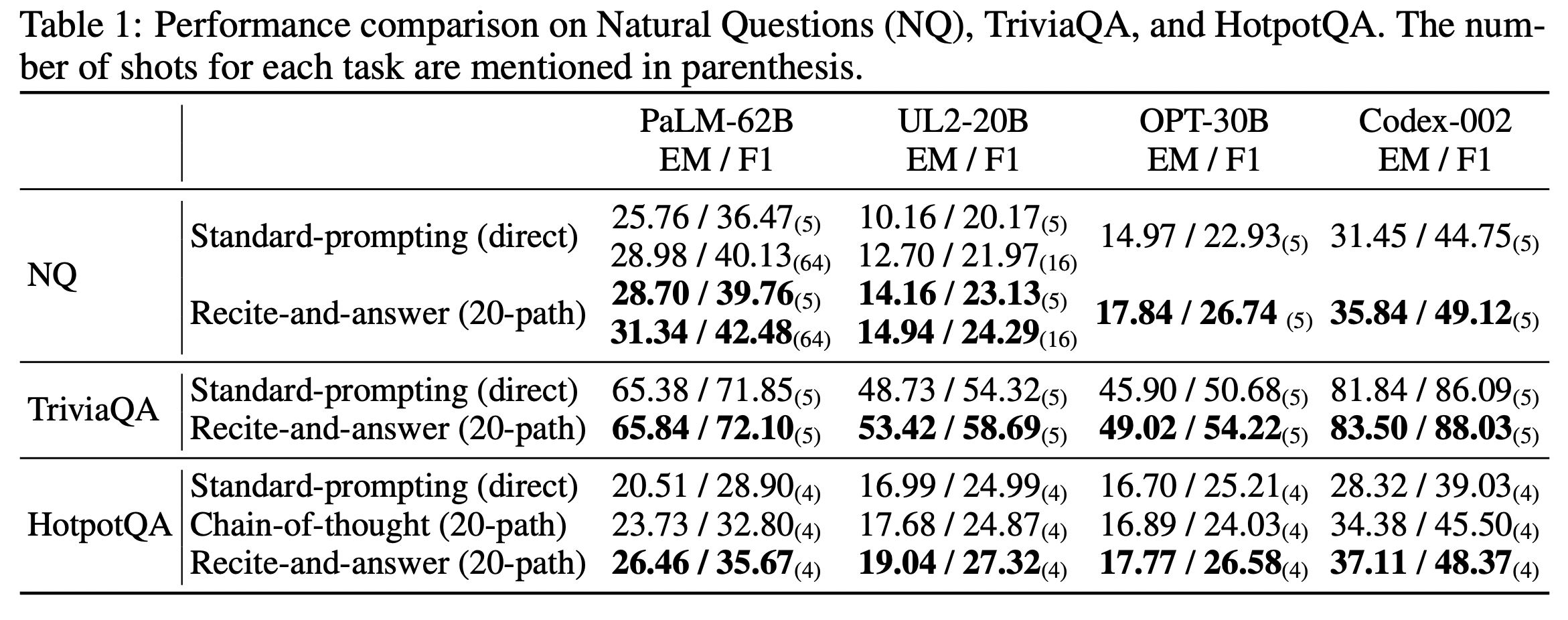
먼저 RECITE에 결과를 보면 이 연구에서는 PaLM, UL2, OPT, Codex 네 개의 사전학습된 모델을 통해서 점수를 내었고 Natural Questions, TriviaQA, HotpotQA 세 개의 ODQA(Open domain Question Answering) 결과를 아래와 같이 보여주었다.
Pre-trained model
먼저 여기에서 시작점으로 잡은 네 가지 모델에 대해 간단하게 알아보자.
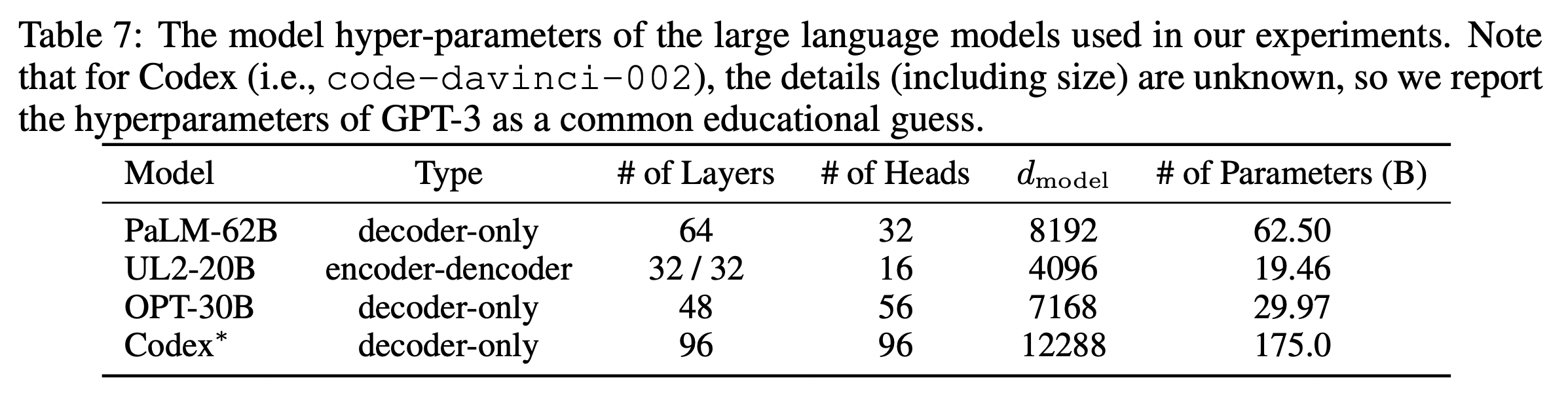
PaLM은 구글에서 공개한 초거대모델로, 540B까지 있다. 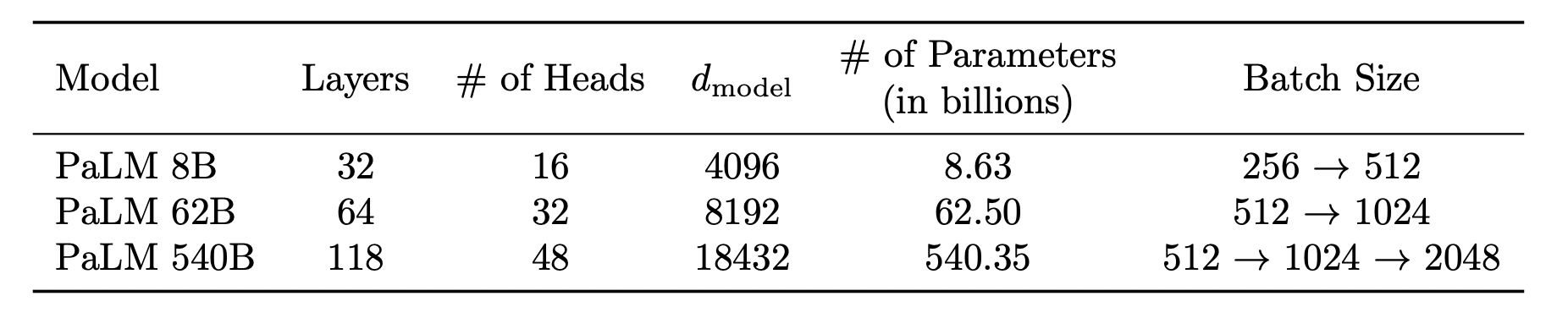
UL2 또한 구글에서 공개했으며 PaLM과 다르게 encoder-decoder 모델이다. 20B까지 있으며 Flax-based T5X model checkpoints(UL2 20B model, Flan-UL2 20B)가 공개되었다고 한다.(https://github.com/google-research/google-research/tree/master/ul2) 다음은 SuperGLUE의 점수인데 PaLM62B와 UL2 20B의 성능이 유사하게 보인다. 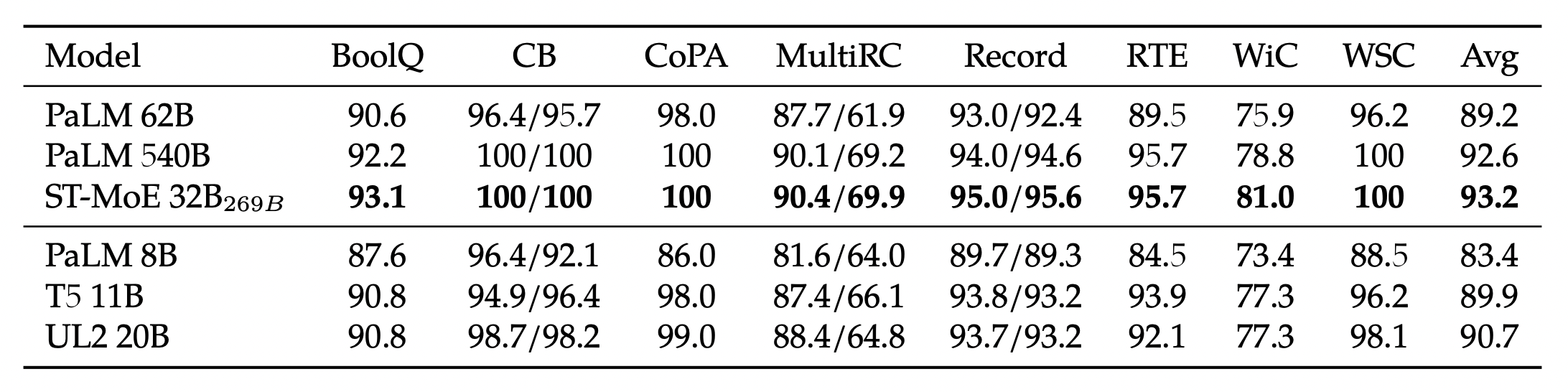
OPT는 Meta에서 공개한 초거대 모델이다. 175B까지 있지만 이 연구에서는 30B를 가져와서 사용하고 있다.
RECITE
RECITE는 질문에 대해 정답을 내기 전에 recitation을 중간 스텝으로 삼는 방식이며 어떤 질문에 대답하기 위해서 사전지식이 굉장히 많이 필요한 경우에, 관련된 사전지식에 대해서 먼저 언급하는 상황을 LLM에 적용해서 구현한 연구이다. 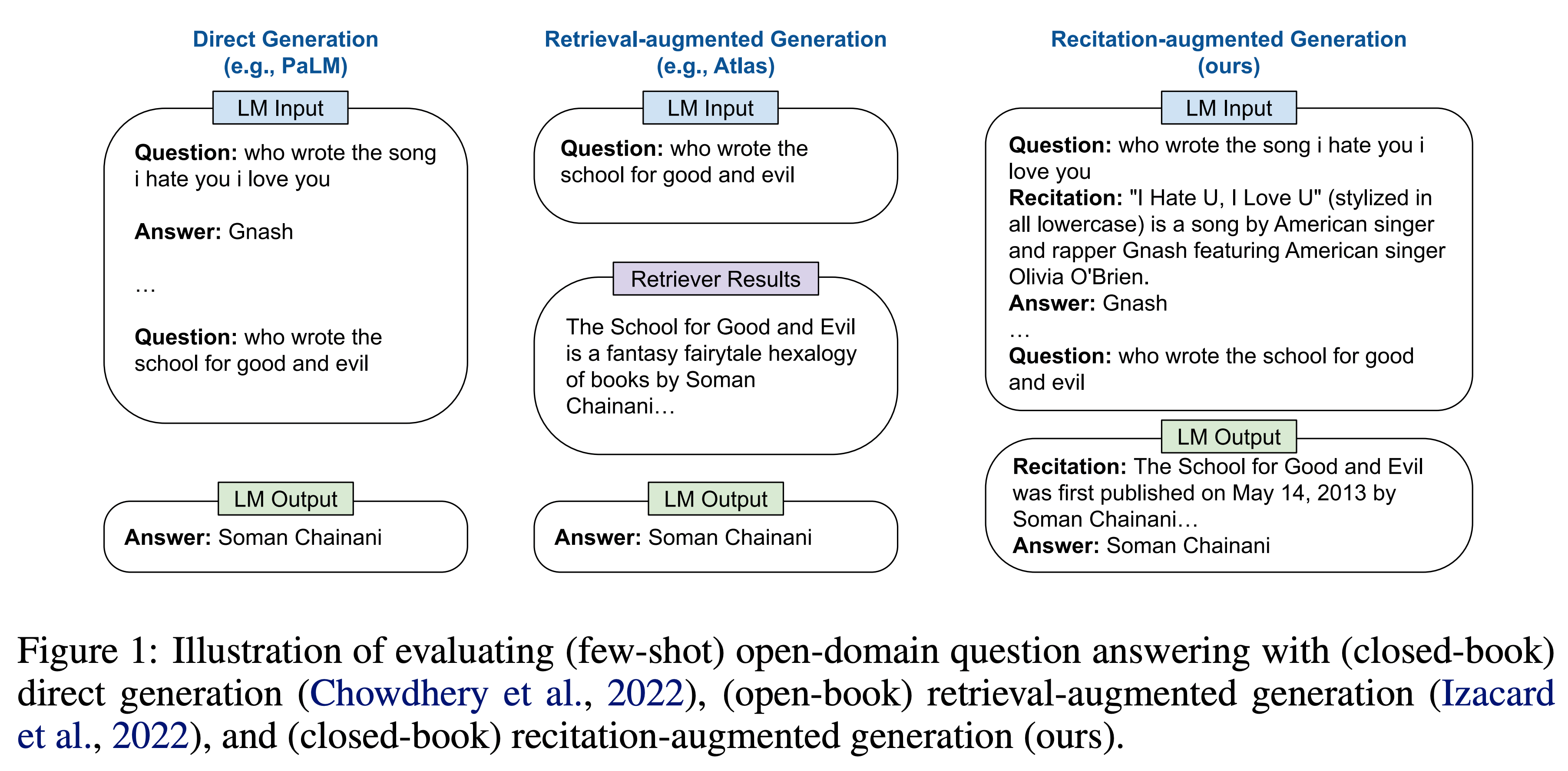
Figure 1을 보면, 가장 왼쪽의 그림은 보통 QA를 진행할 때의 그림이다. LM Input으로 Question, Answer 쌍을 넣어주고 마지막으로 묻고 싶은 질문을 넣어주면 정답을 하는 방식이다. 가운데 그림은 좀 더 정확한 답변을 위해서 검색결과를 중간에 가져오는 방식이다. 가장 오른쪽 그림이 이 연구에서 제시하는 방향을 보여주는데, Recitation을 통해서 중간 과정을 생성하도록 유도하는 그림이다. Question, Recitation, Answer 순으로 들어가고 마지막 묻고 싶은 질문을 넣으면 Recitation, Answer를 차례로 만들어간다.
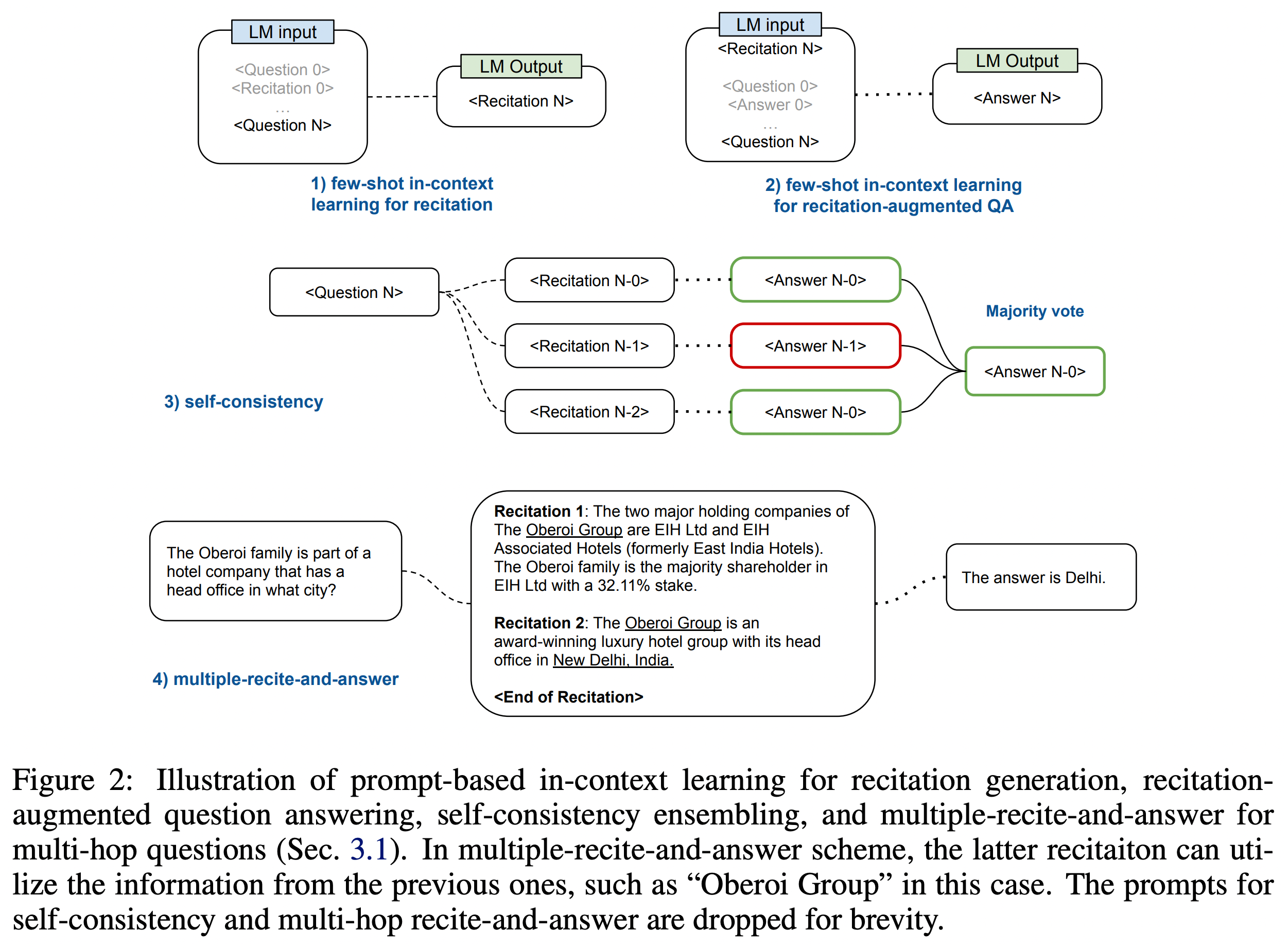
few-shot으로 진행이 되며, 여러 문서에서 해당 답을 찾을 수 있기 때문에 top-k 샘플링을 통해서 몇 개의 recitation들을 생성하고 여기에서 가장 최적의 답변을 생성하는 식으로도 할 수 있다.
멀티홉 질문에서도 이를 이용할 수 있는데, 단순히 관련된 문서에서 뽑은 답들 중 최적값을 뽑는 것이 아니라 아예 문서의 정보들을 종합해서 답변을 생성하게 할 수도 있다.
다시 결과를 보면, recite 얼마나 진행할지에 대한 부분이 20으로 세팅되어있는데 이는 아래와 같은 결과 때문에 설정된 수치이다. 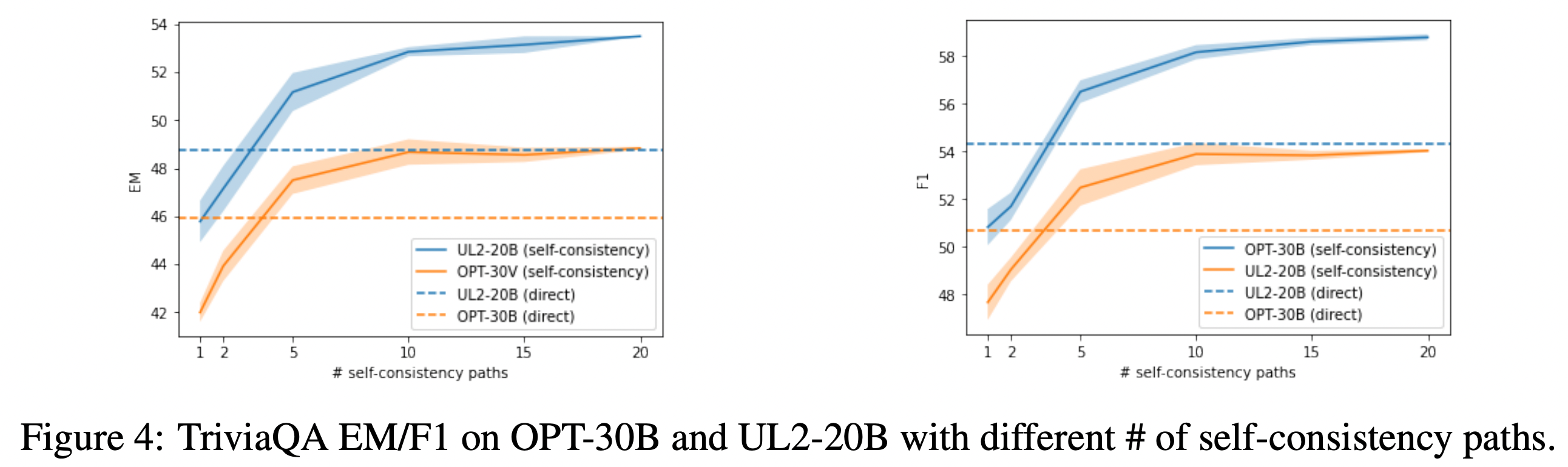
HotpotQA에 사용된 prompt 예시는 아래와 같다. 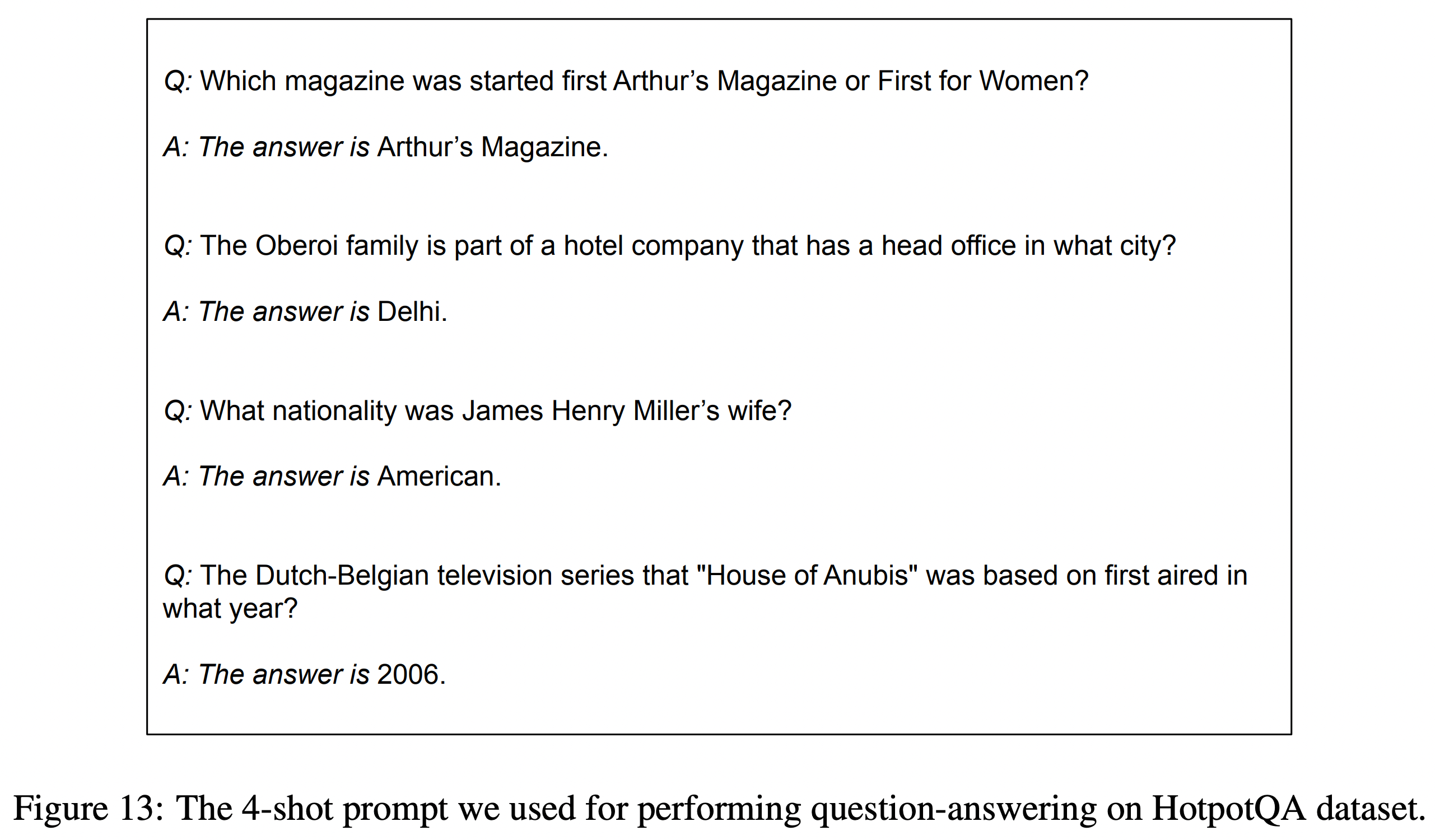


Self-Prompting Large Language Models for Zero-Shot Open-Domain QA
두 번째 소개할 연구는 RECITE의 점수를 뛰어넘는 연구이다. 이 연구에서는 Self-Prompting framework를 제시한다. 이 연구에서는 LLM 자체가 가지고 있는 능력치를 최대한 발휘하는 데에 초점을 맞추었다.
(이 연구에서는 Zero-shot이라고 말하고 있는데, 사실 LLM을 통해서 prompt로 들어가는 데이터를 미리 만들어서 넣어준다는 점에서 논란의 여지가 있겠다. 아무래도 저자들의 입장에서는 미리 만들어진 데이터를 넣지 않는다는 점에서 Zero-shot이라고 말한 것이 아니었을까 생각해보았다.)
Self-Prompting은 preparation, inference 두 가지 스텝으로 구성이 되어있다.
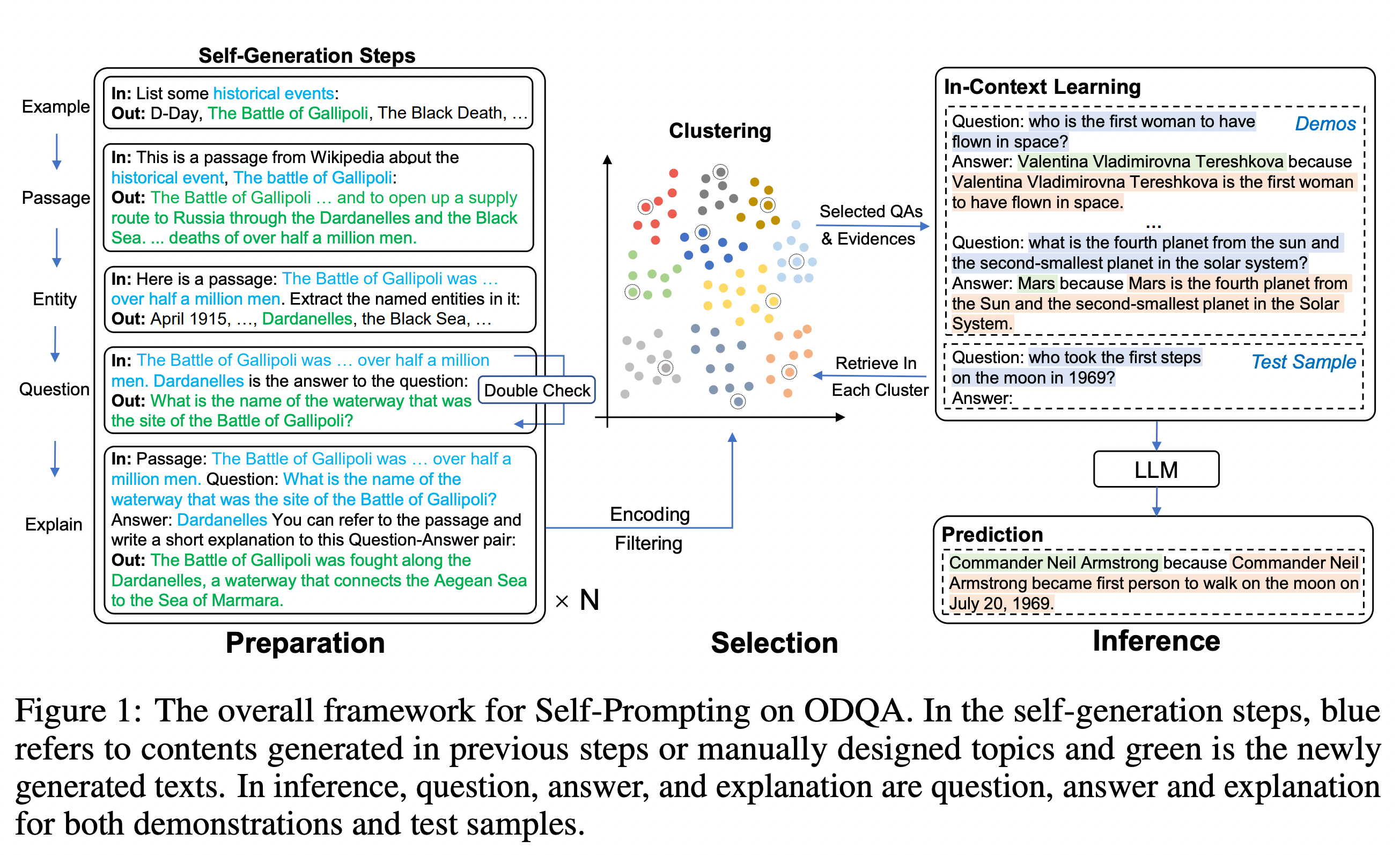
Preparation
- Passage Generation
“List some {topic}:”
“This is a passage from Wikipedia about the {topic}, {example}:” - Named Entity Recognition (date, name, location)
“Here is a passage: {passage} Extract the named entities in it:” - Question Generation
“{passage} {entity} is the answer to the question:”. - Explain the QA pair (a fine-grained annotation for the generated QA pairs)
“Passage: {passage} Question: {question} Answer: {answer} You can refer to the passage and write a short explanation to this Question-Answer pair:”.
Inference
추론을 위한 question과 유사하게 묶이는 질문답변 예제들을 in-context learning(prompt)에 포함시킨다. 이 때에 벡터 단위로 질문답변의 예제들을 모은다고 나와있는데 논문에서는 Sentence-BERT를 통해 인코딩했다고 하고 k-means 클러스터링으로 k 개의 질문답변 예제를 뽑는다고 한다. (이후에 10개를 뽑는다고 나와있다.)
지금까지
ODQA에서 Retriever-Reader 구조 없이 LLM의 역량을 최대한 발휘하는 방향의 두 가지 연구를 살펴보았다.
