1. YOLO v7 tiny 모델 선정 이유
- https://github.com/WongKinYiu/yolov7
- 최신 모델을 사용하여 학습해보고 싶어서 yolo v7 모델을 사용했다 (자이카에 탑재해야하기 때문에 가벼운 v7 tiny를 선택하였다)
- yolo v3 모델도 학습하였지만 결과적으로 yolo v7 모델의 성능이 좋아서 자이카에 v7 모델을 탑재했다
- v7에서 제공해주는 onnx 변환, tensorRT 변환 코드를 사용하여 tensorRT로 변환하고 자이카에 탑재했다
2. YOLO v7 전이학습
전이 학습을 위해 AiHub에서 제공하는 100만장 이미지와 총 2일간 tiny 모델 학습을 진행하였다
2-1. AiHub Dataset
- ai-hub 사이트의 dataset을 다운받아서 사용
- AIHub에서 신호등/도로표지판 인지 영상 데이터를 활용하여 모델 사전 학습 진행
- 프로젝트 환경과 비슷한 표지판, 신호등 인지 데이터를 통해 적은 데이터로 좋은 성능을 위해 사전 작업을 수행하였다

2-2. hyper-parameter 설정
- 기본적으로 YOLOv7이 제공하는 기본 파라미터를 사용
- 데이터 증강(Data Augmentation)기법인 mixup을 사용하여 데이터 증강을 최대화 시킴
- shear, flip과 같이 방향을 바꾸는 파라미터는 0으로 주어 좌,우 표지판의 방향을 유지하며 학습 진행
- 교차 검증을 진행하며 best 모델 추출 (500에폭)
3. 학습 과정 및 결과
- 사전 학습을 진행한 모델의 loss와 mAP 모두 준수한 성능을 확인함
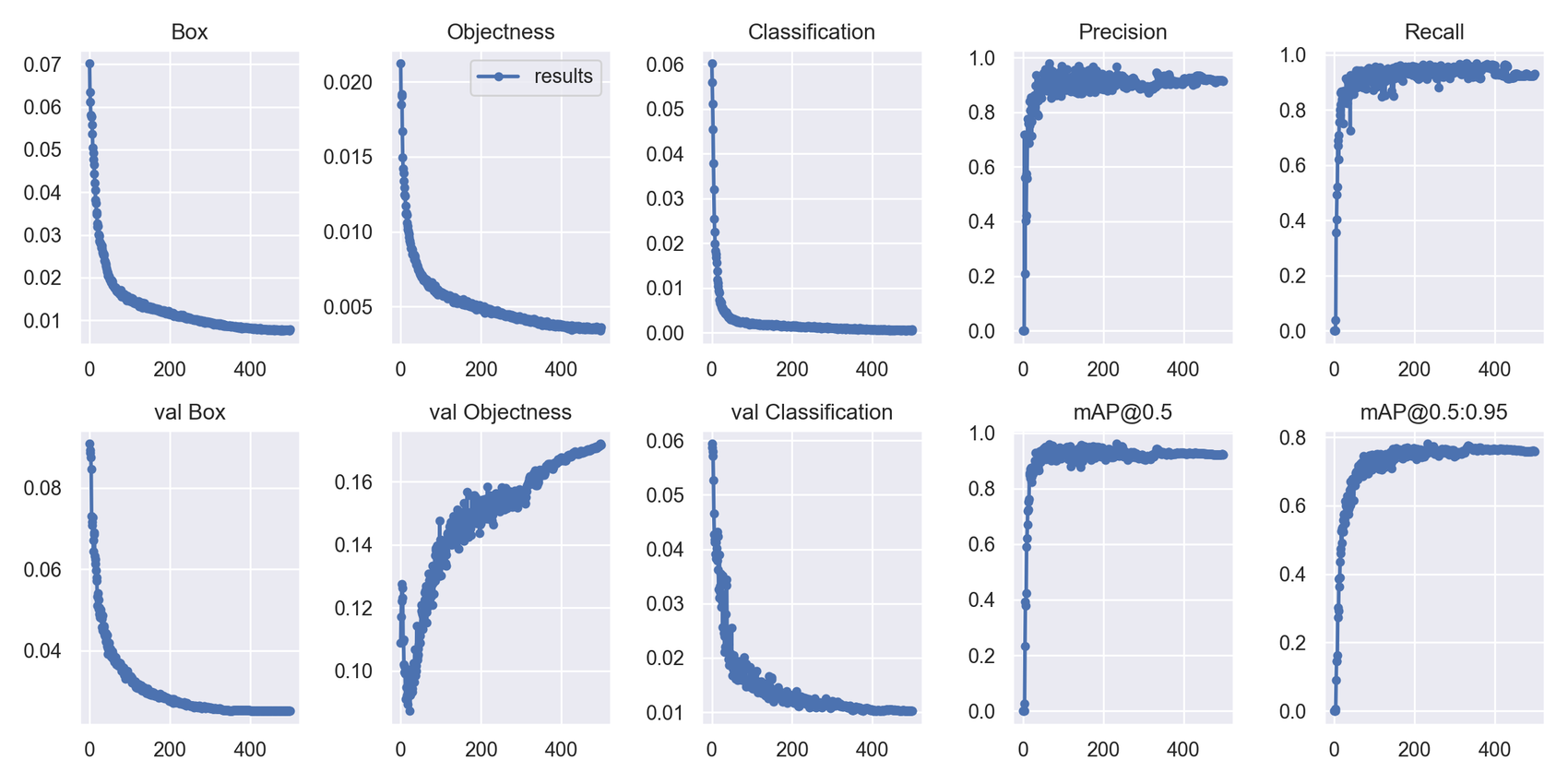
- 하지만 objectness에서는 loss가 오르는 모습은 라벨링 단계에서 ignore 클래스에 대해 명확한 기준을 정하지 못하고 라벨링을 진행하여 모델에 혼란을 야기함
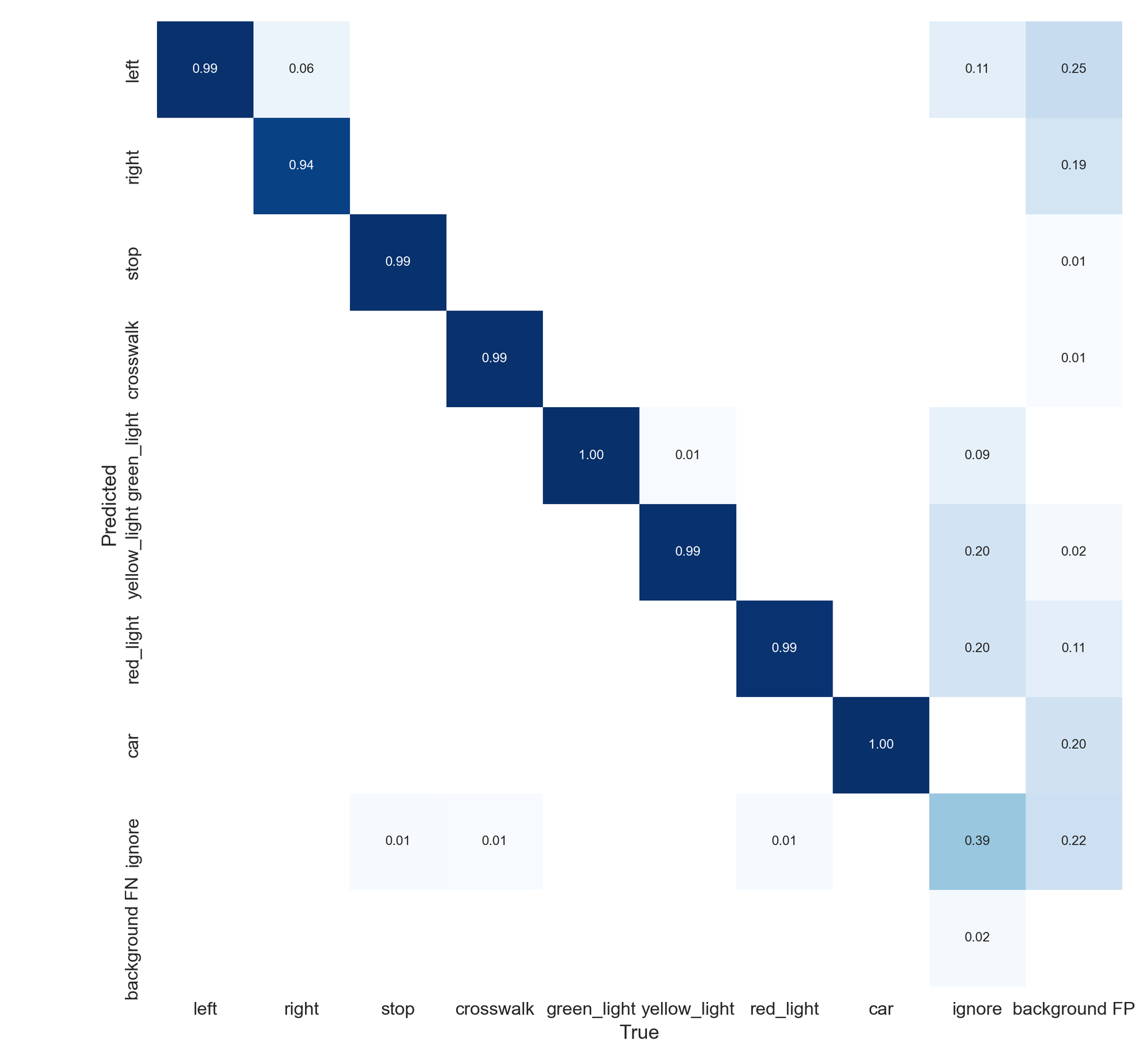
- 결과적으로 ignore을 제외한 모든 클래스를 잘 예측하는 모델을 구축함

- 예측 결과를 보면 대부분 90% 이상 confidence score를 보이며 객체 탐지에 대한 좋은 정확도와 안정성을 확인할 수 있음
- 또한, YOLOv7은 40에 가까운 FPS를 유지하며 기존 yolov3보다 대략 2~3배 높은 FPS 성능을 보여주며 실시간에 가까운 차선 인지와 객체 탐지가 가능함
