
개요
화면을 타일(예: 32×32픽셀) 단위로 나누고, 각 타일마다 조명이 영향을 줄 가능성이 있는지 검사한 뒤 실제 픽셀 셰이딩 시 연산할 라이트만 골라 쓰는 기법입니다.
단순한 2D 스크린 분할(타일) + 각 타일의 z(깊이) 분포(min/max 혹은 여러 depth‐slice) 두 가지를 함께 쓰기 때문에 “2.5D”라는 명칭이 붙었습니다.
본 글에서는 [Real Time Rendering 4th Edition] 에서 발췌한 Tiled Shading, 2.5D Culling 기법을 소개한 후 D3D11에서의 구현 과정, Culling 후 Lighting 연산 결과 화면을 기술합니다.
Tiled Shading의 도입
Tiled Shading은 Uncharted: Drake’s Fortune (2008)에서 처음 제안된 기법입니다. 이 방식은 픽셀들을 타일(tile) 단위로 나누고, 각 타일에 영향을 미치는 조명만 저장함으로써 처리량과 저장량을 줄이는 것이 핵심입니다.
예를 들어 32x32 크기의 타일로 화면을 나누고, 각 타일에 영향을 주는 조명 리스트를 구성합니다. 이후 셰이더는 각 타일의 조명 리스트만 참조하여 렌더링을 수행하는 것입니다.

[Harada, Takahiro. "A 2.5D Culling for Forward+." SIGGRAPH Asia 2012]
타일은 화면의 작은 뷰 프러스텀(Frustum)으로 간주되며, 조명의 구형 볼륨(spherical volume)이 이 프러스텀과 겹치는지 빠르게 테스트할 수 있습니다. 타일 단위로 리스트를 저장하면 처리 비용, 저장소 사용량, 대역폭 사용량이 크게 줄어드는 장점이 있습니다.
Tiled Shading의 한계
그러나 타일의 작은 뷰 프러스텀에 조명의 Bounding Sphere가 조금이라도 겹치면 해당 타일에 영향을 주는 조명을 판정됩니다. 이러한 느슨한 판정은 실제 타일이 포함하는 오브젝트와 가까이 있지 않은 무관한 조명조차 타일에 영향을 주는 조명으로 판정되는 단점이 있습니다.
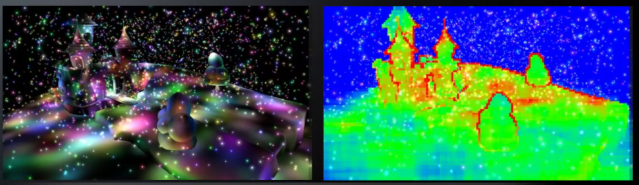
[Harada, Takahiro. "A 2.5D Culling for Forward+." SIGGRAPH Asia 2012]
위 그림에서 Screen Space 기준 타일 프러스텀은 길어지고, 길어진 타일 프러스텀은 오브젝트와 멀리 떨어진 불필요한 광원을 다수 포함하는 문제가 있습니다.
이러한 문제를 해결하기 위해 Z-Prepass Light Culling이 등장하였는데요, 타일이 포함하는 모든 물체의 최소 깊이, 최대 깊이인 MinZ와 MaxZ를 추출한 뒤 광원의 깊이가 [0, MinZ) 또는 (MaxZ, 1] 일 때 Culling하는 아이디어입니다.
Z-Prepass Culling의 한계
그러나 Z-Prepass Culling은 MinZ가 작고 MaxZ가 클수록 광원이 Culling되지 않을 확률을 높이는 깊이 불연속 문제가 있습니다.

[ Image from “Just Cause 3,” courtesy of Avalanche Studios [1387].)
단순한 Z-Prepass Culling은 환경에서 숲, 잔디, 복잡한 오브젝트가 많은 환경에 불리하게 작용합니다.
위 그림에서 캐릭터와 멀리 있는 구조물은 같은 타일에 포함되어 있고, Z-값의 범위 (MinZ ~ MaxZ )가 매우 넓어지는 상황입니다. 이렇게 되면 해당 타일 내에서 대부분의 광원이 컬링되지 않고 계산에 포함되므로, 비효율적인 조명 연산이 들어갈 것입니다.
이를 해결하기 위해 HalfZ / BiModal Clustering 등의 기법이 타일 내 깊이 분포를 분석하여 두 개의 대표 Z값(가까운 객체, 먼 객체 중)을 사용해 컬링하는 것이 제안되었습니다만, 마찬가지로 깊이 분포가 단일하거나 복잡한 환경에 부정확하다는 문제점이 있습니다. GPU 효율성을 살린 대신, 2개의 깊이 만으로는 표현하지 못하는 환경에는 불리한 셈이지요.
2.5D Culling - 제안 배경
2.5D Culling은 깊이 불연속이 잦은 장면에서 Z-prepass 기반 단순 컬링 방식이 비효율적인 문제를 해결하기 위해 제안되었습니다.
해당 타일의 오브젝트들의 Z분포와 조명의 Z값을 비교할 때에 비트마스킹 연산을 활용함으로써, 오버헤드를 많이 늘리지 않으면서도 정확한 컬링을 수행하기 위해 Harada 외에 의해 제안되었습니다.

(a) 기존 타일 프러스텀 컬링 (b) 2.5D Culling - Depth 구간 적용 후
Harada 외는 2.5D 컬링(2.5차원 컬링)이라는 더 정교한 알고리즘을 제안합니다. 이 방식에서는 각 타일의 깊이 범위인 zmin과 zmax를 깊이 방향으로 n개의 셀로 분할하는데요,
- 각 타일마다 n비트로 구성된 지오메트리(라이팅 대상이 될 오브젝트들) 비트마스크를 생성하고, 해당 깊이에 지오메트리가 존재할 경우 비트를 1로 설정합니다. (일반적으로 n = 32를 사용합니다.)
- 이후 모든 라이트에 대해 반복하면서 라이트 비트마스크를 만듭니다. 이 비트마스크는 해당 조명이 어떤 셀을 점유하는지를 나타냅니다.
- 셀은 Z값을 기준으로 분할 되었으므로 위에서 내려다 본 평면 구간과도 같습니다
- 지오메트리 마스크와 라이트 마스크를 비트 단위 AND 연산 후 결과가 0이면, 해당 조명은 해당 타일의 지오메트리에 영향을 주지 않으므로 제외합니다.
- 그렇지 않다면, 그 라이트는 타일의 조명 리스트에 추가됩니다.
실제로 한 GPU 아키텍처에서 Stewart와 Thomas의 실험에 따르면, 라이트 수가 512개를 초과하면 HalfZ가 기본 타일드 디퍼드보다 더 나은 성능을 보였고, 2300개를 초과하면 2.5D 컬링이 가장 뛰어난 성능을 보였다고 합니다.
💡각 타일마다 다른 깊이 범위를 32개로 나누어 타일 별로 다른 깊이 분포를 고려하면서도 비트 연산에 용이한 구간 개수(32bit = uint)로 나눈 셈입니다.
타일 뷰 프러스텀과 구의 교차 판정은 구-평면 교차와 동일하므로 Depth Masking과 타일별 조명 인덱스를 저장하는 방법에 대해서 기술하겠습니다.
Depth Masking 과정
✅ 만일 각 타일이 32x32 픽셀 단위라면, 32x32 스레드로 나누어 각 1픽셀에 해당하는 Depth texture를 병렬 샘플링하여 지오메트리 비트마스크를
InterlockedOr연산을 통해 수행할 수 있습니다.
✅ 본 구현에서는 [NearZ, FarZ]를 32개 구간으로 분할한 예시를 보여드립니다만, 타일별 [MinZ, MaxZ] 구간을 분할하는 것이 올바른 방식입니다.
- Depth 샘플링 및 선형 변환
if (all(pixel < screenSize)) { … }
각 스레드가 맡을 1픽셀이 화면 내에 있을 때에만 깊이 텍스처에서 값을 샘플링합니다.
- 선형 깊이 계산:단, 깊이값이 1.0 (즉, 가장 먼 값)이면 FarZ로 처리합니다
- 정규화 및 슬라이스 인덱스 결정
- 선형 깊이를 [0,1]로 정규화합니다.
- 정규화된 값에
NUM_SLICES = 32를 곱하고 floor 함수를 사용하여 해당 픽셀이 속한 슬라이스 인덱스를 결정합니다.
- 정규화된 값에
- 선형 깊이를 [0,1]로 정규화합니다.
- 비트 마스크 생성
- 각 슬라이스는 하나의 비트를 표현합니다. 예를 들어 Slice Index가 5이면 0x20가 됩니다.
- 각 스레드는 Atomic OR 연산(InterlockedOr)을 사용, 그룹 공유 변수인 TileDepthMask에 자신의 비트를 누적시켜 타일별 오브젝트의 Z 값 구간 분포를 나타냅니다.
- 각 슬라이스는 하나의 비트를 표현합니다. 예를 들어 Slice Index가 5이면 0x20가 됩니다.
- 그룹 동기화
GroupMemoryBarrierWithGroupSync()로 모든 스레드가 계산을 완료한 후, 다음 계산(예: 타일 뷰 프러스텀 교차 등)에 지오메트리 비트마스크 값이 쓰입니다.
- 코드
// DepthMap Texturing할 때 한 픽셀의 값 읽어오려면 TILE_SIZE만큼 나눠야 효율적 [numthreads(TILE_SIZE, TILE_SIZE, 1)] void mainCS(uint3 groupID : SV_GroupID, uint3 dispatchID : SV_DispatchThreadID, uint3 threadID : SV_GroupThreadID) { uint2 tileCoord = groupID.xy; uint2 pixel = tileCoord * TILE_SIZE + threadID.xy; uint2 screenTileSize = TileSize; // TILE_SIZE uint2 screenSize = ScreenSize; // --- 1. 타일 내 각 픽셀의 Depth를 샘플링하고, 해당 슬라이스 인덱스의 비트를 그룹 공유 변수에 누적 // 초기화: 그룹의 첫 번째 스레드가 tileDepthMask를 0으로 초기화 if (threadID.x == 0 && threadID.y == 0) { tileDepthMask = 0; } // (1) 만약 Enable25DCulling 옵션이 켜져 있다면, 해당 타일 내의 depth mask 구성 if (Enable25DCulling != 0) { if (threadID.x == 0 && threadID.y == 0) { tileDepthMask = 0; } GroupMemoryBarrierWithGroupSync(); // 픽셀이 화면 내에 속하면 depth 샘플링 float depthSample = 0; if (all(pixel < screenSize)) { depthSample = gDepthTexture[pixel]; } // 깊이값 변환: gDepthTexture가 보통 [0,1] 범위의 비선형 값이면 선형화 float linearZ = (depthSample == 1.0f) ? FarZ : (NearZ * FarZ) / (FarZ - depthSample * (FarZ - NearZ)); float depthNormalized = saturate((linearZ - NearZ) / (FarZ - NearZ)); // 해당 구간의 depth slice 인덱스 계산함 int sliceIndex = (int) floor(depthNormalized * NUM_SLICES); sliceIndex = clamp(sliceIndex, 0, NUM_SLICES - 1); uint sliceBit = 1u << sliceIndex; InterlockedOr(tileDepthMask, sliceBit); GroupMemoryBarrierWithGroupSync(); // 동기화 (32x32픽셀: 스레드가 각 픽셀 맡음) } }
타일별 Light를 비트로 저장
RWStructuredBuffer<uint> TileLightMask : register(u0);- 타일별 조명 마스크
RWStructuredBuffer : 각 타일에 대한 라이트 정보는 비트로 (사용 / 미사용) 저장됩니다.
타일 단위로 조명 적용 여부를 저장하는 버퍼이며, 예를 들어 최대 1024개만큼 각 타일별로 담을 수 있다면 1024 / 32 = 32개의 정수를 할당하여 저장합니다. 타일별 저장할 수 있는 조명 개수가 클수록 위 비트 저장 방식이 효율적입니다.
아래의 Compute Shader 코드의 인자, 예시를 설명하겠습니다. 현재 i번째 Light가 프러스텀과 교차하고, Depth 구간 또한 지오메트리 비트마스킹 연산을 통과 했다면 현재 타일(flatTileIndex)에 i번째 Light가 들어갈 bucket번째 정수의 bitIndx를 1로 만들어 저장합니다.
if (insideFrustum && depthOverlap)
{
uint bucketIdx = i / 32;
uint bitIdx = i % 32;
InterlockedOr(TileLightMask[flatTileIndex * SHADER_ENTITY_TILE_BUCKET_COUNT + bucketIdx], 1 << bitIdx);
hitCount++; // 타일별 Light 개수 증가 (HeatMap 출력에 쓰임)
}- 인자
MAX_LIGHTS_PER_TILE = 1024: 각 타일은 1024개의 조명 정보를 담을 수 있으며, 32개의 32비트 정수로 구성됨을 뜻합니다.SHADER_ENTITY_TILE_BUCKET_COUNT: 각 타일이 조명 정보를 담기 위해 필요한uint정수의 개수 입니다.SHADER_ENTITY_TILE_BUCKET_COUNT=MAX_LIGHTS_PER_TILE/ 32bit = 32개.
bucketIdx: 특정 조명이 타일의 몇번째 버킷 (몇 번째 정수)에 담기는 지를 나타냅니다.bitIdx: 특정 조명이 해당 버킷에서의 몇번 비트에 해당하는 지 나타냅니다.
- 예시 : 전체 조명 인덱스가 다음과 같다 가정해보겠습니다. ( 조명 인덱스: 3, 45, 900)
- 조명 인덱스 3:
bucketIdx = 3 / 32 = 0bitIdx = 3 % 32 = 3- → 타일의 첫 번째 버킷(bucket 0)에서 3번 비트가 1로 설정 (즉, 2^3 = 8 또는 0x00000008)
- 조명 인덱스 45:
bucketIdx = 45 / 32 = 1bitIdx = 45 % 32 = 13- → 두 번째 버킷(bucket 1)에서 13번 비트가 1로 설정 (2^13=8192 또는 0x00002000)
- 조명 인덱스 900:
bucketIdx = 900 / 32 = 28(28 * 32 = 896)bitIdx = 900 % 32 = 4- → 29번째 버킷(bucket 28)에서 4번 비트가 1로 설정 (2^4 = 16 또는 0x00000010)
- 조명 인덱스 3:
이 값을 복원하여 전체 조명의 인덱스를 구하는 로직은 다음과 같습니다. TileLightMask가 Pixel Shader로 전달될 경우 해당 디코딩 로직은 Pixel Shader에서 수행됩니다.
- 모든 버킷(예, 32개)을 순회
- 각 버킷의 값(예:
bucketValue)을 읽음
- 각 버킷의 값(예:
- 각 버킷의 비트들을 검사
- 0부터 31까지 반복하면서, 특정 비트가 1인지 검사.
- 해당 버킷의 전체 조명 인덱스를 계산
lightIndex = bucketIdx * 32 + bitIdx;
- 1로 설정된 비트에 해당하는 조명 인덱스를 리스트에 추가 또는 저장
- 코드 (구-프러스텀 충돌 및 Depth Masking 후 비트 저장)
[loop] for (uint i = 0; i < NumLights; ++i) { FLightGPU light = LightBuffer[i]; Sphere s; s.c = mul(float4(light.Position, 1), View).xyz; s.r = light.Radius; bool insideFrustum = SphereInsideFrustum(s, frustum, NearZ, FarZ); bool depthOverlap = true; // 2.5D 컬링이 비활성화면 무조건 true if (Enable25DCulling != 0) { // 빛의 Bounding Sphere의 view-space z값 범위 계산 float3 posVS = mul(float4(light.Position, 1), View).xyz; float s_minDepth = posVS.z - s.r; float s_maxDepth = posVS.z + s.r; float normMin = saturate((s_minDepth - NearZ) / (FarZ - NearZ)); // 가까운 곳부터 light float normMax = saturate((s_maxDepth - NearZ) / (FarZ - NearZ)); // light부터 farplane int sphereSliceMin = (int) floor(normMin * NUM_SLICES); // light 포함 X -> 내림 int sphereSliceMax = (int) ceil(normMax * NUM_SLICES); // light 포함 X -> 올림 sphereSliceMin = clamp(sphereSliceMin, 0, NUM_SLICES - 1); // 0~31 인덱스로 클램프 sphereSliceMax = clamp(sphereSliceMax, 0, NUM_SLICES - 1); uint sphereMask = 0; for (int j = sphereSliceMin; j <= sphereSliceMax; ++j) { sphereMask |= (1u << j); } // 깊이 영역이 겹치지 않으면, 해당 라이트는 2.5D 기준에서 컬링됨 depthOverlap = (sphereMask & tileDepthMask) != 0; } if (insideFrustum && depthOverlap) { uint bucketIdx = i / 32; uint bitIdx = i % 32; InterlockedOr(TileLightMask[flatTileIndex * SHADER_ENTITY_TILE_BUCKET_COUNT + bucketIdx], 1 << bitIdx); hitCount++; } }
구현 흐름
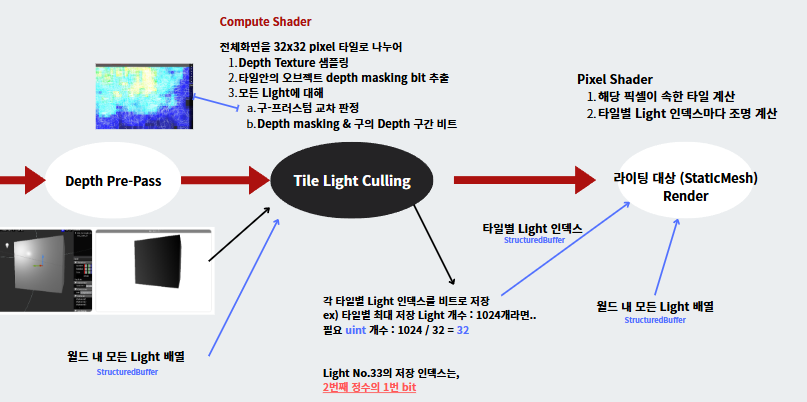
-
모든 물체를 렌더링하기 전 라이팅 대상이 될 오브젝트만 Depth Pre-Pass 후 Depth Texture를 뽑아냅니다
-
모든 전역 조명 정보(여기선 PointLight만을 가정)와 위의 Depth Map을 Compute Shader에 바인딩합니다
→ 각각
StructuredBuffer/Texture2D<float> -
Compute Shader에 대해 한 타일당 수행할 연산을 바인딩 합니다
=
Dispatch(groupSizeX, groupSizeY, 1) -
Compute Shader는 각 타일별 프러스텀 교차, Depth Masking 판정을 수행합니다.
-
Compute Shader는 각 타일별 조명 연산을 할 인덱스 목록 / 디버깅용 히트맵을 내보냅니다
→ 각각
RWStructuredBuffer<uint>/RWTexture2D<float> -
디버깅용 히트맵을 출력합니다.
-
각 타일별 조명 인덱스 목록 / 전역 조명 정보를 라이팅을 수행할 픽셀 셰이더에 넘깁니다
→ 모두
StructuredBuffer -
픽셀 셰이더는
- 현재 SV_POSITION(화면 좌표계)가 몇번째 타일에 위치한지 연산 후 (비트 정보 파싱)
- 해당 타일의 조명에 대해서만 라이팅을 수행합니다.
그 외) 모든 타일의 정수를 OR 연산하여 1인 비트만 그림자 맵을 그리는 최적화를 수행합니다. (후술)
1. GPU 리소스 생성 - UAV, SRV
💡각 타일별 Light Culling 연산을 수행할 Compute Shader에서 필요한 리소스는
1) 조명 정보 (위치, 반지름) - Structured Buffer (읽기 전용)
2) 타일별 라이팅 대상이 될 조명 인덱스 목록 - Unordered Access View (읽기 / 쓰기 가능)
3) 오브젝트 Depth Map (오직 라이팅 대상만을 포함)
입니다. 2번의 경우 Shadow Map을 그릴 Light를 CPU에서 결정하는 데이터로 쓸 수 있음은 물론 Compute Shader에서의 원자적 연산(InterlockedAdd 등)이 용이하기에 RWStructuredBuffer<uint>로 바인딩합니다.
부가1) 각 타일별 충돌 판정이 된 조명 개수를 시각화할 HeatMap - RWTexture2D<float>
부가2) Tile Culling에 필요한 카메라 / 스크린 정보 등 - 상수버퍼
-
변수 설정 - TILE_SIZE는 Real Time Rendering을 참고하여 32로 설정했습니다
SHADER_ENTITY_TILE_BUCKET_COUNT : 만약 한 타일에 1024개의 라이트 개수를 표현하고 싶다면, 비트로 저장하기 위해 필요한 정수 개수 : 1024 / sizeof(uint32) = 32 가 됩니다.
void FTileLightCullingPass::ResizeTiles(const UINT InWidth, const UINT InHeight) { TILE_COUNT_X = (InWidth + TILE_SIZE - 1) / TILE_SIZE; // 타일 개수 - 행 TILE_COUNT_Y = (InHeight + TILE_SIZE - 1) / TILE_SIZE; // 타일 개수 - 열 TILE_COUNT = TILE_COUNT_X * TILE_COUNT_Y; // 전체 타일 개수 SHADER_ENTITY_TILE_BUCKET_COUNT = MAX_LIGHTS_PER_TILE / 32; // 각 타일별로 담을 라이트 인덱스를 담기 위해 필요한 정수 개수 } -
전역 PointLight 배열, SpotLight 배열에 대한 Structured Buffer 크기 설정
각 배열을 담기 위한 Structured Buffer의 ByteWidth = (GPU에 보낼 각 조명 하나의 정보) x 조명 개수가 됩니다. 다음은 PointLight 배열을 담을 StructuredBuffer 생성 코드 입니다.
void FTileLightCullingPass::CreatePointLightBufferGPU() { // ... TObjectRange<UPointLightComp>로 순회하며 Lights 정보 갱신 ... // D3D11_BUFFER_DESC Desc = {}; Desc.BindFlags = D3D11_BIND_SHADER_RESOURCE; Desc.ByteWidth = sizeof(FPointLightGPU) * Lights.Num(); // 전체 바이트 개수 Desc.Usage = D3D11_USAGE_DEFAULT; Desc.StructureByteStride = sizeof(FPointLightGPU); Desc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED; D3D11_SUBRESOURCE_DATA InitData = {}; InitData.pSysMem = Lights.GetData(); // .. 기존 Buffer, SRV Release 코드 생략 .. // HRESULT hr = Graphics->Device->CreateBuffer(&Desc, &InitData, &PointLightBuffer); // .. 오류 처리 코드 생략 .. // D3D11_SHADER_RESOURCE_VIEW_DESC SrvDesc = {}; SrvDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER; SrvDesc.Format = DXGI_FORMAT_UNKNOWN; SrvDesc.Buffer.FirstElement = 0; SrvDesc.Buffer.NumElements = Lights.Num(); hr = Graphics->Device->CreateShaderResourceView(PointLightBuffer, &SrvDesc, &PointLightBufferSRV); // .. 오류 처리 코드 생략 .. // } -
타일별 라이팅 대상이 될 조명 인덱스 목록
- 메모리 절약하고자 각 타일별로 조명 인덱스를 정수의 비트에 압축해 담습니다.
- 이를테면 1번째 타일에 전역 배열 기준 조명 No.1, No.3가 영향을 준다면 (비트 생략…) 0101이 됩니다.
- 인자
- ByteWidth : 타일 전체 개수 x 한 타일별 담을 조명 상한 개수 / 32(비트로 표현하기 때문) x sizof(uint32)
- BindFlags :
D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_SHADER_RESOURCE- Compute Shader의 연산 결과를 담으면서, Pixel Shader에서 파싱되기 위함
- 메모리 절약하고자 각 타일별로 조명 인덱스를 정수의 비트에 압축해 담습니다.
2-1. 부가적으로 Shadow Map 연산에 쓰이기 위한 UAV를 생성합니다.
모든 타일에 대해 특정 조명의 비트가 0이라면, 어느 타일에도 영향을 주지 않는 조명임을 뜻합니다. 즉 라이팅 연산의 대상이 되지 않기 때문에, 그림자 맵을 생성할 이유가 없습니다.
이는 모든 타일의 조명 비트 정보를 OR 연산하여 얻습니다.
Note) 그림자 맵을 그리는 주체는 Draw Call을 호출할 CPU입니다. 따라서 위 정보를 파싱하기 위해 GPU에서 CPU로의 “스테이징”이 필요합니다.
// .. 기존 코드 .. //
// 아래 UAV 해당 Buffer는 모든 Tile에 대해 한 번이라도 영향을 주는 조명 비트를 저장합니다.
BufferDesc.ByteWidth = sizeof(uint32) * SHADER_ENTITY_TILE_BUCKET_COUNT;
SRVDesc.Buffer.NumElements = SHADER_ENTITY_TILE_BUCKET_COUNT;
UAVDesc.Buffer.NumElements = SHADER_ENTITY_TILE_BUCKET_COUNT;
// Culled PointLight Index Buffer
hr = Graphics->Device->CreateBuffer(&BufferDesc, nullptr, &CulledPointLightIndexMaskBuffer);
hr = Graphics->Device->CreateUnorderedAccessView(CulledPointLightIndexMaskBuffer, &UAVDesc, &CulledPointLightIndexMaskBufferUAV);
// .. 생략 - 각각에 대한 오류 처리 코드 .. //2. Compute Shader
💡Tile based Light Culling 연산을 수행하기 위해서 각 타일별로 Frustum을 설정하고 조명의 구(Bounding Sphere)와의 충돌 계산이 필요합니다.
1. 연산을 병렬적으로 하기 위해 Compute Shader로 각 타일을 한 그룹으로 묶어 연산 수행합니다.
2. 해당 구간의 Depth 구간을 병렬적으로 추출하기 위해 1x1px 씩 스레드가 맡아 Depth Map 샘플링을 수행합니다.
3. 각 스레드의 Depth 구간을 타일 단위 공통의 [minZ, maxZ]로 동기화 시킨 후, 타일 프러스텀-구 충돌 및 깊이 비트 마스킹 연산을 수행합니다.
Compute Shader는 다른 프로그램 가능 파이프라인 단계들과 근본적으로 다릅니다. 다른 단계로부터 입력을 받지 않으며, 출력을 다른 단계에 (명시하지 않는 이상) 넘겨주지도 않습니다.
몇 가지 시스템 값 의미소들은 입력 매개변수로 받을 수 있지만, 그 외의 모든 자료 입출력은 자원을 통해서만 일어납니다.
즉, 아래의 Light Culling 연산은 하나의 프로그램 안에서 완결적으로 이뤄집니다.
2-1. Dispatch(GroupSizeX, GroupSizeY, 1)
한 개의 스레드 그룹은 32x32 픽셀 영역을 처리한다는 가정 하에, 적절한 GroupSizeX / Y를 계산하여 각 행 / 열마다 몇 번의 타일로 나눠지는지 계산 후, Dispatch를 호출합니다.
- 아래의 Dispatch() 함수를 호출하면, 세 인자를 곱한 값의 스레드 그룹 개수가 생성됩니다.
- 한 개의 그룹은 32x32 픽셀(타일 1개)의 타일 프러스텀 연산, 한 개의 스레드는 1x1 픽셀의 Depth Map 샘플링에 사용됩니다.
- 이를 테면 [2, 1, 1]의
GroupID를 가진 스레드 그룹은 스크린 좌표 기준 [64, 32] ~ [95, 63] 구간의 정사각형 타일에 대한 연산을 수행합니다.
- [32, 32, 1]의
GroupThreadID를 가진 스레드는 [95, 63] 의 1x1px을 맡아 Depth Map 샘플링을 수행합니다.- Group ID, Thread ID에 대한 자세한 설명은 링크를 참고 부탁드립니다
void FTileLightCullingPass::Dispatch(const std::shared_ptr<FEditorViewportClient>& Viewport) const
{
// 한 스레드 그룹(groupSizeX, groupSizeY)은 32x32픽셀 영역처리
const UINT GroupSizeX = (Viewport->GetD3DViewport().Width + TILE_SIZE - 1) / TILE_SIZE;
const UINT GroupSizeY = (Viewport->GetD3DViewport().Height + TILE_SIZE - 1) / TILE_SIZE;
// 중략 .. 리소스 및 Shader 바인딩 //
Graphics->DeviceContext->Dispatch(GroupSizeX, GroupSizeY, 1);
// .. UAV, SRV, 상수버퍼 바인딩 해제 .. //
}- 타일 프러스텀 뿐만 아니라 타일 안의 Depth Map Sampling 시의 빠른 병렬 처리를 위해
num_thread=TILE_SIZE로 두었습니다. 타일 프러스텀 연산만을 수행한다면 스레드 개수는 크게 유의미하지 않을 것입니다.[numthreads(TILE_SIZE, TILE_SIZE, 1)] void mainCS(uint3 groupID : SV_GroupID, uint3 dispatchID : SV_DispatchThreadID, uint3 threadID : SV_GroupThreadID)
2-2. Tile의 Depth 구간 추출
- 2.5D Culling을 위해서 실제 오브젝트가 Tile 내에 위치한 Depth 구간을 샘플링할 것입니다
-
Depth Pre-Pass를 통해 (라이팅 대상이 되는) 오브젝트만을 렌더한 Depth Map Texture를 병렬적으로 샘플링 및 구간을 추출합니다.
groupshared uint tileDepthMask; // 각 타일 별 오브젝트의 Depth Mask groupshared uint groupMinZ; // 각 타일별 minZ groupshared uint groupMaxZ; // 각 타일별 maxZ groupshared uint hitCount; // 각 타일별 Light 교차 수 uint2 tileCoord = groupID.xy; uint2 pixel = tileCoord * TILE_SIZE + threadID.xy; float minZ = NearZ; // 상수 버퍼로부터 대입 (지역 변수로 복사하면 모니터링에 용이) float maxZ = FarZ; if (threadID.x == 0 && threadID.y == 0) { tileDepthMask = 0; groupMinZ = 0x7f7fffff; groupMaxZ = 0x00000000; } hitCount = 0; GroupMemoryBarrierWithGroupSync(); float depthSample = 1.0f; float linearZ = FarZ; if (Enable25DCulling != 0 && all(pixel < ScreenSize)) { depthSample = gDepthTexture[pixel]; if (depthSample < 1.0f) { linearZ = (NearZ * FarZ) / (FarZ - depthSample * (FarZ - NearZ)); InterlockedMin(groupMinZ, uint(linearZ)); InterlockedMax(groupMaxZ, uint(linearZ)); } } GroupMemoryBarrierWithGroupSync(); if (Enable25DCulling != 0 && groupMaxZ > groupMinZ) { minZ = float(groupMinZ); maxZ = float(groupMaxZ); }
-
2-2-1. Depth Mask with Margin
- Depth Map은 비선형적일 뿐더러 샘플링 되는 간격이 불규칙하고 (픽셀 기준), 한 타일 안에 오브젝트 Depth 샘플 수가 불안정할 수 있습니다. 이 때의 Depth 구간 [minZ, maxZ]가 너무 좁을 경우 라이트와의 깊이 마스킹을 제대로 수행하지 못한 문제가 있었습니다. (조명 연산 또한 불안정해지는 Dithering 현상 발생) Margin을 둔 Z구간으로 보정 후, 각 스레드 별로 소속 타일에 대한 오브젝트 깊이 마스크 OR 연산을 원자적으로 수행했습니다.
// 너무 좁은 분포라면 아예 NearZ, FarZ로 늘려버리는 예시입니다 // 라이팅을 아예 안하는 Artifact를 줄이나, 이러한 분포를 보이는 타일 수가 많을수록 // 조명 연산 부담이 커집니다 (개선 필요사항) if (Enable25DCulling != 0 && depthSample < 1.0f) { float rangeZ = maxZ - minZ; if (rangeZ < 1e-3) { minZ = NearZ; maxZ = FarZ; rangeZ = maxZ - minZ; } float sliceNormZ = saturate((linearZ - minZ) / rangeZ); int sliceIndex = clamp((int) floor(sliceNormZ * NUM_SLICES), 0, NUM_SLICES - 1); InterlockedOr(tileDepthMask, (1u << sliceIndex)); } GroupMemoryBarrierWithGroupSync();
2-3. Light Culling
Cull Light 함수는
1. 타일 프러스텀 내에 구가 존재하는지
2. 타일 안의 오브젝트 깊이 구간과 조명의 깊이 구간이 겹치는지 AND 비트 연산을 수행합니다.
컬링 여부는 0 또는 1로 구분되어, 해당 타일의 bucket 번째 정수의 bitIdx 번째 비트에 저장됩니다.
void CullLight(uint index, float3 lightVSPos, float radius, Frustum frustum, float minZ, float maxZ, uint flatTileIndex, RWStructuredBuffer<uint> MaskBuffer, RWStructuredBuffer<uint> CulledMaskBuffer)
{
Sphere s = { lightVSPos, radius };
if (!SphereInsideFrustum(s, frustum, NearZ, FarZ))
return;
if (Enable25DCulling != 0 && !ShouldLightAffectTile(lightVSPos, radius, minZ, maxZ, tileDepthMask))
return;
uint bucketIdx = index / 32; // 각 타일별의 몇 번째 정수 - bucket
uint bitIdx = index % 32; // 해당 정수의 몇 번째 비트 - bitIdx
InterlockedOr(MaskBuffer[flatTileIndex * SHADER_ENTITY_TILE_BUCKET_COUNT + bucketIdx], 1 << bitIdx);
InterlockedAdd(hitCount, 1);
InterlockedOr(CulledMaskBuffer[bucketIdx], 1 << (index % 32));
}2-3-1. Tile Frustum
1차적으로 각 한 타일의(한 스레드 그룹의) Tile Frustum을 계산합니다.
1. Tile Frustum의 ClipSpace 좌표 → View Space 좌표로 변환하여 평면 및 AABB를 계산합니다.
- 우선 Tile Frustum을 이루는 4개 평면을 역투영 변환으로 계산합니다.
- View Space Tile Frustum을 이룰 8개의 꼭짓점 계산 후, 평면 4개를 계산합니다.
float2 tileMin = tileCoord * TileSize; // NDC 기준 해당 타일의 Min 좌표
float2 tileMax = tileMin + TileSize; // NDC 기준 해당 타일의 Max 좌표
float3 viewCorners[8]; // View space Tile Frustum을 이루는 8개 꼭짓점
[unroll]
for (uint i = 0; i < 4; ++i)
{
float2 uv = float2((i & 1) ? tileMax.x : tileMin.x, (i & 2) ? tileMax.y : tileMin.y) / ScreenSize;
uv.y = 1.0 - uv.y;
float4 clipNear = float4(uv * 2.0 - 1.0, NearZ, 1.0);
float4 clipFar = float4(uv * 2.0 - 1.0, FarZ, 1.0);
float4 viewNear = mul(clipNear, InverseProjection);
float4 viewFar = mul(clipFar, InverseProjection);
viewCorners[i + 0] = viewNear.xyz / viewNear.w;
viewCorners[i + 4] = viewFar.xyz / viewFar.w;
}
// 각 평면에 대한 설정 (평면은 법선 벡터 N 및 스칼라 D로 이뤄짐)
Frustum frustum;
frustum.planes[0] = ComputePlane(viewCorners[0], viewCorners[2], viewCorners[6]);
frustum.planes[1] = ComputePlane(viewCorners[3], viewCorners[1], viewCorners[7]);
frustum.planes[2] = ComputePlane(viewCorners[1], viewCorners[0], viewCorners[5]);
frustum.planes[3] = ComputePlane(viewCorners[2], viewCorners[3], viewCorners[6]);
2-3-2. Tile Frustum - Sphere(Light) Collision
- 모든 조명이 반지름을 갖는 구란 가정 하에, 타일 프러스텀과의 충돌을 계산합니다.
bool SphereInsidePlane(Sphere sphere, Plane plane)
{
return dot(plane.N, sphere.c) - plane.d < -sphere.r;
}
bool SphereInsideFrustum(Sphere sphere, Frustum frustum, float zNear, float zFar) // this can only be used in view space
{
bool result = true;
result = ((sphere.c.z + sphere.r < zNear || sphere.c.z - sphere.r > zFar) ? false : result);
result = ((SphereInsidePlane(sphere, frustum.planes[0])) ? false : result);
result = ((SphereInsidePlane(sphere, frustum.planes[1])) ? false : result);
result = ((SphereInsidePlane(sphere, frustum.planes[2])) ? false : result);
result = ((SphereInsidePlane(sphere, frustum.planes[3])) ? false : result);
return result;
}2-3-3. Geometry Depth Mask & Light Depth Mask
- 조명의 깊이 구간과 타일 내 오브젝트 깊이 구간을 (32비트) AND 연산으로 교차 판정 수행합니다.
- 조명이 교차한 깊이 구간에 대한 정보를 비트로 담습니다.
-
유의) 조명(구)이 32개로 나눠진 깊이 구간에 걸칠 수 있기 때문에, 구의 최소 깊이와 최대 깊이를 각각 내림 / 올림 연산하여 [floor(최소 깊이), ceil(최대 깊이)]에 해당하는 비트를 모두 1로 만듭니다
bool ShouldLightAffectTile(float3 lightVSPos, float radius, float minZ, float maxZ, uint depthMask) { if (depthMask == 0) return false; float s_minDepth = lightVSPos.z - radius; float s_maxDepth = lightVSPos.z + radius; if (s_maxDepth < minZ || s_minDepth > maxZ) return false; float normMin = saturate((s_minDepth - minZ) / max(1e-5, maxZ - minZ)); float normMax = saturate((s_maxDepth - minZ) / max(1e-5, maxZ - minZ)); // 나눠진 32개 구간에 걸칠 수 있으므로 각각 내림, 올림 연산으로 바운드시킵니다 int sliceMin = clamp((int) floor(normMin * NUM_SLICES), 0, NUM_SLICES - 1); int sliceMax = clamp((int) ceil(normMax * NUM_SLICES), 0, NUM_SLICES - 1); uint sphereMask = 0; [unroll] for (int i = sliceMin; i <= sliceMax; ++i) sphereMask |= (1u << i); return (sphereMask & depthMask) != 0; }
-
2-4. Culling Result
- 위 일련의 Culling 과정을 각 스레드가 병렬적으로 연산하고, HeatMap 기록을 수행합니다.
for (uint i = threadFlatIndex; i < NumPointLights; i += totalThreads)
{
float3 lightVSPos = mul(float4(PointLightBuffer[i].Position, 1), View).xyz;
CullLight(i, lightVSPos, PointLightBuffer[i].Radius, frustum, minZ, maxZ, flatTileIndex, PerTilePointLightIndexMaskOut, CulledPointLightIndexMaskOUT);
}
// .. 비슷한 연산을 SpotLight에 대해서도 수행 .. //
GroupMemoryBarrierWithGroupSync();
WriteHeatmap(tileCoord, threadFlatIndex); 3. Pixel Shader - Parsing Lights Per Tile
Pixel Shader는 Compute Shader 연산 결과 (타일별 조명 인덱스 목록을 비트로 담은)와 전역 조명 배열을 바인딩 받습니다.
이제 특정 Mesh를 그릴 때에, Pixel Shader에서 다음을 수행합니다.
1. 해당 SV_POSITION을 통해 몇 번째 타일에 위치한지 계산
2. 해당 타일의 조명 인덱스 목록 중 비트가 1인 것만에 대해서 Lighting 연산을 수행합니다.
- Pixel Shader에서의 SV_POSITION은 화면 픽셀 좌표계를 의미합니다. 다음은 현재 픽셀이 속한 타일 계산하여 Lighting 함수에 인자로 넘기는 코드입니다.
// ... 픽셀 셰이더 main 함수 .. //
// 현재 픽셀이 속한 타일 계산 (input.position = 화면 픽셀좌표계)
uint2 PixelCoord = uint2(Input.Position.xy);
uint2 TileCoord = PixelCoord / TileSize; // 각 성분별 나눔
uint TilesX = ScreenSize.x / TileSize.x; // 한 행에 존재하는 타일 수
uint FlatTileIndex = TileCoord.x + TileCoord.y * TilesX;
// ... if it's Lit Mode ... //
float3 LitColor = Lighting(Input.WorldPosition, WorldNormal, Input.WorldViewPosition, DiffuseColor, FlatTileIndex).rgb;- Lighting 연산 시, 해당 픽셀이 속한 타일에 영향을 주는 조명만을 (비트가 1인) 연산합니다.
// .. Lighting 함수 내부 .. //
int BucketsPerTile = MAX_LIGHT_PER_TILE / 32;
int StartIndex = TileIndex * BucketsPerTile;
for (int Bucket = 0; Bucket < BucketsPerTile; ++Bucket) {
int PointMask = PerTilePointLightIndexBuffer[StartIndex + Bucket];
for (int bit = 0; bit < 32; ++bit) {
if (PointMask & (1u << bit)) {
// 전역 조명 인덱스는 bucket * 32 + bit 로 계산됨.
// 예외처리 - 전역 조명 인덱스가 총 조명 수보다 작은 경우에만 라이팅 계산
int GlobalPointLightIndex = Bucket * 32 + bit;
if (GlobalPointLightIndex < MAX_LIGHT_PER_TILE)
{
FinalColor += PointLight(GlobalPointLightIndex, WorldPosition, WorldNormal, WorldViewPosition, DiffuseColor);
}
}
// ... SpotLight도 동일하게 수행 ... //
}
}결과


개선 과정
-
초기 과도히 넉넉한 Z구간 [NearZ, FarZ] → Depth Map 내 오브젝트의 깊이 구간 [minZ, maxZ]로 조정하여 32개 슬라이스로 나누자, 불안정한 슬라이싱과 깊이 값에 의해 Dithering 현상이 나타났습니다. 특히 라이팅 계산이 이뤄지지 않는 픽셀이 도드라지는 문제가 있었습니다.


이는 Z 구간이 epsilon보다 작을 때에 마진을 주어 정상적인 라이팅을 시키도록 고쳤습니다. 기존 라이팅이 아예 안되었던 타일들의 Z 구간을 넉넉히 주어 아예 비는 HeatMap 타일이 없도록 한 것입니다. (이 매직넘버는 정확한 Z구간 계산과 Z 분포로 해결이 필요합니다)
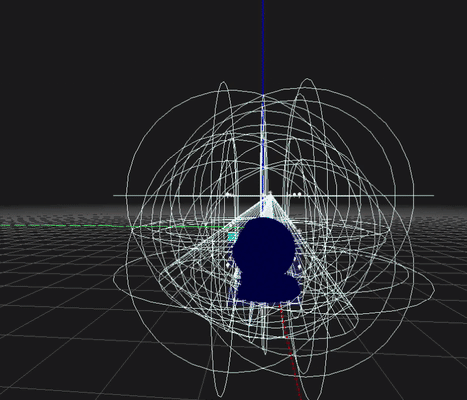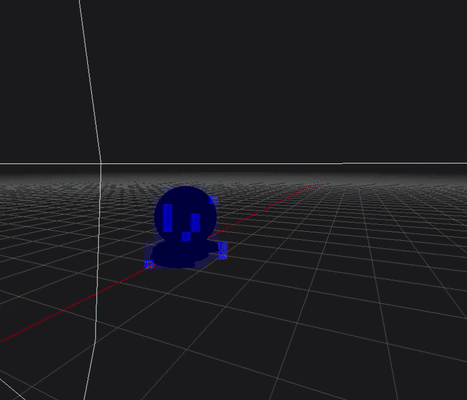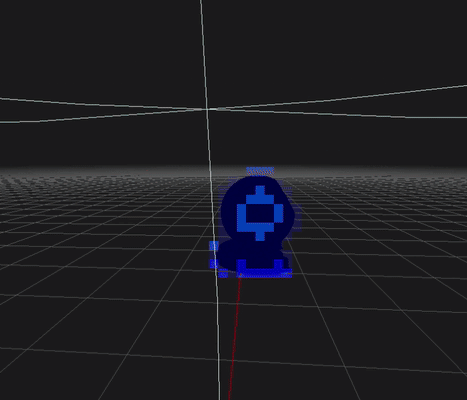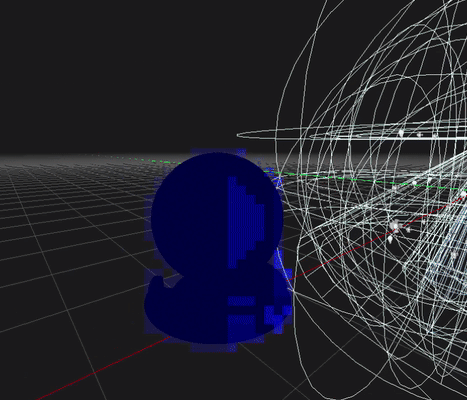
-
병렬 연산을 최대한 적용하여 Compute Shader의 비용을 줄이고자 했습니다.

-
아래는 최종적으로 오브젝트와 조명의 깊이 구간까지 고려한 데모 이미지입니다. 아래 이미지는 오브젝트와 조명과 멀찍이 떨어져 있어 교차횟수가 적게 표기됩니다. (파랑색)
(근본적으로 멀리 떨어져 있으면 교차 횟수가 증가하는 2.5D Culling 한계가 있습니다)

디버깅 과정
-
Depth Pre-Pass에서 올바른 Depth Map을 저장하는지 확인 유효한지 확인
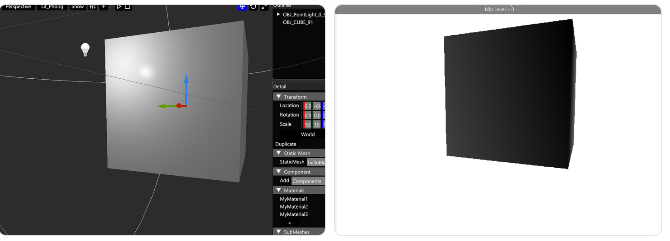
- 오직 라이팅 대상이 될 Static Mesh의 Depth만을 출력하기 위함
- Depth Map 값을 선형화 하지 않고도 NSight Graphics에서 확인 가능
- 해당 Depth Map이 SRV로의 바인딩 여부 또한 RenderDoc / NSight 에서 확인 가능
- 오직 라이팅 대상이 될 Static Mesh의 Depth만을 출력하기 위함
-
Compute Shader 컴파일 및 히트맵 값을 출력 테스트
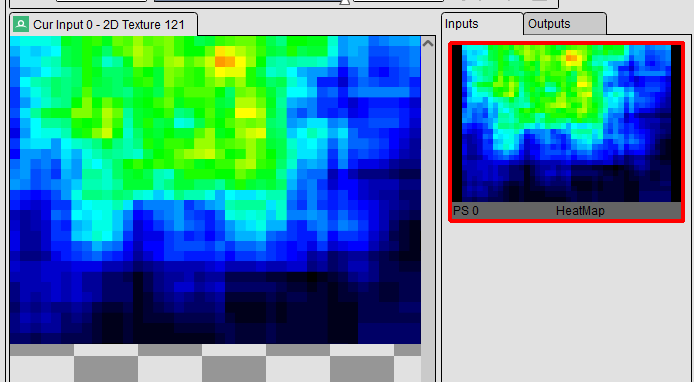
- 간단한 후처리용 Quad로 히트맵을 덧붙여(lerp) 그렸습니다
-
Compute Shader가 유효한 타일 프러스텀 판정에 따른 히트맵 출력 확인

- RenderDoc의 Compute Shader Debug : 스레드 인덱스 지정 및 값 관찰
-
Compute Shader에 Depth Masking 로직도 추가하여 확인
-
Pixel Shader에 유효한 조명 정보, 타일별 조명 인덱스 목록이 저장되는지 확인. (via NSight)
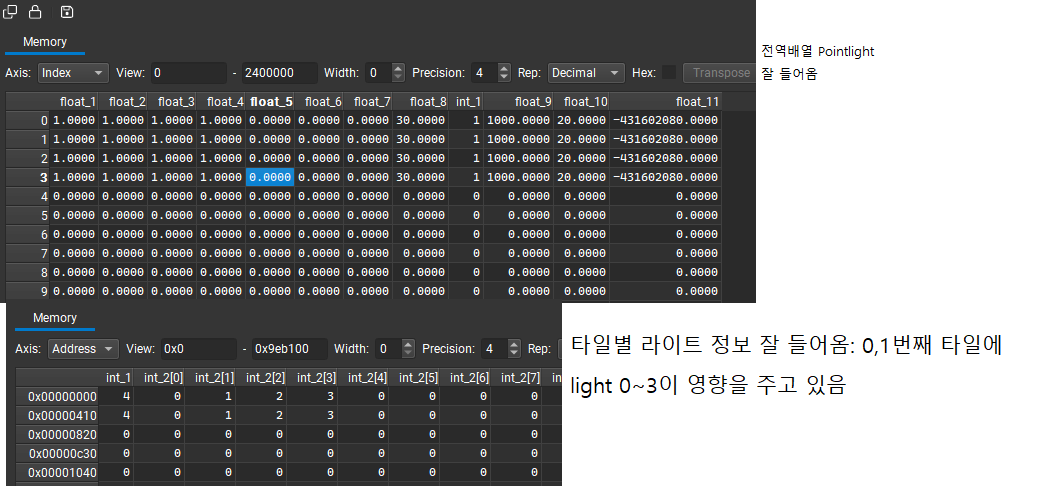
-
Shader Hot-Reload
Compute Shader 또한 적용시켜 프로그램 실행 중에 수정하면 변경 내용이 컬링 연산에 적용되도록 하였습니다. 결과적으로 Debug Iteration Cost를 아꼈습니다.
-
Timer Monitor
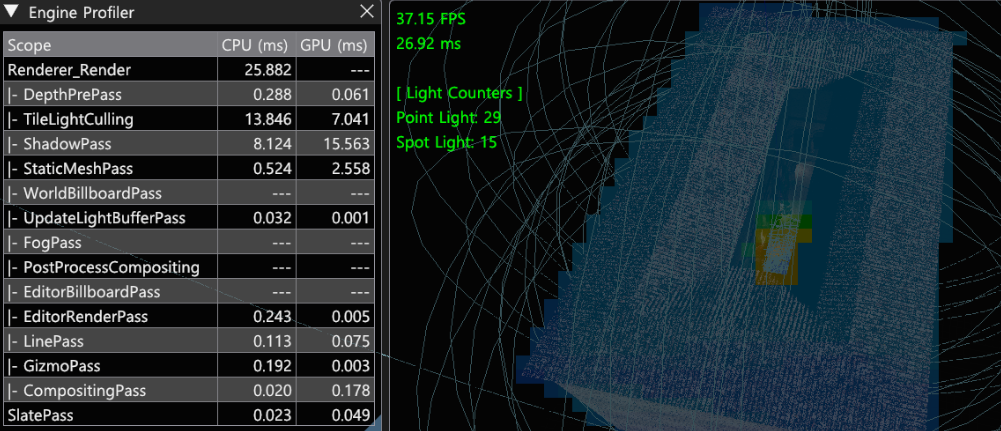
최초 구현 후 파싱 연산으로 인해 프레임 드랍이 일어났습니다. Light Culling Pass에 대한 비용 측정을 위해 RenderDoc의 GPU Timer, CPU 실행 시간을 보기 위한 Timer 측정으로 패스 내의 스테이징 과정이 가장 비용이 많이 듦을 파악할 수 있었습니다.
한계
- 타일 프러스텀의 경계는 넉넉히(거칠게) 잡히기 때문에, 2.5D Culling을 통해 Depth Masking을 하여도 False Positive가 생기는 한계가 있습니다.
- Z Depth Texture에 대한 구간 마진 조정 / 근본적인 샘플링 값 Dithering 완화가 필요해 보입니다.
이는 실제 픽셀에는 영향을 주지 않는 조명도, 타일 프러스텀 안에 걸려듦을 일컫습니다.
위 경우 Z 슬라이스 등을 더 잘게 쪼개는 클러스터링 방식, 또는 타일 AABB - 구 충돌 연산으로 바꾸어 개선이 필요해 보입니다. (레퍼런스 링크 참고)
기타 시도 : SpotLight - Cone Culling
💡3D 상의 Cone Culling이란 까다로운 문제를 해결하고자 했습니다.
1. 각 (스레드)픽셀별 타일 프러스텀을 32개 z슬라이스로 나눈 후의 AABB를 바운딩 구로 감쌉니다.
2. 각 구와 View Space 상의 원뿔과의 최단 거리를 구합니다.
구와 원뿔의 관계는 다음 3가지 경우로 나뉠 수 있습니다. (아래는 원뿔이 Culling 될 것입니다.)
- 구가 원뿔의 정면에 있으나, 구의 반지름 + 원뿔의 반지름 < 실제 구의 중심과 원뿔 꼭짓점의 거리
- 구와 원뿔이 반대 방향에 있고, 원뿔 꼭짓점에서 구의 중심으로 향하는 벡터를 원뿔 축의 음수방향으로 정사영했을 때의 거리 < 구의 중심과 원뿔 꼭짓점과의 거리
- 구와 원뿔 측면의 최단 거리가 0보다 큰 경우
현재 구현 상태는 SpotLight 또한 바운딩 볼륨 구로 가정하였습니다만, 이는 부정확한 충돌을 야기할 수 있습니다. 이는 Spot Light의 각도가 각각 둔각, 예각일 때에 바운딩 볼륨 구는 넓게, 특히 원뿔의 축 반대 방향을 넉넉히 감싸기 때문에 False Postive를 대폭 생성합니다.
매우 넉넉한 판정으로 인해 발생하는 문제를 다음 링크에선 발상을 전환하여 해결할 수 있음을 보입니다. 요지는,
원뿔의 측면과 구의 가장 가까운 수직거리를 계산하는 것입니다.
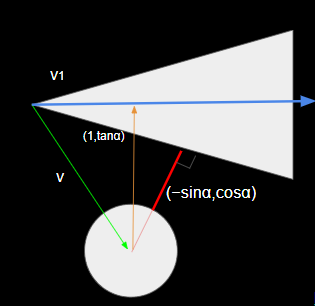
위와 같은 그림에서 원뿔의 측면과 구의 최단거리는 다음과 같이 정의됩니다.
- 항상 원뿔의 꼭짓점을 원점으로 두어 구의 좌표를 정의한다. (이는 항상 d = N.P가 양수인 효과를 준다 )
- 원뿔의 측면을 정의하는 벡터 (1, tan(a))를 정의하고 측면의 법선벡터를 단위벡터로 정의한다 (-sina, cosa)
- 원뿔의 측면의 법선벡터 N과 구의 상대좌표(원뿔의 꼭짓점에 대한)를 내적하여 최단 거리를 구한다
위 과정은 3D 상의 원뿔과 구를 교차 판정하는 데에도 유효합니다 (원뿔과 구는 축에 정렬되있고 중심 기준 대칭이란 특수한 조건을 모두 만족합니다)
여기에 추가적으로 구가 원뿔과 완전히 정면, 반대면에 위치할 때만을 고려하면 빠른 연산과 정교한 교차 판정이란 두 마리 토끼를 잡을 수 있습니다.
아래는 위 수식을 통해 수행한 카메라 구 - 원뿔 교차 데모 영상입니다. 영역 안에 들어오면 파랑색으로 HeatMap을 표기했습니다.

References
- Harada, Takahiro. "A 2.5D Culling for Forward+." SIGGRAPH Asia 2012
- Improved Culling for Tiled and Clustered Rendering
- WickedEngine - Optimizing tile-based light culling
- Cull that Cone - https://bartwronski.com/2017/04/13/cull-that-cone/
- Akenine-Möller, Tomas, et al. Real-Time Rendering. 4th ed., CRC Press, 2018.
- Forward vs Deferred vs Forward+ Rendering with DirectX 11
- GDC 2015 - Advancements in Tiled-Based Compute Rendering
- A Primer On Efficient Rendering Algorithms & Clustered Shading.
- https://wickedengine.net/2019/02/thoughts-on-light-culling-stream-compaction-vs-flat-bit-arrays/
- Optimizing spotlight intersection in tiled/clustered light culling
