
(before, after만 확실하게 보고 싶으시다면,, #비포 애프터를 먼저 보시면 됩니다 ^_^)
🤔 백엔드는 빨라졌는데,,, 프론트는?
저번 글에서 백엔드 리팩토링으로 API 응답 속도를 개선한 얘기를 했었습니다. 백엔드 리팩토링으로 오류가 없어지고 성능 자체는 좋아지긴 했지만, 막상 사용자 입장에서 보면 여전히 느리다는 느낌이 들더라고요.
백엔드에서 엄청 빠르게 응답을 준다고 해도, 프론트엔드에서 매번 새로 데이터를 가져오고, 로딩 중에 아무것도 안 보여주면... 답답하기 때문에,,, 프론트도 함께 리팩토링 해주었습니다.
(글 너무 길어져서 나눈 거 맞음)
여전히 남아있던 문제들
- 🔄 페이지 이동할 때마다 똑같은 데이터를 다시 가져옴
- ⏳ 로딩 중에 빈 화면만 보여줌 (안 좋은 UX)
- 🖼️ 이미지들이 순차적으로 하나씩 로드됨
- 📱 무한 스크롤 시 데이터가 꼬이는 경우 발생
- ❌ 에러 처리가 일관적이지 않음
특히 "홈 → 디테일 → 뒤로가기 → 홈"을 할 때마다 똑같은 아티클 리스트를 매번 다시 불러오는 게 너무 비효율적이라는 생각이 들었습니다.
그리고 프론트 리팩토링은 무조건 필요하다고 생각했던 게, 다른 사이트도 아니고 UX 관련 사이트인데 UX는 최소한은 챙겨야하지 않나 싶어 UX 개선을 가장 중요하게 두고 리팩을 진행했습니다.
그래서 결국 React Query를 도입하기로 했습니다..!
🎯 React Query를 선택한 이유
사실 처음엔 아시다시피 빠르게 최소한의 기능만 배포하는 토이 프로젝트 느낌이었기 때문에 "굳이 라이브러리를 추가해야 하나?" 싶었습니다. 그런데 인턴 하면서 React Query를 직접 도입해봤고, 그 때 직접 구현하는 것보다 훨씬 많은 이점을 느꼈기 때문에 무조건 도입해야겠다고 생각했습니다.
🏗️ 프론트엔드 리팩토링 전략
먼저, 백엔드에서 제공하는 API 정리
백엔드 리팩토링으로 어떤 기능들이 생겼는지 정리해보자면 아래와 같습니다.
| 기능 | Before (JSON) | After (Supabase + NestJS) |
|---|---|---|
| 데이터 로딩 | 전체 데이터 한 번에 | 페이지네이션 (10개씩) |
| 필터링 | 프론트에서 처리 | API에서 처리 |
| 정렬 | 프론트에서 처리 | API에서 처리 (DB 쿼리) |
| 검색 | 전체 데이터에서 검색 | DB에서 ILIKE 검색 |
| 이미지 | 외부 호스팅 (느림) | S3 + CloudFront (빠름) |
백엔드 API 예시
GET /api/articles?
page=1
&limit=10
&keywordId=keyword_001
&productId=product_002
&uxEvaluation=Good UX
&sortBy=created_at
&sortOrder=desc
// 응답
{
"articles": [...], // 딱 10개만
"total": 156, // 전체 개수
"page": 1,
"totalPages": 16,
"hasMore": true // 다음 페이지 존재 여부
}
이제 프론트엔드에서 이걸 제대로 활용하면 됩니다.
1단계: 백엔드 API 활용 - 페이지네이션 구현
Before: 전체 데이터 로딩
// 이전 방식
const fetchAllArticles = async () => {
const response = await fetch('/api/articles'); // ex. 전체 200개
const allArticles = await response.json();
// 프론트에서 필터링
const filtered = allArticles.filter(article =>
article.keywordId === selectedKeyword
);
// 프론트에서 정렬
const sorted = filtered.sort((a, b) =>
new Date(b.createdAt) - new Date(a.createdAt)
);
return sorted;
};
After: 백엔드 API 활용
// 개선된 방식
const fetchArticles = async (page: number, filters: any) => {
const params = new URLSearchParams({
page: page.toString(),
limit: '10',
...(filters.keywordId && { keywordId: filters.keywordId }),
...(filters.sortBy && { sortBy: filters.sortBy }),
});
const response = await fetch(`/api/articles?${params}`);
return response.json(); // 딱 10개만
};
이제:
- ✅ 10개만 다운로드 (가벼움)
- ✅ 필터링/정렬은 DB에서 처리 (빠름)
- ✅ 인덱싱된 DB 쿼리 활용 (효율적)
🚀 React Query 도입 과정
백엔드 API를 활용하는 것만으로도 많이 개선되었는데, 여기에 React Query를 더하면 캐싱까지 되어 성능을 향상시킬 수 있었습니다.
1단계: React Query 기본 설정
먼저 App.tsx에서 이런 식으로 QueryClient를 설정했습니다.
import { QueryClient, QueryClientProvider } from "@tanstack/react-query";
import { ReactQueryDevtools } from "@tanstack/react-query-devtools";
const queryClient = new QueryClient({
defaultOptions: {
queries: {
staleTime: 5 * 60 * 1000, // 5분
gcTime: 10 * 60 * 1000, // 10분
retry: 1,
},
},
});
function App() {
return (
<QueryClientProvider client={queryClient}>
<LanguageProvider>
<AuthProvider>
<ModalProvider>
<Router />
<SourceInfoModal />
<ReactQueryDevtools initialIsOpen={false} />
</ModalProvider>
</AuthProvider>
</LanguageProvider>
</QueryClientProvider>
);
}
캐싱 전략
staleTime: 5분→ 5분 동안은 재요청 안 함gcTime: 10분→ 10분 후 메모리에서 제거retry: 1→ 네트워크 에러 시 한 번만 재시도
2단계: Query Key 체계적으로 관리
Query Key를 일관되게 관리하지 않으면 나중에 캐시 무효화할 때 헷갈리기 때문에 공식 문서 참고해서 query key를 최대한 효율적으로 관리할 수 있도록 하였습니다.
export const articleQueryKeys = {
all: ["article"] as const,
list: () => [...articleQueryKeys.all, "list"] as const,
detail: (articleId: string) =>
[...articleQueryKeys.all, "detail", articleId] as const,
uxEvaluationCount: () =>
[...articleQueryKeys.all, "uxEvaluationCount"] as const,
};
이런 식으로 구현해두면, 아래와 같이 사용하도록 했습니다.
// 모든 아티클 쿼리 무효화
queryClient.invalidateQueries({ queryKey: articleQueryKeys.all });
// 리스트만 무효화
queryClient.invalidateQueries({ queryKey: articleQueryKeys.list() });
// 특정 아티클만 무효화
queryClient.invalidateQueries({
queryKey: articleQueryKeys.detail("article_001")
});
3단계: Custom Hook으로 쿼리 로직 분리
그리고 각 기능별로 Custom Hook을 만들어서 쿼리 로직을 최대한 컴포넌트에서 분리했습니다.
예를 들면 아티클 리스트를 조회해올 때, 수정된 api에 맞춰 무한 스크롤 가능하도록 해두었는데, 그걸 훅으로 분리해서 사용하였습니다.
import { useInfiniteQuery } from "@tanstack/react-query";
import { manageArticleApi, articleQueryKeys } from "@/entities/article";
export const useArticleListQuery = ({ selectedSortType }) => {
const [searchParams] = useSearchParams();
return useInfiniteQuery({
queryKey: [
...articleQueryKeys.list(),
searchParams.toString(), // 필터가 바뀌면 새 쿼리
selectedSortType,
],
queryFn: async ({ pageParam = 1 }) => {
// 백엔드의 페이지네이션 API 호출
const result = await manageArticleApi.getArticleListPaginated(
pageParam,
10,
searchParams.toString(),
sortParams.sortBy,
sortParams.sortOrder,
);
return result;
},
getNextPageParam: (lastPage) => {
// 백엔드에서 제공하는 hasMore 활용
return lastPage.hasMore ? lastPage.page + 1 : undefined;
},
initialPageParam: 1,
staleTime: 5 * 60 * 1000,
});
};아티클에 대한 상세 정보를 확인해올 때에도, 아래와 같이 훅으로 분리하였습니다.
이외에도 최대한 모든 기능을 ui와 분리시키고, 재사용할 수 있도록 훅으로 분리해두었습니다.
export const useArticleDetailQuery = (articleId: string | undefined) => {
return useQuery({
queryKey: articleQueryKeys.detail(articleId!),
queryFn: () => manageArticleApi.getArticle(articleId!),
enabled: !!articleId, // articleId가 있을 때만 실행
staleTime: 5 * 60 * 1000,
});
};
4단계: 이미지도 Query로 관리
그리고 가장 중요한 이미지….. 사실 이 모든 리팩토링이 이미지에서 시작되었다고 해도 과언이 아닌데,
백엔드에서 S3 + CloudFront로 리팩했기 때문에 이미 로딩 속도가 빨라지기는 했지만, 여기에 프론트에서 캐싱까지 더해서 최대한의 효율을 끌어내려 하였습니다.
export const useImageLoad = (imageUrl: string | undefined) => {
return useQuery({
queryKey: ["image", imageUrl],
queryFn: () => loadImage(imageUrl!),
enabled: !!imageUrl,
staleTime: Infinity, // 이미지는 한번 로드되면 영구 캐싱
gcTime: 24 * 60 * 60 * 1000, // 24시간 캐시 유지
});
};5단계: ErrorBoundary로 에러 처리 통일
이전에는 각 컴포넌트마다 try-catch로 에러 처리를 했는데, (당연히) 코드가 지저분하고 일관성이 없었습니다. 그래서 기왕 react query 도입한 거, ErrorFallback도 공통으로 사용할 수 있게 컴포넌트로 분리해주었습니다.
import { useQueryErrorResetBoundary } from "@tanstack/react-query";
export const QueryErrorFallback = ({
error,
resetError,
title = "데이터를 불러올 수 없습니다",
description,
buttonText = "다시 시도",
}: QueryErrorFallbackProps) => {
const { reset } = useQueryErrorResetBoundary();
const handleRetry = () => {
if (resetError) {
resetError();
} else {
reset(); // 쿼리 에러 상태 초기화
}
};
return (
<div className="query-error-fallback">
<div className="error-icon">
<svg>{/* 경고 아이콘 */}</svg>
</div>
<h2>{title}</h2>
<p>{getErrorMessage()}</p>
<button onClick={handleRetry}>{buttonText}</button>
</div>
);
};
실제로는 아래와 같이 처리해주어 컴포넌트를 보여주도록 수정하였습니다.
<ErrorBoundary
fallback={
<QueryErrorFallback
error={articleListQuery.error as Error}
title="아티클 목록을 불러올 수 없습니다"
/>
}
>
{articleListQuery.isLoading ? (
<ArticleListSkeleton count={6} />
) : (
// 아티클 리스트
)}
</ErrorBoundary>
6단계: Skeleton UI로 로딩 상태 개선
그리고 제가 생각하기에 ux를 개선할 수 있는 부분 중 가장 큰 영향을 미친다고 생각하는데, skeleton을 추가해주었습니다.
사실 피그마에는 스켈레톤이나 로딩에 대한 내용이 없었기 때문에 개발하지 않았던 건데, 있으면 좋을 것 같아 제가 임의로 추가한 뒤,,, 디자이너 분께 보여드리며 스켈레톤 추가하면 어떻냐고 제안드린 사항이엇씁니다..
결과적으로는 매우 성공적이라고 생각한,,
📊 전체 개선 효과
데이터 로딩 흐름 비교
Before: JSON 파일 시절
사용자 접속 → 전체 200개 다운로드 (2MB, ~3초) →
프론트에서 필터링/정렬 → 화면 표시중간: 백엔드만 리팩토링
사용자 접속 → 페이지네이션 API (10개, 150KB, ~0.4초) →
DB에서 필터링/정렬 → 화면 표시
BUT 페이지 이동 시마다 다시 요청...After: 백엔드 + React Query
사용자 접속 → 페이지네이션 API (10개, 150KB, ~0.4초) →
React Query 캐싱 → 화면 표시
페이지 재방문 시 → 캐시에서 즉시 표시 (0ms!)구체적인 개선 사항
| 시나리오 | Before | After | 개선 |
|---|---|---|---|
| 첫 로딩 | 전체 200개 (~3초) | 10개만 (~0.4초) | 87% ↓ |
| 필터 변경 | 전체 다시 로딩 | API로 필터된 데이터만 | 80% ↓ |
| 뒤로가기 | 전체 다시 로딩 (~3초) | 캐시 사용 (0ms) | 100% ↓ |
| 이미지 로딩 | 매번 다운로드 | 한 번만 + 캐싱 | 중복 제거 |
비포 애프터
사실 더 볼 필요도 없이,,, 비포/애프터 영상을 비교하는게 제일 직관적일 것 같습니다.
사실 데스크탑 영상은 비포를 찍어둔 게 없어서,, 어쩔 수 없이 애프터만 첨부하고
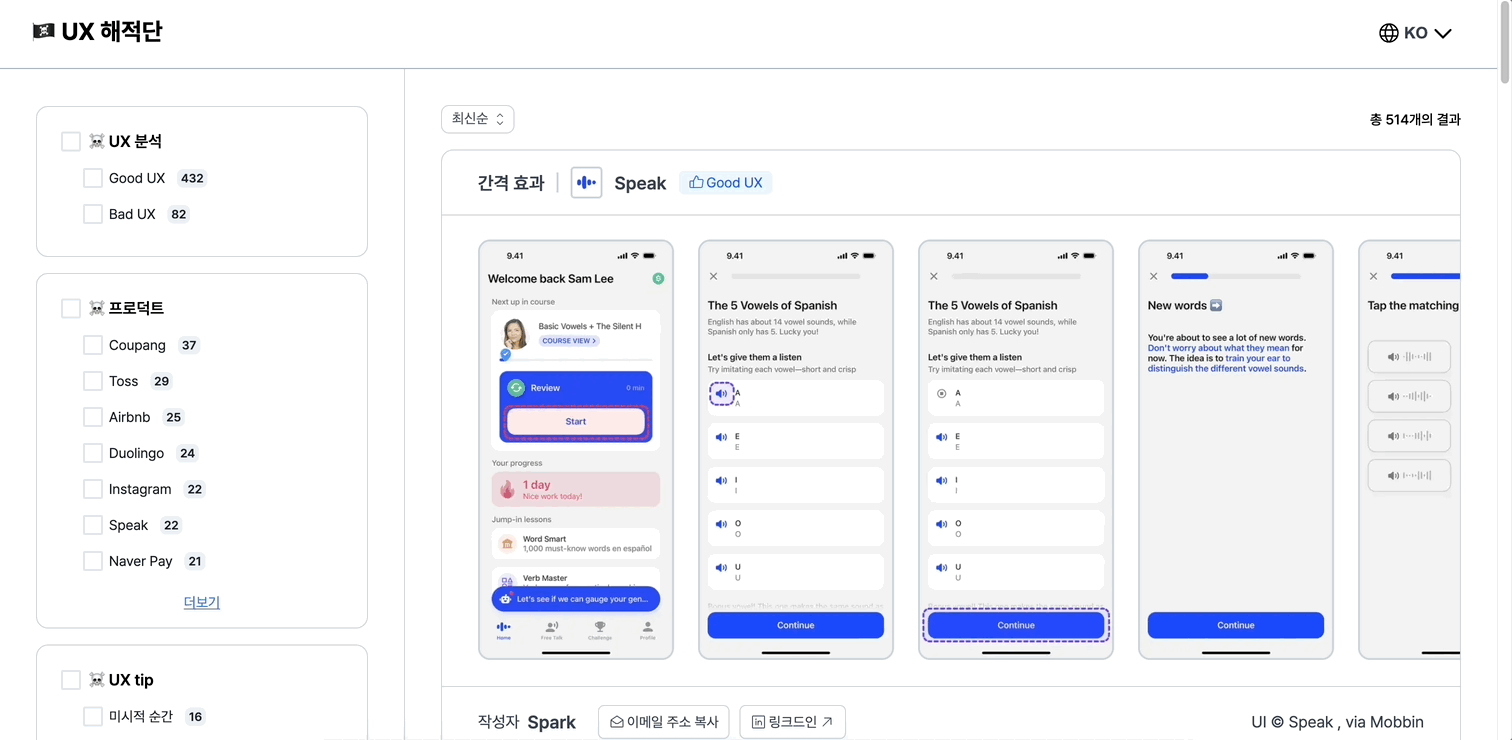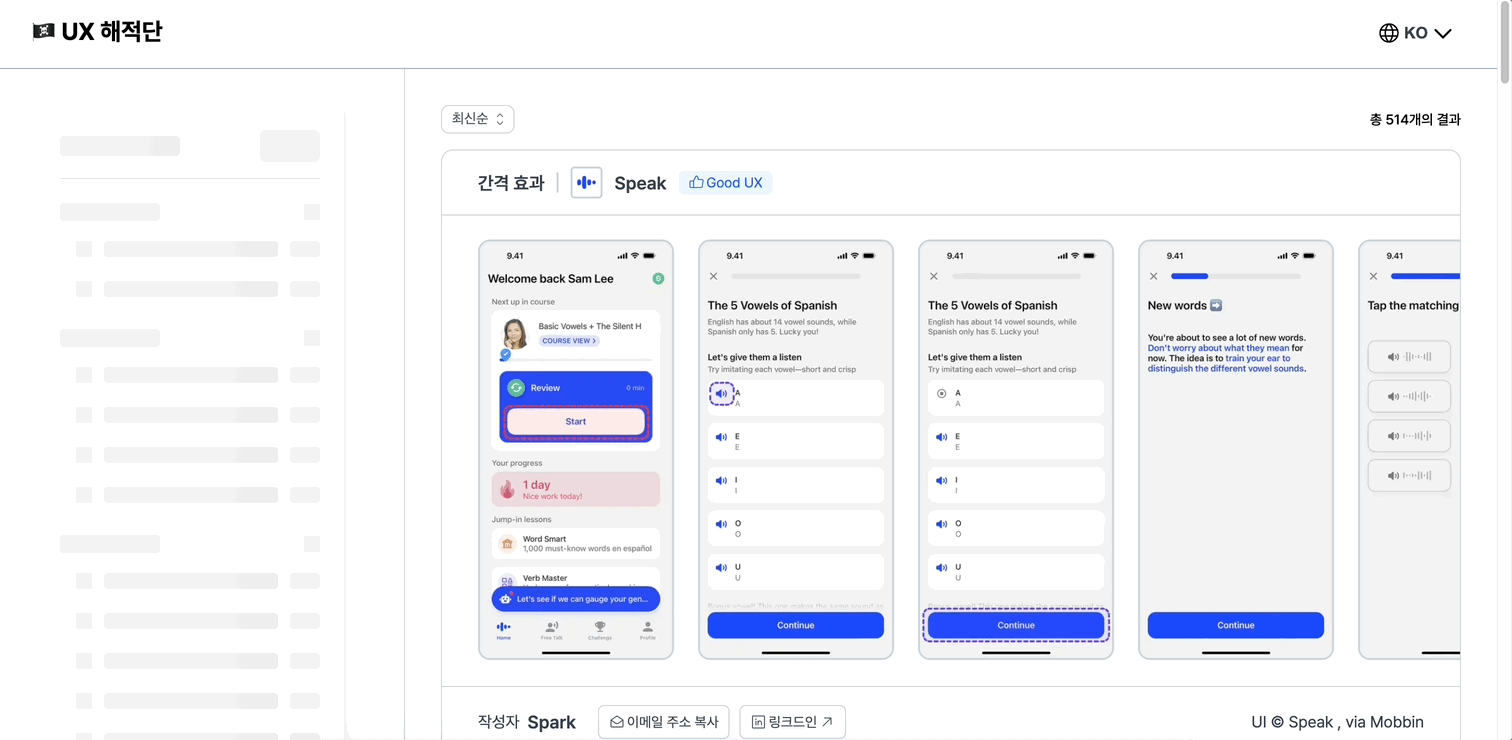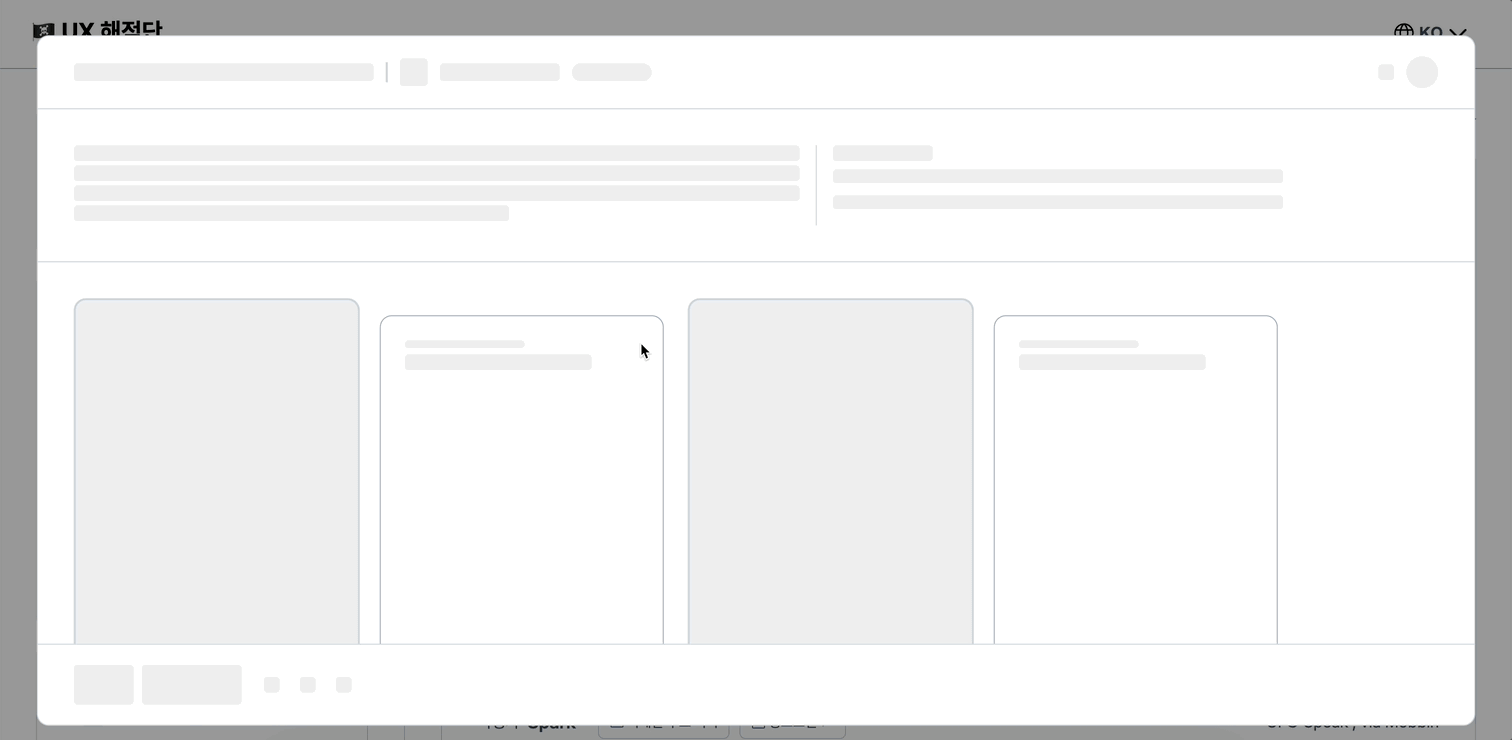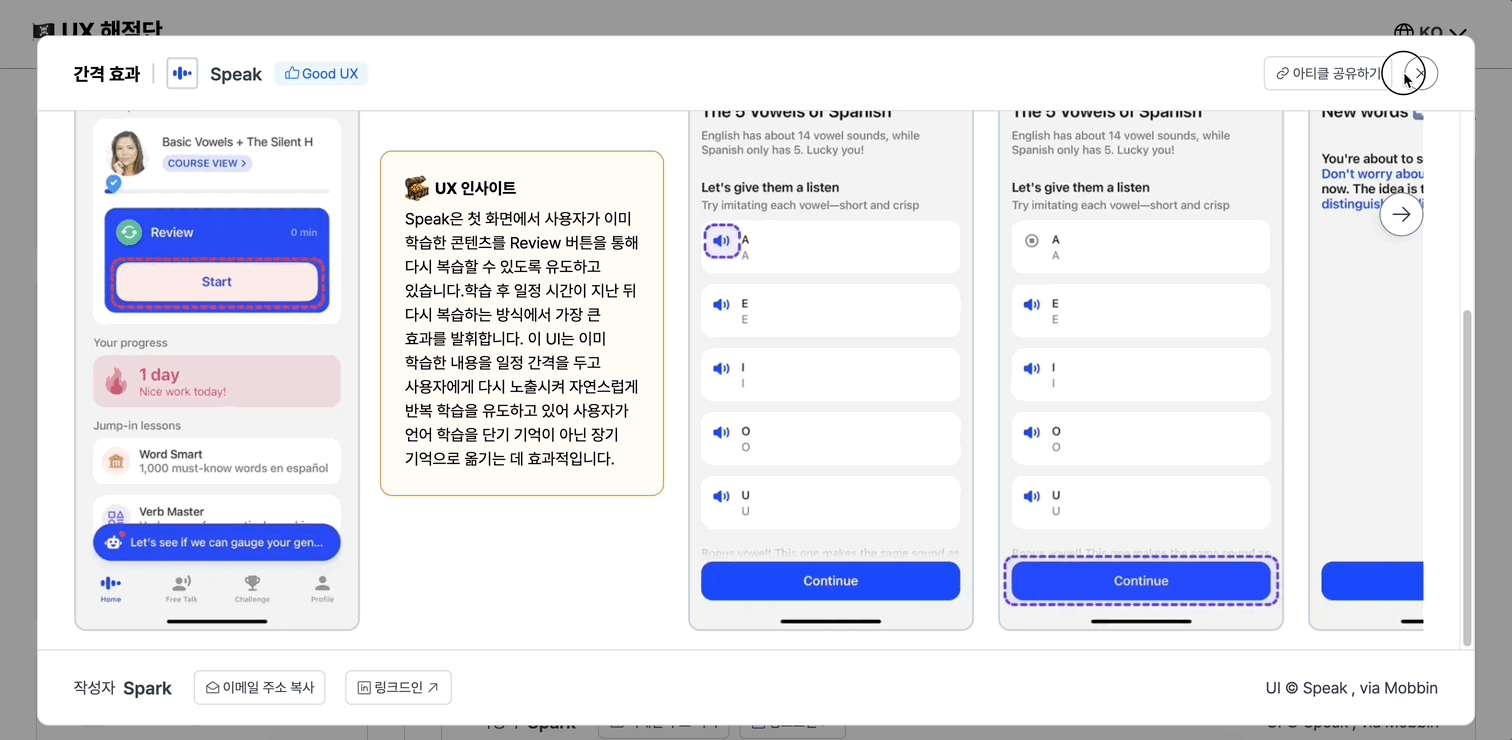
모바일은 qa 때 영상이 있어서 비포를 먼저 첨부해보자면….
(물론 이 때는 실제 배포 중에서도 호스팅 사이트가 정~말 느릴 때의 영상입니다…)
애프터는,, 녹화를 했다고도 무안할 정도로 굉장히 빠름….. (그 사이에 디자인이나 기능 등 업데이트들이 꽤 있었기 때문에 화면이 좀 달라보인다면 그건 착각이 아닙니다.)
정리하며,,,
프론트엔드 리팩토링이라고 하면 "React Query 넣었다!" 이런 얘기를 많이 하는데, 그냥 도입하는게 아니라, key를 어떻게 관리해야 좋을지 고민도 해보고, 어떤 걸 캐싱하고 어떤 걸 캐싱하지 말아야 할지, 중복으로 관리되고 있는 건 없는지 등…. 생각보다 많은 걸 살펴볼 수 있는 기회가 되었던 것 같습니다.
결론적으로 이번 리팩토링은
- 백엔드에서 페이지네이션, 필터링, 정렬 API 제공 (기반)
- 프론트에서 그 API를 제대로 활용 (구현)
- React Query로 캐싱 추가 (최적화)
이 세 단계가 맞물려서 큰 개선을 이룰 수 있었던 것 같다는 생각이 새삼 드네요,,
+ 빨라졌다는 사용자의 피드백
저희 사이트에 관심이 많은 분들이 꽤 계신다는 이야기를 들었습니다,,, 이전에 포스팅했던 것처럼 X에서 인기가 꽤 많았던 건 알고 있었는데, 이번 리팩토링 이후 디자이너 분이 이런 연락을 받았다고 하더라구요. ㅎ 덤덤한 척 했지만 괜히 기분 좋음

📌 참고
관련 글
