
타이타닉 데이터 이진 분류 실습
본 포스팅은 타이타닉 승선자 데이터를 활용하여 각 feature에 따라 생존자가 죽었는지 살았는지(survived)를 이진 분류하여 예측하는 문제를 풀어볼 것이다. 여러개의 분류기를 다뤄볼 것인데 각각에 대한 자세한 개념은 추후 별도의 포스팅을 제작하겠다.
데이터 전처리 결과는 아래와 같다.
- 기존 X
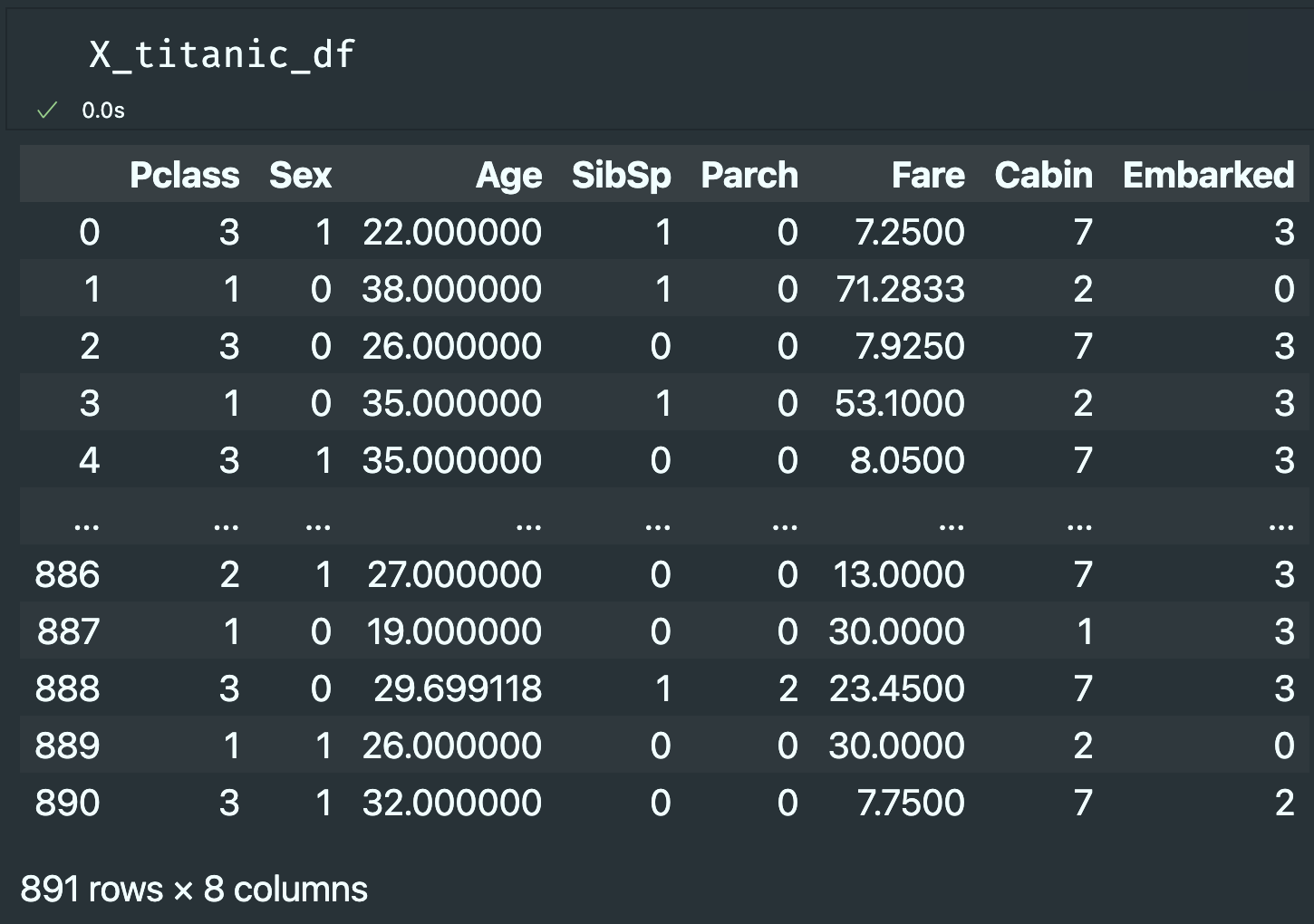
- 정규화 X

- y (target)
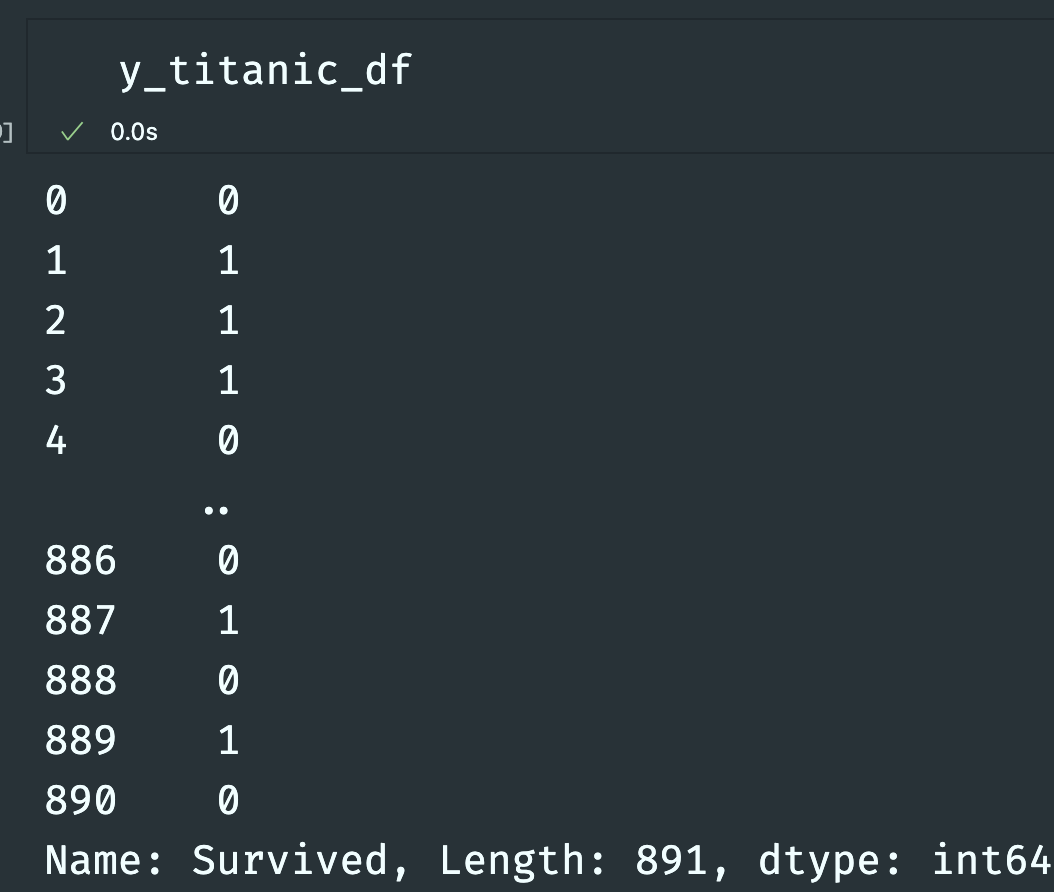
1: 생존 / 0: 죽음
Train Test Split
from sklearn.model_selection import train_test_split
train_scaled, test_scaled, train_target, test_target = train_test_split(
X_train_scale, y_titanic_df, random_state=42)갖고 있는 데이터에서 훈련 세트와 검증 세트로 분할.
KNN Classifier
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))k = 3으로 설정
0.8787425149700598
0.8026905829596412
80점을 맞았다.
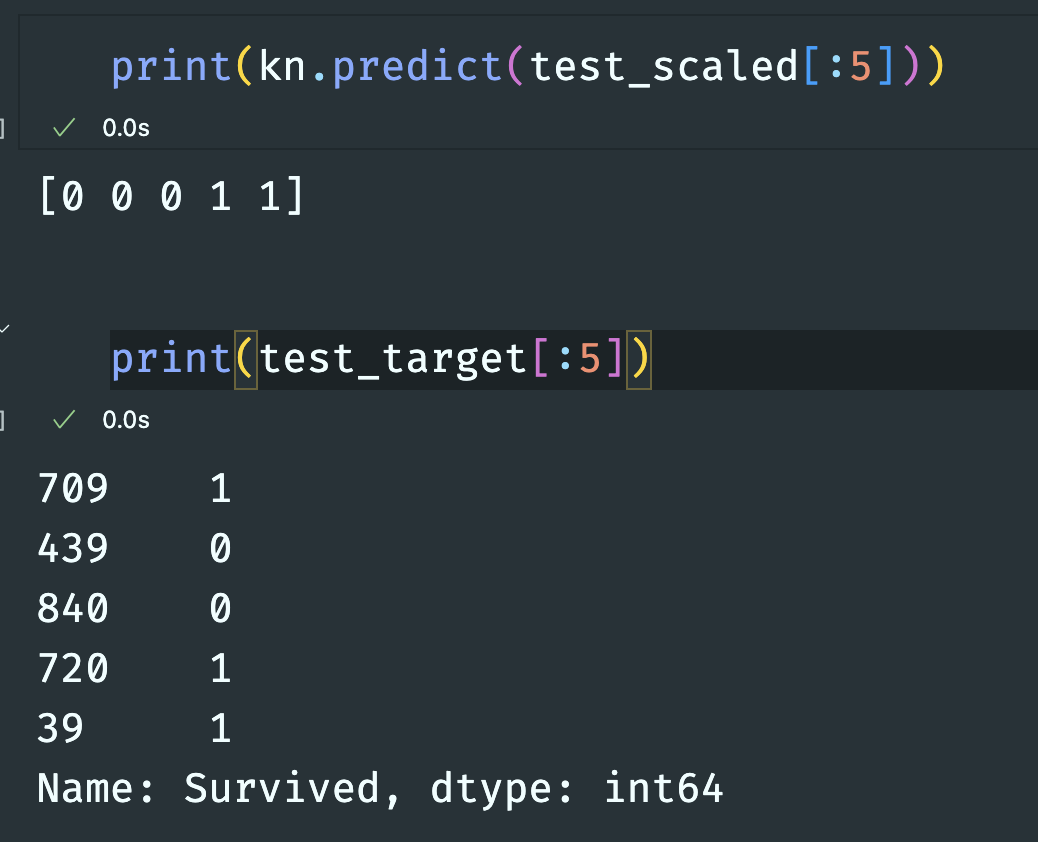
5개의 데이터를 테스트 해보았을 때 4개를 맞춘 것을 확인할 수 있다.
Logistic Regression
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()로지스틱 회귀 모델 생성
교차 검증 (Cross Validate)
accuracy를 사용하여 점수를 확인해볼 수 있었지만 조금 더 정확한 예측 점수를 얻고자 교차 검증 방식을 이용했다.
from sklearn.model_selection import cross_validate
scores = cross_validate(lr, train_scaled, train_target)
print(scores)k = 5 (default)로 설정하여 점수를 출력해보았다.
{
'fit_time': array([0.00352097, 0.00243592, 0.00275683, 0.0024116 , 0.00235128]),
'score_time': array([0.00047588, 0.00040698, 0.00034928, 0.0003562 , 0.00031781]),
'test_score': array([0.79104478, 0.82835821, 0.7761194 , 0.7593985 , 0.81203008])
}
예측 평균 점수를 구해보았다.
import numpy as np
print(np.mean(scores['test_score']))0.7933901918976545
79점!
Random Forest
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9857796912737584 0.8174278981034675
81점 !
현재까지 점수를 비교해보자면
⭐️⭐️⭐️RF 81 > KNN 80 > LR 79⭐️⭐️⭐️
feature importance
rf.fit(train_scaled, train_target)
print(rf.feature_importances_)[0.07208576 0.27029511 0.23832137 0.04881387 0.0343627 0.23531828 0.06459427 0.03620865]
결과값을 확인해보면 3번 feature가 제일 높다.
3번 feature가 뭘까 ??!
위 이미지를 참고해보면 Age다.
나이가 생존 여부에 큰 연관성을 미친다는 사실을 알 수 있다.
Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9150477790612201 0.8068903602289306
80점
XGBoost
from xgboost import XGBClassifier
xgb = XGBClassifier(tree_method='hist', random_state=42)
scores = cross_validate(xgb, train_scaled, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9801659141026986 0.7949949500617214
79점
LightGBM
from lightgbm import LGBMClassifier
lgb = LGBMClassifier(random_state=42)
scores = cross_validate(lgb, train_scaled, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.954717350974833 0.8039277297721916
80점
