
Mac virutalenv 설정
- 작업 폴더 생성
- python -m virtualenv venv
- source venv/bin/activate
해제 = deactivate
github 환경 설정 맞추기
- requirements.txt 다운로드
- pip3 install -r requirements.txt
내가 만든 패키지 저장
- [pip freeze or pip list --format=freeze] > requirements.txt (덮어쓰기)
- [pip freeze or pip list --format=freeze] >> requirements.txt (추가)
문자열 저장
- echo "[내용]" > [name].text (덮어쓰기)
- echo "[내용]" >> [name].text (추가)
GET vs POST
- 이벤트 발생시 주소값 변경 --> get
- 이벤트 발생시 주소값 미변경 --> post
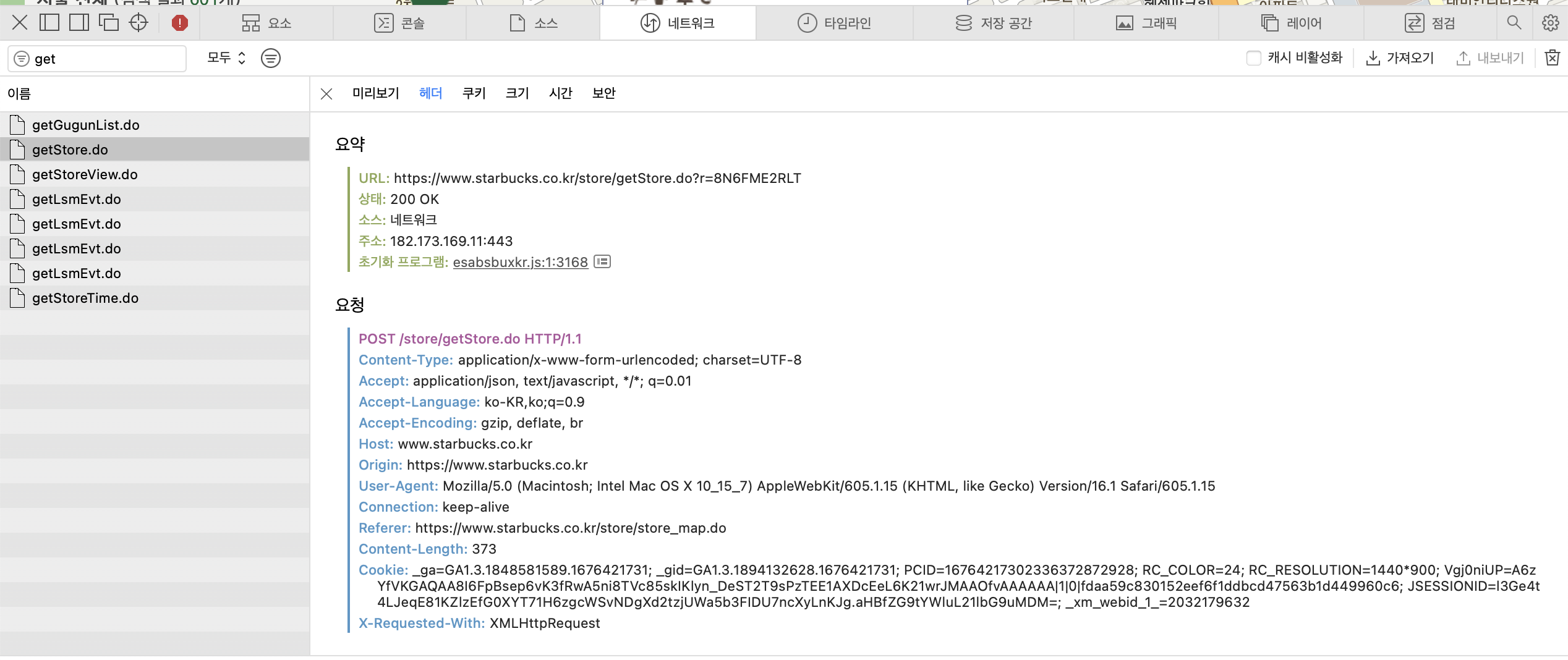
개발자 도구/ 네트워크/ 헤더 에서 확인 가능
IPv4
[0:256].[0:256].[0:256].[0:256]:port
IP:port
통상적으로 http 80번, https는 443번 포트를 이용한다.
자세한건 known port 참조
DNS
Domain Name Server
웹 페이지 주소 ➡️ DNS ➡️ IP 주소 ➡️ 웹 접속
www.starbucks.com ➡️ DNS ➡️ 182.173.169.11
Web Crawling
requests
import requests
url = "url"
payload = dict()
r = requests.(get or post)(url,data=payload)
r.json()웹 페이지의 url 주소에서 payload를 이용하여 json 정보를 얻어낸다.
개발자 도구/Network/ .do 파일 / headers에서 통신 방식을 알 수 있다.
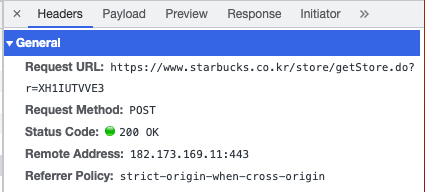
마찬가지로 개발자 도구/Network/ .do 파일 / Payload에서 페이로드 정보를 가져올 수 있다.
경로
절대 경로
파일의 절대적인 위치 경로 (루트 디렉토리부터 시작함)
ex) /Users/happyeon/Desktop/play_data/test
상대 경로
현재 디렉토리를 기준의 파일 경로 (현재 디렉토리부터 시작함)
ex) ./test
명령어
import os
os.getcwd() # 현재 디렉토리의 절대 경로 반환
os.mkdir('directory_name') # 디렉토리 생성
f = open("file_path","write or read",encoding)
#file_path의 파일을 읽거나 쓰기 방식으로 연다. encoding 방식을 지정할 수 있다.
f.write("text") # open한 파일에 text라고 쓴다.
f.close() # 파일을 닫는다.
os.chdir("file_path") # file_path로 디렉토리를 변경한다.
os.path.isdir("directory_path")
# 디렉토리가 있는지 검사해주는 함수File open
f = open("file_path","write or read",encoding)이 방식으로 열면 파일의 크기가 커질 때 상당한 시간이 소요될 수 있다.
왜냐하면 이 방식은 원큐에 여는 방식이기 때문이다. 따라서, 돈까스를 쪼개 먹는 것처럼 한줄씩 꺼내어 읽는 방식이 필요한데 그것이 바로 with 구문이다.
import pickle
with open("file_path","write or read") as f:
pickle.dump(total,f) # total을 f에 저장file path에 있는 파일을 write or read 방식으로 한 줄 씩 수행한다.
What is Pickle?
처음에 피자 먹을 때 먹는 피클을 생각했다.. 프로그래머들은 괴짜가 많으니까, 파이썬도 TV 프로그램을 보다가 명명했는데 이 라이브러리라고 다르지 않을 것 같다.
불필요한 내용은 각설하고, 다음과 같은 상황을 가정해보자.
우리에겐 5GB 짜리 raw text file이 있다. 우리는 데이터 작업을 하기 위하여 이 텍스트 파일에서 필요한 부분을 추출해야 한다. 이것을 추출한 다음에 파이썬으로 가공할 수 있도록 리스트,딕셔너리 등 자료구조를 활용하여 정리해 놓아야 한다. 그런데 모든 텍스트에 대하여 이 작업을 수행하기란 시간이 여간 걸리는 것이 아니다.
따라서, 미리 이 부분을 저장하여 binary 형태로 변환해놓으면은 나중에 그냥 불러오기만 하면 되므로 속도가 훨씬 빨라진다.
한 줄 요약: 텍스트 파일을 저장할 때, pickle로 저장하면 읽을 때 훨씬 빨라짐
BeautifulSoup
BS는 HTML 파일에서 필요한 부분을 파싱할 때 사용하는 도구이다.
사용법
from bs4 import BeautifulSoup
bs = BeautifulSoup('html')
bs.find('태그', 속성 = '속성 이름') # 태그와 속성을 만족하는 라인 찾아줌
bs.findAll('p') # p 태그의 모든 라인을 반환
# find는 제일 첫 번째만 반환Selenium
기본 골격
from selenium import webdriver
driver = webdriver.Chrome() # 크롬창 실행
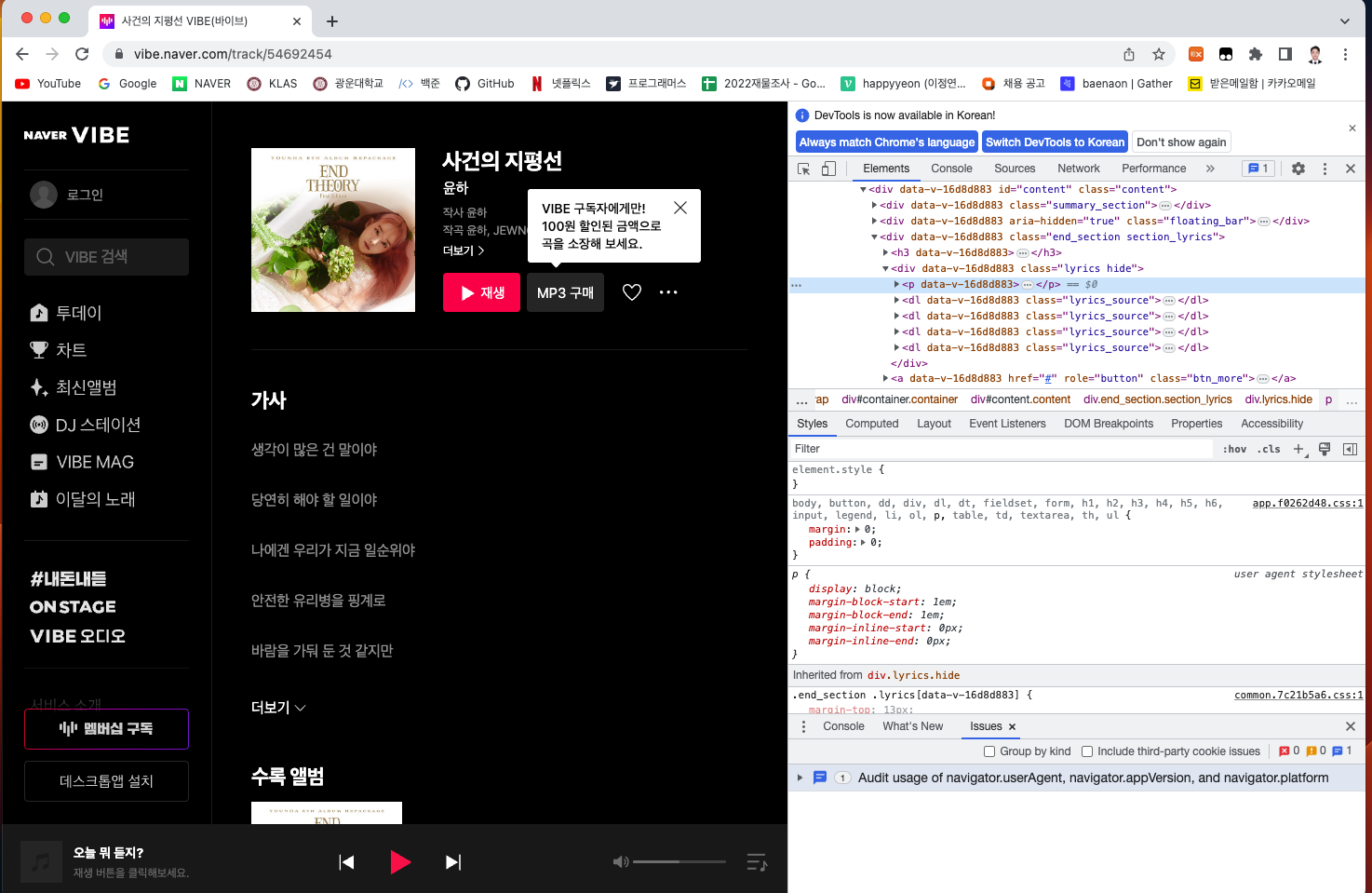
url = "https://vibe.naver.com/track/54692454" # 크롤링할 URL
driver.get(url) # 드라이버에게 URL 접속 시도위의 페이지가 어딜까? 바로 여기!!
by selector
from selenium.webdriver.common.by import By
driver.find_element(By.CSS_SELECTOR, "#content > div.end_section.section_lyrics > a").click()위의 웹에서 우리는 가사를 긁어오고 싶다. 그럴 때 가사가 위치한 HTML 태그를 알아야 한다. 이 때 쉽게 알 수 있는 방법이 있는데 바로 셀렉터를 이용하는 것이다.
개발자 도구에서 command + shift + C를 누르거나 혹은
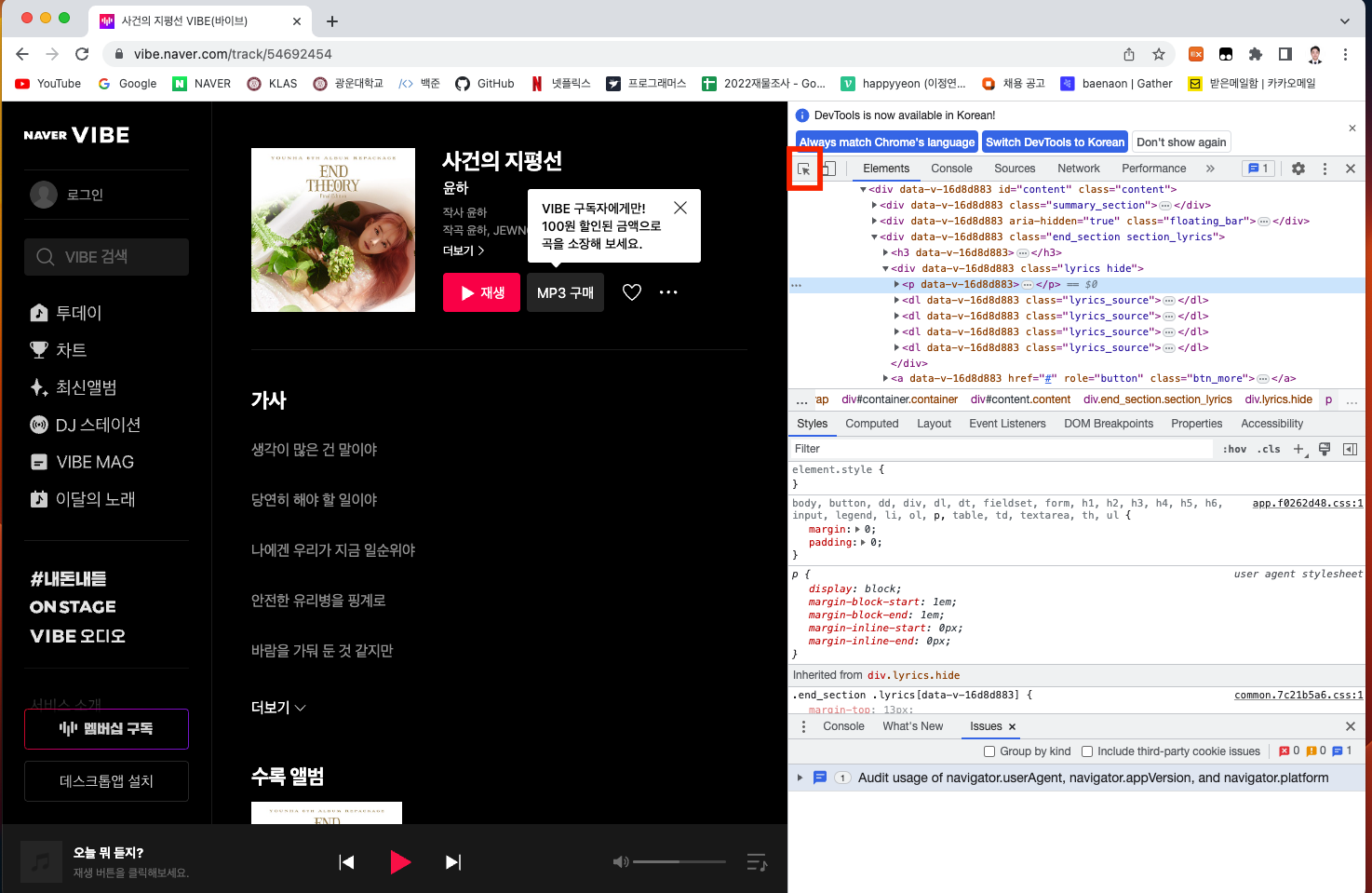
빨간 박스를 클릭하고 내가 원하는 부분에 커서를 갖다 대면 그 위치를 표현하는 HTML 부분이 나온다.
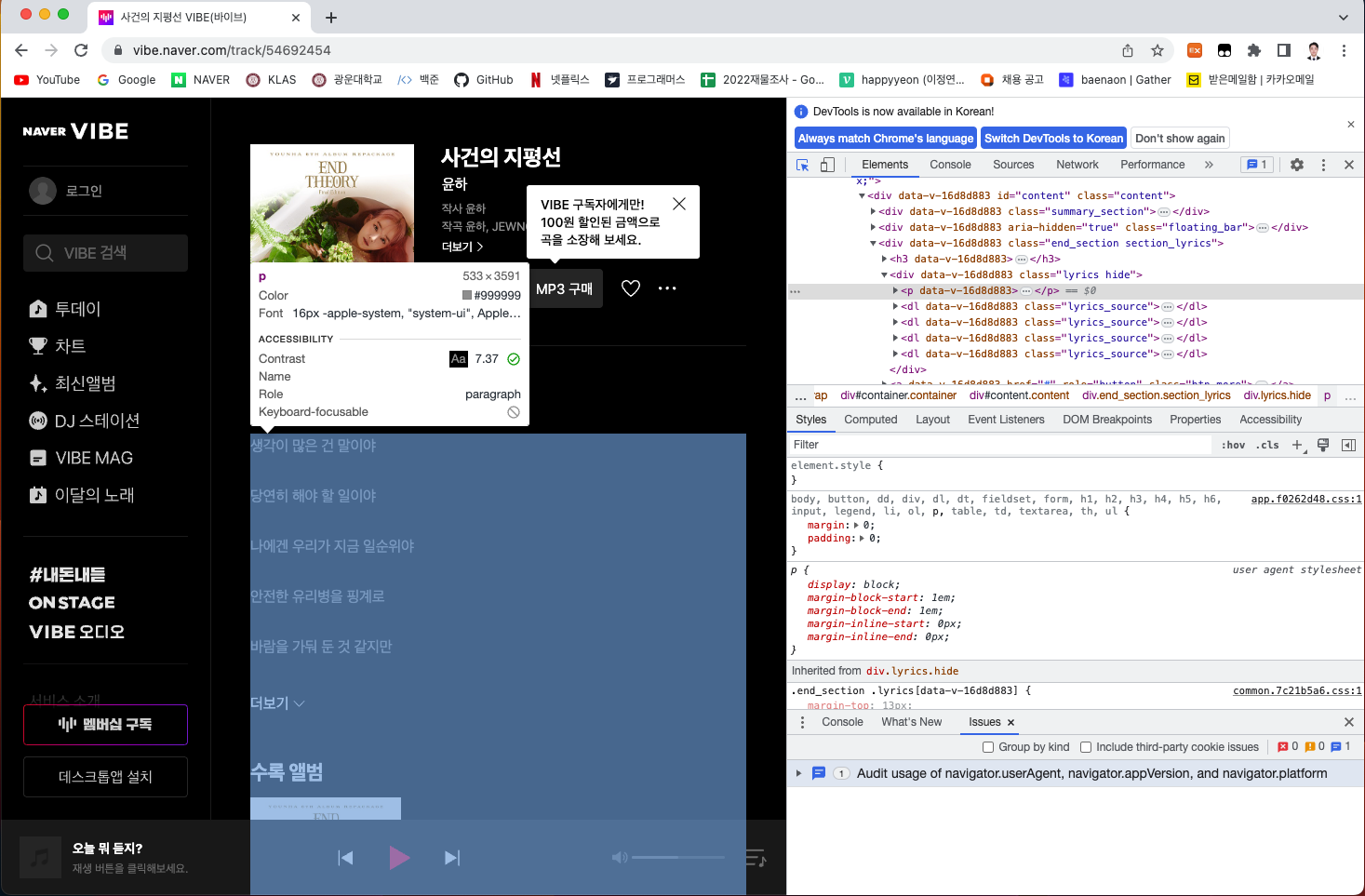
이렇게 !!
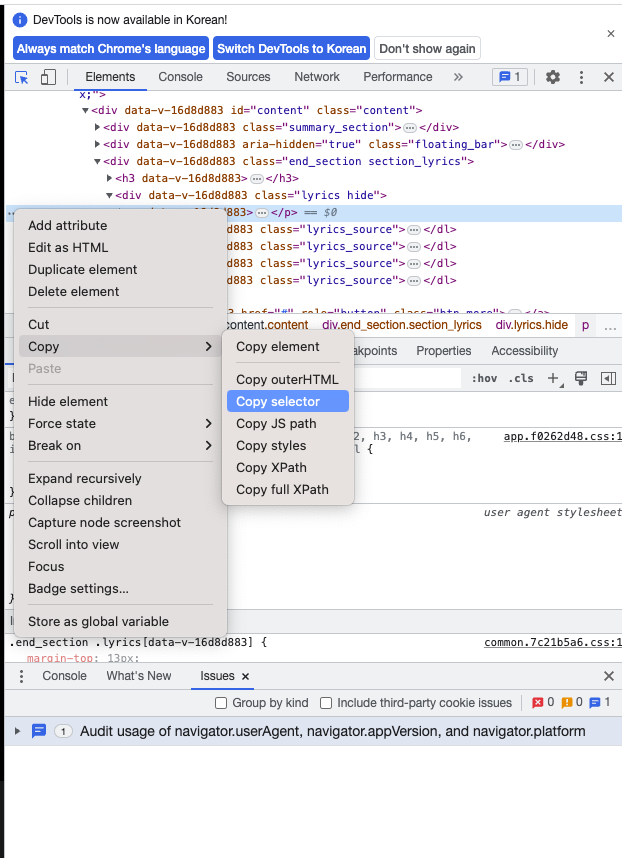
그 다음 .../Copy/Copy selector를 하면 그 부분에 대한 셀렉터 태그 정보가 나오고 이를 저 메소드 안에 가져다 넣으면 해당 부분을 긁어올 수 있다.
