https://www.sciencedirect.com/science/article/pii/S0167739X21002387
개요
- 실제 이미지와 가짜 이미지의 미묘한 질감 차이를 발견
- 차이를 증폭하기 위해
saliency map을 가이드 맵으로 하는 가이드 필터를 활용하여 위조의 잠재적 특징을 표시
인사이트
Saliency Map
- 사람 : 관심영역을 먼저 인지
- Saliency Map : 다른 영역에 비해 픽셀값의 변화가 급격한 부분부터 인지

1. Introduction
- 얼굴을 조작할 때 잠재 공간에서 포인트를 가져와 업샘플링하는 과정에서 출력 이미지에 아티팩트나 아티팩트 패턴 발생
- 기존 연구에서는 GANs로 생성된 이미지에 포함된 체커보드 효과를 기반으로 생성 이미지와 실제 이미지를 구분
- 사용되는 GAN의 종류가 다름 ⇒ 아티팩트의 위치와 정도 다름
- 최근 발전으로 아티팩트 패턴 발생 x
- 이미지 품질 평가 방법과 결합하여
심층 위변조 탐지 파이프라인제안 - 실제 얼굴 이미지와 가짜 얼굴 이미지를 보다 분석하기 쉬운 스타일로 변경하는 것이 목표
Image saliency
- 가짜와 진짜 얼굴 사이의 텍스처 깊이와 픽셀에서의 잠재적 차이를 발견하기 위해 분석
- 차이가 크지 않음 ⇒ 활용 불가능
- 가이드 필터의 상세 향상 기능을 활용하여 텍스처를 강화, 가짜 얼굴 부분의 잠재적 특성을 표시하여 차이 확대
- Resnet18을 사용하여 텍스처 차이를 학습
How
-
image saliency는 진짜와 가짜 이미지 간의 텍스처 깊이와 픽셀 차이점을 발견
-
가이드 필터의 디테일 향상 기능을 사용해 가짜 이미지의 텍스처 디테일이 향상되고 두 종류의 이미지 간의 텍스처 차이가 확대됨
2. Related work
2.1 Face tampering methods 얼굴 위조 방법
Deepfake
- 공유 디코더가 있는 두 개의 인코더를 기반
- 소스 얼굴과 대상 얼굴의 훈련 이미지를 생성하도록 훈련
Face2Face
- 다양한 표정으로 얼굴을 재합성 하는데 사용
FaceSwap
2.2 Forensics methods 포렌식 방법
전통적 방법의 포렌식 탐지
- 스텍그 분석과 아티팩트 통계 사용
- 이미지에 형성된 아티팩트를 이미지 통계적 특성으로 시각화하여 변조된 영역을 검출
학습 기반 탐지
3. Model framework
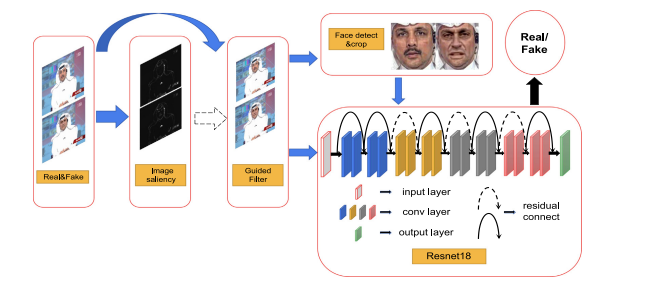
- idea :
이미지 처리와 네트워크 훈련의 조합 가이드 필터- 얼굴 조작 이미지의 텍스처 차이를 확대하여 실제 이미지와 가짜 이미지리를 네트워크 내에서 구분할 수 있는 가이드 특징을 형성
- 2개의 브런치로 나누어짐
- 전체 이미지 학습
- 오직 얼굴 이미지 학습 → Resnet에 학습되기전 크롭된 얼굴
- 각 브랜치의 결과는 독립적이지만 성능 평가에 있어 중요
3.1 Image saliency
-
중요도 감지의 본질은 시각적 주의 모델
- 이미지의 가장 눈에 띄는 부분을 얻기 위해 시각적 주의 메커니즘, 흑백 이미지를 사용해서 중요도를 표시
-
입력이미지 → 픽셀화 → 각 픽셀과 가장자리 픽셀 사이의 대비가 계산 → 배경을 기반으로 한 중요도 맵을 얻음
-
적응형 임계값으로 이미지 분할
- ‘전경’과 ‘배경’을 구분하기 위해서 각 부분에 다른 임계값을 적용
- 적응형 임계값은 이미지의 다양한 밝기와 질감을 고려하여 이미지를 전경과 배경으로 구분
-
전경 기반 중요도 맵 생성
- 전경 시드와 전체 이미지의 중요도 맵 사이의 유사성을 계산하여 전경을 기반으로 한 중요도 맵을 생성
-
지역 특징 중요도 맵 생성
- 전경 기반 중요도 맵과 배경 기반 중요도 맵을 융합
- 가우스 필터를 통해 노이즈를 줄이거나 세부사항을 강조하여 지역 특징에 기반한 중요도 맵을 생성
-
최종 중요도 맵 생성
- 전역 특징 중요도 맵과 지역 특징 중요도 맵을 합쳐 최종 중요도 맵을 생성
- 지역적 특징 : 눈,코,입 같은 객체의 특정 부분. 질감, 색상, 모양 등의 세부 정보
- 전역적 특징 : 이미지 전체의 정보를 반영. 구조, 레이아웃, 색상 분포
- 전역 특징 중요도 맵과 지역 특징 중요도 맵을 합쳐 최종 중요도 맵을 생성
SLIC
- 질감 구조 정보를 더 잘 파악하기 위해 최소 처리 단위로 슈퍼 픽셀을 사용
- 슈퍼 픽셀 : 지각적으로 의미있는 픽셀을 모아서 그룹화한 것
- 인접해 있는 픽셀들 중 비슷한 특성(색상 밝기)을 갖고 있는 것끼리 묶는 것

-
grouping을 통해 이미지에서 일정 object 구분 가능
-
슈퍼 픽셀 분할 → SLIC 알고리즘 사용
-
에지 우선순위에 따라 이미지의 에지 영역이 배경일 가능성 가정
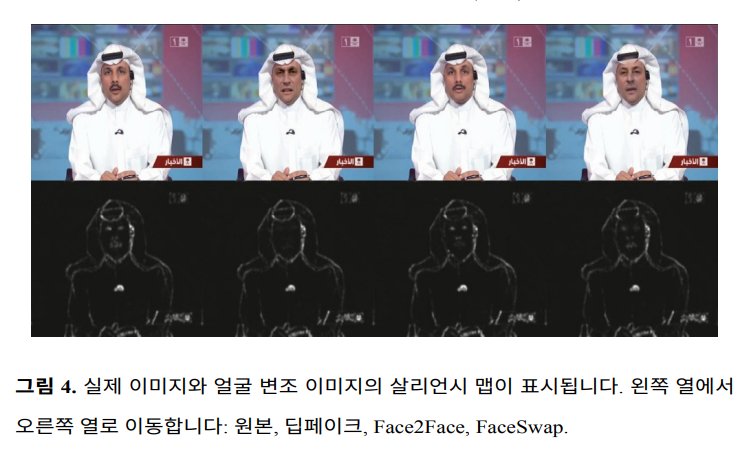
- 딥페이크 살리언시 맵 : 얼굴 날라감
- Face2Face : 얼굴 특징 불완전
- FaceSwap : 얼굴 특징 왜곡
얼굴을 생성하고 대쳏하면서 시각적으로 찾기 어려운 텍스처 아티팩트가 발생, 이를 감지
3.2 Texture enhancement
- 이미지의 차이를 확대하는 방법을 사용
- 전통적인 이미지 개선 알고리즘
- 공간 도메인(Spatial Domain) 알고리즘: 히스토그램 균일화(Histogram Equalization)나 그레이스케일 변환(Grayscale Transformation)과 같이 이미지를 직접 처리
- 주파수 도메인(Frequency Domain) 알고리즘: 푸리에 변환(Fourier Transform)이나 웨이블릿 변환(Wavelet Transform)과 같이 이미지의 특정 변동 도메인에서 작업을 수행
- 가이디드 필터(Guided Filter)
- 각 채널의 입력 이미지가 하는 역할
- 더 큰 창을 사용하여 이미지를 효율적으로 처리할 수 있음 ⇒ 시간 복잡도 극복 가능
- 로컬 선형 모델을 기반
-
함수 상의 한 점은 그 주변의 점들과 선형적인 관계를 가짐
-
함수의 한 점에 대한 값이 필요한 경우 해당 점을 포함하는 모든 선형 함수의 값을 계산하여 평균을 냄
-
가이디드 필터 함수의 출력은 입력과 두 차원 창에서 선형 관계를 가짐
-
가이디드 필터에서 로컬 창 wk 내의 각 픽셀 i 에 대한 출력 픽셀 값 qi를 계산하는 방법
-
q : 출력 픽셀 값
-
I : saliency 이미지의 픽셀 값(입력 이미지)
-
k : 로컬 창의 중심, r : 반지름
-
a,b : 선형 함수의 계수
-
입력과 출력 이미지에서 비슷한 그라디언트를 가지기 때문에 가이디드 필터가 에지를 보존한다는 것을 나타냄
-
- 강화된 이미지는 원래의 가짜 이미지에 비해
명확한 텍스처 가장자리를 가지고 있음 - 실제 이미지와 가짜 이미지의 텍스처 강화 후의 이미지 대비 구조는 더 복잡하며, 심지어 명확한 가짜 이미지 변화 얼굴 프레임까지 볼 수 있음

3.3 Network training
- 두 이미지의 텍스처가 강화되었음에도 불구하고 시각적으로 쉽게 찾을 수 없음
- Resnet18을 기반으로 학습
- epoch : 50
- bath : 64
- optimizer : Adam
- 네트워크 계층을 통과할 때마다 가짜 이미지에 포함된 가이드 특성을 학습
- 마지막 완전 연결 계층은 이미지가 진짜인지 가짜인지 판단을 위한 점수를 얻음
4. Experimental results
4.1 Dataset
Faceforensics++사용
4.2 Training detail
4.3 Performance evaluation
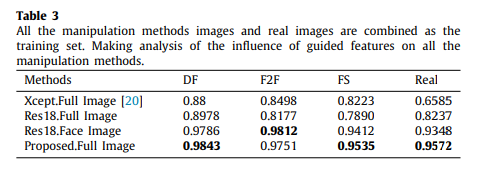
- Resnet18을 훈련시킨 후에는 가이디드 특징을 사용한 모델과 그렇지 않은 모델 간의 성능 차이를 비교
- 가이디드 특징을 사용한 훈련 모델의 정확도가 더 높음
5. Conclusion
- 진짜와 가짜 얼굴 이미지 사이에 존재하는 질감 차이를 찾음
- saliency를 통해 나타냄
- 이를 기반으로 개선된 가이디드 필터를 사용 (질감 아티팩트 강화
- Resnet18과 같은 딥러닝 네트워크를 통해 이러한 차이를 학습하고, 높은 정확도로 진짜와 가짜 얼굴을 구분
