[Code Review] Real3D-AD: A Dataset of Point Cloud Anomaly Detection (2023) (2/2)
Paper I should read
이 포스트에서는 Real 3D-AD 논문의 코드를 리뷰하고자 한다.
관심 연구 주제인 만큼 구체적으로 파헤쳐보자!
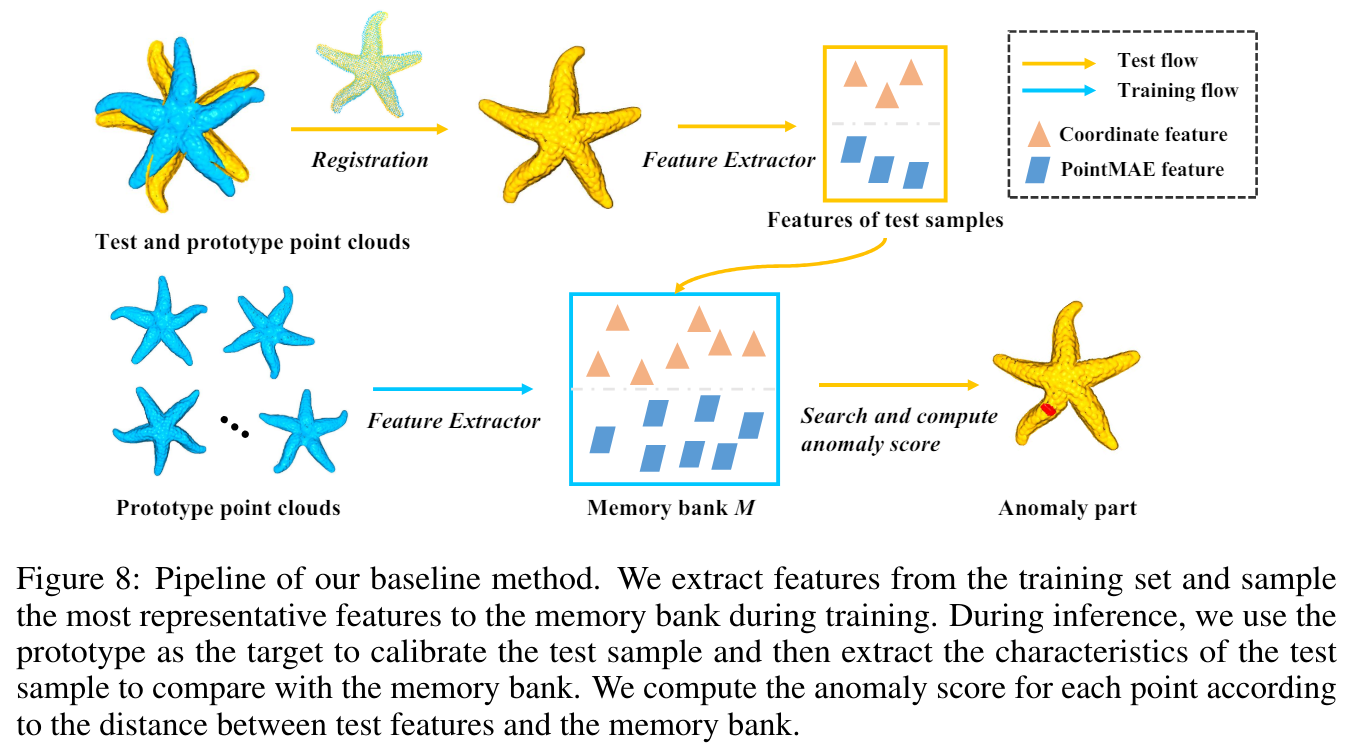
1. Dataset
먼저 Dataset을 정의하자. train, test 용으로 구별하여 구현하였다.
눈여겨 볼 특징은 norm_pcd와 출력값들이다.
데이터 셋은 (n,4)로 구성되어있다.
norm_pcd는 중심점을 구하고 중심점을 기준으로 주변 점들을 normalize시킨다. 그리고 출력값들은 point(n,4), mask(n,), label(정상, 0/ 이상, 1)
test는 good, bad에 따라 나누어서 출력하도록 설정하였다.
class Dataset3dad_train(Dataset):
def __init__(self, dataset_dir, cls_name, num_points, if_norm=True, if_cut=False):
self.num_points = num_points
self.dataset_dir = dataset_dir
self.train_sample_list = glob.glob(str(os.path.join(dataset_dir, cls_name, 'train')) + '/*template*.pcd')
self.if_norm = if_norm
def norm_pcd(self, point_cloud):
center = np.average(point_cloud,axis=0)
# print(center.shape)
new_points = point_cloud-np.expand_dims(center,axis=0)
return new_points
def __getitem__(self, idx):
pcd = o3d.io.read_point_cloud(self.train_sample_list[idx])
pointcloud = np.array(pcd.points)
if(self.if_norm):
pointcloud = self.norm_pcd(pointcloud)
mask = np.zeros((pointcloud.shape[0]))
label = 0
return pointcloud, mask, label, self.train_sample_list[idx]
def __len__(self):
return len(self.train_sample_list)class Dataset3dad_test(Dataset):
def __init__(self, dataset_dir, cls_name, num_points, if_norm=True, if_cut=False):
self.num_points = num_points
self.dataset_dir = dataset_dir
self.if_norm = if_norm
test_sample_list = glob.glob(str(os.path.join(dataset_dir, cls_name, 'test')) + '/*.pcd')
test_sample_list = [s for s in test_sample_list if 'temp' not in s]
cut_list = [s for s in test_sample_list if 'cut' in s or 'copy' in s]
# if if_cut:
# self.test_sample_list = cut_list
# else:
# self.test_sample_list = [s for s in test_sample_list if s not in cut_list]
self.test_sample_list = test_sample_list
self.gt_path = str(os.path.join(dataset_dir, cls_name, 'gt'))
def norm_pcd(self, point_cloud):
center = np.average(point_cloud,axis=0)
# print(center.shape)
new_points = point_cloud-np.expand_dims(center,axis=0)
return new_points
def __getitem__(self, idx):
sample_path = self.test_sample_list[idx]
if 'good' in sample_path:
pcd = o3d.io.read_point_cloud(sample_path)
pointcloud = np.array(pcd.points)
# if self.num_points > 0:
# slice = np.random.choice(pointcloud.shape[0], self.num_points)
# pointcloud = pointcloud[slice]
mask = np.zeros((pointcloud.shape[0]))
label = 0
else:
filename = pathlib.Path(sample_path).stem
txt_path = os.path.join(self.gt_path, filename + '.txt')
pcd = np.genfromtxt(txt_path, delimiter=" ")
# if self.num_points > 0:
# slice = np.random.choice(pcd.shape[0], self.num_points)
# pcd = pcd[slice]
pointcloud = pcd[:, :3]
mask = pcd[:, 3]
label = 1
if(self.if_norm):
pointcloud = self.norm_pcd(pointcloud)
return pointcloud, mask, label, sample_path2. Model
model은 patch core 모델을 사용하였다. 해당 모델의 구조를 살펴보자
전체구조는 PatchCore 모델을 불러오고 Point MAE feature를 뽑기 위해 feature extractor를 불러오고 memory bank를 만듬으로 학습은 종료된다.
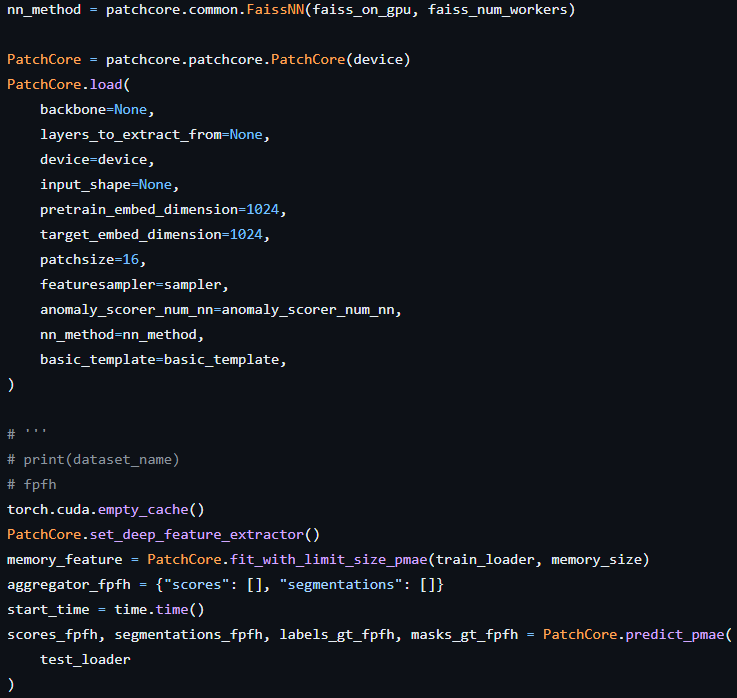
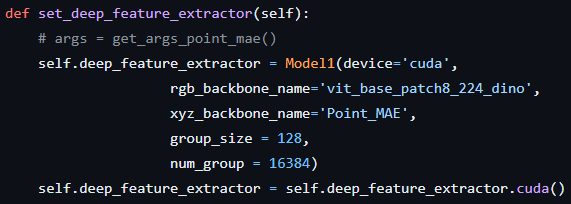
PatchCore에서 set_deep_feature_extractor를 통해 Point_MAE 방식으로 사전 학습된 point transformer 모델을 불러온다.
그 후 memory bank를 fit_with_limit_size_pmae로 생성한다.
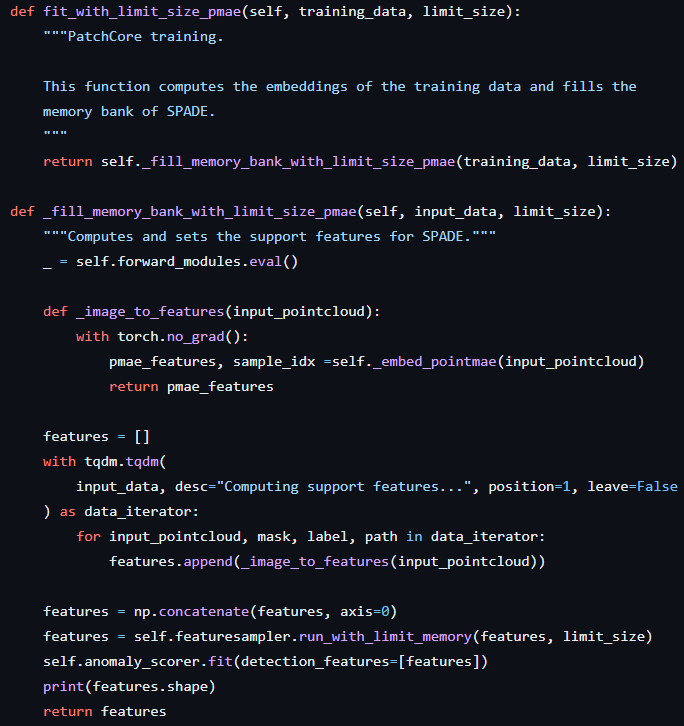
해당 코드를 통해 anomaly_scorer 를 fit 하면서 정상 coreset에 대해 학습하게 된다. 여기서 memory_feature 변수를 만드는데 해당 변수는 따로 사용하지 않는다.
이후 predict_pmae를 통해 예측하여 feature extracted된 feature를 뽑는다. (해당 코드에서 fpfh라고 되어있는데 까먹고 변수명을 안바꾼 것 같다.)
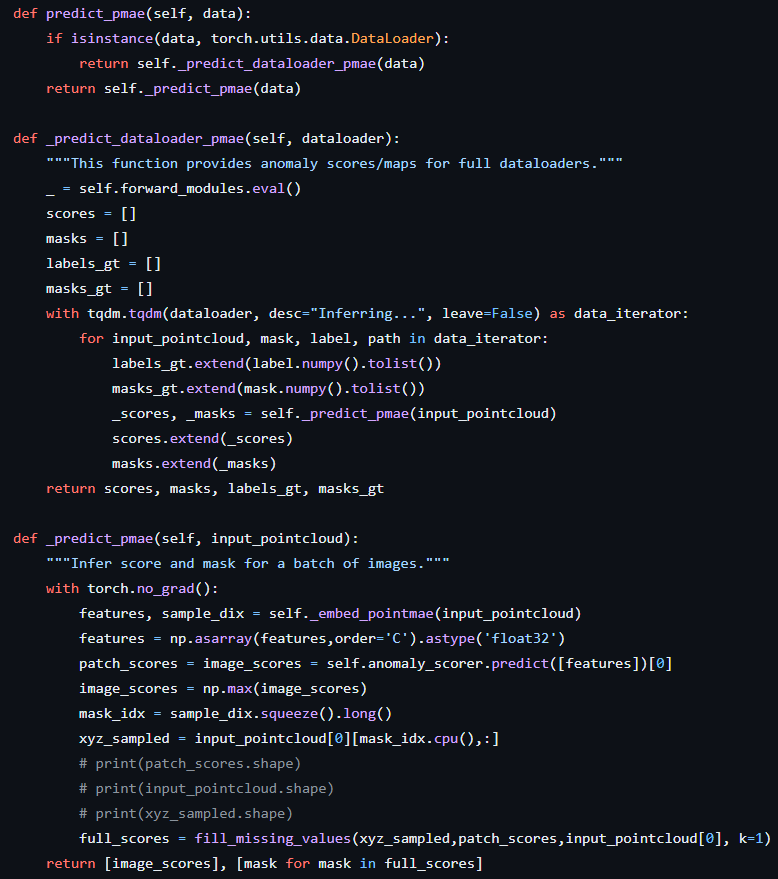
이렇게 나온 points들에 대해 xyz에 대해서도 완벽히 동일한 단계로(함수는 다르다) 수행하며, 각 feature 대해 논문에서 제안한 연산을 통해 anomaly scoring을 한다.
자세한 코드는 공식 페이지에서 확인하면 좋을 것 같다.
추후에 해당 코드를 해당 모델에서 대해서만 보기 쉽게 정리해보도록 하자!
추가로 PatchCore는 고려대 DSBA 연구실 Towards Total Recall in Industrial Anomaly Detection 발표를 들어보는 것을 추천한다.
