[Paper Review] Real3D-AD: A Dataset of Point Cloud Anomaly Detection (2023) (1/2)
Paper I should read
1. Abstract
고정밀 포인트 클라우드 이상 탐지는 고급 가공 및 정밀 제조 결함을 식벽하는 금본위제(gold standard)이다. 데이터셋 부족과 체계적인 벤치마크가 없어 발전이 제한되고 있다. 이에 고정밀 포인트 클라우드 이상 탐지 데이터셋을 소개하여 이 분야의 한계를 해결하고자 한다. 또한, Real3D-AD를 위한 종합적인 벤치마크를 제시하며, 고정밀 포인트 클라우드 이상 탐지를 위한 기준 방법의 부재를 드러냈다. 이를 해결하기 위해 지역적 및 전역적 표현을 보존하는 새로운 memory bank를 통합한 registration-based 3D 이상 탐지 방법인 Reg3D-AD를 제안한다.
2. Introduction
Real 3D-AD Motivation
3D > 2.5D. 학계와 산업 간의 격차를 해소하기 위해 고해상도 포인트 클라우드 이상 탐지 데이터셋을 제안할 필요가 있다. 이는 공장 현장에서 포인트 클라우드 이상 탐지 기능을 실현하는 데 기여한다. 포인트 클라우드 이상 탐지는 real-world 생산 라인에서 널리 사용된다. 하지만, 학계에서 공개된 3D 이상 탐지 데이터셋은 RGBD(2.5D)로 산업 제조의 수요를 충족시키지 못한다. 고급 가공 및 정밀 제조는 검사 과정 내내 사각지대가 없어야 한다. 그러나 RGBD 데이터셋은 단일 시점 스캔을 통해 이루어지기 때문에 사각지대가 존재한다. 실제 포인트 클라우드 이상 탐지 데이터셋의 부재는 3D 이상 탐지의 추가적인 발전을 저해한다. 이러한 이유로, 산업 제조의 요구를 충족하는 포인트 클라우드 이상 탐지 데이터셋을 제안하는 것이 매우 중요하고 시급하다.
Limitation of current 3D-AD dataset and Real3D-AD advantage
1. MVTec 3D-AD
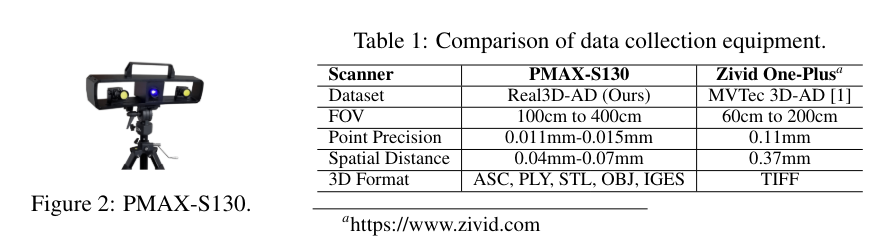
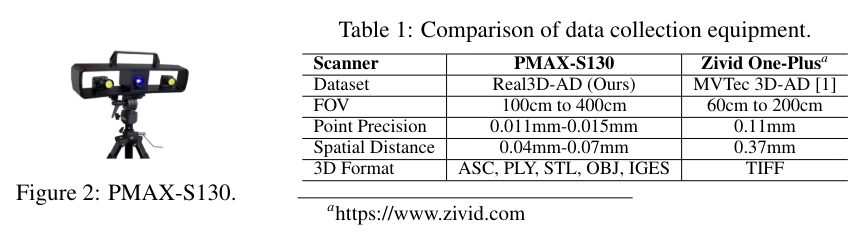
정밀도는 고정밀 포인트 클라우드 이상 탐지 요구를 충족시키기에 부족하다. MVTec 3D-AD는 각 객체당 4,147개의 포인트 클라우드를 제공하는데, 이는 포인트 정밀도가 0.11mm에 불과하다. 반면, Real3D-AD는 MVTec 3D-AD와 비교하여 약 100배 더 많은 1.3백만 개의 포인트 클라우드를 제공하며, 포인트 정밀도는 최대 0.010mm에 이르러 MVTec 3D-AD보다 열 배 더 발전되었다.
2. RGBD Camera
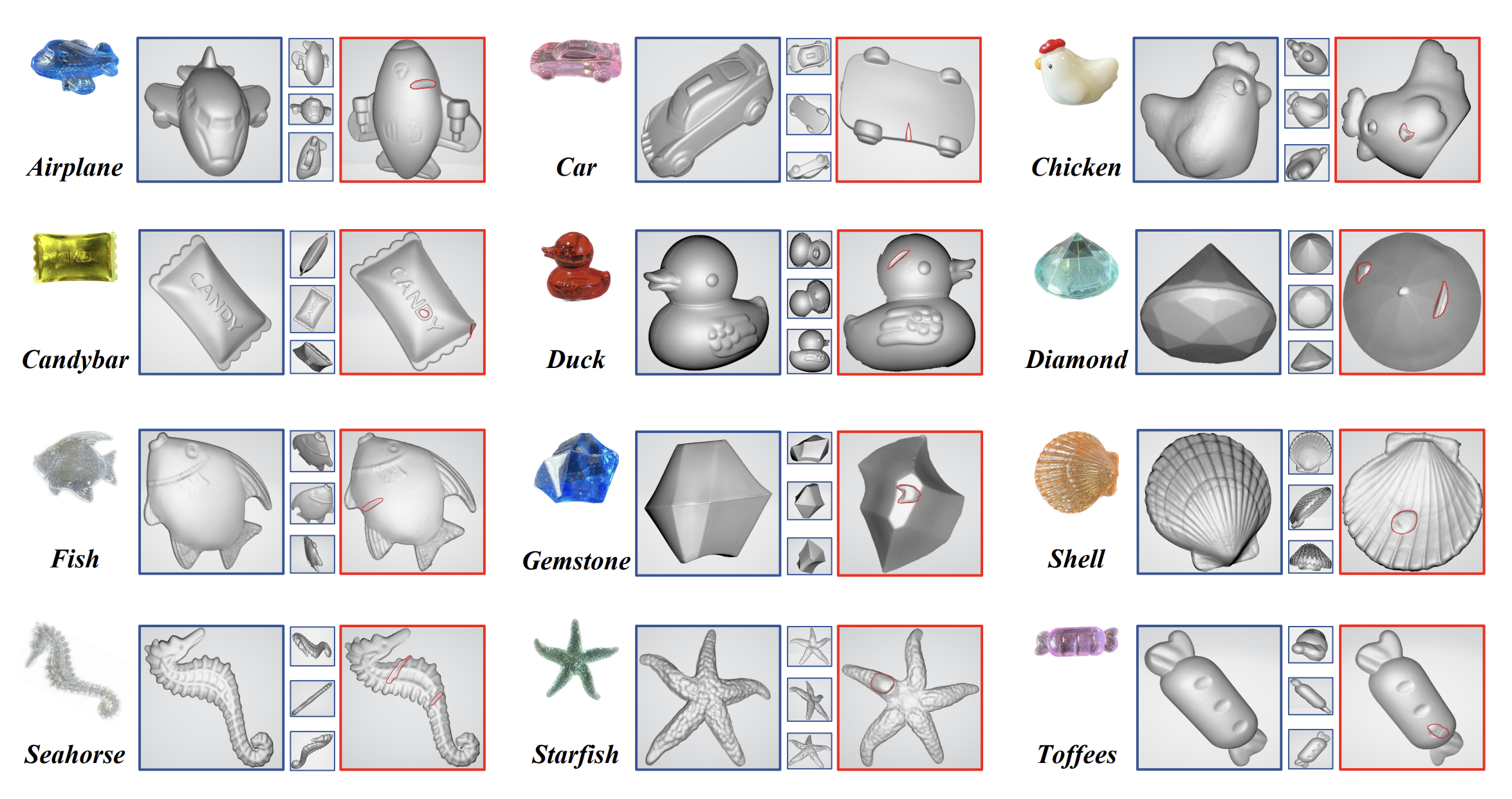
RGBD 카메라를 사용하여 3D 데이터를 수집하는 경우, MVTec 3D와 Eyescandies와 같은 3D 이상 탐지 데이터셋에는 사각지대가 존재한다. 단일 시점에만 의존하여 검사할 때 결함을 식별하는 것이 도전이 될 수 있다. Real3D-AD는 고해상도 레이저 스캔을 사용하여 수집되며, 그림 1에서 보여주듯이 제품의 결함을 곳곳에서 발견하는 데 적합합니다.

Benchmark & Baseline
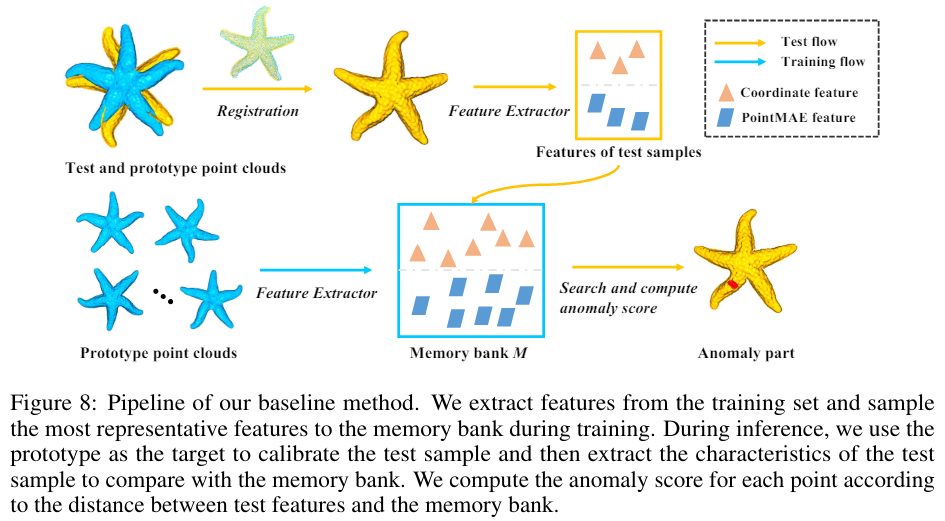
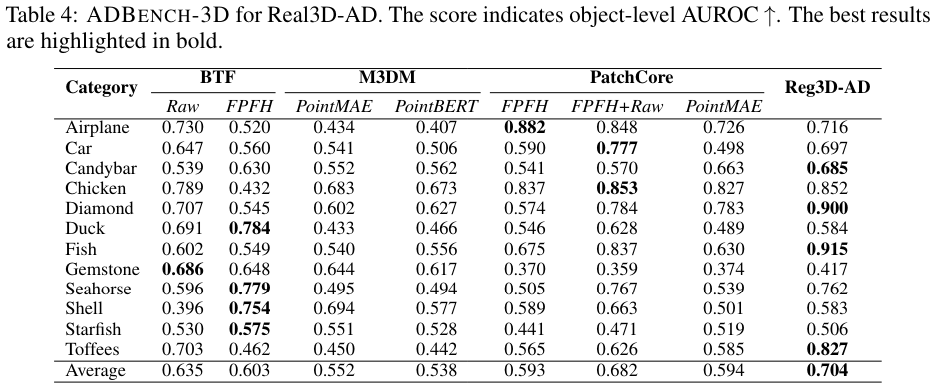
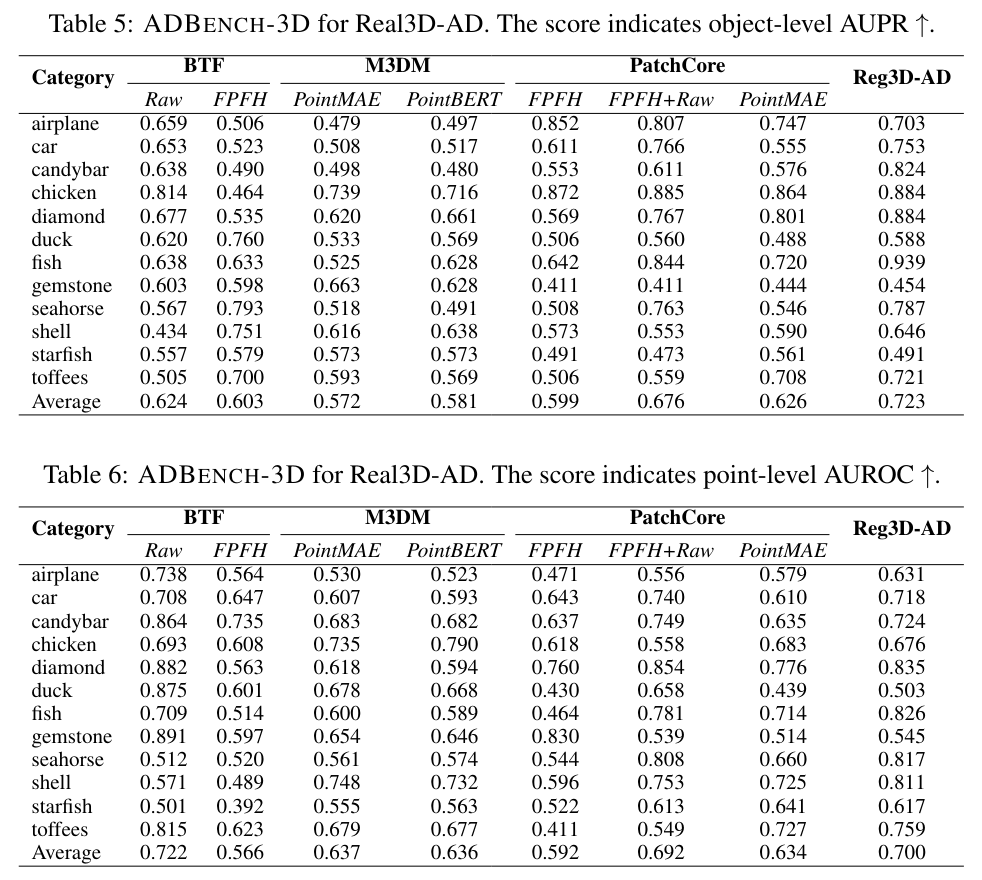
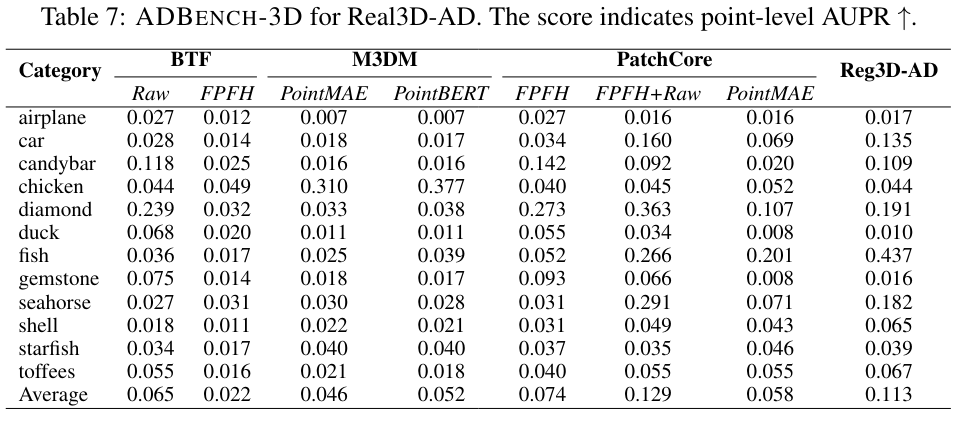
대규모 벤치마크인 ADBENCH-3D를 구축하였다. 실제 제약을 고려하여, 각 카테고리별로 사용 가능한 교육 데이터셋의 수를 4개이하로 제한하였다. 이유는 각 카테고리별로 고정밀 프로토타입을 생성하는 과정이 시간이 많이 소요(카테고리당 최대 이틀)되기 때문이다. ADBENCH-3D의 구성은 최근의 3D 이상 탐지와 다르다. 구체적으로는 train sample은 제한 적이고, 테스트 샘플은 한쪽면만 스캔된다. 이는 real-world 적용을 모방하기 위한 것이다: 생산 라인에서 스캔 위치는 고정되어 있고, 한 위치에서는 제품의 한쪽면 결과만 스캔할 수 있다. 또한 정확한 성능 비교를 용이하게 하고 재현성을 보장하기 위해, ADBENCH-3D 프레임워크는 데이터 전처리, 3D-AD 알고리즘, 평가 스크립트, 지표, 시각화 툴킷을 포함하는 포괄적인 엔드투엔드 파이프라인을 포함한다. ADBENCH-3D는 Real3D-AD 데이터셋에서 구현 및 테스트된 8가지 기본 3D 이상 탐지 방법론을 포함한다. 또한, 표 4에 제시된 결과는 현재의 대부분의 3D-AD 기술이 Real3D-AD에서 만족스러운 성능을 달성하지 못하고 있음을 보여주며, 이는 그들의 객체 탐지 수준 AUROC 점수가 50%에 미치지 못함으로써 입증된다. 그 결과, 우리는 Real3D-AD 데이터셋의 요구를 충족시키는 다용도 솔루션으로서 등록 기반 3D-AD 방법인 Reg3D-AD를 제안한다. Reg3D-AD 모델은 그림 8에서 보여지듯이 지역 및 글로벌 특성을 보존하도록 설계된 새로운 특징 메모리 은행을 도입한다. 추론 과정에서 테스트 객체는 교육 프로토타입과 정렬되며, 그 특성은 지역적 및 전역적으로 추출된다.
Contribution
-
최초의 고해상도 3D 이상 탐지 데이터셋인 Real3D-AD를 생성하여, 고해상도 3D 이상 탐지 알고리즘의 설계를 가능하게 하고 이를 공개적으로 적용하였다. Real3D-AD는 이전의 3D 이상 탐지 데이터셋 연구와 구별되는 세 가지 주요 특성을 보여준다. 이러한 특성에는 높은 수준의 정밀도, 사각지대의 부재, 그리고 현실적이고 고정밀도의 프로토타입이 포함됩니다.
-
ADBENCH-3D가 제공하는 엔드투엔드 파이프라인에는 데이터 준비, 데이터 분할, 평가 메트릭 및 스크립트, 시각화 툴킷이 포함된다. ADBENCH-3D는 Real3D-AD에서 8가지 주요 알고리즘을 사용한 대규모 체계적 평가를 수행하였다.
-
General-purposed registration-based 3D anomaly detection method (Reg3DAD)를 제안하였다.
3. Related work
1. 3D-AD Datasets
AD 작업에서 공간 정보의 가치를 더욱 탐구하기 위해, 우리는 객체 정보를 3D 공간으로 확장하는 Real 3D-AD 데이터셋을 제안한다. Real 3D-AD 훈련 세트의 프로토타입은 다양한 관점에서 종합적인 객체 정보를 포함한다. 테스트 세트 또한 객체에 대한 다중 시점 정보를 포함하여 AD 작업에서 3D 정보의 가치를 더 광범위하게 탐색할 수 있도록 한다.
2. 3D-AD methods
거의 모든 최근 연구는 사전 훈련된 모델과 memory bank에 의존한다. 현재 포인트 클라우드 정보를 사용하는 이상 탐지 방법이 부족하며, 실험할 수 있는 데이터셋 또한 부족한 실정이다.
4. Real3D-AD dataset
1. Data Collection
Prototype construction은 아래의 과정으로 만들어진다.


2. Data Statistics
Real3D-AD는 총 1,254개의 샘플을 포함하며, 이들은 12개의 서로 다른 카테고리에 걸쳐 분포되어 있다. 모든 카테고리는 제조 라인에서 나온 장난감들이다. 표2에 제시된 데이터는 낮은 이상 포인트 비율이 이상을 감지하는 데 어려움을 준다는 것을 보여준다. 카테고리의 대부분 속성은 투명도와 관련되어 있어, Real3D-AD 데이터셋이 포인트 클라우드에서 이상을 감지하는 작업에 매우 적합하다는 것을 나타낸다.
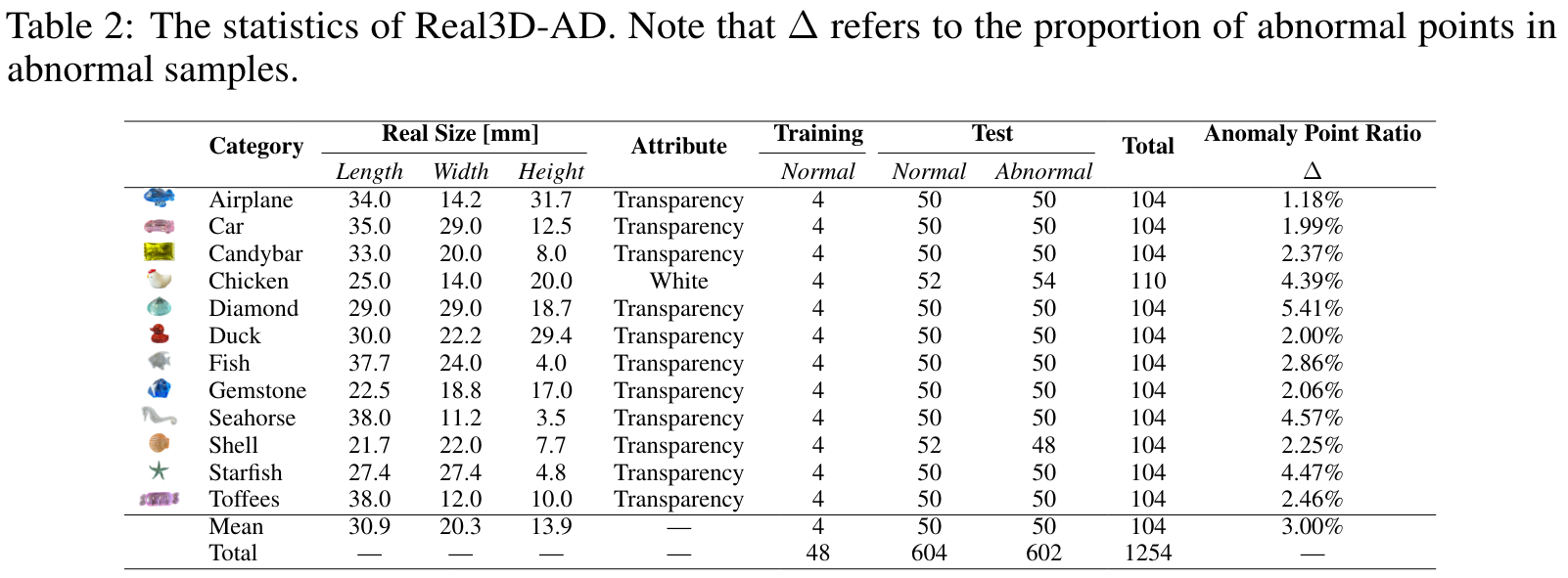
또한, 그림 6에서 보여지는 바와 같이 Real3D-AD 데이터셋의 모든 샘플에 걸친 데이터 포인트의 분포를 box-and-whisker plot로 나타내었다. 2가지 특징을 알 수 있는데, 첫 번째는 학습용 샘플은 3D 객체의 완전한 프로토타입을 제공하는 반면, 테스트 샘플은 한쪽 면만 스캔된다. 따라서 학습용 샘플의 수가 테스트 샘플 수보다 훨씬 많다. 두 번째는, 각 테스트 세트 내에서 정상 샘플과 비정상 샘플 간의 포인트 값 차이는 비교적 미미하다는 것을 관찰할 수 있다. 이러한 관찰은 데이터셋의 구조적 특성과 데이터 포인트의 처리 방식을 이해하는 데 중요한 정보를 제공한다.
5. Benchmark and Baseline
1. Problem Definition and Challenges
-
Problem Definition
훈련 데이터셋은 이고 여기서 이다. 테스트시에는 정상과 비정상 샘플이 모두 주어지며 anomaly detection & localization을 수행한다. -
Training and test samples visualization
학습 데이터 셋은 limited visibility가 존재하지 않는다. 실제 real-world 조건을 모방하기 위해, 테스트 샘플은 한쪽면만 스캔된다. real-world application을 원하기 때문에, 생산 라인의 작업자 또는 품질 검사 장비는 제품의 한쪽 면을 무작위로 확인하여 스캔된 데이터와 프로토타입을 매칭함으로써 결함을 식별한다.
- Challenges
1) 각 카테고리의 훈련 데이터셋은 정상 프로토타입만 포함하며, 객체 또는 포인트 레벨의 주석이 없다.
2) 훈련 세트의 정상 프로토타입이 매우 제한적이다.
3) 테스트 세트와 학습 세트 샘플 간의 피할 수 없는 차이가 존재하며, 이를 해결해야함.
2. ADBENCH-3D
- Metrics
AUROC, AUPR/AP로 평가하였다. AUROC는 모델이 얼마나 잘 이상을 정상과 구분하는지를 보여주고, AUPR/AP는 불균형한 데이터 세트에서의 성능, 특히 소수의 이상 샘플이 많을 때 모델의 정밀도와 재현율 사이의 균형을 평가하는 데 유용하다.
-
Methods
BTF, M3DM, PatchCore를 벤치마크로 삼았다. -
Toolkit
8가지 방법을 3단계로 제공한다.
1) Data preprocessing
2) Evaluation scripts and metrics
3) Visualization toolkit
3. Reg3D-AD
General-purposed registration-based point cloud anomaly
detection method (Reg3D-AD)를 제안한다. Reg3D-AD는 특징 표현 방식을 활용하여 훈련 프로토타입의 지역 및 전역 특징을 보존한다. 두 가지 구별되는 특징이 존재한다. 첫 번째 특징은 각 포인트 클라우드의 좌표값, 즉 x, y, z 값에 관련된다. 두 번째 특징은 PointMAE 특징으로, 이는 훈련 프로토타입을 전체적으로 특징짓는다. 좌표값은 개별 포인트의 위치 속성을 요약하는 반면, PointMAE 모델은 훈련 프로토타입의 포괄적인 표현을 달성하는 것을 우선시한다.
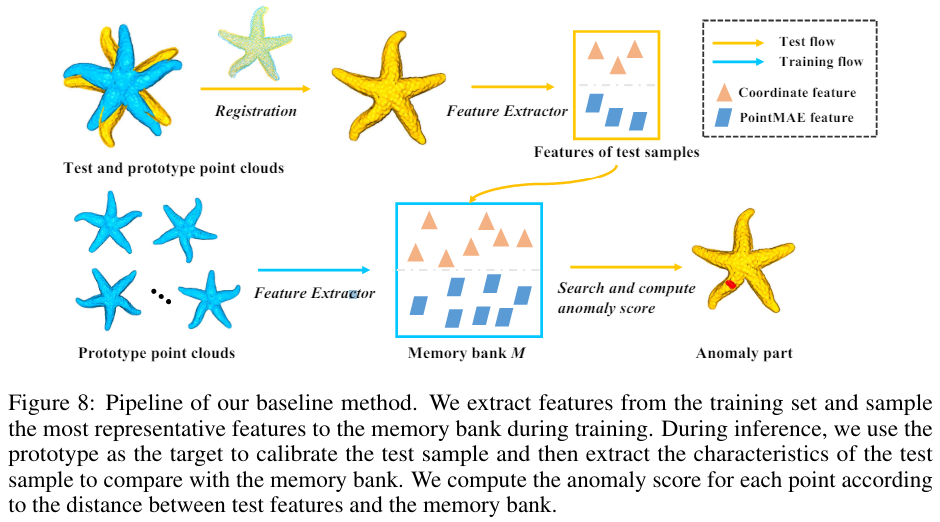
Memory Bank의 크기를 보존하기 위해 Coreset 샘플링 기술을 구현한다. 효율적인 데이터 관리와 함께, 훈련 프로토타입의 중요한 특성을 유지하면서도 검출 정확도를 높이기 위해 설계되었다.
Anomaly score calculation
1. Test 3D 객체는 먼저 RANSAC 알고리즘을 통해 register된다.
2. Test 3D 객체는 적어도 하나의 포인트 클라우드가 이상으로 예측될 경우 이상으로 간주되며, point-level anomaly segmentation은 point-level feature와 global feature의 평균 점수를 통해 계산된다.
: local feature bank
: global feature bank
: object-level anomaly scores
: local feature anomaly score
: global feature anomaly score
object-level anomaly score 는 과 의 평균값으로 계산된다.
local feature anomaly score 는 3D 객체의 point-level feature 와 그에 해당하는 가장 가까운 이웃 사이의 최대 점수 이다.
수식을 뜯어보면 은 와 에 대해서 모든 점들에 대해 거리를 계산하고, 가장 가까운 특정한 점 을 찾는다. 그리고 그 특정한 점 으로 부터 가장 거리가 먼 를 찾는다.
그리고 은 앞에서 구한 테스트 포인트 에 대해, local feature bank내의 가장 가까운 이웃을 찾는다.
이 둘의 거리를 로 삼는다.
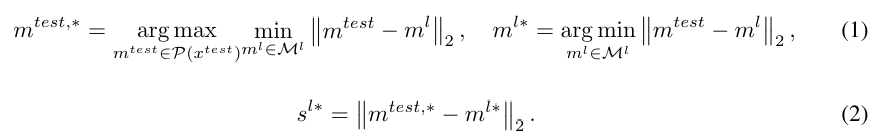
그 후, PatchCore에서 중요한 reweighting method를 anomaly socre를 tune하는데 사용하였다. 여기서 은 test patch-feature 에 대해 안의 nearest patch-features를 뜻한다.
수식을 조금 더 자세히 살펴보자. 와 가장 가까운 점 의 거리는 가장 가까운 점 의 b nearest features들의 상대적 거리로 reweighting 된다. 확률값을 1로 빼줌으로써 주변 b 근접 이웃에 비해서 비교적 아주 가까울 수록 더 커지게된다. 이 값을 에 곱해줌으로써 거리를 상대적 거리 확률로 변환할 수 있다.
global feature anomaly score 는 local feature와 동일하게 구해지고 최종 object-level anomaly score는 로 구할 수 있다.
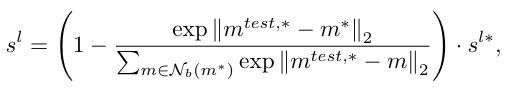
4. Analysis of ADBENCH-3D
표 4에 제시된 결과는 대부분의 3D 이상 탐지 알고리즘들이 Real3D-AD의 요구 사항을 충족하지 못한다는 것을 나타낸다. 4.1의 설정을 재검토해보면, 이 설정이 소수샷 이상 탐지와 유사한 점이 눈에 띈다. 이는 각 카테고리의 교육 데이터셋이 단지 4개의 프로토타입으로 구성되어 있기 때문이다. 대부분의 최신 최첨단 3D 이상 탐지 알고리즘은 소수샷 시나리오에서 이상을 탐지하는 작업에 특별히 설계되지 않았다. 이러한 도전을 해결하기 위해, 프로토타입 데이터의 활용을 최적화하고 획득된 포인트 클라우드 데이터가 공간적 상대 위치에 의해 영향받지 않도록 보장하는 것이 중요하다.
6. Limitations & Potential negative societal impacts
Limitations
이 데이터는 3D 스캐너에서 얻어졌으며 공간 정보만을 포함하는데, 이는 산업 생산에서 일반적인 관행이다. 그러나, 여러 RGBD 이미지를 calibrating하고 stitching 하거나 modeling software rendering을 사용하여 표준화된 RGB 포인트 클라우드 템플릿을 얻을 수 있을 것이다. RGB 포인트 클라우드 템플릿은 RGB (2D)와 포인트 클라우드 (3D) 이상 탐지에 적용될 수 있다. 추가적으로 이 데이터는 rendering conditions를 제어하여 다른 각도에서 깊이 이미지를 생성할 수 있어, 그 관점에서 이상 탐지를 가능하게 한다. 이 부분은 아직 연구되지 않았다. 게다가, 테스트 포인트 클라우드의 가장자리가 잘려 나가기 때문에 잘못된 탐지에 취약하다. 따라서, 이러한 문제를 더 효과적으로 해결할 수 있는 더 진보된 모델이 기대된다.
7. Appendix
A. Experiment setup
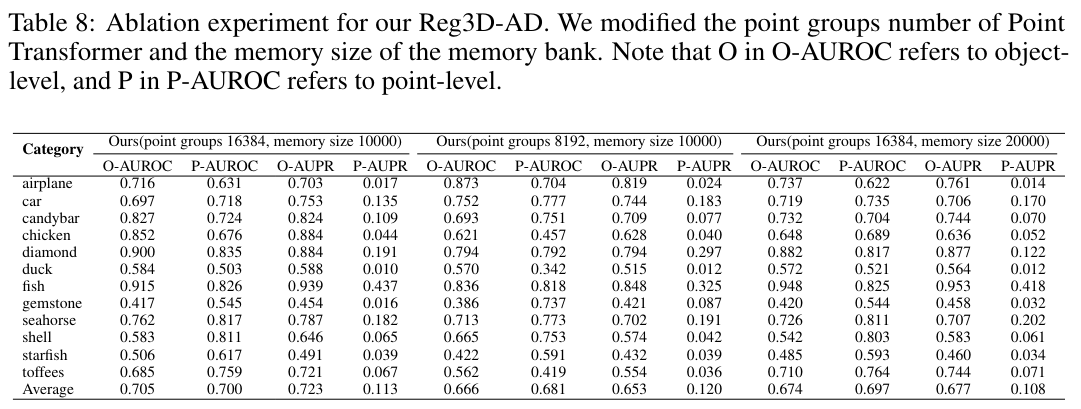
GPU 메모리 제한으로 인해, 벤치마크 방법에 서브 샘플링을 적용하였다. BTF의 경우, 훈련 샘플의 포인트를 100:1의 비율로 샘플링하여 저장하고, 테스트 샘플의 경우 500:1의 비율로 포인트를 샘플링합니다. 각 포인트의 이상 점수를 계산한 후, k-최근접 이웃(KNN) 알고리즘을 사용하여 샘플링되지 않은 포인트의 이상 점수를 추정하였다. M3DM에 대해서는 포인트 변환기의 포인트 그룹 수를 16384로 설정합니다. PatchCore를 기반으로 한 우리의 실험에서는 memory bank의 크기를 일관되게 10000으로 설정했습니다.
B. Experiments
참고자료
대표적 산업 적용 예시
간략한 나의 생각)
해당 데이터셋을 통한 연구는 색상 정보가 없다는 한계점이 존재
하지만, fully한 3D를 통해서 프로토 타입 확보가 가능하고 이를 통해서 여러 inline inspection 에 대한 딥러닝 접목 연구가 충분히 잘 될 수 있음. 대신 해당 데이터는 프로토타입이 하나로 굳어지는 강체인 경우에 적합함.
