[Paper Review] RoFormer: Enhanced Transformer with Rotary Position Embedding
Paper I should read
Transformer-based language models 의 학습 관점에서 positional information 을 다양한 방법으로 조사한 논문이다. 그 중 positional information 을 효과적으로 반영하는 Rotary Position Embedding (RoPE) 를 제안하였다.
RoPE 는 절대적 위치를 rotation matrix 로 인코딩하면서 관계 의존성을 self-attention 을 통해 반영하였다.
RoPE 의 기여점은 크게 3가지이다.
1. Flexibility of sequence length
ㅇ 고정된 길이의 입력 데이터에만 국한되지 않고, 다양한 길이의 입력 데이터를 효과적으로 처리할 수 있다.
2. Decaying inter-token dependency with increasing relative distances
ㅇ RoPE 는 상대적 거리가 증가함에 따라 토큰 간의 의존성을 자연스럽게 감소시키는 특성을 가지고 있다.
ㅇ 이는 모델이 멀리 떨어진 토큰 간의 상관관계를 적절히 줄여줌으로써, 더 효율적이고 정확한 처리를 가능하게 한다.3. Capability of equipping the linear self-attention with relative position encoding
ㅇ Linear self-attention 을 통해 입력 데이터 내에서 토큰들의 상대적 위치 정보를 효과적으로 활용할 수 있다.
Background
Absolute position embedding
시간 관계상 논문의 일부분으로 작성하였다. 절대적 위치 임베딩은 말 그대로 절대적인 위치에 따른 수치를 더해주는 것이다.

Relative position embedding
관계를 고려한 위치 임베딩이다. (6) 번 식에서 = (Query, Key) + (Query, Key Position) + (Query Position, Key) + (Query Position, Key Position) 로 정의하였다. 각 Query 와 Key 마다 위치를 고려하겠다는 취지이다. 여기서 (7) 번 식은 앞선 식의 Key Position 을 Query 위치와의 차이로 바꿈으로써 위치의 차이를 학습하고자 한다. 하지만, (8) 번 식은 앞선 수식들을 뒤 엎고 trainable bias 를 더함으로써 식을 재수립하였다. (9) 번 식은 (6) 번식의 중간 두 항의 의미가 거의 없음을 지적하고 위치간 새로운 학습파라미터와 trainable bias 를 통해 학습하고자 하였다.

Proposed approach
rotation matrix
아래의 general form 을 보면 알 수 있듯이, position embedding 이 차원에 따라 진행됨을 알 수 있다. 이는 입력 토큰의 개수와 무관하게 임베딩 차원에 따라 결정되는 것임으로 flexibility of sequence length 임을 알 수 있다.

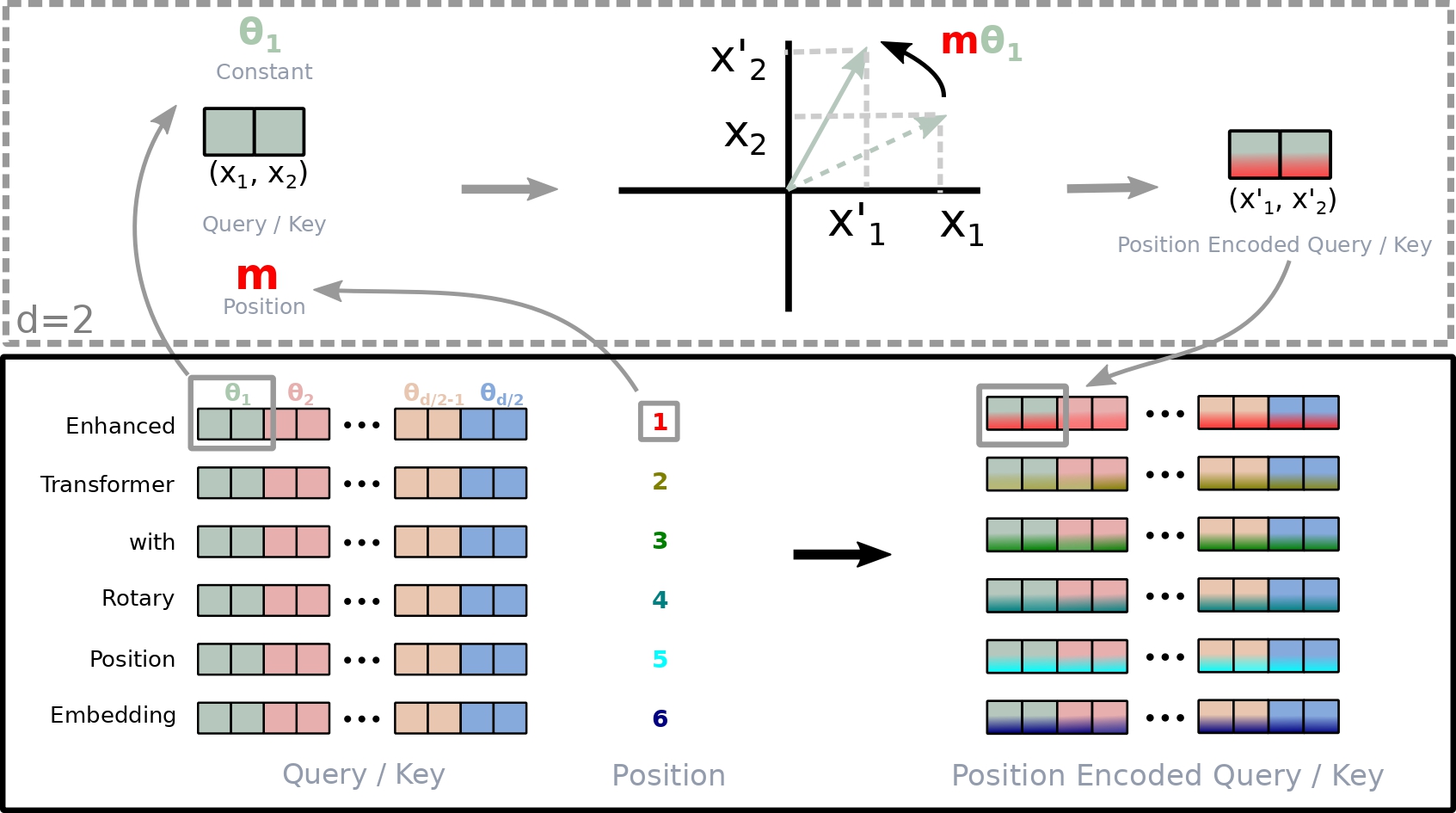
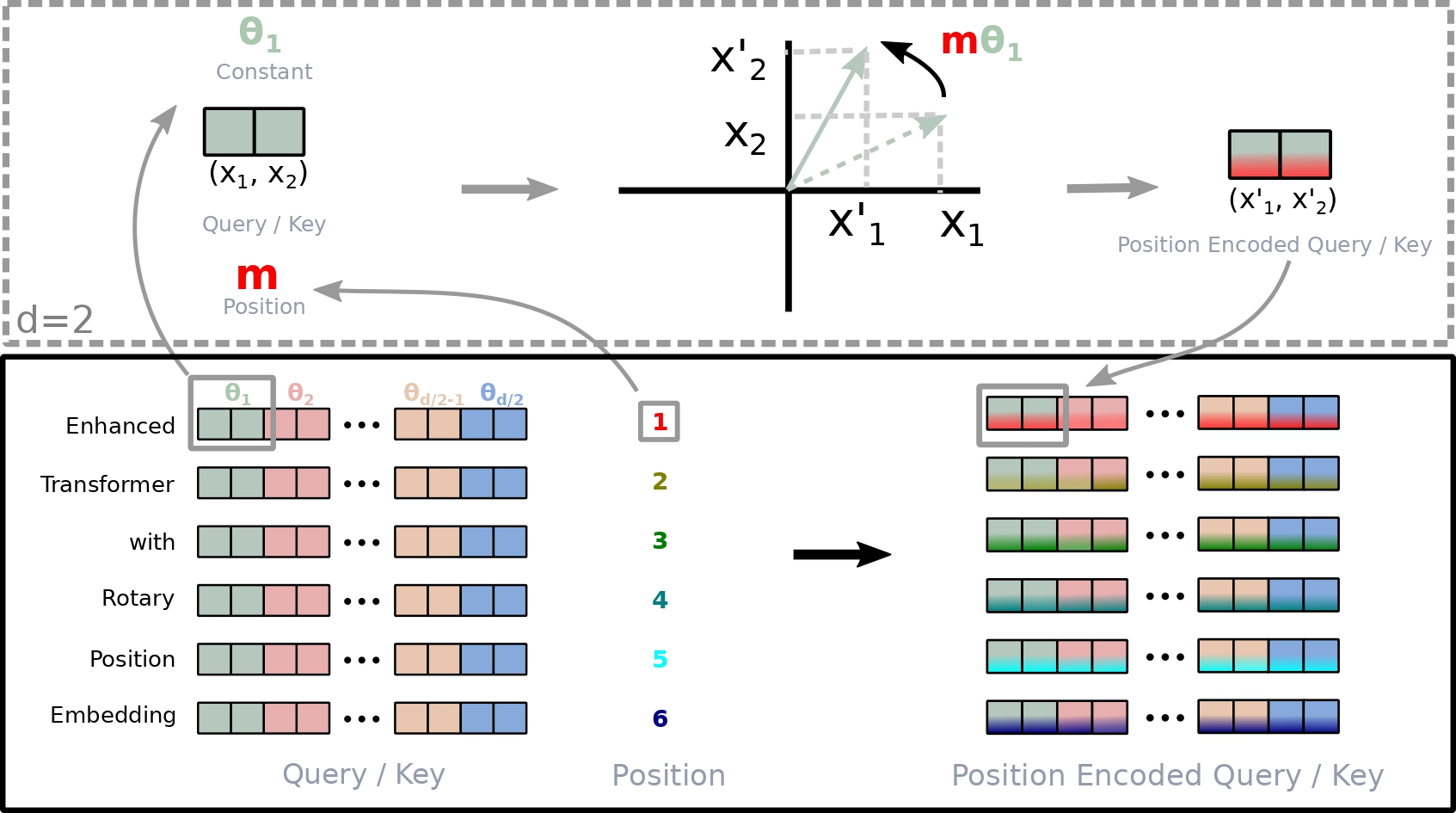
정리해보면, token embedding 이 된 word vector 에 weight matrix 를 통해 query, key 를 만든다. 그리고 해당 벡터에 rotation matrix 를 곱하는데, 이때 각도 는 absolute position embbeding 과 동일하며 차원은 d/2 차원을 사용한다. 만약에 d=3 이라면 d차원의 query 를 3차원 벡터로 각각 쪼개어서 position embedding을 수행한다는 의미이다.
각 임베딩 단어를 query, key, value 로 생성하는 과정은 아래의 그림으로 이해해보자.
이렇게 생성된 q,k,v 에 대해 아래의 그림처럼 d 차원 만큼 쪼갠 후 rotation matrix 를 통해 위치를 반영하면 position encoded query/ key 처럼 위치가 반영된 것을 볼 수 있다. 여기서 색상이 다른 것은 단어가 멀어질 수록 가 커짐으로 decaying inter-token dependency 가 자동으로 반영되는 것을 알 수 있다.
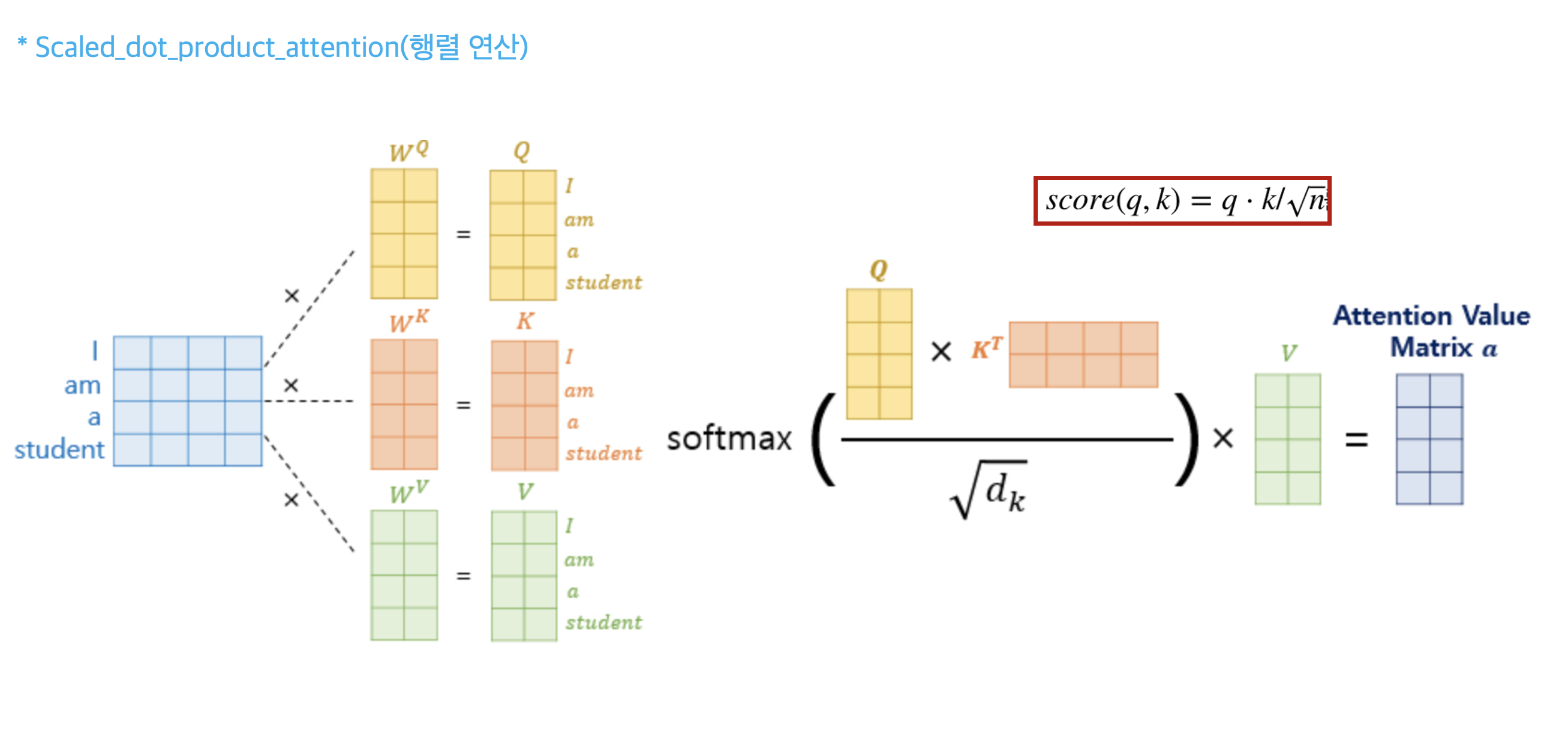
linear attention
Attention score 를 계산할 때, query 에는 softmax 를 key 에는 exponential 을 적용하였다. 기존의 attention 은 query, key 내적 후에 전체 softmax 였지만, RoPE 에서는 query 의 softmax 값으로 attention 을 계산하기 때문에 계산 효율성이 더욱 좋다고 한다. 여기서 적용된 함수는 non-negative function 이면 모두 적용할 수 있다.

더욱 자세한 내용은 논문을 참고하길 바랍니다. 감사합니다.
