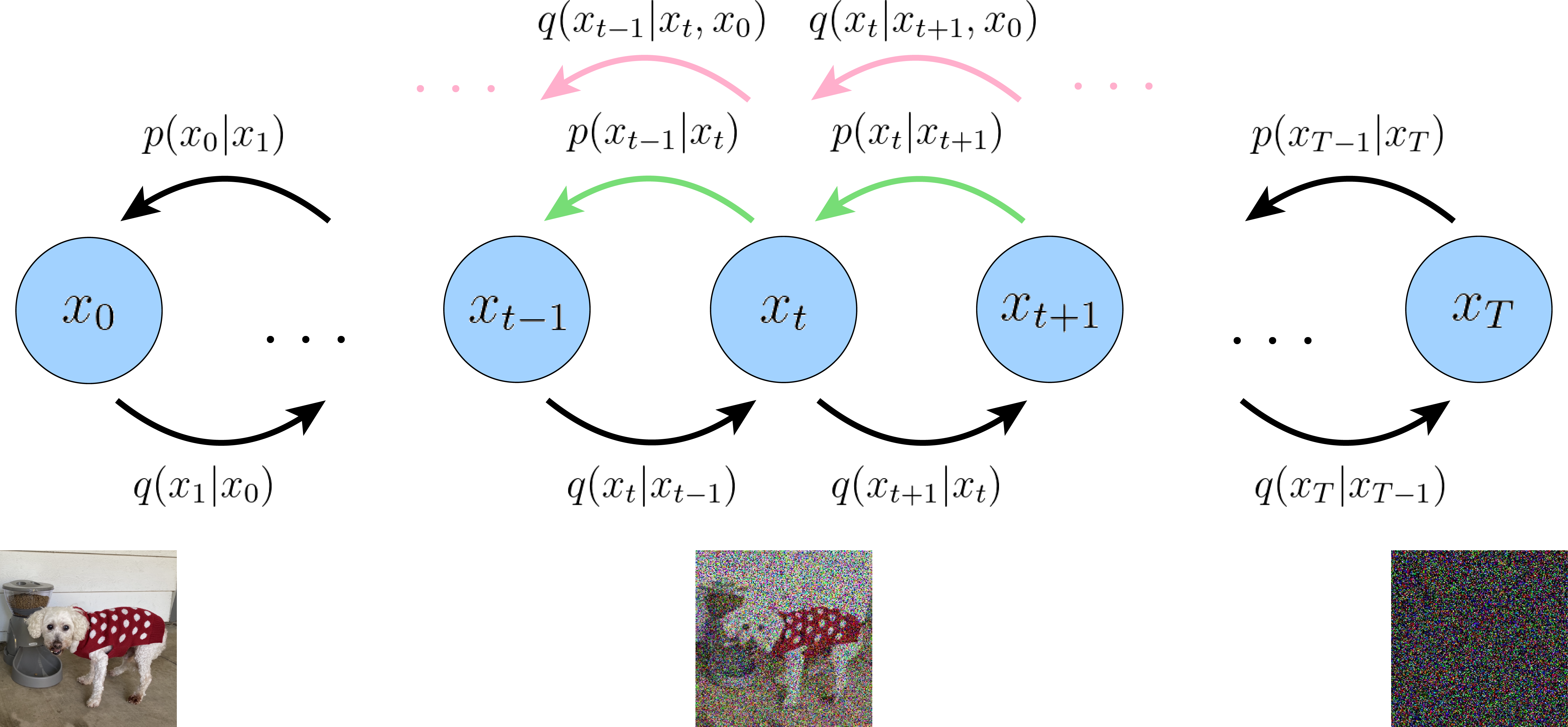
생성형 AI의 트렌드를 이끌고 있는 Diffusion Model(확산 모델). 이 모델의 핵심은 "데이터를 복원하는 능력"을 학습하는 것입니다. 하지만 복원을 배우기 위해서는 먼저 "데이터를 아주 정교하게 망가뜨리는 과정"이 필요합니다.
오늘은 디퓨전 모델의 기초가 되는 Forward Process(확산 과정)의 수식과, 왜 하필 그 수식을 써야 했는지에 대한 수학적 원리를 아주 쉽게 풀어서 정리해 보겠습니다.
1. 전체 그림: 데이터를 모래성처럼 무너뜨리기 (Forward Process)
Diffusion 모델의 학습 준비 단계는 멀쩡한 원본 데이터()에 1,000번()에 걸쳐 조금씩 노이즈를 섞어, 결국 완전한 노이즈()로 만드는 과정입니다.
- : 원본 데이터 (깨끗한 이미지)
- : 가우시안 노이즈 (형체를 알아볼 수 없는 상태)
이 과정은 마치 정교하게 쌓은 모래성()에서 모래 알갱이를 하나씩 흩뿌려, 나중에는 그냥 모래 더미()로 만드는 것과 같습니다. 이 과정을 수식으로 표현하면 다음과 같습니다.
여기서 (Product) 기호, 조건부 확률 의 의미는 단순합니다.
"현재 상태()는 바로 직전 상태()에 의해서만 결정되며, 이 작은 변화들이 1,000번 쌓여 전체 과정이 된다."
이를 마르코프 체인(Markov Chain)이라고 부릅니다. 과거의 모든 이력이 아니라, '바로 직전의 상태'만이 현재에 영향을 준다는 뜻입니다.
2. 핵심 레시피: 가우시안 전이와 노이즈 스케줄
그렇다면 구체적으로 직전 단계()를 어떻게 망가뜨려서 다음 단계()를 만들까요? 그 레시피는 다음과 같습니다.
수식이 복잡해 보이지만, 코드로 구현하면 아래 한 줄과 같습니다. (이를 Reparameterization Trick이라고도 합니다.)
- : 랜덤 노이즈 (표준 정규분포에서 뽑은 값)
- : 노이즈 스케줄(Noise Schedule). 이번 단계에 노이즈를 얼마나 섞을지 결정하는 아주 작은 값 (예: 0.0001)
이 식의 의도는 명확합니다.
1. 원본 유지: 만큼 이전 이미지()를 남기고,
2. 노이즈 추가: 만큼 새로운 노이즈()를 채워 넣습니다.
3. 왜 하필 '루트()'를 씌울까? (Variance Preservation)
여기서 많은 분들이 궁금해하는 지점이 있습니다.
"그냥 와 를 더하면 1이 되는데, 왜 굳이 복잡하게 제곱근()을 씌워서 계수를 정하나요?"
이유는 "데이터의 에너지(분산, Variance)를 일정하게 유지하기 위해서"입니다. 이를 이해하기 위해 간단한 수학적 성질을 알아야 합니다.
[분산의 성질]
확률 변수에 상수 를 곱하면, 분산은 가 아니라 (제곱)만큼 변합니다.
실험: 루트가 없을 때 vs 있을 때
원본 신호()와 노이즈()의 분산(에너지)이 모두 1이라고 가정하고, 두 가지 방법으로 섞어보겠습니다. (편의상 50:50, 즉 로 가정)
Case A: 루트 없이 그냥 섞을 때 (실패)
이 경우 분산은 각각 제곱되어 더해집니다.
- 신호 분산:
- 노이즈 분산:
- 총 분산: 0.5
결과: 에너지가 1에서 0.5로 반토막 났습니다. 이 과정을 반복하면 이미지가 점점 어두워지다가 0(검은색)으로 사라져 버립니다 (Vanishing Signal).
Case B: 루트를 씌워서 섞을 때 (Diffusion의 방식)
이제 분산을 계산해 봅니다.
- 신호 분산:
- 노이즈 분산:
- 총 분산: 1.0
결과: 에너지가 정확히 1로 유지됩니다!
결론
디퓨전 모델은 다음 수식이 성립하도록 설계되었습니다.
덕분에 1,000번을 반복해서 노이즈를 섞더라도 픽셀 값이 폭발하거나(Exploding) 사라지지 않고, 안정적인 분포(Standard Normal Distribution)를 유지할 수 있는 것입니다.
요약
Diffusion의 Forward Process는 단순히 이미지를 망가뜨리는 것이 아닙니다. 수학적으로 매우 정교하게 설계된 "에너지 보존 법칙" 하에서, 원본 데이터를 표준 정규분포(Pure Noise)로 변환하는 과정입니다.
이 과정을 통해 모델은 반대로 "노이즈에서 원본을 찾아가는 길(Reverse Process)"을 학습할 준비를 마치게 됩니다.
