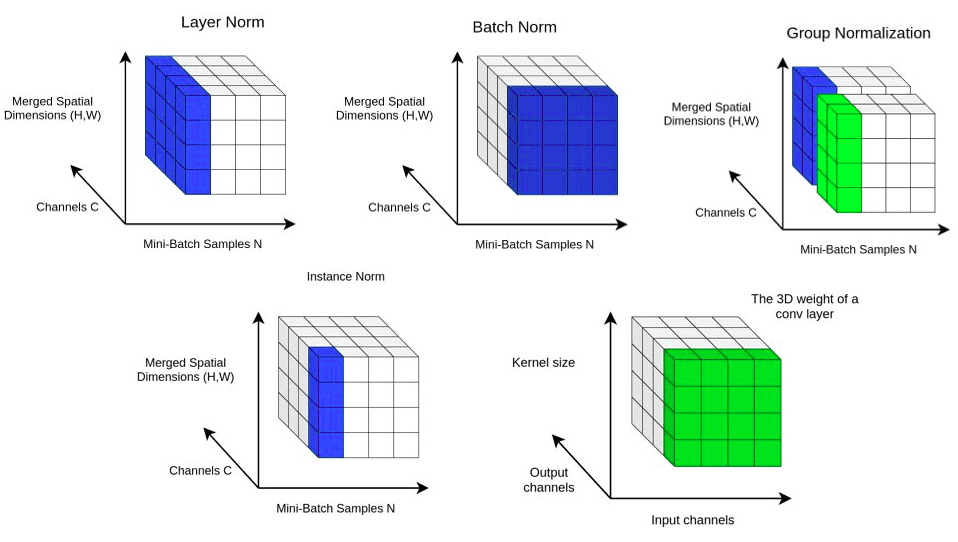

최근 Stable Diffusion이나 Cascaded Diffusion Model(CDM) 같은 최신 생성 모델 논문들을 살펴보면 공통적으로 발견되는 특징이 있습니다. 바로 우리에게 익숙한 Batch Normalization(BN)이 사라지고, 그 자리를 Adaptive Group Normalization(AdaGN)이 차지하고 있다는 점입니다.
왜 최신 트렌드는 BN을 버리고 GN을 선택했을까요? 오늘은 그 이유를 Batch Size와 Diffusion의 특성 관점에서 아주 쉽게 풀어보겠습니다.
1. 직관적 비교: "전국 모의고사" vs "나만의 성취도 평가"
가장 먼저 Batch Norm(BN)과 Group Norm(GN)의 차이를 학교 시험 성적에 빗대어 이해해 봅시다.
🅰️ Batch Normalization (BN): "상대 평가"
"철수야, 너 이번 수학 점수가 반 평균보다 얼마나 높니?"
- 방식: 배치(Batch) 내 모든 데이터(학생들)의 특정 채널(과목) 평균을 구해서 정규화합니다.
- 특징: 남들(다른 데이터)의 점수가 내 평가에 영향을 줍니다.
- 치명적 단점: 만약 시험 보는 학생이 단 1명(Batch Size=1)이라면? 비교 대상이 없어서 평균을 낼 수 없고, 통계가 엉망이 되어 학습이 불가능해집니다.
🅱️ Group Normalization (GN): "절대/자체 평가"
"철수야, 너 이과 과목(수학, 과학) 평균에 비해 이번 수학 점수는 어때?"
- 방식: 데이터 하나(학생 한 명) 안에서 연관된 채널끼리(그룹) 묶어서 평균을 냅니다.
- 특징: 남들이 몇 점을 받았든 상관없습니다. 오직 내 데이터 내부의 특성만 봅니다.
- 강점: 시험 보는 학생이 1명(Batch Size=1)이어도 아무 문제 없이 완벽하게 계산할 수 있습니다.
2. 왜 Diffusion Model은 Group Norm을 써야 할까?
이미지 분류(Classification)에서는 BN이 여전히 강력하지만, 3D 데이터나 Diffusion 같은 생성 모델에서는 BN이 치명적인 독이 될 수 있습니다. 그 이유는 크게 두 가지입니다.
이유 ①: Heavy Data와 'Batch Size 1'의 한계
고해상도 3D 데이터나 무거운 모델을 다룰 때는 GPU 메모리의 한계로 인해 Batch Size를 1 또는 2로 아주 작게 설정할 수밖에 없습니다.
- BN: 배치가 작으면 통계적 대표성이 사라져 학습이 망가집니다.
- GN: 배치가 1이든 100이든, 각 데이터 내부에서 계산하므로 항상 안정적인 성능을 보장합니다.
이유 ②: Diffusion의 핵심 'Time Mixing' 문제
Diffusion 모델 학습 시, 하나의 배치 안에는 서로 다른 시점(Timestep)의 데이터가 섞여 들어옵니다.
- 데이터 A: (거의 완성된 깨끗한 이미지)
- 데이터 B: (완전한 노이즈)
이때 BN을 쓰면 치명적인 문제가 발생합니다. "깨끗한 이미지"와 "노이즈 이미지"의 픽셀 값을 섞어서 평균을 내버리기 때문입니다. 이렇게 되면 모델은 시점별 미세한 노이즈 차이를 학습하지 못하고 혼란에 빠집니다.
반면 GN은 데이터 A는 A끼리, B는 B끼리 독립적으로 계산하므로 시점 정보가 섞이지 않고 온전하게 유지됩니다.
3. Adaptive Group Norm (AdaGN): GN의 진화
Diffusion 모델은 단순히 GN만 쓰는 것이 아니라, 여기에 조건(Condition)을 주입하는 Adaptive Group Norm을 사용합니다.
어떻게 동작하나요?
1. Group Normalization 기본 수식
Group Norm의 표준 수식은 다음과 같습니다:
- : 그룹별로 계산된 평균과 표준편차
- (Scale), (Shift): 정규화된 값의 크기를 조절하고 이동시키는 파라미터
2. Adaptive Group Normalization (AdaGN)의 특징
Diffusion 모델에서 사용하는 AdaGN은 와 를 고정하지 않고, 시점(t)과 조건(Condition)에 따라 실시간으로 예측합니다.
이 방식을 통해 모델은 각 스텝마다 노이즈의 강도에 맞춰 정규화의 정도를 유연하게 조절할 수 있습니다.
일반적인 정규화 수식에서, (Scale)와 (Shift)를 학습 파라미터로 고정하지 않고 외부에서 주입합니다.
- Time Embedding: 현재가 노이즈가 많은 초기 단계인지, 완성 단계인지() 정보를 벡터로 만듭니다.
- Condition Embedding: 생성하려는 대상의 클래스나 특징 정보를 벡터로 만듭니다.
- AdaGN: 위 두 정보를 MLP(Linear Layer)에 태워 와 를 예측하고, 이를 Group Norm 결과에 적용합니다.
결론
결국 Diffusion 모델은 "작은 배치 사이즈에서도 잘 돌아가야 하고(GN)", "시점과 조건에 따라 이미지를 다르게 변조해야 하기(Adaptive)" 때문에 AdaGN이 표준으로 자리 잡게 된 것입니다.
