Positional Encoding: 딥러닝의 '디테일'을 놓치지 않기.
인공지능
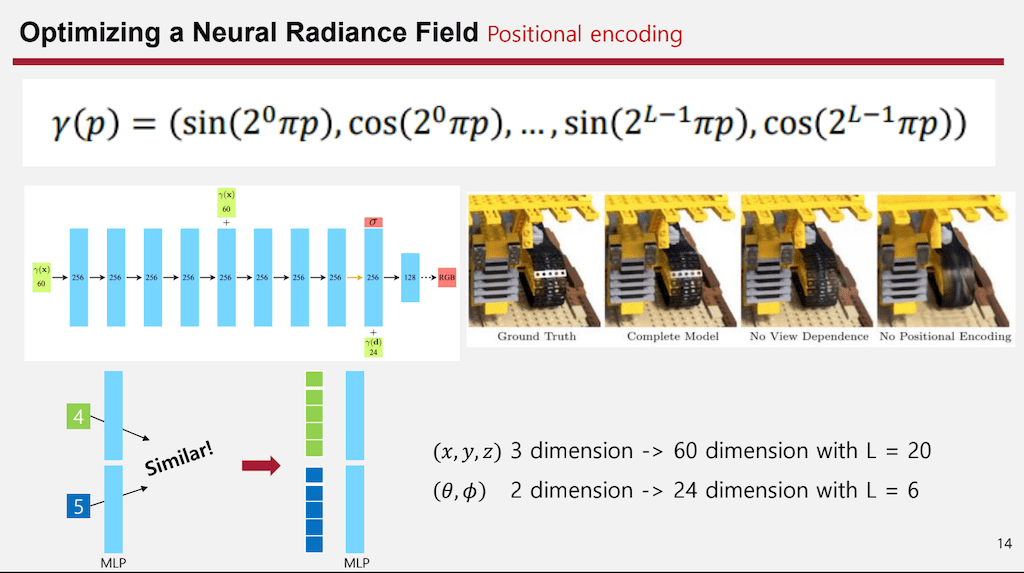
3D 비전이나 생성 모델(Generative Models)을 다루다 보면, 단순히 좌표값 를 네트워크에 넣었을 때 결과물이 뭉개지거나 흐릿하게 나오는 현상을 자주 겪게 됩니다. 이때 마법 같은 해결책이 바로 Positional Encoding입니다.
딥러닝, 특히 NeRF(Neural Radiance Fields)나 3D 생성 모델을 공부하다 보면 Positional Encoding이라는 개념을 필수적으로 마주하게 됩니다. 단순히 "좌표를 확장한다"라고만 알고 넘어가기엔, 이 기술이 결과물의 품질—특히 고주파(High-frequency) 디테일—에 미치는 영향은 실로 엄청납니다.
왜 딥러닝 모델은 그냥 좌표를 입력받으면 세밀한 형상을 만들지 못할까요? 그리고 Positional Encoding은 어떻게 이 문제를 해결할까요?
1. 딥러닝 네트워크의 고질병: Spectral Bias (스펙트럼 편향)
우리가 흔히 사용하는 MLP(Multi-Layer Perceptron) 네트워크에는 치명적인 게으름이 하나 있습니다. 바로 "저주파(Low-frequency) 성분을 먼저 학습하려는 성향"입니다. 이를 학계에서는 Spectral Bias라고 부릅니다.
- 저주파(Low-frequency): 색상이 완만하게 변하거나, 표면이 매끄러운 부분 (전반적인 형태).
- 고주파(High-frequency): 급격하게 변하는 경계선, 뾰족한 모서리, 미세한 질감 (디테일).
네트워크에 좌표를 있는 그대로 입력하면, 네트워크는 아주 천천히 변화하는 매끄러운 함수로 근사하려고 합니다. 그 결과, 뾰족한 모서리는 둥글게 뭉개지고, 미세한 표면의 요철은 사라져 버립니다. 마치 초점이 나간 사진처럼 말이죠.
2. Positional Encoding이란 무엇인가?
Positional Encoding은 저차원의 입력 데이터(예: 3D 좌표)를 고차원의 벡터 공간으로 맵핑(Mapping)하는 기법입니다. NLP의 Transformer에서 단어의 순서를 알려주기 위해 처음 유명해졌지만, 비전(Vision) 분야에서는 좌표 기반 신경망(Coordinate-based Neural Network)의 성능을 극대화하기 위해 사용됩니다.
가장 대표적인 형태는 사인(Sin)과 코사인(Cos) 함수를 이용한 방식입니다. 입력 좌표 가 있을 때, 이를 다양한 주파수의 함수로 변환합니다.
이 수식을 거치면 단순했던 좌표 하나가 여러 주파수 대역을 가진 긴 벡터로 변신하게 됩니다.
3. 왜 고주파 형상(Sharp Details) 생성에 더 유리한가?
이 부분이 핵심입니다. Positional Encoding이 고주파 형상을 잘 살리는 이유는 "네트워크가 고주파 패턴을 볼 수 있도록 강제하기 때문"입니다.
① 입력 공간의 확장 (Manifold Mapping)
인접한 두 좌표 와 은 원래 매우 비슷한 값을 가집니다. 네트워크 입장에서는 이 둘을 구별하기가 쉽지 않습니다. 하지만 고주파수가 포함된 Positional Encoding을 통과하면, 아주 미세한 좌표 차이도 고차원 공간에서는 완전히 다른 벡터 값을 갖게 됩니다. 덕분에 네트워크는 미세한 위치 변화를 민감하게 감지할 수 있습니다.
② 푸리에 피처(Fourier Features) 효과
2020년 발표된 논문 "Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains" 에서는 이를 수학적으로 증명했습니다.
- Encoding 없음: 네트워크가 저주파수부터 천천히 학습하므로, 학습이 끝날 때까지 고주파 디테일(엣지, 텍스처)을 배우지 못함.
- Encoding 적용: 데이터를 고주파수 대역으로 미리 펼쳐서(Mapping) 네트워크에 던져줍니다. 이를 통해 네트워크는 Spectral Bias를 우회하여, 학습 초기부터 고주파수 영역(디테일한 형상)을 효과적으로 학습할 수 있게 됩니다.
4. 결론: 디테일의 차이는 여기서 온다
결국 Positional Encoding은 딥러닝 모델에게 "돋보기"를 쥐여주는 것과 같습니다. 그냥 보면 밋밋해 보이는 공간도, Positional Encoding을 통해 보면 수많은 주파수의 조합으로 보입니다.
만약 여러분이 3D 모델링, 덴탈 CAD, 혹은 NeRF와 같은 프로젝트를 진행 중인데 결과물이 찰흙처럼 뭉개져 나온다면? 모델의 깊이를 늘리기 전에 Positional Encoding의 차원 수()나 주파수 대역(Scale)을 조절해 보세요. 잃어버렸던 날카로운 엣지와 디테일이 살아날 것입니다.
