딥러닝, 특히 컴퓨터 비전(Computer Vision) 분야에 입문하면 가장 먼저 접하게 되는 두 가지 큰 작업(Task)이 있습니다. 바로 분류(Classification)와 분할(Segmentation)입니다. 얼핏 들으면 비슷해 보일 수 있지만, 이 둘은 모델의 구조부터 결과물까지 근본적으로 다릅니다.
오늘은 CNN(합성곱 신경망)의 관점에서 분류와 분할 모델이 구조적으로 어떻게 다른지, 그리고 실무와 이론 측면에서 어떤 차이가 있는지 완벽하게 정리해 보겠습니다.
1. 구조적 차이: 네트워크는 어떻게 다른가?
두 작업의 가장 큰 차이는 네트워크의 형태와 그 안에 들어가는 파라미터(Parameter)의 수에 있습니다.
핵심 구조
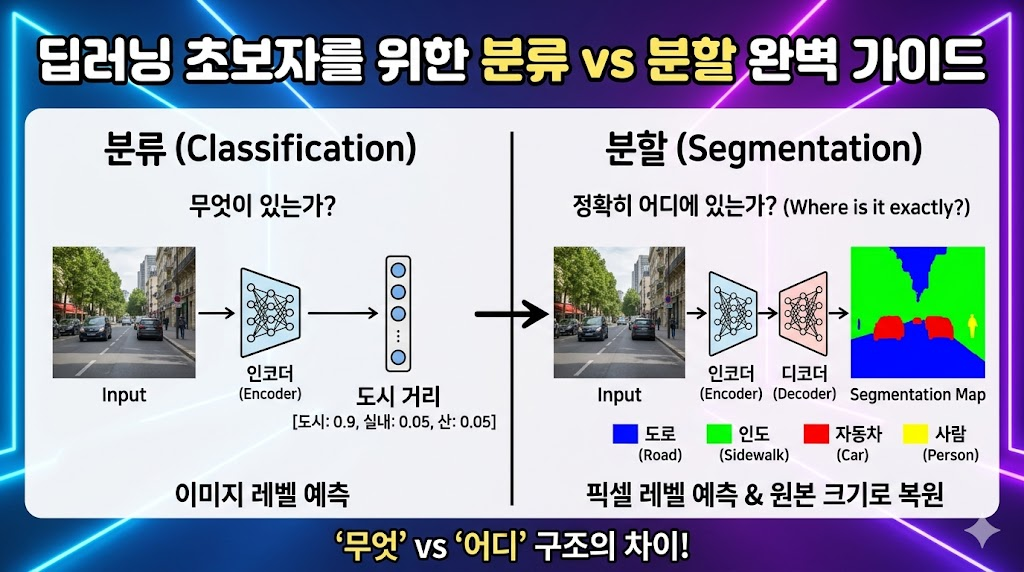
- 분류 (Classification): 입력을 받아 특징을 추출하는 인코더(Encoder / Encoding unit)만 있으면 됩니다.
- 분할 (Segmentation): 인코더로 특징을 추출한 후, 이를 다시 원래 크기로 복원하는 디코더(Decoder / Decoding unit)가 반드시 추가로 필요합니다. 즉, 인코더-디코더 구조 전체가 필요합니다.
데이터 흐름
- 분류: 이미지가 컨볼루션과 서브 샘플링(풀링)을 거치며 정보가 압축됩니다. 이 과정에서 피처 맵의 개수는 늘어나고, 차원(이미지 크기)은 점점 줄어듭니다.
- 분할: 인코더로 크기를 줄여 특징을 요약한 후, 디코더의 업-컨볼루션을 통해 원본 이미지와 동일한 차원(크기)으로 복원해 냅니다.
최종 출력
- 분류: 네트워크의 맨 끝에 Softmax 연산을 적용하여 전체 이미지에서 대상 클래스일 확률(예: 고양이일 확률 0.9, 강아지일 확률 0.1)을 계산합니다.
- 분할: 원본 해상도와 동일한 크기의 분할 맵(Segmentation map)을 생성합니다.
파라미터 수
- 분류: 네트워크가 깊어질수록 파라미터가 늘어나지만 상대적으로 가벼운 편입니다.
- 분할: 복원을 위한 디코더라는 거대한 복원 장치가 추가되기 때문에, 분류 모델에 비해 거의 2배에 달하는 파라미터가 필요합니다. 따라서 효율적인 설계가 매우 중요합니다.
2. 근본적 차이: 무엇을 예측하고, 어떻게 평가하는가?
구조적인 차이 외에도, 두 작업은 목적과 결과를 평가하는 방식에서根本적인 차이가 있습니다.
① 목적과 예측의 단위 (Image-level vs Pixel-level)
- 분류: '이미지 전체'를 보고 이 이미지가 어떤 범주에 속하는지 하나의 정답을 내립니다. 즉, "이 사진에 무엇이 있는가?(What)"에 답합니다.
- 분할: 이미지 전체가 아니라 '개별 픽셀 하나하나'가 어떤 클래스에 속하는지 분류합니다. 즉, "그것이 정확히 픽셀 단위로 어디에 있는가?(Where)"에 답하며 대상의 정확한 경계(Boundary)를 찾아냅니다.
② 출력 데이터의 형태 (Output Format)
- 분류: [고양이: 0.1, 강아지: 0.9]와 같은 1차원 벡터 형태의 확률값이 출력됩니다.
- 분할: 원본 이미지와 가로세로 크기가 완벽히 동일한 2차원(또는 3차원) 행렬(Matrix)이 출력되며, 각 픽셀 위치에 클래스 번호가 맵핑되어 있습니다.
③ 성능 평가 지표 (Evaluation Metrics)
- 분류: 모델이 전체 이미지 중 몇 개를 맞췄는지 보는 정확도(Accuracy)나 정밀도(Precision), 재현율(Recall)을 주로 사용합니다.
- 분할: 모델이 예측한 픽셀 영역이 실제 정답 픽셀 영역과 얼마나 겹치는지를 평가해야 합니다. 따라서 영역의 교집합을 척도로 하는 다이스 유사계수(Dice Similarity Coefficient, DSC)나 IoU(Intersection over Union) 같은 특화된 지표를 핵심 성능 지표로 사용합니다.
3. 실제 예시: 눈앞의 세상을 어떻게 바라보는가?
직관적인 이해를 돕기 위해, 우리가 일상에서 흔히 볼 수 있는 풍경 사진을 예로 들어보겠습니다.
분류의 예
사진을 입력받아 "이 사진은 '도심 거리' 사진이다." 혹은 "이 사진에는 '자동차'가 있다."를 판별하는 것.
분할의 예
도심 거리 사진을 보고 "이 영역은 '도로', 이 영역은 '인도', 저 영역은 '자동차', 그리고 저 픽셀들은 '사람'이다."를 픽셀 단위로 정확히 색칠하여 구분해 내는 것.
요약하자면, 분할(Segmentation)은 분류(Classification)보다 훨씬 더 정교한 공간적 정보를 요구합니다. 그렇기 때문에 디코더라는 무거운 복원 장치가 추가로 필요하며, 예측과 평가 방식도 픽셀 단위의 면적을 기준으로 이루어집니다.

AI developer