INTRO
: 이번 시간에는 Encoder에 관해서 작성한다. 여기서는 '흐름' 만 파악해도 성공한다고 본다. 제목은 'Encoder and EncoderLayer'라고 하였지만, Encoder 안에 EncoderLayer가 들어있다. 정리를 하면, Encoder 내에서의 흐름만 파악하면 이번 포스트의 목표는 달성했다고 보면 된다.
- 이번 포스트에서는 따로 실습코드(Colab Link)가 제공되지는 않는다.
: 하지만, 다음 포스트들을 꼭 숙지하고 보길 바란다. - References
- wandb 트랜스포머(Transformer) 심층 분석
- bentrevett/pytorch-seq2seq/attention_is_all_you_need.ipynb
: Seq2Seq부터 트랜스포머 공부할 때, 여기를 많이 참고했다. - 고현웅님의 트랜스포머 구현 깃허브
설명이 필요하다면?
07 About Transformer PART 01 간단한 구조 설명 에도 있는 설명이지만, 여기서도 해보겠다.
구조와 Flow
- 구조
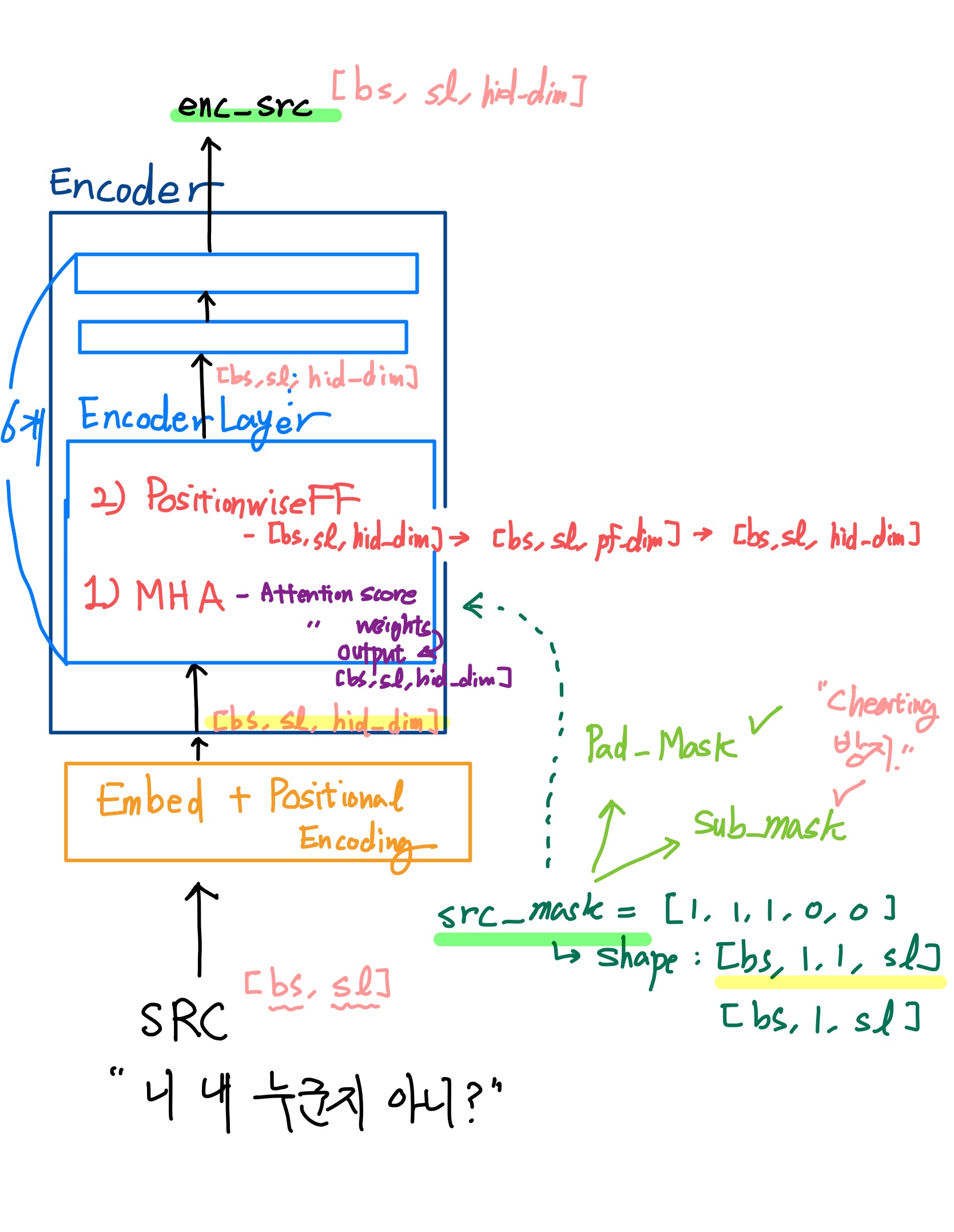
: Encoder에는 EncoderLayer가 (논문에 의하면) 6개가 존재한다. 각각의 EncoderLayer에는 MHA(Multi-Head Attention) 과 PositionwiseFF(PositionwiseFeedForwardLayer) 가 존재한다.- One More Thing!
: 필자의 코드에서는 08 About Transformer PART 02 "Positional Encoding Layer" 에서 나왔던 Embed와 PositionalEncodingLayer를 Encoder 안에다가 넣을 것이다.
- One More Thing!
- Flow
: (필자 코드 기준) 텍스트데이터가 토크나이징되고 숫자(Int)로 바뀐 다음, Encoder에 들어오자마자, Embed와 PositionalEncodingLayer를 지난다. 지나면서 Shape이 [bs, sl, hid_dim] 등의 3차원으로 되고 위치정보를 부여받게 된다. 그리고 EncoderLayer 6개를 지나게 되는데, 6개의 EncoderLayer를 지나는 동안 Shape은 [bs, sl, hid_dim]로 동일하게 유지가 된다.- EncoderLayer를 지나는 동안, 그 유명한 MHA(Multi-Head Attention) 를 지나게 된다. 지나는 동안, 문장의 각 토큰끼리의 관계도를 모두 계산한다.(attention score) 그리고 이를 Softmax를 통해 가중치로 만들고 (attention weights) 가중치를 적용한 enc_src(attention output)을 뱉어내게 된다.
- mask(필자 코드에서는 src_mask)에 관해서는 다음 포스트에서 설명
BERT, Roberta, ... 등 Encoder 모델
- Attention is all you need에서 말하는 트랜스포머 구조는 아니지만, Encoder 구조만 따와서 학습된 Pretrained Model이다. BERT, Roberta, Deberta 모두 여기에 속한다. Classification을 비롯하여 텍스트의 특정 속성을 파악하고 학습하거나 Inference 하는 TASK에서 적합하다. (Text Classificiation, NER, ... 등)
Encoder
- About Transformer PART 02 "Positional Encoding Layer" 의 Embed와 PositionalEncodingLayer 등장
- self.layers : nn.ModuleList([ ]) 안에 (마치 리스트처럼) EncoderLayer(...) 객체를 6개 담았다.
- forward 부분에서 for문을 돌리게 된다.
- layer(=EncoderLayer 객체)에 데이터가 들어가면, 입력 Shape([bs, sl, hid_dim])과 동일한 Shape으로 결과물이 reutrn 된다.
- 이를 src로 받기 때문에, for 문안에서 다시 layer의 입력으로 들어간다. 이 과정이 반복된다.
- 이런 방법으로 EncoderLayer 6개를 지나는 것이다.
- forward 부분에서 for문을 돌리게 된다.
- src_mask에 관해서는 다음 포스트에서 설명하겠다.
: 여기서는 딱히 연산되는 것이 없다.
class Encoder(nn.Module):
def __init__(self,
input_dim = len(korbow.keys()),
hid_dim = 8,
pf_dim = 16,
n_heads = 2,
n_layers = 6,
device = device,
dropout = .1):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
# input data(=src)'s Shape: [bs, sl]
# Embed와 PostionalEncodingLayer를 여기에 넣었다.
self.embed = Embed(input_dim = input_dim)
# [bs, sl] -> [bs, sl, hid_dim]
self.pe = PositionalEncodingLayer()
# 위치 정보 부여
# [bs, sl, hid_dim] -> [bs, sl, hid_dim]
self.layers = nn.ModuleList([ EncoderLayer(hid_dim,
pf_dim,
n_heads,
dropout,
device) for _ in range(n_layers)])
# self.layers = [EncoderLayer(...), EncoderLayer(...), ... ]
def forward(self, src, src_mask):
# input data(=src)'s Shape: [bs, sl]
# src_mask: [bs, 1, 1, sl]
src = self.pe(self.embed(src))
# src: [bs, sl, hid_dim] -> [bs, sl, hid_dim]
# self.layers = [EncoderLayer(...), EncoderLayer(...), ... ]
for layer in self.layers:
# layer = EncoderLayer(...)
# src: [bs, sl, hid_dim]
src = layer(src, src_mask)
# src가 layer 입력으로 들어가고 그에 대한 결과물을 src로 받는다.
# for 문 안에서 이 src가 다시 layer의 입력으로 들어가게 된다.
# 이런 방법으로 EncoderLayer 6개를 지나는 것이다.
return src
# src: [bs, sl, hid_dim] EncoderLayer
- 여기서는 그 유명한 MHA(Multi-Head Attention) 과 PositionwiseFF(PositionwiseFeedForwardLayer) 가 존재하는데 이에 대한 설명은 길어질 수 있기 때문에, 다음 포스트에서 설명하겠다.
- 몇 가지 기억해야하는 부분이 있는데 그 부분은 코드에 주석으로 작성하도록 하겠다.
class EncoderLayer(nn.Module):
def __init__(self,
hid_dim = 8,
pf_dim = 16,
n_heads = 2,
dropout = .1,
device = device, ):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
self.self_attn = MultiHeadAttention(hid_dim, n_heads, dropout, device)
self.attn_layer_norm = nn.LayerNorm(hid_dim)
self.ff = PositionwiseFeedForwardLayer(hid_dim, pf_dim, dropout, device)
self.ff_layer_norm = nn.LayerNorm(hid_dim)
def forward(self, src, src_mask):
# src: [bs, sl, hid_dim]
# src는 현재, Encoder에서 Positional Encoding Layer까지 지난 상태
# Multi-Head Attention
_src, _ = self.self_attn(src, src, src, src_mask)
# _src, _ = self.self_attn(query, key, value, mask)
# Multi Head Attention 에서 Query, Key, Value 자리에 동일한 src가 들어간다.
# 문장 내의 토큰끼리 관계도를 연산하기 위함이다.
# _src: [bs, sl, hid_dim]
# src와 동일한 Shape
# Layer Normalization after Multi-Head Attention
src = self.attn_layer_norm(self.dropout(_src) + src)
# Residual Connection(Skip connection)으로 만든 후 Layer Normalization
# self.dropout(_src) + src: Residual Connection(Skip connection) 부분
# Input
# _src: [bs, sl, hid_dim]
# src: [bs, sl, hid_dim]
# Output: 동일한 Shape
# src: [bs, sl, hid_dim]
# PositionwiseFeedForwardLayer
_src = self.ff(src)
# Input
# src: [bs, sl, hid_dim]
# Output: 동일한 Shape
# _src: [bs, sl, hid_dim]
# Layer Normalization after PositionwiseFeedForwardLayer
src = self.ff_layer_norm(self.dropout(_src) + src)
# Residual Connection(Skip connection)으로 만든 후 Layer Normalization
# self.dropout(_src) + src: Residual Connection(Skip connection) 부분
# Input
# _src: [bs, sl, hid_dim]
# src: [bs, sl, hid_dim]
# Output: 동일한 Shape
# src: [bs, sl, hid_dim]
return src
# src: [bs, sl, hid_dim] Encoder and EncoderLayer는 여기까지이다.
다음 포스트에서는 Multi Head Attention 부분을 다룰 것이다.

weird