Abstract
지금의 LLM은 parameter에 지식을 저장하여, 더 많은 사실을 포함하려면 더 큰 parameter를 가져야 한다.
-> 이러한 방식 대신 latent knowledge retriever를 사용하여 LLM을 강화하고 이를 통해 model은 각 task에서 wikipedia 같은 대규모 corpus에서 검색하여 사용 한다.
MLM을 학습으로 사용하고, 수백만개의 문서를 고려하여 검색 단계를 통해 역전파 하는 등 비지도 방식으로 knowledge retriever를 사전훈련
-> 논문은 OpenQA의 어려운 작업을 fine-tuning하여 REALM의 pretrain 효과를 보여준다.
Introduction
최근 언어 모델의 발전 방향
BERT, RoBERTa, T5 등의 model은 거대한 text corpus에서 지식을 저장
-> 이러한 방식은 parameter에 저장
-> parameter 저장 방식은 network 크기에 의해 제한이 존재 한다. (학습이 더 오래걸리거나, 모델의 크기가 더 커져야한다.)
- 논문은 REALM을 제안
textual knowledge retriever를 사용하여 LLM pretrain 알고리즘을 증강하는 방식
-> 무슨 차이점이 존재하는가?
--> predict 하는 중 검색하고 사용할 지식을 결정하도록 모델에게 요청하여 지식을 노출(corpus에서 검색을 한다.)
REALM의 핵심
-> Unsupervised text의 성능 기반 신호를 사용하여 retriever를 훈련
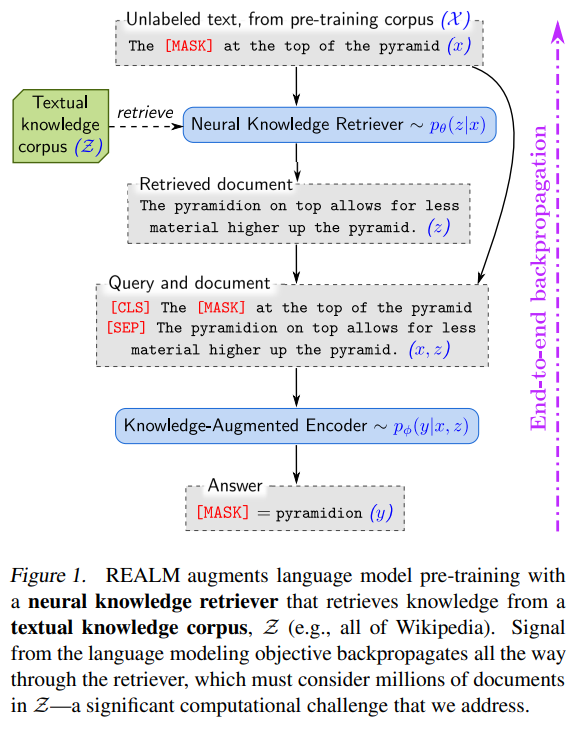
Figure1을 통해 알 수 있는점
1. text 지식의 전체 corpus를 고려하는 검색을 통하여 역전파 한다.
2. “the at the top of the pyramid”의 빈칸을 채울 필요가 있을때 retriever는 “The pyramidion on top allows for less material higher up the pyramid”를 검색하고 선택한 것에 대한 보상을 받는다.
-> latent variable language model과 주변 가능성을 최적화 하여 동작을 달성한다.
pre-training 중 대규모 neural retrieval module을 통합하는 것은 중대한 계산 과제를 가진다.
-> retriever는 수백만게의 후보 문서를 고려하고, model은 그걸 역전파 해야한다.
--> 해결하기 위해 수행한 계산이 cache되고 비동기적으로 업데이트되며, MIPS로 공식화 되게끔 retriever를 구조화 한다.
이전 연구는 신경망에 이산 검색을 추가하는 이점을 입증하였으나 대규모 문서 수집을 위해 비학습 retriever를 사용
-> 언어 모델링 문헌에서 KNN-LM은 기억력을 향상하기 위해 유사 LM 예제를 검색. 하지만 downstream 작업에 대해 fine-tuning은 되지 않았다.
--> label이 지정된 예제에서만 사용 되며, 이는 많은 지식을 포함하는 LM 예제는 제외.
REALM은 Label이 지정된 데이터가 아니라 text면 된다.
-> 이전에는 불가능 하였다.(KNN-LM)
OpenQA 작업을 통해 평가를 진행하였으며, 세가지 벤치마크에서 실험하였는데 SOTA를 달성하였다.
Background
- Language model pre-training
language model의 사전 학습의 목표 : label이 지정되지 않은 text corpus로 부터 언어의 유용한 표현을 배우는 것
-> 이후 fine-tuning을 통하여 downstream에 추가로 훈련
-> 종종 처음부터 훈련하는게 일반화로 이어지기도 한다.
논문은 BERT의 방식 MLM을 변형하여 적용
-> label이 없는 pretrain corpus가 주어지면 sampling된 text에서 token을 무작위로 masking 하여 생성
--> MLM은 구문 및 의미 정보는 물론 지식을 encoding 하는법을 배운다.
- Open-domain question answering (Open-QA)
지식을 통합할 모델의 능력을 측정하려면 지식이 중요한 downstream 작업을 보면 된다. -> Open QA능력(수백만개의 문서에서 지식을 유지해야한다)
지식 corpus를 사용하는 OpenQA 시스템에 초점을 맞추며
질문 X가 주어지면 corpus Z에서 검색을 하여 답변 y를 추출한다.
-> 이 방식을 pre-train으로 확장
Approach
REALM's generative process
pre-train 및 fine-tuning에서 REALM은 입력의 일부 x를 가지고 출력 y에 대한 분포 를 학습
pre-train : MLM (x는 masking된 문장, y는 masking된 값)
fine-tuning : x는 질문, y는 답변
REALM은 는 두 단계로 분해 된다.
입력 x가 주어질때 corpus z에서 검색을 하는 것 -> 로부터 모델링
z와 x를 모두 조건으로 하여 출력 y를 생성하는 부분 ->
전체적인 가능서을 얻기 위해 z를 latent valiable로 취급하고 z를 주변화하여 산출
Model architecture
두 가지 핵심 요소가 존재
1. 를 모델로 하는 neural knowledge retrever
2. 를 모델로 하는 knowledge-augmented encoder
Knowledge Retriever
embed input과 embed doc은 x와 z를 각각 d차원 벡터에 매핑하는 embedding 함수이다.
x와z의 relevance score는 inner product로 정의된다.
논문은 BERT-style의 transformer를 사용하여 embedding 기능을 구현
[SEP]token으로 분리, [CLS]token을 접두사, 최종[SEP]token을 추가하여 텍스트 범위에 합류
위의 것을 Transformer에 전달하여 sequence를 pooled 표현으로 사용되는 [CLS]에 해당하는 벡터를 포함하여 각 토큰에 대해 하나의 vector를 생성
마지막으로 projection matrix W로 표시되는 vector의 차원성을 줄이기 위해 linear projection을 수행
W는 다음과 같다.
은 문서의 제목, 는 문서의 본문
Knowledge-Augmented Encoder
입력 x와 검색된 문서 z가 주어지면, Knowledge-Augmented Encoder는 로 정의된다.
논문에서는 x와 z를 transformer에 입력하는 단일 sequence에 결합
-> y를 predict하기 전에 x와 z사이에 충분한 cross attention을 하게 해준다.
MLM에서 loss function은 다음과 같다.
는 trnasformer의 output vector를 의미하며, 는 x에 포함된 [MASK] token의 총 개수를 나타내며, 는 token 에 대한 학습된 단어 임베딩을 나타낸다.
OpenQA fine-tuning을 위해 Answer y를 생성하고자 할때 y는 z에서 token의 연속 sequence로 발견 될 수 있다고 가정한다.
를 z에서 y와 일치하는 span의 집합이라 하면 는 다음과 같이 정의가 가능하다
와 는 각각 span의 시작 token과 종료 token에 해당하는 Transformer output vector를 나타내고 MLP는 feed-forward network를 나타낸다.
Training
pre-train과 fine-tuning에서 y의 log likelihood()를 최대화하여 훈련
retriever랑 knowledgeaugmented encoder는 모두 신경망이라, parameter 와 에 대해 의 기울기를 계싼하고 sgd를 사용하여 최적화 가능
계산 문제가 존재
marginal probability 는 corpus Z의 모든 문서 z에 대한 합을 포함한다.
-> 논문에서는 에서 가장 높은 상위 k개의 문서를 합해 근사화
--> 어떠한 방식으로 상위 k개의 문서를 찾을 것인가?
-> 문서 수에 따라 하위 문서를 확장하는 실행 시간과 저장 공간을 사용하여 대략적인 k개의 문서를 찾는다. ()
MIPs를 사용하기 위해선 에 대해 모든 를 계산하고 효율적인 검색 index를 구성해야한다.
-> parameter 가 업데이트 되면 이 구조는 와 일치하지 않는다.
--> 논문에서는 수백 step마다 refresh하여, 상위 k개의 문서에 대해 refresh 를 사용하여 의 gradient를 다시 계산
Implementing asynchronous MIPS refreshes
parameter에 대한 gradient 업데이트를 수행하는 기본 trainer 작업과 문서를 임베딩하고 index를 생성하는 보조 index builder 작업의 두가지 작업을 병렬하여 비동기적 refresh를 한다.
-> 비동기 refresh는 pretriain과 fine-tuning 모두 사용할 수 있지만 논문에서는 pretrain에서만 사용

What does the retriever learn?
retriever는 문서 z에 할당하는 relevance score를 주기에 점수를 어떻게 변경하는지 아래를 통해 볼 수 있다.
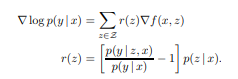
각 문서 z에 대해 gradient는 retriever가 점수 를 만큼 변경하도록 유도하며, 문서 z는 예상보다 더 좋은 성능을 보일때 긍정적인 업데이트를 받는다.
Injecting inductive biases into pre-training
REALM을 개발하는 과정에서 모델을 더욱 유도하는 추가전략
Salient span masking
masking을 하는데 있어서 랜덤한것이 아니라 두드러진 span을 masking하여 성능을 늘리는 것
Null document
검색된 상위 k개의 문서에 null 문서를 추가하여 검색이 불필요할때 일관된 sink에 적절한 credit을 할 수 있게끔 modeling
Prohibiting trivial retrievals
pre-train corpus와 knowledge corpus Z가 동일하면 너무 정보가 많은 검색 후보 z가 존재하게 된다. masking된 문장 x가 z에서 나오면 지식 증강 encoder는 z에서 masking 되지 않은 x를 봐서 y를 사소한것으로 예측할 수 잇다.
-> x와 z사이에서 정확한 문자열 일치를 배우게 되며, 이는 다른 형태의 관련성을 포착 못한다.
Initialization
와 에 대한 좋은 embedding이 없는 경우 z와 x는 무관할 가능서이 있다.
-> 지식 증강인코더는 검색된 문서를 무사히는 방법을 배운다
--> 지식 검색기는 의미 있는 gredient를 받지 못한다.
---> Cold start 문제가 발생하게 된다
-> 이를 해결하고자 와 를 wram start한다.
지식 증강 인코더의 경우 BERT pretrain 방식을 사용하여 warm start한다.
Experiments
Open-QA Benchmarks
데이터셋에 대한 설명
질문 작성자가 답변을 알지 못하는 dataset에 초점을 맞추고 있다.
-> 현실적인 정보 추구와 특정 답변을 염두해두고 공식화하는 문제를 피할 수 있다.
NaturalQuestions-Open
자연스럽게 발생하는 구글 query와 답변으로 구성되었다.
-> dataset은 검색할 제안된 위키 피디아 문서도 제공
WebQuestions
구글 API에서 하나의 seed 질문을 사용하고 관련 질문을 확장하여 수집한 dataset
CuratedTrec
MSNSearch 및 AskJeevs와 같은 사이트에서 발생된 query랑 answer 쌍 모음이다.
이 데이터셋에서는 평가를 진행하지 않는다.
Approaches compared
Retrieval-based Open-QA
대부분은 지식 corpus에서 잠재적으로 관련된 문서를 검색 -> 답변을 추출하기 위한 읽기 이해 시스템으로 답
(DrQA, HardEM, GraphRetriver, PathRetriever)
일부 최근 접근 방식은 MIPS index를 사용하여 학습 가능한 검색을 구현할 것을 제안
ORQA는 REALM과 유사한 잠재변수 모델을 사용하여 Open-QA를 공식화 하고 한계 가능성을 최대화 하여 훈련
-> 하지만 REALM은 새로운 언어 모델을 pretrain단계를 추가하고 고정 index 대신 MIPS index에 역전파를 한다
Generation-based Open-QA
sequence 예측 작업으로 modeling 하는것
GPT-2는 sequence간 주어진 context를 사용하지 않고 직접 답변하는 가능성을 보여줌 -> 하지만 fine-tuning의 부족으로 경쟁력 X
T5는 주어진 context에서 명시적 추출 없이 직접 답변을 생성하는 것이 실행 가능한 접근 방식임을 보여줌 -> context 문서가 제공디는 읽기 이해 작업에서만 실험
OpenQA를 위해 T5를 fine-tuning 하는 동시작업과 비교
Implementation Details
Fine-tuning
논문에서는 직접 비교를 가능하게 하기 위해 모든 hyper parameter를 재사용하며 지식 corpus는 88개의 BERT wordpiece로 분할되어 1300만개가 넘는 검색 후보가 된다.
-> fine-tuning 동안 상위 5개의 후보를 고려하고 전체 모델은 12GB GPU 단일 기기에서 실행 가능하다.
pre-training
BERT 최적화기를 사용하여 512의 batch size를 사용하며 3e-5의 학습률을 사용 64개의 구글 TPU에서 200K step의 pre-train한다.
MIPS index는 16개의 TPU를 걸쳐 병렬화 된다.
Main results
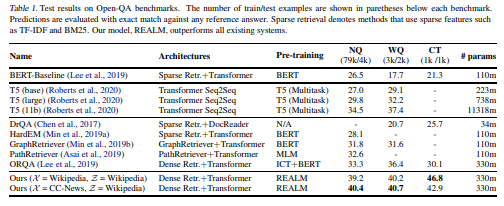
REALM은 이전의 모든 접근 방식을 상당히 능가하였음을 보여주낟.
T5-11B 모델은 이전 최고 Open-QA 시스템을 능가한다.
하지만 REALM은 T5 11B 모델보다 성능이 뛰어나고 30배 작다.
모든 시스템 중 REALM과 가장 직접적 비교는 ORQA이며, 여기서 fine-tuning 설정 등의 parameter는 동일하다.
ORQA에 비해 REALM의 개선은 더 나은 pre-train 방법이다. 결과는 single corpus setting, seperate corpus setting에 모두 적용할 수 있음을 보인다.
Analysis
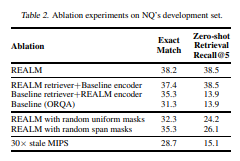
표 2에서 결과를 보여준다.
encoder or Retriever
REALM pre-training이 encoder와 Retriever를 개선하는지 둘다 개선하는지를 결정하는 것을 목표로 한다.
-> encoder와 Retriever를 모두 재설정하면 ORQA로 줄어든다. 둘다 REALM 훈련의 혜택을 개별적으로 받지만, 최상의 결과는 두 구성 요소가 모두 일치해서 작동해야한다.
Masking scheme
salient span masking 체계를 BERT에 도입된 무작위 masking과 SpanBERT에 의해 제안된 무작위 spanMasking과 비교를 한다.
-> salient span masking은 REALM에 중요하며, 직관적으로 latent variable learning은 검색 효용에 크게 의존하여 일관된 학습 신호에 더 민감하다.
MIPS index refresh rate
pre-train 동안 병렬 process를 실행하여 corpus 문서를 다시 포함하고 MIPS index를 재구성한다.
-> 500 step마다 하나의 index refresh가 발생한다.
-> 표2에서 오래된 index가 모델 교육에 악영향을 미침을 보여주며, 이를 줄이면 더 나은 최적화를 보여줄 수 있다.
Examples of retrieved documents

REALM(c)는 BERT model(a)에 비해 단어에 훨씬 높은 확률을 부여한다. REALM은 관련 사실을 가진 일부 문서를 검색하여, 정답에 소외된 확률이 증가한다. 이는 REALM이 unsupervised text로 훈련 되더라도 masked 단얼를 채우기 위해 문서를 검색할 수 있음을 보여준다.
Discussion and Related Work
Language modeling with corpus as context
점점 더 큰 범위의 context를 통합하여 일반화 하는것
Retrieve-and-edit with learned retrieval
입력 텍스트의 분산을 더 잘 설명하고 제어 가능한 생성을 하기 위해 높은 어휘 중복 및 편집 frame work를 가진 언어 모델을 제안하였다.
-> REALM은 모델의 perplexity를 줄이기 위해 가장 유용한 텍스트를 스스로 학습한다는점을 제외하고는 유사하다
Scalable grounded neural memory
REALM은 product key memory와 같은 작업과 motivation을 공유하여 이러한 확장 가능한 memory layer를 큰 언어 모델로 통합할 수 있다.
-> 차이점은 memory가 접지 되어 있다는 것
Unsupervised Corpus Alignment
sequence-tosequence models with attention에서 text는 token의 latent selection으로 생성된다.
-> 유사하기 REALM은 문서의 latent selection으로 텍스트를 생성한다.
pretrain corpus X와 지식 corpus Z에서 text 사잉의 모델 중심 unsupervised Alignment를 제공한다.
Future work
대량의 지식 corpus에 대한 추론을 수행하도록 하는 REALM과 같은 접근 방식의 최소 instance화
1.구조화된 지식에 대한 일반화
2.고자원언어(영어)로 지식을 탐색하여 저자원 언어(한국어)로 텍스트를 표현하는 능력
3. 텍스트에서 거의 보이지 않는 지식을 지식을 제공하는 image나 video를 검색하는 능력
