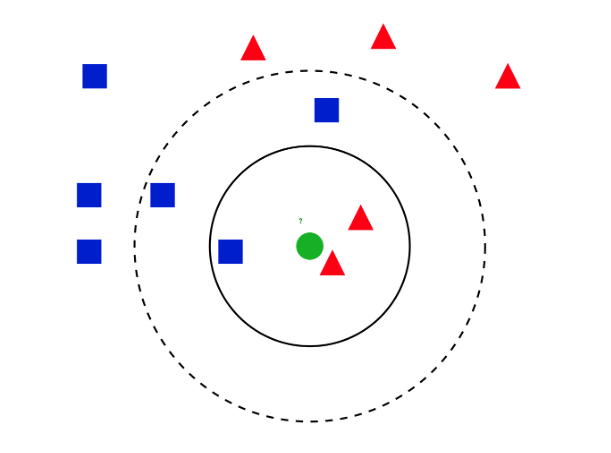
KNN
K-NN은 비슷한 특성이나 속성을 가진 것들이 가까운 곳에 모여있는다는 특징을 이용합니다. K-NN 알고리즘은 이처럼 K개의 가까운 이웃의 속성에 따라서 분류하는 방법이라고 보면 될 것 같습니다. 여기서 그럼 가까움이란 어떻게 판별하는 것일까요?
'어떤 데이터가 들어오면 그와 거리가 가까운 K개의 레이블을 참고하여 K개의 데이터 중 가장 빈도 수가 높게 나온 데이터를 분류한다.'
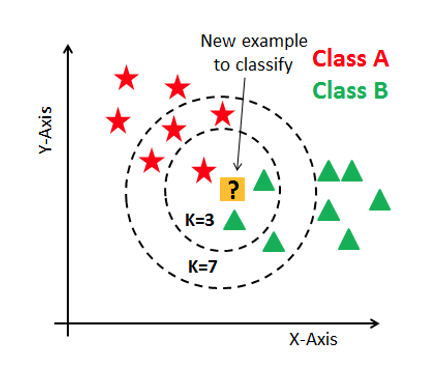
위 그림을 살펴보면 새로운 데이터가 들어오고 이 데이터를 분류해본다고 하겠습니다. 여기서 먼저 k값을 정하고 그 안에 있는 모든 데이터 값들을 가져옵니다. k=3 일때 새로운 데이터로부터 가장 가까운 것 3개를 뽑았을 시 초록이 2 빨강이 1이므로 새로들어온 값은 '초록'으로 분류가 됩니다. 반면에 k=7일때는 빨강이 4개 초록이 3개로 '빨강'으로 분류가 됩니다.
이렇듯 어떠한 값 k를 정해놓고 새로운 데이터와 갖장 가까운 값 순서대로 데이터들의 특성을 파악해 클래스를 분류한다고 보면 됩니다.
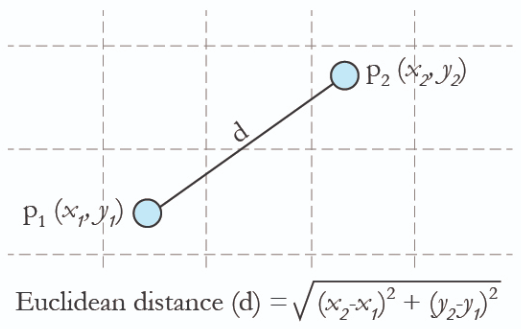
거리 측정
KNN 분류 모델에서 '거리' 라는 부분이 굉장이 중요한 부분을 차지합니다. 때문에 어떤 방식으로 거리를 측정하는가에 대한 다양한 방법론이 있는데 먼저 가장 대표적인 '유클리드 거리'를 알아보겠습니다. 유클리드 거리는 가장 일반적인 거리 계산법으로 서로 다른 점의 직선 거리를 말하게 됩니다.
KNN의 장점과 단점
KNN의 가장 큰 장점중 하나는 모델을 만들거나 파라미터를 조정할 필요가 없다는 겁니다. 때문에 데이터를 학습할 필요도 없는데다가 모든 데이터가 예측에 사용되게 됩니다. 다만 KNN의 큰 단점은 computing cost가 크다는 점입니다. 모든 데이터를 예측에 사용한다는점에서 분류하는데 시간이 많이 걸리게 됩니다. 또한 K값을 어떻게 정하냐에 따라 값이 많이 달라지기 떄문에 이 점도 단점 중 하나라고 말할 수 있습니다.
Anomaly Detection에서의 사용법..
개인적으로 KNN을 접하게 된 건 anomaly detection을 접하게 된 이후였습니다. 물체의 이상치를 탐지한다는 점에서 현재 데이터가 정상인지, 이상치인지를 구분했어야 하는데, supervised training으로 접근했을 경우에는 많은 학습시간과 labeling cost가 크다는 단점이 있었습니다. 또한 이상치라는 점이 하나의 feature을 가진 것이 아닌 여러가지 특성을 가지고 있었기 때문에 일반적인 방법으로 처리하기 어려웠다는 점입니다. 때문에 딥러닝에 KNN방식을 접목시켜 이상치 탐지하는 방법을 알게 되었고, 너무나 신선하게 다가왔습니다.
