딥러닝 수학
1.Multivariate normal distribution(다변수 정규 분포)
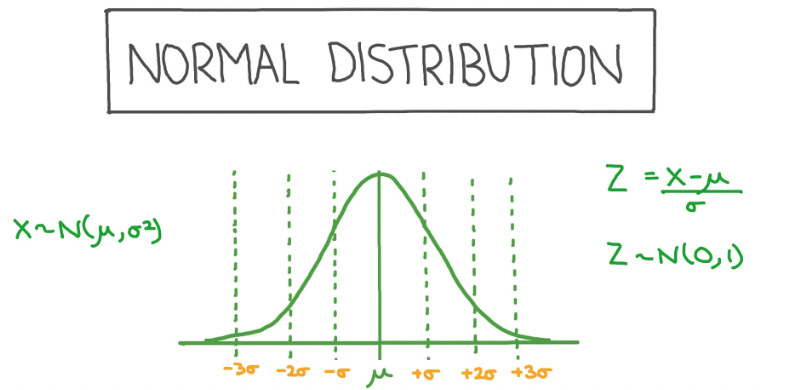
일반적으로 정규 분포 하면 많이들 변수가 하나인 정규 분포를 떠올리실 겁니다...
2022년 8월 13일
2.Bayes' theorem(베이즈 정리)
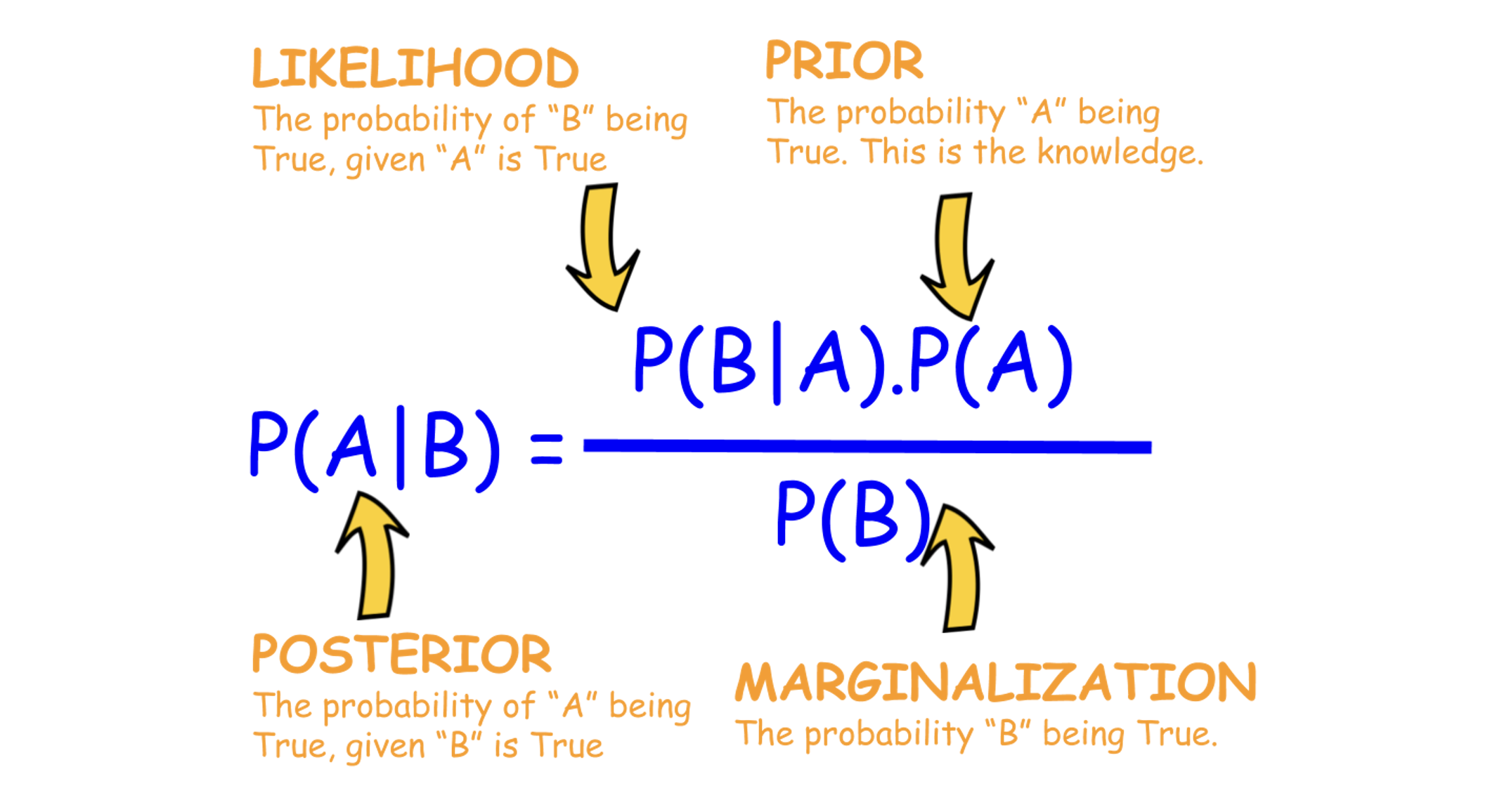
베이즈 정리 어떠한 사후 확률을 구하는 것을 말한다.. 이는 어떤 사건이 만들어 놓은 상황에서, 그 사건이 일어난 후 앞으로 일어나게 될 다른 사건의 가능성을 구하는 것. $$ P(B|A) = \frac{P(A|B)P(B)}{P(A)} $$ 정리만 보면 어려우니
2022년 8월 15일
3.KNN (K-Nearest-Neighbors)
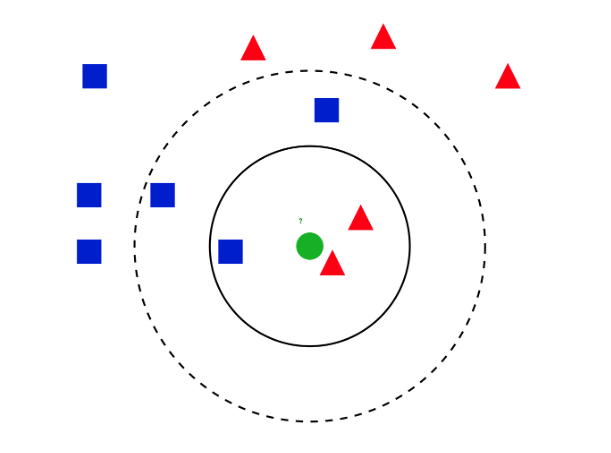
K-NN은 비슷한 특성이나 속성을 가진 것들이 가까운 곳에 모여있는다는 특징을 이용한다. K-NN 알고리즘은 이처럼 K개의 가까운 이웃의 속성에 따라서 분류하는 것이다. 여기서 그럼 가까움이란 어떻게 판별하는 것일까? '어떤 데이터가 들어오면 그와 거리가 가까운 K개의
2022년 8월 16일
4.Likelihood(가능도함수)
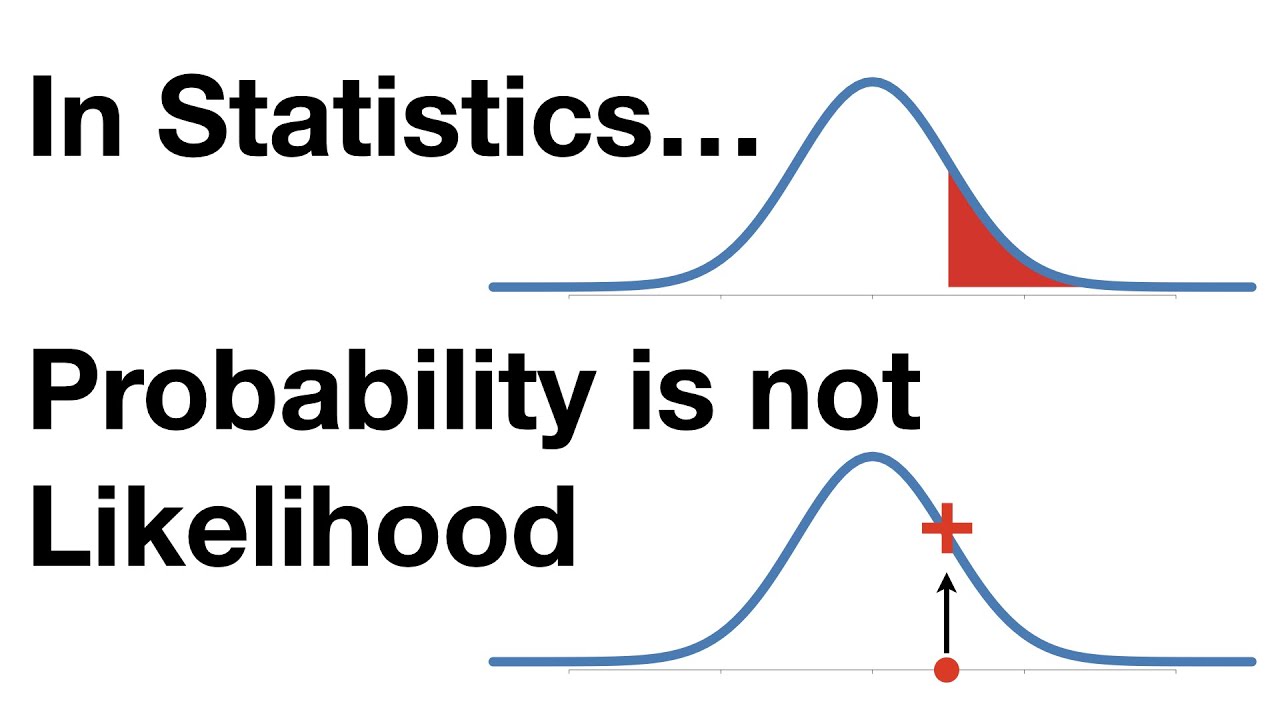
가능도함수는 고전 통계학, 베이지안 통계학에서 자주 등장합니다. 추론을 한다는 의미에서 자주 쓰이는데 예를 들어 한번 설명해 보겠습니다. 동전을 던질때 앞면이 나올 확률을 말해보라 하면 1/2(50%)이다 라고 잘 대답할 것입니다. 그렇다면 동전을 10번 던졌을때 앞면
2022년 8월 17일