[DeiT 관련 논문 리뷰] 04-Training data-efficient image transformers & distillation through attention(DeiT)
논문리뷰

이번 글에서는 Training data-efficient image transformers & distillation through attention(2021)을 리뷰하겠습니다. DeiT 관련 논문 리뷰의 마지막 글이며, DeiT를 소개합니다.
DeiT의 특징은 크게 두 가지로 설명됩니다.
(1) ViT와 동일한 모델 구조 → Transformer 모델
(2) CNN 구조의 Teacher 모델의 지식을 증류 기법으로 학습한 Student 모델 → cnn의 inductive bias를 상속받음
(1)에 대한 설명은 이전 ViT 모델 논문 리뷰를 통해 되었으리라 생각합니다. 이번 글에서는 (2)를 중점적으로 설명하겠습니다.
DeiT는 데이터 효율성이 높은 모델로, 대규모 데이테섯이 필수 요건이 아니며 적은 데이터로도 높은 효율을 달성합니다. 그 이유는 DeiT가 지식 증류 기법으로 학습된 모델이기 때문입니다. DeiT의 Teacher 모델은 CNN 아키텍처인 RegNet입니다. CNN 모델을 선생님으로 둠으로써 CNN 아키텍쳐의 장점인 inductive bias를 상속합니다. 또한 Teacher 모델의 지식을 학습함으로써 지식증류기법으로 학습하지 않은 다른 모델보다 더 빠르게 똑똑해집니다.
Inductive bias
시리즈의 가장 최근 게시글에서 ViT모델이 transformer 아키텍쳐를 이용하여 이미지를 처리하는 모델이라고 소개했습니다. 또한 ViT는 데이터 효율성이 낮은 모델임을 강조했는데요, Transformer 구조인 Vision Transformer가 inductive bias의 이점을 뛰어넘기 위해선 많은 대규모 데이터셋으로 학습해야 하기 때문입니다.
inductive bias를 뛰어넘으려면 large scale training만이 답일까요?
- ViT는 inductive bias가 얕다는 취약점을 large scale training을 통해 보완합니다.
- DeiT는 inductive bias가 얕다는 취약점을 Teacher모델의 inductive bias를 전달받음으로써 보완합니다.
DeiT는 사전 학습 과정에서 CNN 모델로부터 distillation 방법([DeiT 관련 논문 리뷰]-02)을 통해 inductive bias를 전달받습니다.
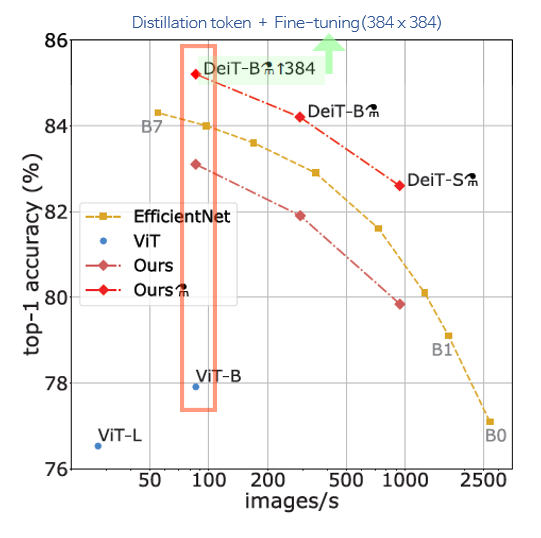
- EfficientNet : cnn 아키텍처
- ViT : Trasnformer 아키텍처
- DeiT : Transformer 아키텍처
transformer 아키텍처인 DeiT가 cnn 아키텍처인 EfficientNet보다 좋은 성능을 기록한 것을 확인할 수 있습니다. 특히 ViT(파랑)와 DeiT(빨강)를 비교하면, 우월한 성능입니다.
+) 표를 자세히 보면 Ours가 두 개 있는데요, 채도가 높은 빨간색 옆을 보면 샤워기 호스 기호 같은 게 보입니다. 이 기호가 옆에 붙은 경우 사전 학습 과정에서 distillation token 전략을 활용해 cnn의 inductive bias를 전달받은 모델입니다. 연두색으로 하이라이트한 모델은 384라는 숫자가 옆에 함께 있는데요, 이 경우엔 fine-tuning 단계에서 resolution을 384(→Fine-tuning at different resolution에서 설명)로 높인 모델입니다.
Disitillation Token
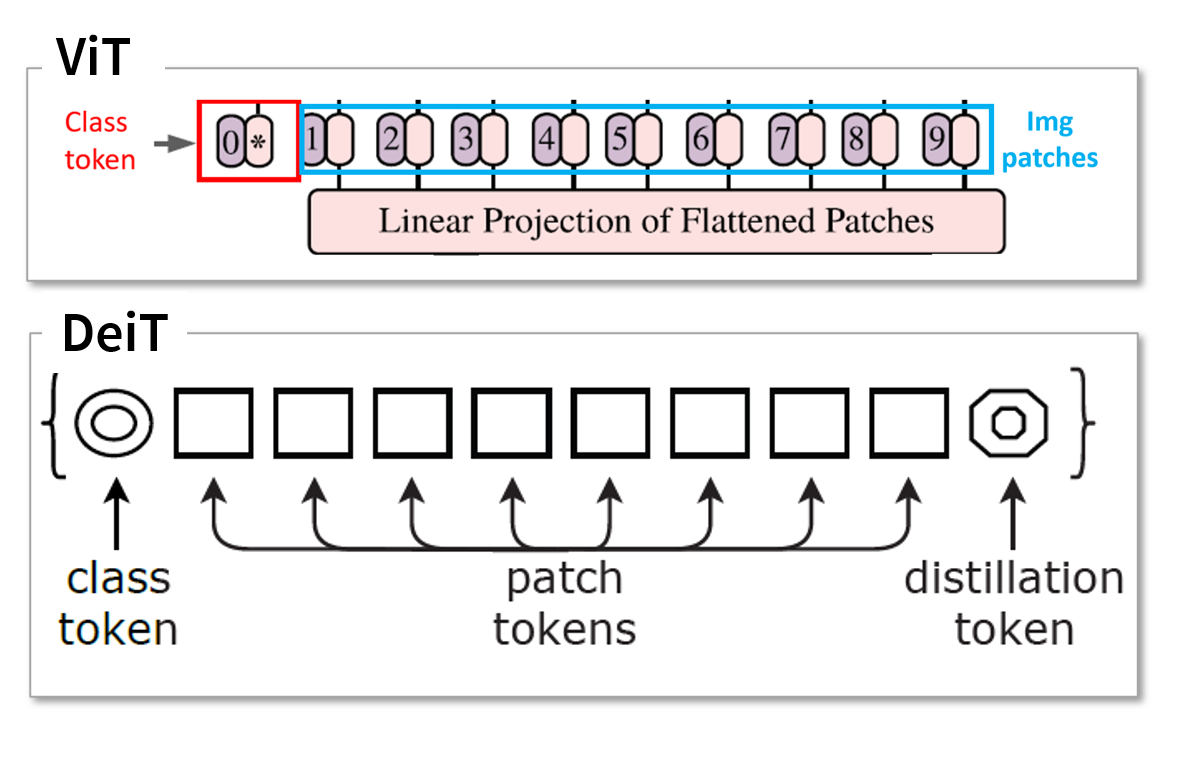
ViT 모델의 Input으로 Class token, img patches가 투입됩니다. DeiT는 ViT처럼 Class token, img patches가 투입되며, 거기에 Distillation token이 추가됩니다. disitllation token을 활용한 Distillation 방법은 매우 단순합니다. class token처럼 랜덤 초기화된 distillation token을 추가하는 것인데요, 단순한 방법임에도 효과는 매우 좋습니다.
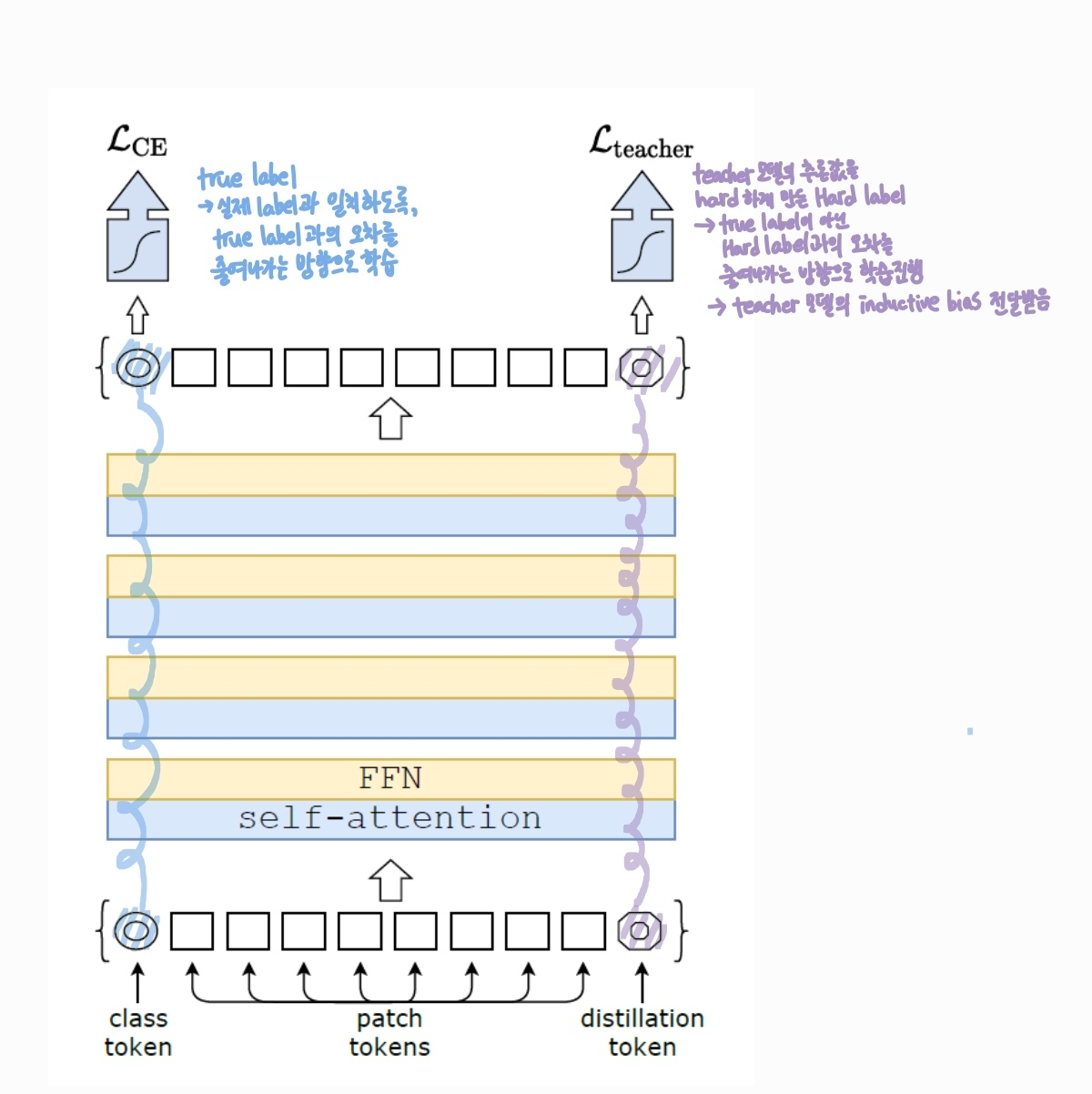
class token과 distillation token은 transformer 구조에 들어가기 전에, random initialized됩니다.
하기 이미지는 DeiT 모델이 distillation token을 초기화하는 부분입니다.
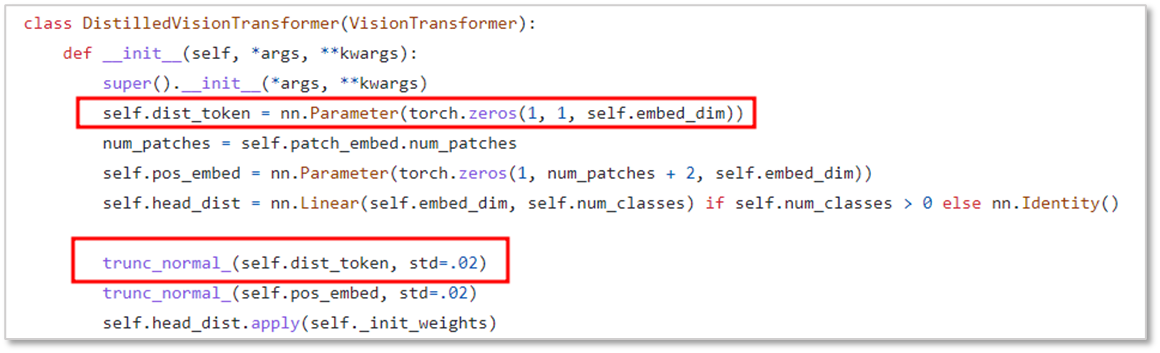
랜덤하게 초기화된 두 개의 토큰(cls token, distill.token)은 이미지 패치와 함께 transformer에 들어가 여러 레이어를 통과하면서 랜덤값에서 최적화된 값으로 변경됩니다.
class token과 distillation token은 초기 투입 시에 동일한 방법으로 랜덤 초기화됩니다. transformer 레이어를 모두 거친 뒤에 입력 이미지에서 추출된 정보를 전역적으로 표현하는 토큰이 되는데요, 두 개의 토큰은 각자의 역할에 따라 다른 방식으로 학습이 이루어집니다.
Distillation Token은 Teacher 모델의 지식을 학습하는 역할을 맡습니다. 따라서 teacher 모델이 예측한 hard label을 재생산하는 것을 목표로 합니다. 보통의 학습 방법은 입력 이미지의 true label을 맞추는 방향으로 전개되는데요, 이는 class token이 담당하게 됩니다. distillation token은 true label이 아닌 teacher 모델의 추론값과의 오차를 줄여나감으로써 teacher 모델의 지식을 학습하는 역할을 담당합니다.
(본 논문에서는 기존의 class token에 distillation token 말고 class token을 하나 더 추가하여 총 2개의 클래스 토큰으로 training을 진행했다고 합니다. 두 개의 class token은 true label을 맞추도록 설정되었는데요, 효과는 없었다고 합니다.)
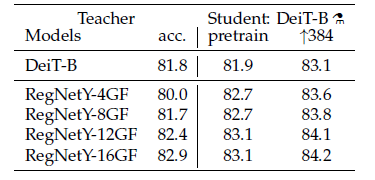
DeiT 모델의 Teacher 모델은 CNN 아키텍처인 RegNeT 모델입니다.
ditillation token으로 학습하였을 때 Teacher 모델인 RegNeT보다 더 높은 성능을 기록했습니다.
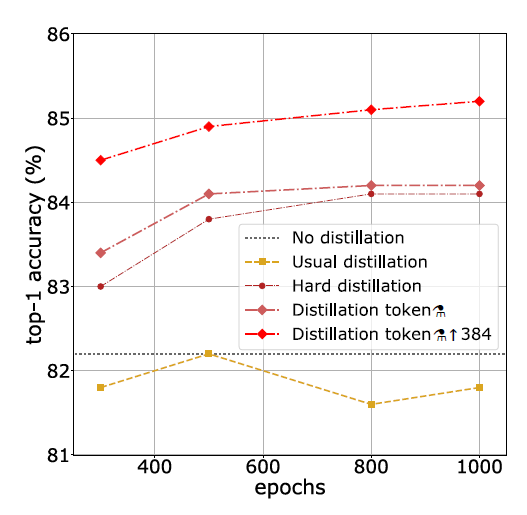
본 논문에서는 Distillation 방법에 따른 성능 차이를 실험합니다. 지난 포스팅에서 언급된 기본 distillation 방법도 포함됩니다. 본 논문에서 제시한 distillation token + fine-tuning 단계에서 이미지의 해상도를 384로 올린 방법 조합이 가장 좋은 성능을 기록하였습니다.
Fine-tuning at different resolution
이미지 해상도를 384로 올려서 fine-tuning을 진행한 방법은 'Fixing the train-test resolution discrepancy(2019)'라는 논문에서 착안하였습니다. 해당 논문에서 training 단계에서는 저해상도(224 X 224)로 진행하고 파인튜닝 단계에서 고해상도(384 X 384)로 조정하는 것이 성능에 좋다는 것을 보여줬습니다. DeiT로 테스트했을 때도 고해상도로 파인튜닝한 경우가 훨씬 성능이 좋게 나왔네요.
- transformer 계열의 모델은 img를 입력받으면 고정된 크기로 이미지를 쪼갭니다.
- training 단계에서 224 x 224 해상도의 이미지를 n개의 패치로 분류하였다고 가정하겠습니다. 이후 fine-tuning 단계에서 384 x 384 해상도의 이미지를 다시 n개의 패치로 나누게 됩니다. 이 경우 positional encoding을 차이나는 패치 수만큼 추가적으로 수행해줘야 합니다.
- 224-> 384 만큼의 차이에 대한 positional encoding은 interpolation으로 수행합니다.
- bilinear interpolation으로 테스트했을 때 해당 기법이 벡터들의 L2-norm을 떨어뜨려서 accuracy가 급격히 감소했다고 합니다. 따라서 bicubic interpolation을 사용하였습니다.
정리
vision분야에서 transformer 아키텍처는 cnn에 비해 그 역사가 짧습니다. 실험 결과에 따르면, transformer 기반의 deit가 다른 cnn 모델(파라미터수가 비슷한 경우)에 비해 처리 연산량이 훨씬 큽니다. 또한 아주 단순하게 disitllation token을 추가하여 inductive bias를 상속하게 한 시도를 통해 efficientNet과 ViT의 성능을 뛰어넘었습니다. 이를 통해 비전 분야에서의 transformer모델 발전 가능성을 기대할 수 있겠습니다.



저는 몰랑님의 발전 가능성을 기대해보겠습니다 (●'◡'●)