Object Detection : Backbone, Neck and Head Architecture
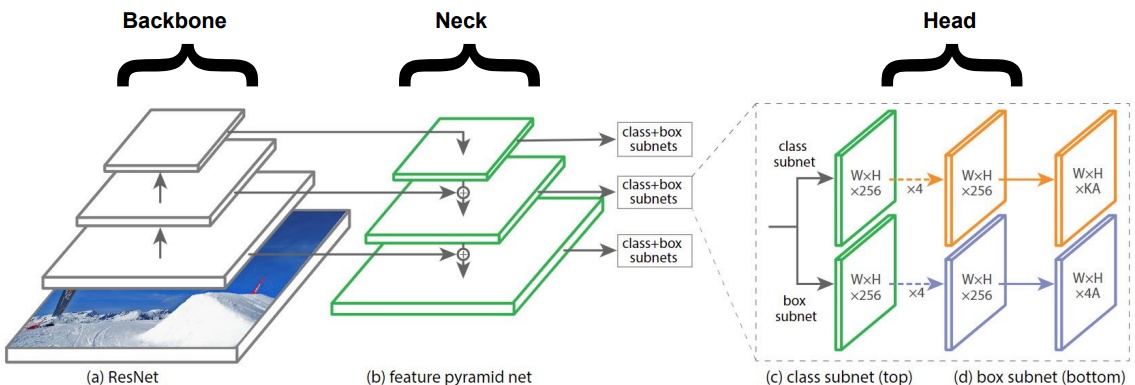
※YOLOv4 논문의 2. Related Work 파트를 참고하였습니다.
안녕하세요, :) 입니다.
이번 포스트는 아마 제가 입대하기 전 마지막 포스트가 될 것 같은데요,
Object detection이 ML이나 DL과는 완전히 다른 영역인 줄 아시는 분들이 많은 것 같아서 'object detection의 architecture'에 대해 써보는 글입니다. 실제로 저도 CV 분야를 잘 모르기 전까지는 "이런거에서 ML과 DL 모델을 쓰긴 쓰나?" 라고 생각을 했었죠.
아래 사진은 지난 포스트인 CCNet 논문 리뷰에서 4.2 Implementation Details의 한 부분입니다.
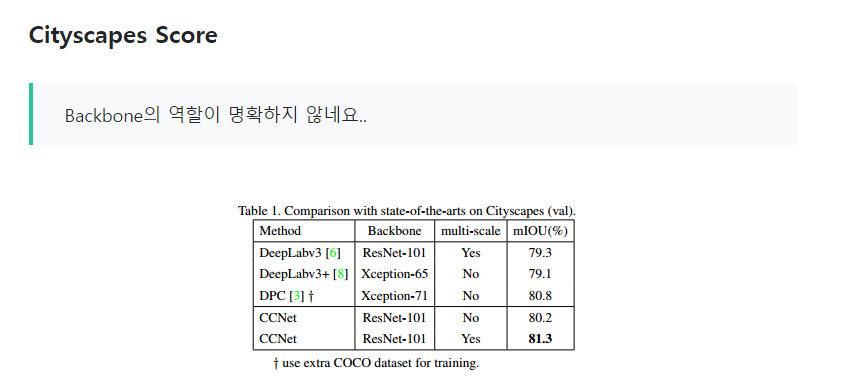 제가 Object Detection 분야의 논문을 읽는게 처음이라, 논문에 나왔던 'Backbone'의 역할이 뭔지를 몰랐습니다.
제가 Object Detection 분야의 논문을 읽는게 처음이라, 논문에 나왔던 'Backbone'의 역할이 뭔지를 몰랐습니다. 이론만 얕게 알았던 자의 눈물
 그래서 Casey 교수님께 3월 9일에 이메일로 여쭤봤어요.
그래서 Casey 교수님께 3월 9일에 이메일로 여쭤봤어요.
이 근래에 무슨 마가 씌었는지는 몰라도 교수님 실력을 의심하다가, 이메일로 주신 코드를 받고 정신 차렸답니다...
 친절하게 'upper layers'에 해당하는 pre-trained network라고 답해주셨습니다. 이걸 보고 lower layers도 있고, 뭔가 분리되어있는 구조구나 싶어서 이러한 구조에 대해서 공부하게 되었습니다.
친절하게 'upper layers'에 해당하는 pre-trained network라고 답해주셨습니다. 이걸 보고 lower layers도 있고, 뭔가 분리되어있는 구조구나 싶어서 이러한 구조에 대해서 공부하게 되었습니다.
사실 이 키워드 (Backbone, neck, head in object detection 같은)로 검색해서 들어오신 분들은 저처럼 computer vision 분야의 newbie라고 생각하기에, 간단하게 object detection에 대한 gentle introduction으로 넘어가겠습니다.
Object Detection
여러분, 여러분이 지금까지 알고 있었던 '이미지 데이터에 대한 일반적인 ML (혹은 DL)'이라고 하면 뭐가 떠오르셨나요?
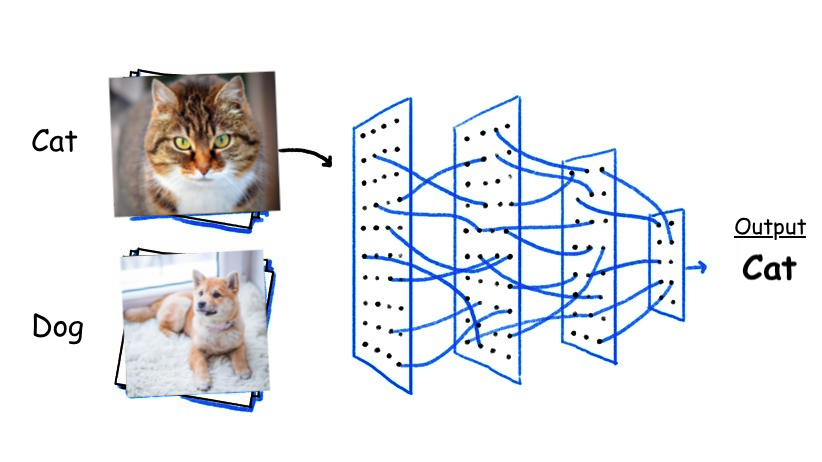 위와 같은 image와 image 자체에 대한 classification이 많이 생각나셨을 겁니다. 물론 이것도 computer vision의 일부이죠.
위와 같은 image와 image 자체에 대한 classification이 많이 생각나셨을 겁니다. 물론 이것도 computer vision의 일부이죠.
하지만, object detection은 '한 이미지 내에서' 진행되는 것입니다. 다음 사진을 보시면,
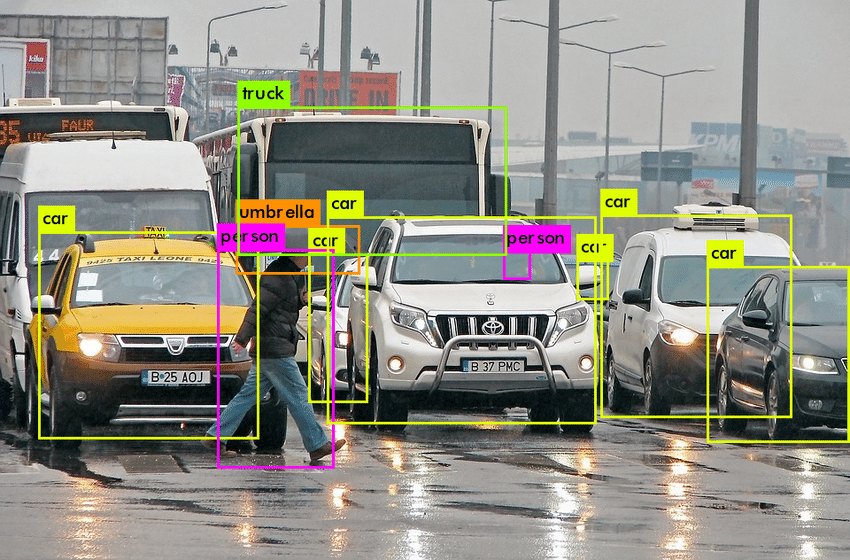 한 이미지 내에서 서로 다른 객체들을 '분류 (= 검출)' 하고 있죠. 이것이 바로 CV에서 object detection입니다.
한 이미지 내에서 서로 다른 객체들을 '분류 (= 검출)' 하고 있죠. 이것이 바로 CV에서 object detection입니다.
Classification이지만 우리가 알던 classification이 아닌 것 같은 느낌.. 이것이 가능한 이유는 바로 Backbone - Neck - Head 구조에 있습니다.
Architecture
대표적으로 YOLO가 one-stage detector인데요, 물론 R-CNN처럼 정확하지만 느린 two-stage detectors도 있습니다. 구조 설명은 one-stage detector 기준으로 하겠습니다.
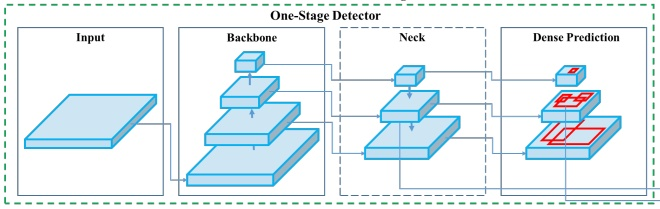
※ 위 그림의 구조를 잘 기억해주시고, 헷갈리실 때마다 remind 해주세요!
Backbone
ResNet, DenseNet 그리고 VGGNet 등은 Backbone 파트에서 feature extractors로 사용됩니다. 이것들은 ImageNet같은 'image classification datasets에 이미 훈련된 모델'인데요, detection dataset에 fine-tune됩니다.
이렇게 깊어질수록 higher semantics와 함께 다양한 level의 feature를 생성하는 구조는 object detection network의 후반부에서 유용합니다.
그럼 이 Backbone이 우리가 이전에 알고 있던 CNN과 동떨어진 것인가, 전혀 그렇지 않습니다.
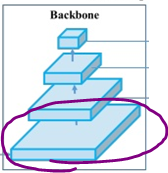 맨 밑은 input image인데요,
맨 밑은 input image인데요, 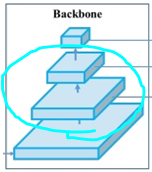 가운데 두 개 (실제로는 더 적거나 더 많을 수 있죠)는 conv layers 입니다.
가운데 두 개 (실제로는 더 적거나 더 많을 수 있죠)는 conv layers 입니다.
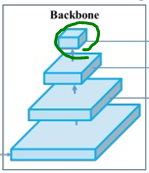 맨 위는 바로 feature map이랍니다. 결론적으로 Backbone 파트는 일반적인 CNN cell을 거쳐 평범하게 feature map을 생성하는 파트인 것이죠.
맨 위는 바로 feature map이랍니다. 결론적으로 Backbone 파트는 일반적인 CNN cell을 거쳐 평범하게 feature map을 생성하는 파트인 것이죠.
게다가 image를 다루게 되니 이러한 상황에 최적화된 CNN architecture인 ImageNet을 주로, ResNet이나 VGG를 사용하는 경우가 많은 것이구요.
Neck
이름 그대로, backbone과 head 사이를 이어주는 연결부입니다. Neck에서는 backbone의 다른 stages에서 서로 다른 feature maps를 추출하게 되는데요, FPN, PANet, Bi-FPN 등이 사용될 수 있습니다. YOLOv3는 FPN을 사용하고 있습니다.
여기서 FPN은 Feature Pyramid Network인데요,
Top-down 방식과 측면 연결을 통해서 기존의 convolutional network를 증강시킵니다. 이는 network가 single resolution input image로부터 풍부하고 다양한 scale의 feature pyramid를 구성할 수 있도록 합니다.
각 측면 연결은 bottom-up pathway로부터 top-down pathway까지 feature maps를 병합하여 서로 다른 pyramid level을 생성합니다. Feature maps를 합병하기 전에, 이전의 pyramid level은 FPN의 2x 요소에 의해 up-sample되어 같은 spatial size를 가지도록 합니다.
이렇게 다양한 층 (pyramid) 덕분에, 각 층에 classification이나 regression network (Head)를 적용하여 서로 다른 사이즈의 object를 검출할 수 있게 됩니다.
자세한 내용은 FPN 논문을 확인하세요 :)
(a)는 SSD(Single Shot Detector Architecture)의 backbone에서 어떻게 features가 추출되는지 보여주고 있습니다. (b)는 FPN 방식 (FPN은 ResNet을 씀), (c)는 STDN 방식이며 (d)는 YOLOv4의 방식입니다.
결론적으로, '피라미드 형태를 통해 검출 객체에 다양한 스케일 변화를 준다'는 아이디어는 모두 같습니다.
Head
Bounding boxes의 classification이나 regression같은 '검출'이 이루어지는 실질적인 부분입니다. Output은 네 개의 값 (x, y, h, w)과 k classes + 1의 확률 (+ 1은 배경을 위한 것) 형태입니다.
결론
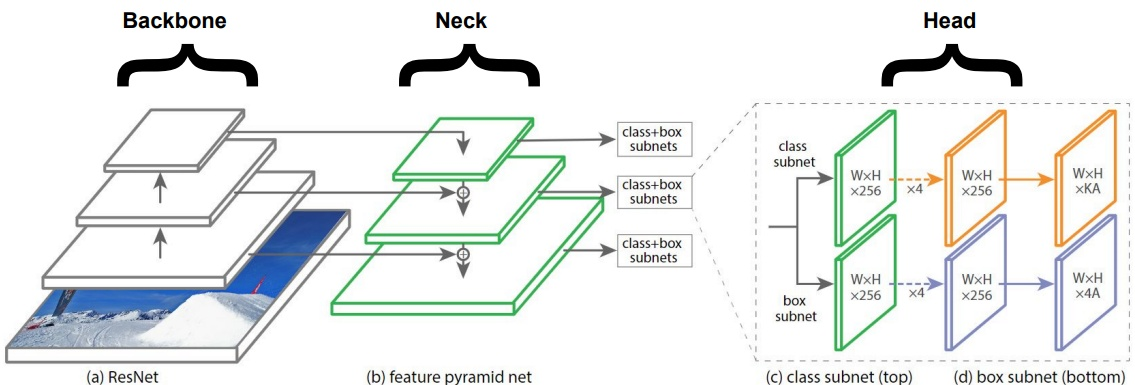 세 모듈을 하나의 과정으로 모아보면 이렇습니다.
세 모듈을 하나의 과정으로 모아보면 이렇습니다.
사실 이 구조는 이렇게 글만 봐서는 실전에서 어떤 느낌인지 명확하지 않을 가능성이 높지만, 유명한 object detector에 대한 논문을 몇 개 읽어보거나 실전 코드를 통해 적용해본다면 훨씬 감이 잘 오실 겁니다.
++ 입대 전 마지막 포스트일 것 같은데요.. 이 지식들을 두고 가야한다니 참 안타깝습니다. 제가 가서 하기 마련이겠지만.. 걱정이 이만저만이 아니네요.
글 읽어주셔서 감사하고, 언제가 될진 모르겠으나 다음에 뵙겠습니다! 감사합니다 :)



많은 도움이 되었습니다! 여기 한명 추가됬으니 목적 성공하셨네요!! ㅎㅎ:) 혹시 깃허브 있으시면 제 깃허브도 방문해주세요!! https://www.github.com/jonychoi