
[WIL] 1월 셋째주
프로덕트 데이터 사이언스 강의감정분석(리뷰 테이블 중심으로)긍정/부정 키워드 워드 클라우드 그래프긍정/부정 키워드 네트워크 그래프리뷰 클러스터링(실패)물류 관련 방향 정리사업계획서 작성방향성이 너무 안 잡혀서 힘들다 괴롭다\~~
최종 프로젝트 정리
🔍 현재 진행 상황 정리텍스트 마이닝 분석워드클라우드, 네트워크 그래프를 활용하여 텍스트 분석을 수행했음.결과적으로, "배송"과 관련된 단어가 주요하게 나타났으며, 기존 기대했던 것보다 유의미한 인사이트를 도출하기 어려웠음.리뷰 기반 클러스터링리뷰 텍스트만으로 K-M
[WIL] 1월 둘째주
API 특강자연어 특강프로덕트 데이터 사이언스프로젝트 기획서 작성프로젝트 EDA프로젝트 기획서 피드백 정리 및 반영프로젝트 EDA(중간) 보고서 제출프로젝트 EDA(중간) 보고서 피드백 정리 및 반영EDA 마무리사업 계획서EDA가 이렇게 힘든거였나... 너무 많은 걸
[챌린지]프로덕트 데이터사이언스②
프로덕트 센스와 기회 규모 추정 방법론 이번 챌린지는 데이터 기반으로 프로덕트 개선 방향을 설정하고 비즈니스 임팩트를 창출하기 위한 프레임워크를 배웠습니다. 1. 프로덕트 센스(Product Sense)란? 정의: 사용자의 니즈를 이해하고, 비즈니스 목표 달성을 위한
[특강]자연어 처리①
자연어 처리는 현대 데이터 분석의 필수적인 부분으로 자리 잡고 있습니다. "자연어 처리 특강"의 1회차 내용을 바탕으로 텍스트 데이터 분석, 임베딩, 전처리에 대해 정리해 보았습니다.텍스트 데이터 분석의 기본 원리 이해분석을 위한 전처리 단계 학습코드를 통한 실습으로
[챌린지]프로덕트 데이터사이언스
Product Data Science는 데이터를 기반으로 제품 및 서비스의 의사결정을 지원하는 직무입니다.주요 목표는 제품 개선, 성장 전략 수립, 사용자 경험 최적화입니다.기회 규모 추정 (Opportunity Sizing)특정 기능이나 시장 진출이 가져올 가치와 영
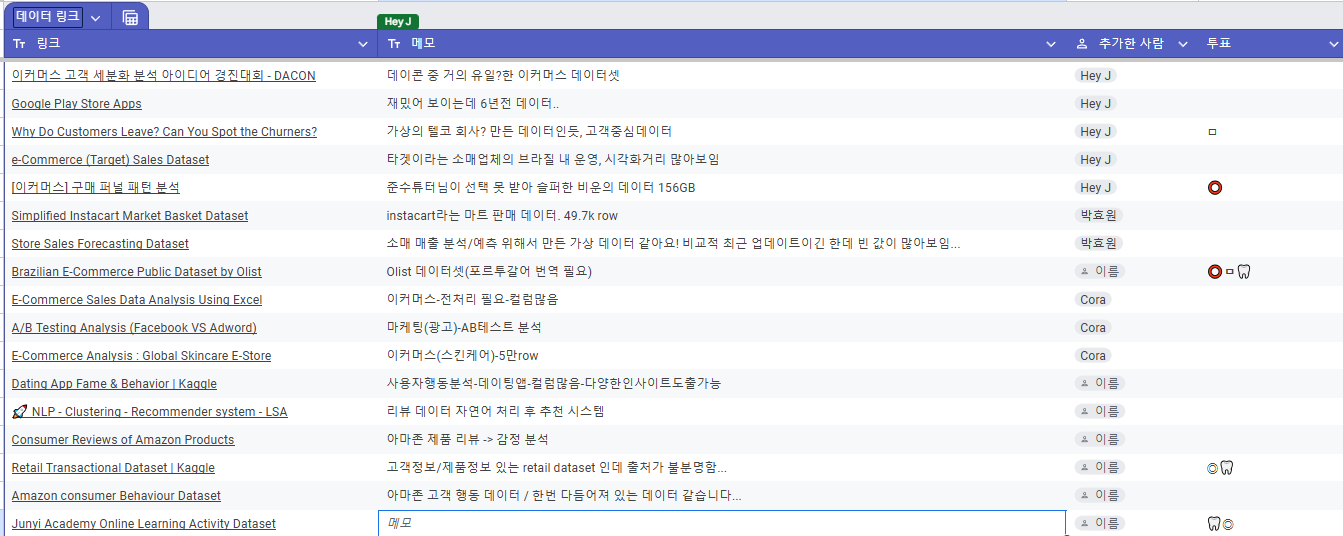
최종 프로젝트 ①
구글 드라이브 공유 폴더를 활용해 프로젝트를 진행하기로 결정했다. 위처럼 데이터 수집 링크를 적재하기도 하고, 회의록, 진행사항, 코랩을 이용한 코드 공유 등을 진행할 수 있도록 세팅을 했다.데이터는 여러 인사이트를 도출 해 낼 수 있을 거라고 예상한 olist데이터를
[WIL] 12월 셋째주
실전 프로젝트 1일차실전 프로젝트 2일차실전 프로젝트 3일차실전 프로젝트 4일차열심히 하는 것도 좋지만 건강 잘 챙기면서 하자헷갈릴 수 있지만 확신을 가지면서 하기지금까지 해왔던거처럼 팀원들과 의지하면서 대화를 통해 더 많은 방향으로 결정하기

[실전 프로젝트] 4일차
대시보드가 총 4개로 구성되도록 계획을 짯기 때문에 총 네 가지 색상의 백그라운드를 만들었다. 1\. Overview : 주요 KPI 지표를 볼 수 있는 Summary 대시보드2\. Country : 나라, os, 고객 세그먼트를 볼 수 있는 고객 정보 중심 대시보드3

[실전 프로젝트] 3일차
📝오늘 대시보드에 들어갈 전체적인 버튼을 만들었다. 그리고 데이터를 바탕으로 설정한 회사에 대한 로고도 만들었다. 내일은 대시보드에 디자인적으로 적용하고 1번째 대시보드를 완성하고자 한다.
[실전 프로젝트] 2일차
총 매출필요한 열Revenue : 매출CVR : 클릭 수 대비 전환율필요한 열 Conversions: 전환 수Clicks: 클릭 수CTR : 노출 수 대비 클릭률필요한 열 Clicks: 클릭 수Impressions: 노출 수ROI : 투자 대비 수익률필요한 열Reve
[실전 프로젝트] 1일차
Engagement 수신자의 긍정적인 반응을 이끌어내는 것Conversion 고객이 구매, 앱 다운로드, 메일 링리스트 가입 등의 특정한 기대 행동을 완료하는 것Awareness 마케팅 캠페인, 소비자 조사 및 발굴을 통해 잠재 고객을 이 단계로 끌어들임PPC 고객이
[태블로] 실습으로 배우는 태블로 과제
📖 필수 1: 데이터 연결 및 준비제공된 세계 행복 보고서 2023 (WHR_2023.csv) 데이터를 Tableau에 연결해주세요.데이터셋의 주요 컬럼은 다음과 같습니다:Region (지역)Country (국가)Happiness Score (행복 점수)GDP per
[WIL] 12월 둘째주
QCC\-> 다음에는 다 맞출 수 있도록 특단의 조치가 필요함\-> 오전에 1시간 동안 밀도 있게 집중하기 위해 9시에 미니스크럼 진행하기로태블로\-> 스파르타에서 제공하는 강의로는 이해도가 부족. 부스트코스라는 태블로 강의를 통해 좀 이해도를 높여야 함.\-> 주말에
[QCC] 4회차
테이블 설명 :stores 테이블은 각 매장에 대한 정보를 담고 있습니다. 테이블 구조는 다음과 같으며, STORE_NAME, REGION_NAME, SALES, EMPLOYEES, OPEN_DATE, TYPE은 각각 매장 ID, 지역 이름, 매출, 직원 수, 개점일,
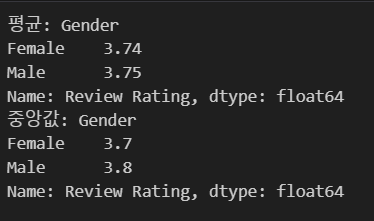
[과제] 통계학&머신러닝
statistics csv 파일을 읽고, 성별 Review Rating 에 대한 평균과 중앙값을 구해주세요. 결과는 소수점 둘째자리까지 표현해주세요.그리고 이에 대한 해석을 간략하게 설명해주세요.✍나의 답✍튜터님 답성별, Review Rating 컬럼에 대한 T-TES
[태블로] 차원(Dimension)과 측정값(Measure)
태블로(Tableau)와 같은 데이터 시각화 도구에서 Dimension(차원)과 Measure(측정값)는 데이터를 분석하고 시각화할 때 핵심적으로 사용되는 두 가지 데이터 유형입니다.의미데이터를 그룹화하고 분류하는 데 사용되는 필드 주로 텍스트 또는 범주형 데이터를 포
[태블로] LOD 표현식
LOD(Level of Detail) 표현식은 태블로에서 데이터 집계의 범위를 세부적으로 제어할 수 있는 도구 입니다. 이는 특정 차원에 독립적이거나 종속적인 집계값을 생성할 때 유용합니다.INCLUDE추가적인 차원을 포함하여 집계를 수행합니다.데이터 세트에서 현재 뷰
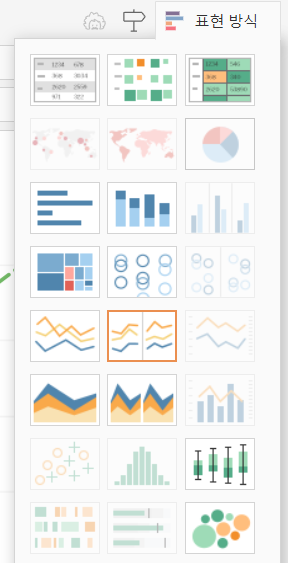
[태블로] 실습으로 배우는 태블로
Tableau 표현 방식 기능은 데이터에 적합한 대표적으로 24개의 그래프를 이용할 수 있다.특징간단하고 사용하기 쉽습니다.시계열 데이터(시간에 따른 추이)를 시각화할 경우, 변화량과 트렌드를 한눈에 보기에 용이합니다.연속적인 데이터에 사용하기 적합합니다. 연속형 데이
[머신러닝] 머신러닝 특강 - 군집분석
데이터 사이의 유사성을 기준으로 그룹을 나누는 과정인 군집분석, 클러스터링(Clustering)에 대해 알아 보려고합니다.이 강의의 목표는?클러스터링 개념 제대로 알기: 데이터를 그룹으로 묶는 게 왜 중요한지 이해해요!전처리 → 모델링 → 인사이트 도출까지 프로세스 따