Encoder and Scalar
Label Encoder
- 글자로 되어있는 컬럼을 숫자로 바꿔줌.
- 그 반대도 가능.
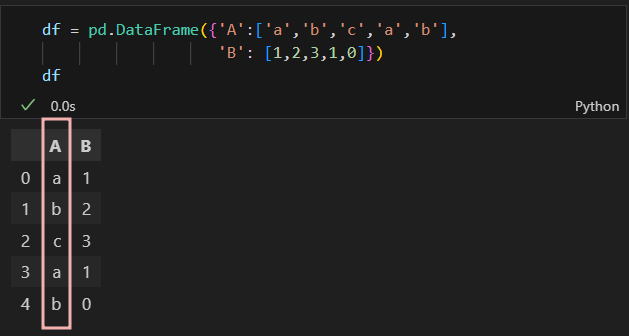
- 아래 코드를 통해 학습
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])le.classes_: 클래스 확인le.transform(df['A']): A컬럼의 문자를 숫자로 변환le.inverse_transform(df['le_A']): 숫자를 글자로 변환
min-max scaler(정규화)
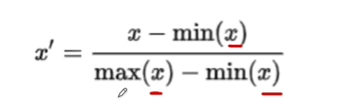
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)-
mms.data_max_, mms.data_min_, mms.data_range_: 각 컬럼의 최대값, 최소값, 범위 나타냄. -
df_mms = mms.transform(df): min-max scaler 로 변환
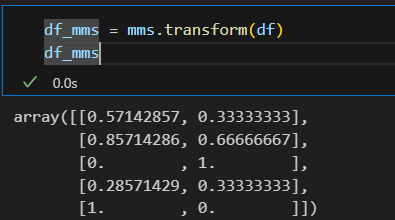
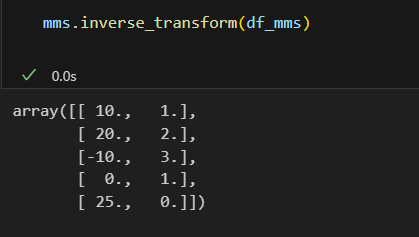
-
mms.inverse_transeform(df_mms): 변환시킨걸 다시 원래대로 되돌릴 수 있음.
standard scaler(표준화)
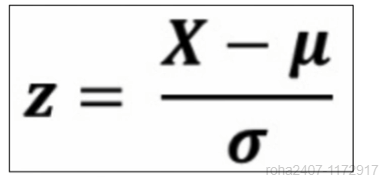
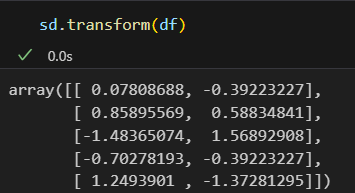
sd.mean_, sd.scale_: 평균과 표준편차

- 표준화 시키면 아래와 같다
roburst scaler
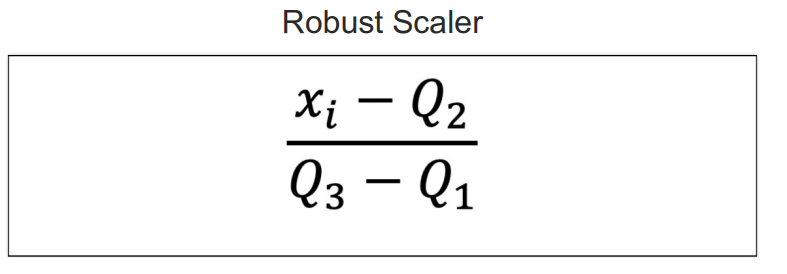
- 사분위 데이터를 활용
from sklearn.preprocessing import RobustScaler사용- 사용법은 위의 scaler들과 같음
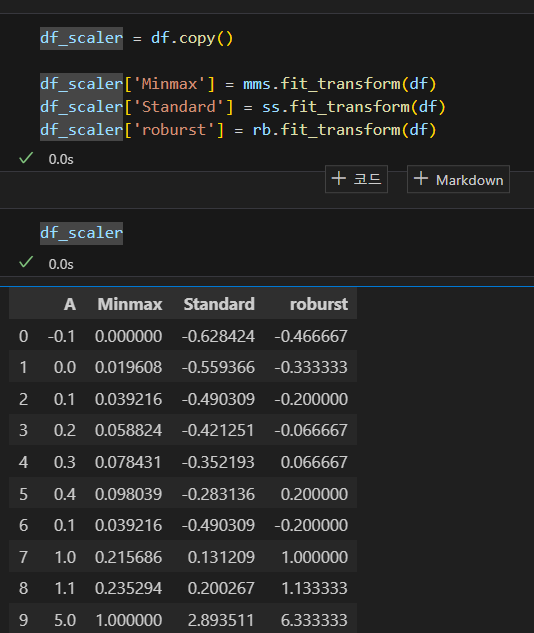
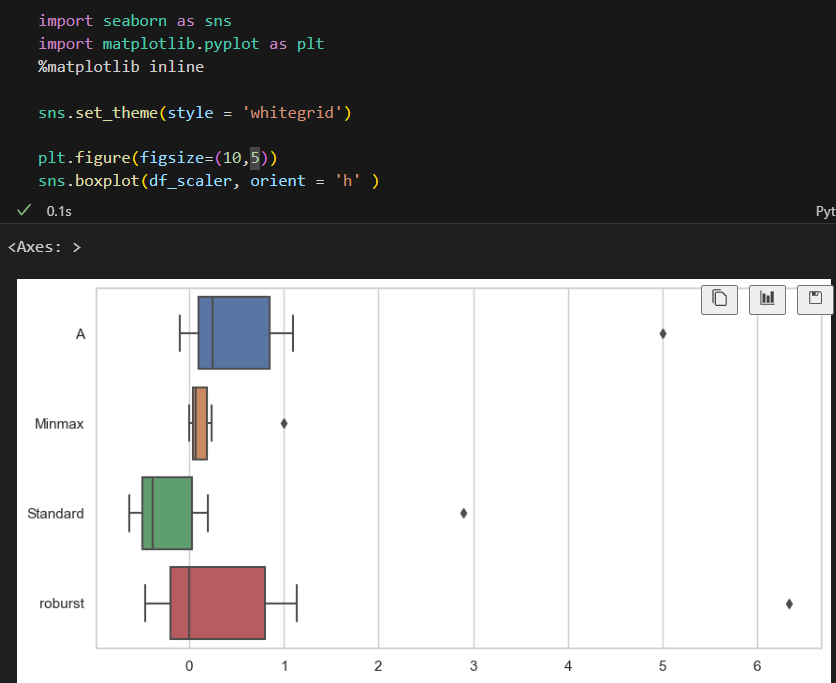
총 비교
📌회고록(오답노트)
pip install scikit-learn: sklearn설치- 머신러닝은 머신에게 데이터를 주고, 학습한 후,사용자가 질문한 내용에 대답할 수 있다.
- 머신러닝에서 예측은 꼭 미래에 대한 데이터를 의미하는건 아니다.
- 과적합이 발생하면 흔히들 모델이 일반화된 성능이 높지 않을 것이라 생각한다.
