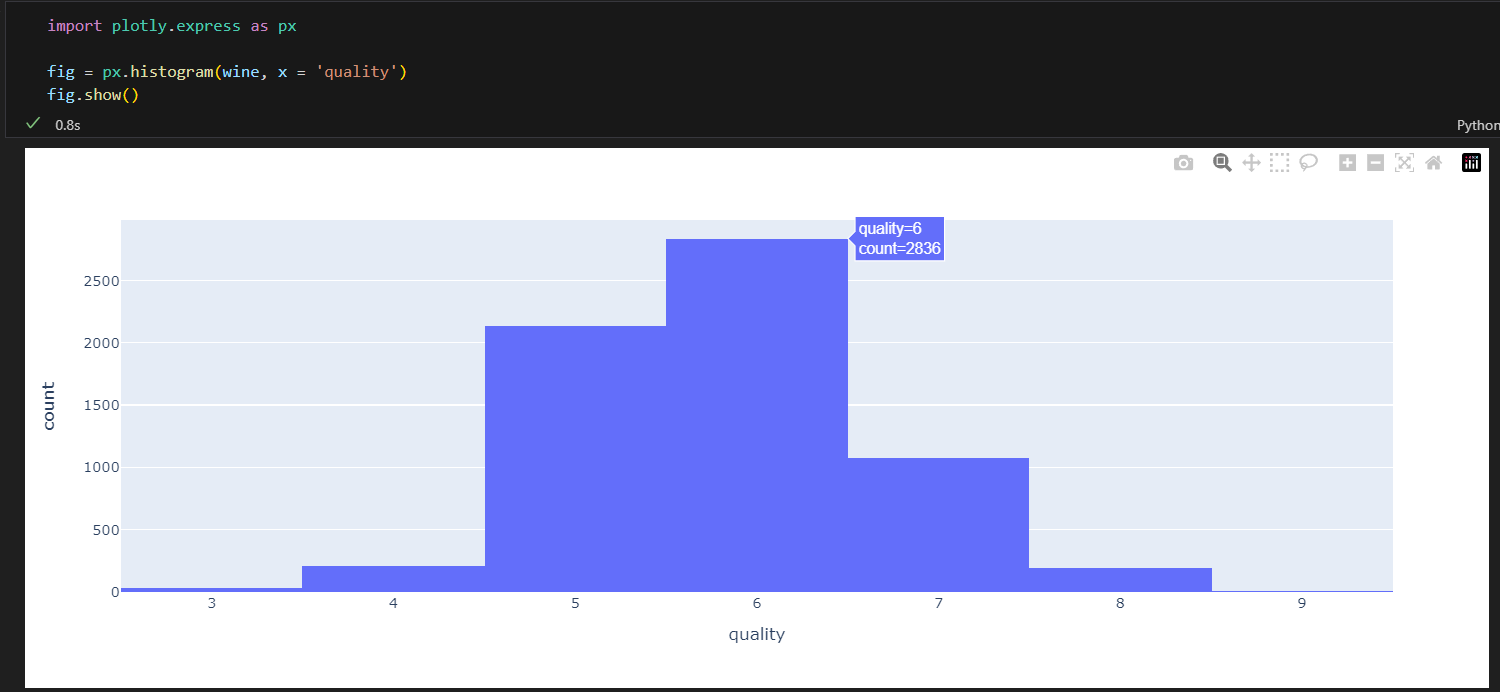
레드와인 화이트와인 분류기
훈련용, 테스트용 데이터 분류양상 확인
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Histogram(x = x_tr['quality'], name = 'Train'))
fig.add_trace(go.Histogram(x = x_t['quality'], name = 'Test'))
fig.update_layout(barmode ='overlay')
fig.update_traces(opacity = 0.75)
fig.show()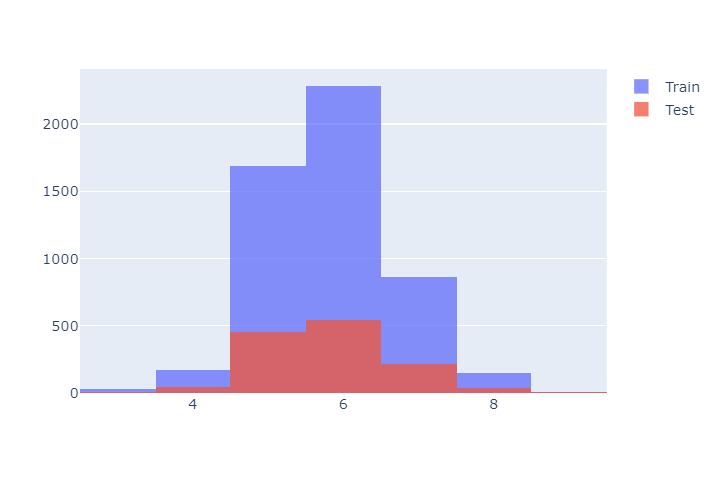
Decision Tree Train
- 두 데이터셋의 성능은 비슷하다.
from sklearn.metrics import accuracy_score
y_pred = wine_tree.predict(x_tr)
y_pred_test = wine_tree.predict(x_t)
print(f'Train acc: {accuracy_score(y_tr, y_pred)}')
print(f'Test acc: {accuracy_score(y_t, y_pred_test)}')
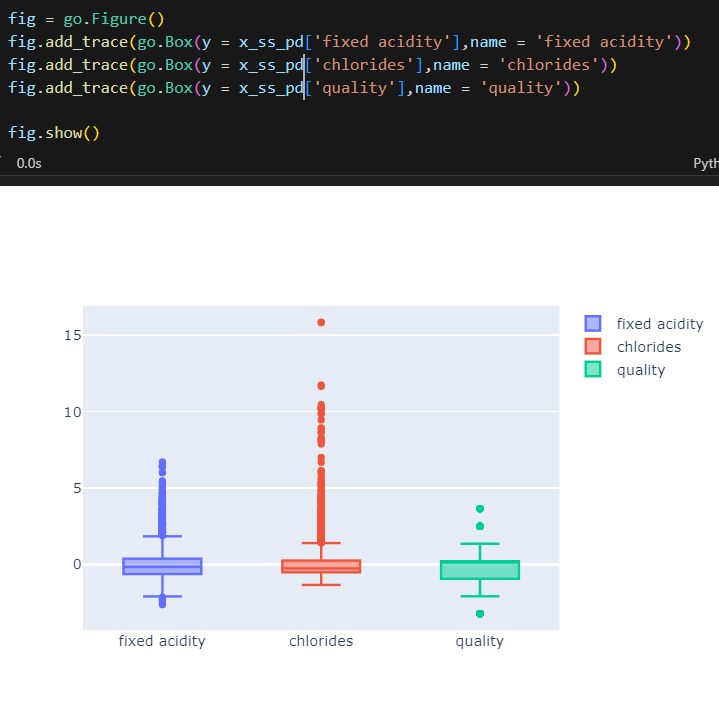
데이터 전처리
fig = go.Figure()
fig.add_trace(go.Box(y = x['fixed acidity'],name = 'fixed acidity'))
fig.add_trace(go.Box(y = x['chlorides'],name = 'chlorides'))
fig.add_trace(go.Box(y = x['quality'],name = 'quality'))
fig.show()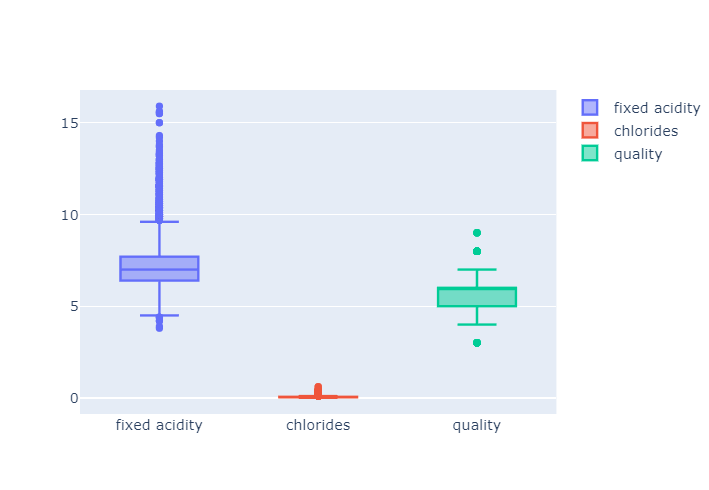
- 일반적으로 머신러닝에서 컬럼간의 범위격차가 많이 나면 트레이닝이 잘 안 될 수.도. 있다.
- 이렇게 차이가 나는 경우 스케일링을 하는게 좋을 수 있는데, Decision scaler에서는 의미가 없음.(주로 cost function 을 최적화할때 유효하다.)
MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
mms = MinMaxScaler()
ss = StandardScaler()
mms.fit(x)
ss.fit(x)
x_mms = mms.transform(x)
x_ss = ss.transform(x)
x_mms_pd = pd.DataFrame(x_mms, columns = x.columns)
x_ss_pd = pd.DataFrame(x_ss, columns = x.columns)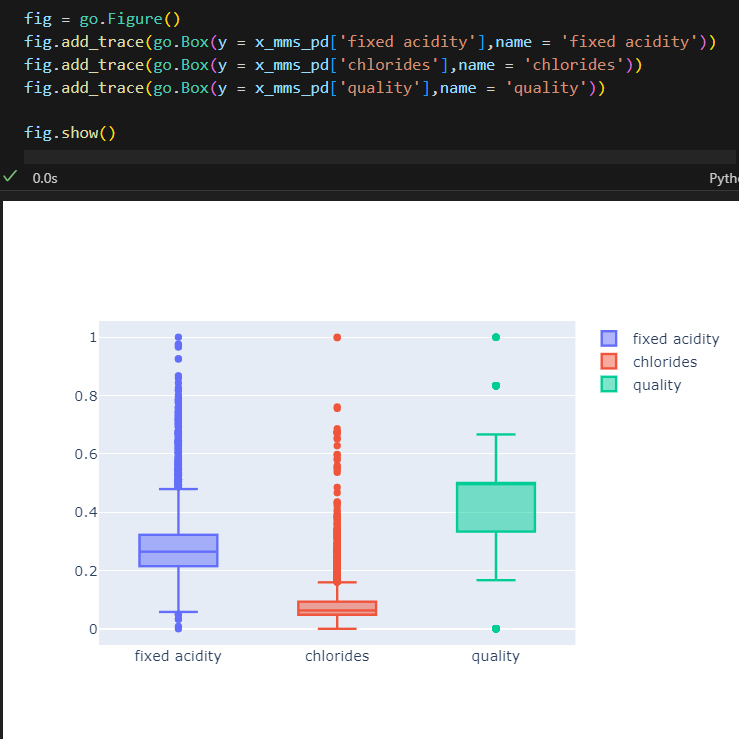
- 정확성 확인: 별 차이가 없긴 하지만 그래도 테스트 해봐야함.
x_tr,x_t,y_tr,y_t = train_test_split(x_mms_pd, y, test_size = 0.2, random_state= 0xC0FFEE)
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 0xC0FFEE)
wine_tree.fit(x_tr,y_tr)
y_pred = wine_tree.predict(x_tr)
y_pred_test = wine_tree.predict(x_t)
print(f'Train acc: {accuracy_score(y_tr, y_pred)}')
print(f'Test acc: {accuracy_score(y_t, y_pred_test)}')
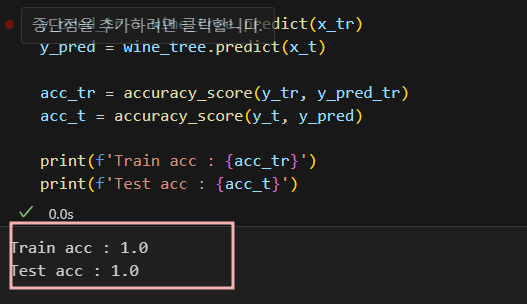
StandardScaler
- 정확성 확인: 차이 없음.
x_tr,x_t,y_tr,y_t = train_test_split(x_ss_pd, y, test_size = 0.2, random_state= 0xC0FFEE)
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 0xC0FFEE)
wine_tree.fit(x_tr,y_tr)
y_pred = wine_tree.predict(x_tr)
y_pred_test = wine_tree.predict(x_t)
print(f'Train acc: {accuracy_score(y_tr, y_pred)}')
print(f'Test acc: {accuracy_score(y_t, y_pred_test)}')
맛의 이진 분류
- 퀄리티의 지표가 몇 개 없으니 0,1로 taste 칼럼을 추가로 만들어 평가할 것.
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
wine.head()-
이 형태로 모델을 학습시킨뒤 정확성을 보았더니 1.0으로 나옴.
-
이걸 확인해보기 위해 트리 작성.(이 경우에서 feature_names 부분에 x.columns만 쓰면 오류가 나서 list로 묶어줌.)
-
quality컬럼으로 taste컬럼을 만들었기 때문에 quality컬럼도 삭제 시켜주어야 학습이 잘 된다.
from sklearn import tree
import matplotlib.pyplot as plt
import sklearn.tree as tree
plt.figure(figsize=(12,8))
tree.plot_tree(wine_tree, feature_names = list(x.columns));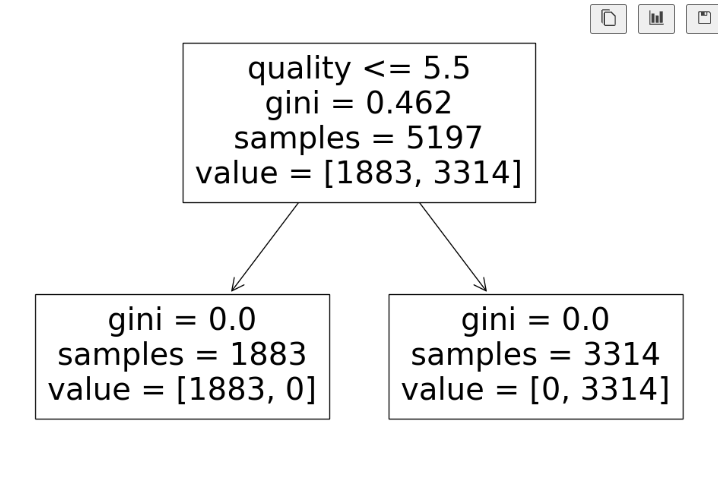
- 코드를 수정한 정확도는 아래와 같다.
x = wine.drop(['taste','quality'],axis = 1)
y = wine['taste']
x_tr, x_t, y_tr, y_t = train_test_split(x,y,test_size = 0.2, random_state = 0xC0FFEE)
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 0xC0FFEE)
wine_tree.fit(x_tr, y_tr)
#수정 후
plt.figure(figsize=(12,8))
tree.plot_tree(wine_tree, feature_names=list(x.columns),
rounded = True,
filled = True)
plt.show()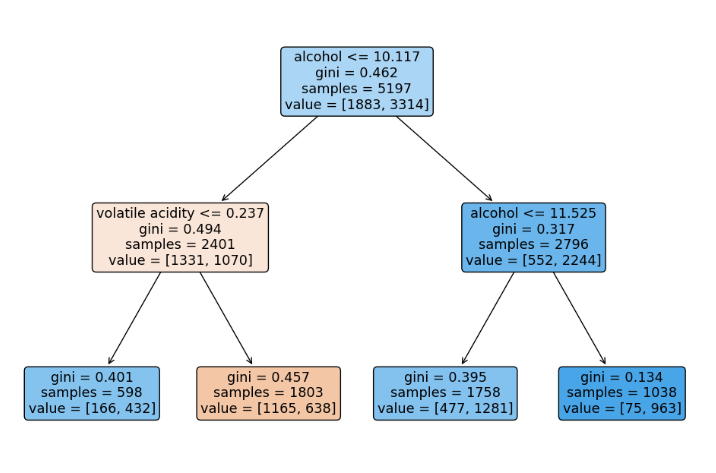
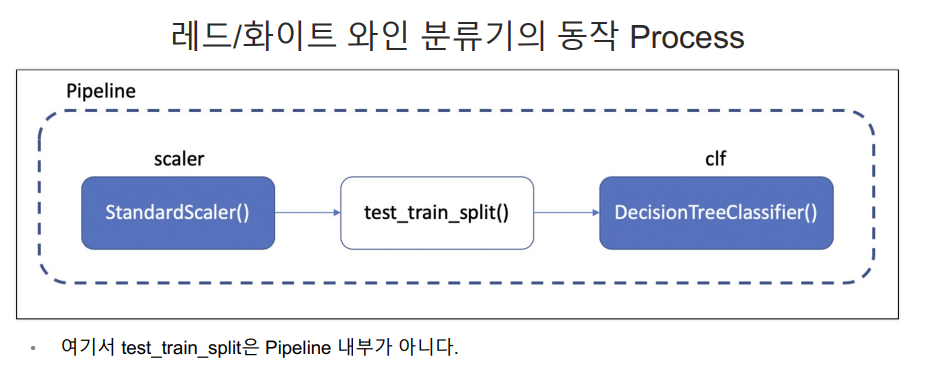
pipeline
- Jupyter Notebook 상황에서 데이터의 전처리와 여러 알고리즘의 반복 실행,
하이퍼 파라미터의 튜닝 과정을 번갈아 하다 보면 코드의 실행 순서에 혼돈이 있을 수 있다. - 이런 경우 클래스(class)로 만들어서 진행해도 되지만, sklearn 유저에게는 꼭 그럴 필요없이 준비된 기능이 있다. → Pipeline
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler',StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)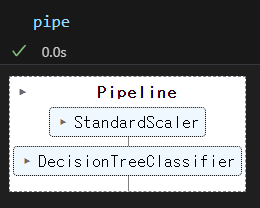
-
pipe.steps:어떤 단계로 이루어지고, 뭐가 지정되어 있는지 알려준다. -
pipe.steps[1]: 어느 위치에 뭐가 지정되어 있는지 알려준다.(스텝별로 객체 호출 가능) -
pipe.set_params(clf__max_depth = 2): pipe에 할당된 스탭에 언더바 두개 '__'로 속성 할당이 가능하다. -
pipeline을 통해 학습이 깔끔해져서 혼돈이 생기지 않게 된다.
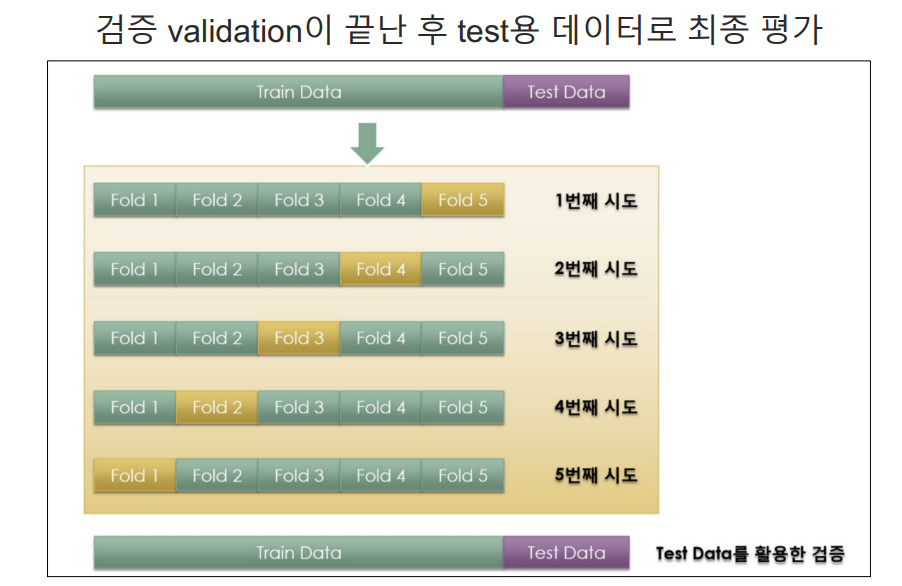
교차검증
- 과적합: 모델이 학습 데이터에만 과도하게 최적화된 현상
- 이로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지게 된다.
- 나에게 주어진 데이터에 적용한 모델의 성능을 정확히 표현하기 위해서도 사용이된다.
1. KFold사용
import numpy as np
from sklearn.model_selection import KFold
#샘플 생성
x = np.array([
[1,2],[3,4],[1,2],[3,4]
])
y = np.array([1,2,3,4])
#k-fold
kf = KFold(n_splits = 2)
print(kf.get_n_splits(x))
print(kf)
for train_idx, test_idx in kf.split(x):
print(f'train:{train_idx}')
print(f'test:{test_idx}')
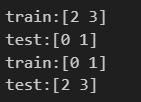
- 실제 들어가있는 데이터가 뭔지 확인하기
for train_idx, test_idx in kf.split(x):
print(f'train:{train_idx}')
print(f'test:{test_idx}')
print('----train_data')
print(x[train_idx])
print('---validation_data')
print(x[test_idx]) 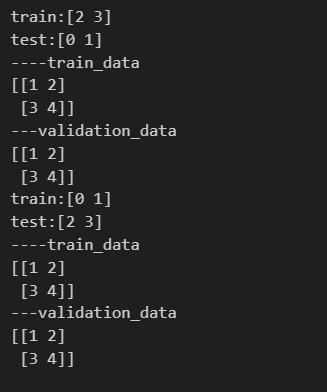
2. StratifiedFold사용
from sklearn.model_selection import StratifiedKFold
kf = KFold(n_splits = 5)
wine_tree_cv = DecisionTreeClassifier(max_depth = 2, random_state = 13)
cv_acc = []
for train_idx, test_idx_idx in kf.split(x):
x_tr = x.iloc[train_idx]
x_t = x.iloc[test_idx]
y_tr = y.iloc[train_idx]
y_t = y.iloc[test_idx]
wine_tree_cv.fit(x_tr,y_tr)
y_pred = wine_tree_cv.predict(x_t)
cv_acc.append(accuracy_score(y_t, y_pred))
cv_acc3. cross validation score 사용
from sklearn.model_selection import cross_val_score
kf = KFold(n_splits = 5)
wine_tree_cv = DecisionTreeClassifier(max_depth = 2, random_state = 13)
cross_val_score(wine_tree_cv, x, y, cv = kf)- train score를 함께 보고싶다면 cross_validate사용
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, x, y, cv =kf, return_train_score= True)
fit_time: 모델을 학습(fit)하는 데 걸린 시간을 측정한 값
score_time: 모델이 예측을 수행하고 점수를 계산하는 데 걸린 시간을 측정한 값
하이퍼파라미터 튜닝
- 모델의 성능을 확보하기 위해 조정하는 값
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth': [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 13)
gridsearch = GridSearchCV(estimator = wine_tree, param_grid = params, cv = 5)
gridsearch.fit(x,y)- cv는 cross validation
import pprint
pp = pprint.PrettyPrinter(indent =4)
pp.pprint(gridsearch.cv_results_)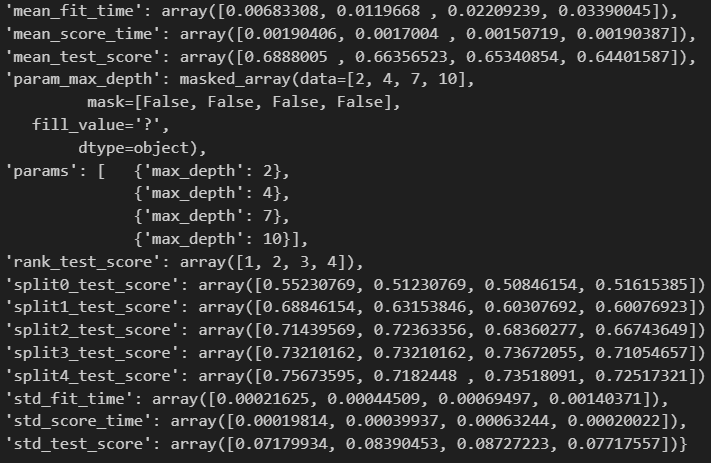
-
gridsearch.best_estimator_,gridsearch.best_score_,gridsearch.best_params_: 성능이 좋은 지표들을 출력해준다.
- 파이프라인과 연결
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler',StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth': [2,4,6,8]}]
GridSearch = GridSearchCV(estimator = pipe , param_grid = param_grid, cv =5)
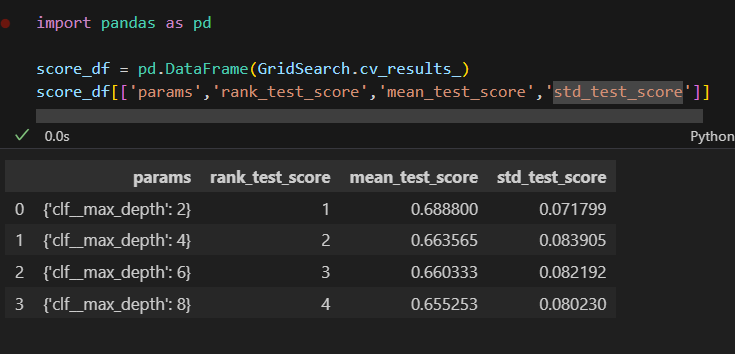
GridSearch.fit(x,y)
- 표로 정리
📌회고록
pip install plotly로 plotly 모듈 불러오기 가능.
(plotly는 대화형 그래프를 만들기 위한 라이브러리이고, 주로 사용하는 모듈은 graph_objs와 express가 있다.아래와 같이 수치가 나온다.)
np.unique: 분리된 트레인,테스트 데이터가 어떻게 분리되었는지 확인할 수 있음.dict(zip(x_tr.columns,wine_tree.feature_importances_)): 중요한 영향을 끼치는 컬럼에 대해 확인할 수 있으며, max_depth를 증가시키면 저 수치에도 변화가 생긴다.- 트리 그림에서 value는 두번째 층을 보았을때 총 2401개의 샘플 중에 1331개는 첫번째 클래스에 속하고, 1070은 두번째 클래스에 속하는 것을 의미한다.