Grokking the Machine Learning Interview - Recommendation System (1) Problem Statement
Recommendation System
Grokking the Machine Learning Interview - Recommendation System
1. Problem Statement
Introduction
추천 시스템은 우리가 매일 사용하는 대부분의 플랫폼에서 사용된다.
예를 들어:
- Amazon 홈페이지에서의 맞춤형 제품 추천
- 핀터레스트 피드에 트렌드와 검색 기록을 바탕으로 한 핀
- 넷플릭스의 나의 취향 및 인기 영화를 바탕으로 한 영화 추천
여기서는 Netflix 영화 추천 태스크를 살펴보는데,
여기서 사용한 유사한 기술들은 거의 모든 다른 추천 시스템에 적용될 수 있다.
Problem statement
Netflix 사용자를 위한 미디어(영화/쇼) 추천해야 하는 태스크에는 사용자가 시청할 "가능성이 최대화되는 방식"으로 추천을 제공한다.
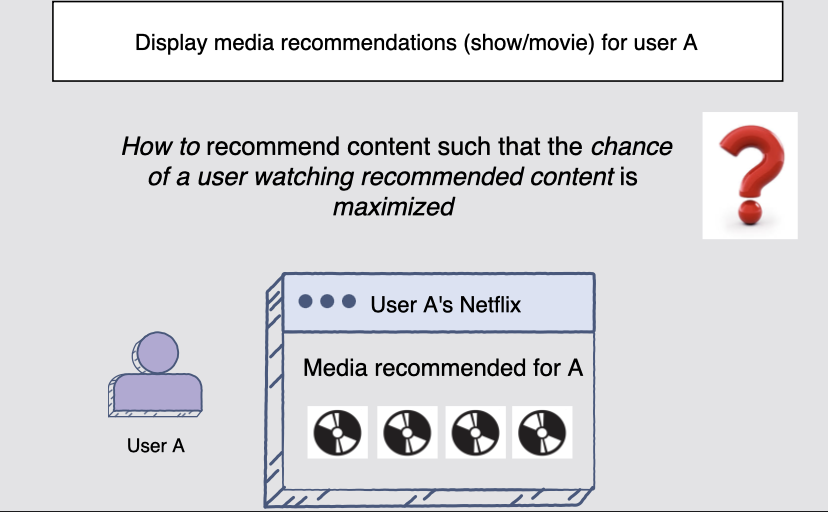
Visualizing the problem
넷플릭스의 성공을 이끈 가장 큰 요인은 추천 시스템이다.
추천 알고리즘이 사용자에게 적합한 종류의 콘텐츠를 제공하는 데 큰 역할을 한다. Netflix의 추천 시스템과 달리 단순 추천 시스템은 특정 사용자의 선호도를 거의 고려하지 않고 단순히 인기 있는 영화/쇼를 추천한다. 기껏해야 시청자의 과거 시청 기록을 살펴보고 같은 장르의 영화/쇼를 추천하는 정도이다.
Netflix 접근 방식의 또 다른 주요 측면은 사용자의 일반적인 선택과 달라 보이는 콘텐츠를 추천하는 방법을 찾았다는 것이다. 그러나 Netflix의 추천은 추측에 근거한 것이 아니라 다른 사용자의 시청 기록을 기반으로 하며 이러한 사용자와 다른 사용자와의 몇 가지 공통 패턴을 이용한다.
그래서 다른 방법으로는 찾을 수 없는 새로운 콘텐츠를 발견하게 한다.
Netflix에서 시청하는 프로그램의 80%는 특정 프로그램을 검색하여 시청하는 것이 아니라 Netflix의 추천에 따라 시청된다. 여기서의 당면한 과제는 사용자의 관심을 유지하고 시야를 넓힐 수 있는 다양한 콘텐츠를 소개하는 추천 시스템을 만드는 것이다.
Scope of the problem
당면한 문제는 위와 같으니 문제의 범위를 정의한다.
2019년 기준 플랫폼의 총 가입자 수는 1억 6,350만명이다.
해외 일일 활성 사용자 수는 5,300만 명입니다.
따라서 매일 좋은 추천이 필요한 다수의 사용자를 위한 시스템을 구축해야 한다.
기계 학습 세계에서 추천 시스템을 설정하는 일반적인 방법 중 하나는 사용자가 콘텐츠를 선택할 확률을 예측하는 것을 목표로 하는 것이다.
따라서 문제 범위는
"사용자와 상황(시간, 위치, 계절)을 고려하여 각 영화를 선택할 만한 확률을 예측하고 해당 점수를 사용하여 영화를 추천한다" 이다.
Problem formulation
각 영화/쇼에 대한 선택 확률을 예측한 다음 해당 점수를 기준으로 영화를 추천 및 순위를 지정한다는 사실을 확립했습니다. 더욱이, 우리의 주요 초점은 사용자가 추천한 항목을 보도록 유도하는 것이기 때문에 추천 시스템은 암시적 피드백(이진 값을 가짐: 사용자가 영화/쇼를 보았는지 여부)을 기반으로 한다.
영화 등급을 예측하기 위해 "명시적 피드백(Explicit feedback)"을 사용하는 대신 "암시적 피드백(Implicit feedback)"을 확률 예측자로 사용하여 영화 순위를 결정한 이유를 살펴본다.
(미디어에 대한 사용자 평가를 예측하는 추천 시스템을 구축할 때의 목표는 사용자가 높은 평점을 주는 추천을 표시하는 것이다)
Types of user feedback
일반적으로 추천에 대한 최종 사용자의 피드백에는 두 가지 유형이 있다.
(1) 명시적 피드백(Explicit feedback):
- 사용자는 추천에 대한 명시적인 평가를 제공한다.
여기서 명시적 피드백의 예는 별표 평점이다.
예를 들어 사용자는 영화에 별 5개 중 4개를 부여한다.
여기서는 추천 문제를 평점 예측 문제로 살펴볼 수 있다.
(2) 암시적 피드백(Implicit feedback):
암시적 피드백은 사용자와 권장 미디어의 상호 작용에서 추출된다. 대부분의 경우 본질적으로 바이너리(binary)이다.
예를 들어 사용자가 영화를 보거나(1) 영화를 보지 않거나(0)이다. 여기서는 추천 문제를 순위 문제로 살펴볼 수 있다.
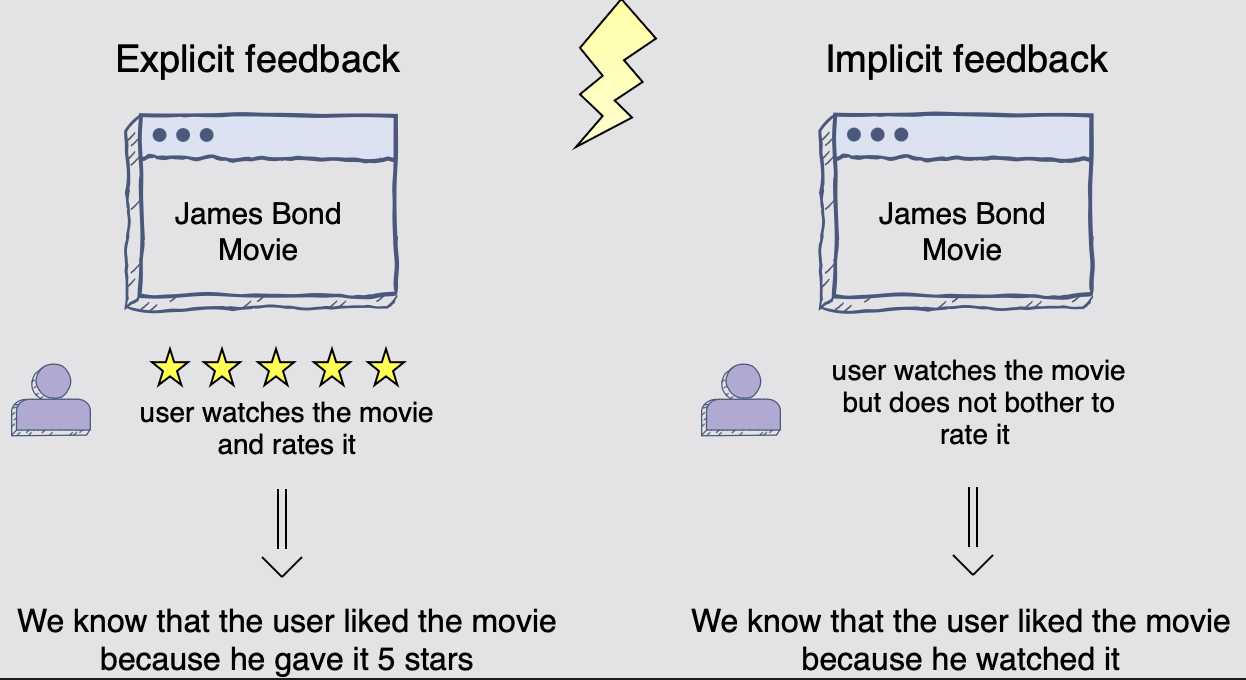
암시적 피드백을 활용하는 주요 이점 중 하나는 대량의 훈련 데이터를 수집할 수 있다는 것이다. 이를 통해 사용자를 더 많이 파악함으로써 추천을 더욱 개인화할 수 있다.
그러나 명시적인 피드백의 경우에는 그렇지 않다.
아래 깔때기에 표시된 것처럼 사람들은 영화를 본 후 영화를 평가하는 경우가 거의 없다.
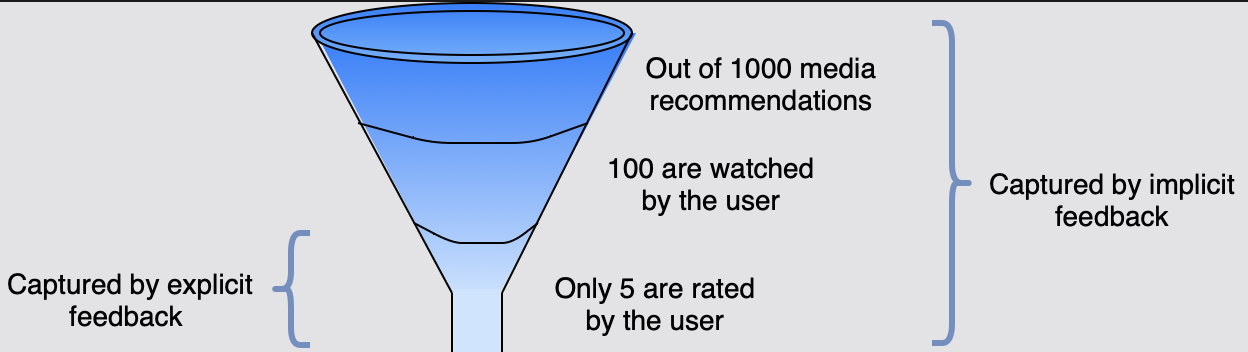
명시적 피드백은 MNAR(Missing Not at Random) 문제에 직면한다. 사용자는 일반적으로 자신이 좋아하는 미디어 추천을 4/5 또는 5/5 별 평점으로 평가한다.
따라서 1/5, 2/5 또는 3/5 등급은 사용자가 좋아하지 않는 영화 종류에 대한 정보이고, 평점이 낮은 영화는 추천 프로세스에 미치는 영향이 적다.
출처
